






文章汇总
要解决的问题
1:大量的纯医学图像和纯文本数据集未使用上,如何让他们也加入对比学习?
2:假阴性问题,一些图像文本对尽管没有标记成一对,但是他们却拥有很高的相似度,单纯把它看成负样本对不利于模型训练。
流程解读
问题1的解决:
作者相当于请了外援,利用前人给好的知识图谱,将采样的
x
i
m
g
x_{img}
ximg和
x
t
x
t
x_{txt}
xtxt得到相应的
l
i
m
g
l_{img}
limg和
I
t
x
t
I_{txt}
Itxt,因此任何图片和样本都能构成样本对来进行对比学习。
假设我们有
n
n
n个成对的图像-文本样本,
m
m
m个标记图像和
h
h
h个医学句子。以前的方法只能使用
n
n
n个成对样本。相比之下,我们将
n
n
n个配对样本分别解耦为
n
n
n个图像和
n
n
n个句子。最终,通过遍历所有可能的组合,我们能够获得
(
n
+
m
)
×
(
n
+
h
)
(n+m)\times (n+h)
(n+m)×(n+h)对图像文本,这导致
(
n
+
m
)
×
(
n
+
h
)
2
×
\frac{(n+m)\times (n+h)}{2}\times
2(n+m)×(n+h)×更多的监督。例如,在上图中,先前的方法对2个图像-文本对进行预训练,而MedCLIP能够利用
(
2
+
3
)
×
(
2
+
3
)
=
25
(2+3)\times (2+3)=25
(2+3)×(2+3)=25个样本,因为我们可以利用上3个单纯的图像和3个单纯的文字。
问题2的解决:
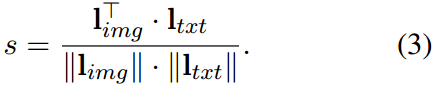
相似度的计算是基于知识图谱转换后的
l
i
m
g
l_{img}
limg和
I
t
x
t
I_{txt}
Itxt来获得的,这使得即使没有标记在一起的图文对也有可能得到很高的相似度,解决了假阴性问题。
摘要
现有的视觉-文本对比学习,如CLIP (Radford等人,2021)旨在匹配配对的图像和标题嵌入,同时将其他嵌入分开,从而提高表征可转移性并支持零差预测。然而,医学图像-文本数据集比来自互联网的一般图像和说明文字要低几个数量级。此外,以前的方法遇**到了许多假阴性,即来自不同患者的图像和报告可能具有相同的语义,但被错误地视为阴性。**在本文中,我们将图像和文本解耦用于多模态对比学习,从而以低成本的组合幅度缩放可用的训练数据。我们还提出用基于医学知识的语义匹配损失代替InfoNCE损失,以消除对比学习中的假阴性。我们证明MedCLIP是一个简单而有效的框架:它在zero-shot预测,监督分类和图像文本检索方面优于最先进的方法。令人惊讶的是,我们观察到,仅使用20K预训练数据,MedCLIP就胜过了最先进的方法(使用≈200K数据)。
1 介绍
医学图像,如x射线、CT和核磁共振成像,通常用于诊断、监测或治疗临床实践中的医疗状况(FDA, 2022)。随着医学图像和相应报告数据的快速增长,研究人员开发了各种深度学习模型来支持临床决策(Çallı et al, 2021)。最近,大规模的图像-文本预训练,例如CLIP (Radford et al ., 2021),在计算机视觉和自然语言处理领域取得了相当大的成功。CLIP被训练来预测一批图像和文本训练的例子的正确匹配。在大规模imagetext对上对图像和文本表示进行联合训练,生成可转移的表示,支持灵活的下游任务。受CLIP成功的启发,我们认为从医学图像和报告中共同学习的知识应该有助于下游的临床任务。
然而,在医学领域采用视觉文本预训练是一项非常重要的任务,因为(1)CLIP (Radford等人,2021)数据匮乏的性质:CLIP是在从互联网收集的400M图像文本对数据集上进行训练的,而公开可用的医学图像和报告的总数是以下数量级;(2)医学图像和报告的特异性:与一般领域(例如,“猫”与““狗”),医学领域内的差异更加微妙和细粒度(例如,“pneumonia”与“"consolidation”)。简而言之,有必要(1)解决数据不足的问题;(2)捕捉微妙但至关重要的医学意义。
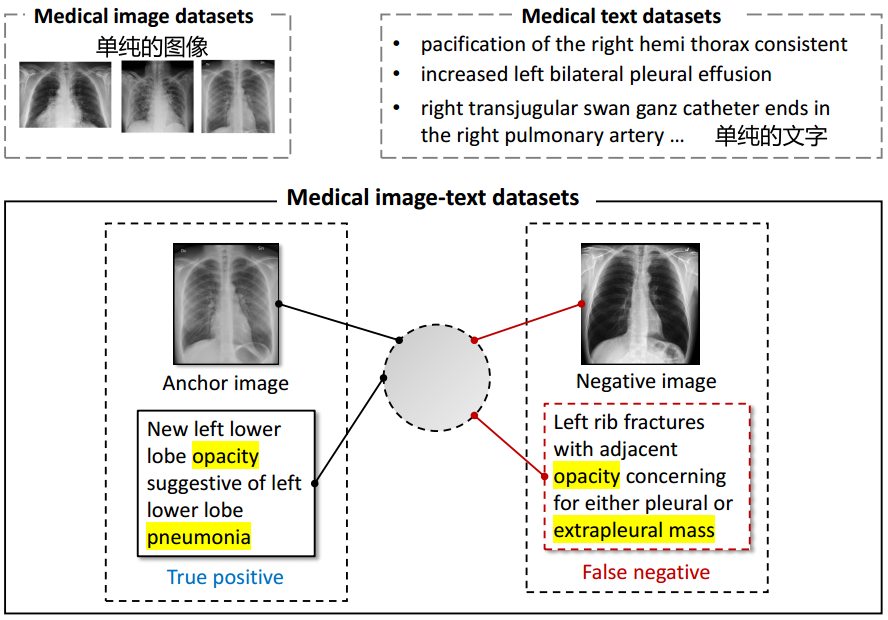
现有的作品试图以不同的方式应对上述挑战。ConVIRT (Zhang et al ., 2020)通过双向对比物镜对配对的医学图像和报告联合训练视觉和文本编码器;GLoRIA (Huang et al ., 2021)进一步对医学图像和报告之间的全局和局部相互作用进行建模,以捕获特定图像区域的病理含义。然而,这两个作品都有明显的局限性,如图2所示。
•可用数据有限。大多数医学图像数据集只提供诊断标签,而不提供原始报告。然而,这两个工作都需要配对的图像和报告,留下大量的医学图像和纯文本数据集未使用。
•对比学习中的假否定。这两种方法都试图将不同患者的图像和文本嵌入分开。然而,即使一些报告不属于目标患者的研究,它们仍然可以描述相同的症状和发现。简单地将其他报告视为负样本,会给监督带来噪音,混淆模型。
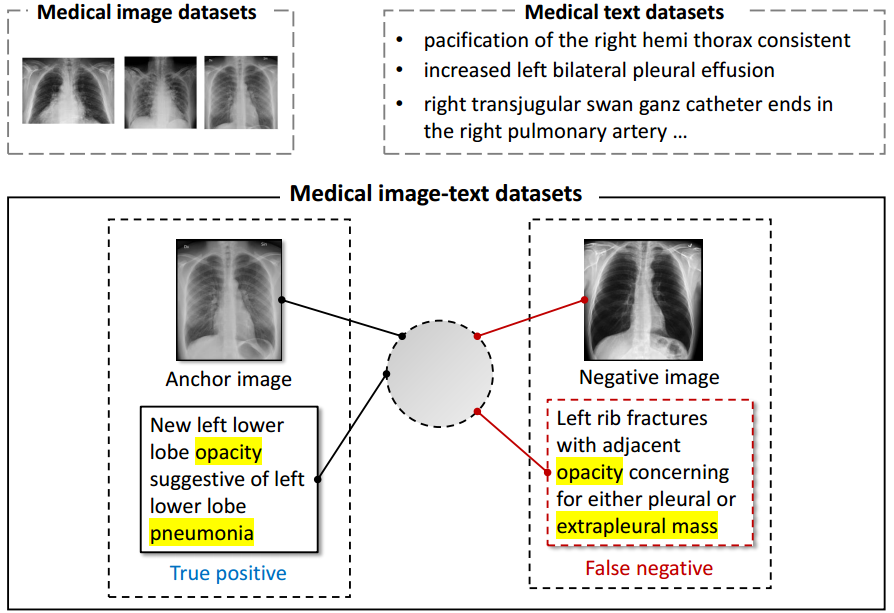
图2:展示医学图像-文本对比学习的挑战。(1)预训练数据只包括配对的图像和文本。然而,更多的纯图像和纯文本数据集被忽略了。(2)出现假阴性。对于锚点图像,以前的方法将成对文本(即来自同一患者研究的报告)视为阳性,将未成对文本(即来自其他患者研究的报告)视为阴性。然而,负面文本可以描述与锚文本相同的症状。
为了应对上述挑战,我们提出了一种简单而有效的方法,即MedCLIP。它有以下贡献:
•解耦图像和文本的对比学习。我们将预训练扩展到大量未配对的图像和文本数据集,以组合的方式扩展训练数据的数量。它为扩展基于医学知识的多模式学习开辟了一个新的方向,而不是昂贵的按比例扩大数据。
•通过医学知识消除假阴性。我们观察到,来自不同患者研究的图像和报告可能具有相同的语义,但被以前的方法错误地视为阴性。因此,我们设计了一种软语义匹配损失算法,以医学图像和医学报告之间的语义相似度作为监督信号。这种方法使模型具备捕捉微妙但至关重要的医学意义的能力。
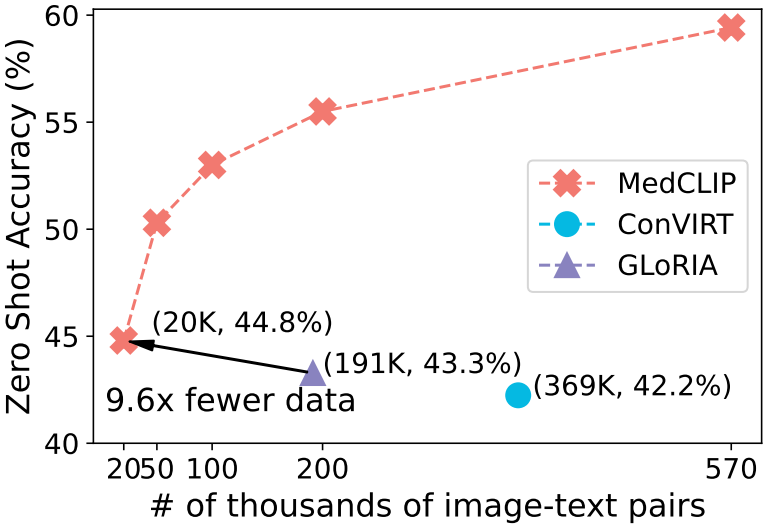
图1:使用不同数据量进行预训练时,MedCLIP、ConVIRT (Zhang et al ., 2020)、GLoRIA (Huang et al ., 2021)的零射击性能。ConVIRT和GLoRIA分别在MIMIC-CXR (369K)和CheXpert (191K)数据集上进行训练。使用接近1/10的预训练数据,我们的方法产生比GLoRIA更好的ACC。
我们在四个公共数据集上对MedCLIP进行了综合评估。结果表明,MedCLIP达到了极高的数据效率,如图1所示。我们的方法仅使用10%的预训练数据就获得了比最先进的GLoRIA (Huang et al ., 2021)更好的性能。大量的实验验证了MedCLIP在各种下游任务中的可转移性。它大大超过了基线:提高了10%以上预测ACC用于zero-shot预测和监督图像分类任务;检索精度提高2%以上。详情见§4。
2 相关工作
视觉-文本表示学习被证明可以学习到良好的视觉表示(Joulin et al ., 2016;Li et al ., 2017;Sariyildiz et al, 2020;德赛和约翰逊,2021;Kim et al, 2021;Wang et al ., 2021a)。但它们都适用于来自一般领域的成对图像和字幕,例如Flickr (Joulin et al ., 2016)和COCO captions (Desai and Johnson, 2021)。同样,这些方法不支持跨模态检索,因此也不支持zero-shot预测。
许多人提出学习视觉语义嵌入用于视觉文本检索(Liu et al ., 2019;Wu et al ., 2019;Lu et al ., 2019;黄等,2020;Chen et al ., 2021)通过注意或目标检测模型;以及通过视觉-文本对比学习(Zhang et al, 2020;Jia等,2021;Yuan等,2021;Yu et al, 2022)或多重视觉和文本监督(Singh et al, 2021;Li et al ., 2022)。它们都在通用领域工作,在这个领域,几乎有无限的网络图像和标题可用,这使医学图像文本数据的规模相形见绌。这一挑战阻碍了自监督CL对大型视觉文本转换器的执行。虽然提出了数据增强(Li et al ., 2021)和知识图谱(Shen et al ., 2022)等补救措施,但使用的数据量仍然远远大于医疗数据。
基于对比学习的医学图像-文本表示学习也进行了研究(Zhang et al ., 2020;Huang等,2021;Wang et al ., 2021b)。尽管如此,它们都是在配对的医学图像和文本上工作,因此仍然遇到缺乏数据的挑战。此外,在采用噪声对比估计(NCE) (Van den Oord等,2018)进行实例判别(Wu等,2018)时,它们都存在假负噪声,从而破坏了表征质量(Arora等,2019);郑等,2021)。我们的工作通过充分利用所有可用的医学数据来支持医学图像-文本预训练,弥合了这一差距。并利用针对性的医学知识消除对比学习中的假阴性,提高预训练数据的效率。
3 方法
在本节中,我们按照图3中的流程介绍MedCLIP的技术细节。MedCLIP由三个部分组成:(1)构建语义相似矩阵的知识提取,(2)提取嵌入的视觉和文本编码器,以及(3)训练整个模型的语义匹配损失。
3.1 视觉和文本编码器
MedCLIP由一个视觉编码器和一个文本编码器组成。
视觉编码器
我们使用视觉编码器
E
i
m
g
E_{img}
Eimg将图像编码为
v
∈
R
D
v \in R^D
v∈RD嵌入。projection head 然后将原始嵌入映射到
v
p
∈
R
p
v_p \in R^p
vp∈Rp。
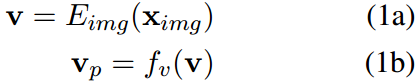
其中
f
v
f_v
fv为视觉编码器的projection head。
文本编码器
我们通过文本编码器在
t
∈
R
M
t \in R^M
t∈RM上创建具有临床意义的文本嵌入。我们把它们投射到
t
p
∈
R
P
t_p \in R^P
tp∈RP上
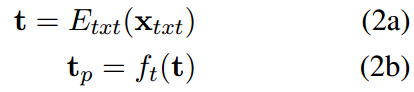
其中
f
t
f_t
ft为投影头,
E
t
x
t
E_{txt}
Etxt为文本编码器。这给出了与视觉编码器相同的嵌入维数
P
P
P,适用于对比学习。
3.2 利用医学知识提取器解耦图像-文本对
配对医学图像文本数据集比一般的配对图像文本(例如,来自互联网)要小几个数量级,因为提供医学专家的高质量注释以及隐私和法律问题需要大量费用。为了增强医学多模态学习,我们希望充分利用所有现有的医学图像-文本、图像-纯和文本-纯数据集。挑战在于,对于纯图像和纯文本数据集,类似clip的对比学习是不可行的。同时,我们要找出所有的正对,以消除假阴性。
图2:展示医学图像-文本对比学习的挑战。(1)预训练数据只包括配对的图像和文本。然而,更多的纯图像和纯文本数据集被忽略了。(2)出现假阴性。对于锚点图像,以前的方法将成对文本(即来自同一患者研究的报告)视为阳性,将未成对文本(即来自其他患者研究的报告)视为阴性。然而,负面文本可以描述与锚文本相同的症状。
假设我们有
n
n
n个成对的图像-文本样本,
m
m
m个标记图像和
h
h
h个医学句子。以前的方法只能使用
n
n
n个成对样本。相比之下,我们将
n
n
n个配对样本分别解耦为
n
n
n个图像和
n
n
n个句子。最终,通过遍历所有可能的组合,我们能够获得
(
n
+
m
)
×
(
n
+
h
)
(n+m)\times (n+h)
(n+m)×(n+h)对图像文本,这导致
(
n
+
m
)
×
(
n
+
h
)
2
×
\frac{(n+m)\times (n+h)}{2}\times
2(n+m)×(n+h)×更多的监督。例如,在图2中,先前的方法对2个图像-文本对进行预训练,而MedCLIP能够利用
(
2
+
3
)
×
(
2
+
3
)
=
25
(2+3)\times (2+3)=25
(2+3)×(2+3)=25个样本。
为了实现额外的监督,我们提出利用外部医学知识来构建知识驱动的语义相似度。与之前平等对待所有阳性样本的研究不同(Khosla等人,2020;郑等,2021;Wang and Sun, 2022),这里我们建议通过语义相似性来区分样本。

特别地,我们将原始报告分割成句子
x
t
x
t
x_{txt}
xtxt。MetaMap (Aronson and Lang, 2010)用于从原始句子中提取统一医学语言系统(Bodenreider, 2004)中定义的实体。按照Peng等人(2018)的做法,我们重点关注表5所示的14种主要实体类型。同样,对于带有诊断标签的图像,我们利用MetaMap将原始类映射到UMLS概念,从而与文本中的实体保持一致,例如,“Normal”映射到“No Findings”。我们从提取的图像和文本实体中分别为
l
i
m
g
l_{img}
limg和
I
t
x
t
I_{txt}
Itxt构建多热向量。因此,我们统一了图像和文本的语义。对于任意采样的
x
i
m
g
x_{img}
ximg和
x
t
x
t
x_{txt}
xtxt,我们可以通过比较相应的
l
i
m
g
l_{img}
limg和
I
t
x
t
I_{txt}
Itxt来度量它们的语义相似度。(me:这个知识图谱可以将采样的
x
i
m
g
x_{img}
ximg和
x
t
x
t
x_{txt}
xtxt得到相应的
l
i
m
g
l_{img}
limg和
I
t
x
t
I_{txt}
Itxt,因此任何图片和样本都能构成样本对来进行对比学习)
3.3 语义匹配丢失
我们通过构建语义标签
l
i
m
g
l_{img}
limg和
I
t
x
t
I_{txt}
Itxt来连接图像和文本。在每次迭代中,我们分别对
N
b
a
t
c
h
N_{batch}
Nbatch输入图像
{
x
i
m
a
g
e
}
\{x_{image}\}
{ximage}和文本
{
x
t
e
x
t
}
\{x_{text}\}
{xtext}进行采样。代替通过搜索等价标签来定义正配对,我们建议建立软目标
s
s
s
s
s
s表示医学语义相似度。
对于图像
i
i
i,我们得到一组
s
i
j
s_{ij}
sij,其中
j
=
1...
N
b
a
t
c
h
j=1...N_{batch}
j=1...Nbatch对应于文本的批次。软目标是通过softmax对
j
j
j进行规范化来计算的。
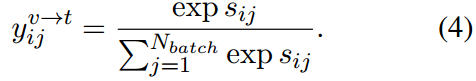
与此类似,文本到图像的反向软目标由
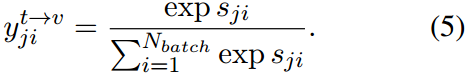
通过图像和文本嵌入之间的余弦相似度获得对数:
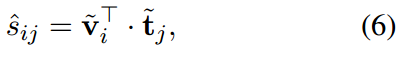
其中
v
~
i
,
t
~
j
\tilde{v}_i,\tilde{t}_j
v~i,t~j分别是归一化的
v
p
,
t
p
v_p,t_p
vp,tp。利用softmax函数得到预测的相似度
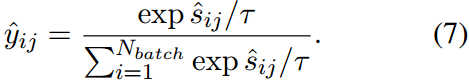
τ
\tau
τ为0.07初始化的温度。因此,语义匹配损失是逻辑与软目标之间的交叉熵
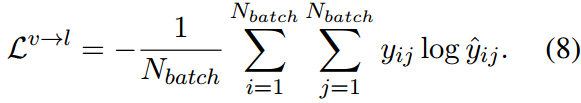
同样地,我们可以计算
L
l
→
v
L^{l \rightarrow v}
Ll→v,然后到达
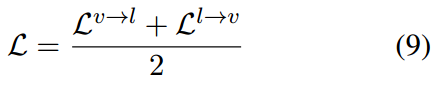
作为最终的训练目标。
4 实验
我们在四个x射线数据集上进行了广泛的实验,以回答以下问题:
•Q1。所提出的预训练方法是否能产生更好的zero-shot图像识别性能?
•Q2。知识驱动的监督即语义匹配任务是否促进了对比图像-文本预训练?
•Q3。MedCLIP是否通过微调为下游分类任务带来更好的性能和标签效率?
•Q4。学习的嵌入是否擅长跨模检索任务?
•Q5。习得的嵌入是什么样的?
4.1 数据集
CheXpert (Irvin et al, 2019)是一个从斯坦福医院收集的包含14个观察标签的大型胸部x射线数据集。请注意,该数据集不向公众提供相应的医疗报告。我们使用该数据集的训练分割进行预训练。为了进行评估,我们遵循(Huang et al ., 2021),并从测试分割中抽取一个多类分类数据集,即CheXpert-5x200。这个多类分类数据集有200张专门用于CheXpert竞赛任务的阳性图像:肺不张、心脏扩大、水肿、胸膜、积液。
MIMIC-CXR (Johnson等人,2019)是一个大型胸部x射线数据库,其中包含从马萨诸塞州波士顿Beth Israel Deaconess医疗中心收集的自由文本放射学报告。我们使用该数据集的训练分割进行预训练。为了进行评估,我们还为上面相同的五个任务采样了一个MIMIC-5x200数据集。
COVID (Rahman等人,2021)是一个公开可用的x射线数据集,具有COVID和非COVID标签。正负比例大致为1:1。我们使用这个数据集进行评估。
RSNA肺炎(Shih et al ., 2019)是美国国立卫生研究院公开的胸片数据库中发现的肺炎病例的集合。这是一个二元分类数据集:肺炎vs .正常。我们选取一个平衡的子集(即1:1的正负比例)并将其用于评估。
4.2 Baselines
Random是具有默认随机初始化的ResNet-50 (He et al, 2015)模型。
ImageNet是在标准ImageNet ILSVRC-2012任务(Deng et al, 2009)上预训练权值的ResNet-50 (He et al, 2015)模型。
CLIP (Radford et al ., 2021)是一个视觉-文本对比学习框架,它是在从互联网收集的400M图像-文本对数据集上进行预训练的。
ConVIRT致力于医学中的视觉-文本对比学习。它对配对的x射线和报告使用了简单的InfoNCE损失(Van den Oord等人,2018)。我们根据他们基于BioClinicalBERT文本编码器和ResNet50 (He et al, 2016)视觉编码器的论文进行了复制。
GLoRIA (Huang et al ., 2021)通过交叉注意在推理中将图像子区域和单词纠缠在一起,认为这样可以更好地捕捉图像和报告中的关键特征。我们基于官方代码和提供的预训练权重2来实现它。
4.3 实现细节
我们使用BioClinicalBERT 3作为主干文本编码器和Swin Transformer (Liu et al ., 2021),并对ImageNet (Deng et al ., 2009)进行预训练权重作为主干视觉编码器。这两种基于变压器的模型都是从变压器库中绘制的(Wolf等人,2019)。我们还提供了以ResNet-50 (He et al, 2015)作为视觉编码器的烧蚀研究,这与之前的工作一致(Zhang et al, 2020;Huang et al, 2021)。
MIMIC-CXR和CheXpert用于预训练,我们将5000个样本拿出来进行评估。所有图像被填充到正方形,然后缩放到224 × 224。对于MIMIC-CXR,我们将的“发现”和“印象”部分结合起来然后报告将它们分成句子。我们删除少于3个单词的句子。我们取一个输出维数为512的线性投影头,初始化时间为0:07的可学习温度τ。我们利用图像增强首先将原始图像缩放到256 × 256,然后应用大小为224×224的随机裁剪;水平翻转概率为0:5;颜色抖动的亮度和对比度从[0:8;1:2);从[−10]采样的随机仿射变换;[10],最大翻译率0:06 . 25,比例因子[0:8];1:1)。其他超参数为:学习率5e-5,批大小100,权值衰减1e-4,迭代次数10,学习率预热比0:1。我们采用混合精度训练,使预训练在单个RTX-3090 GPU上在8小时内完成。
4.4 Q1.Zero-Shot分类
我们对CheXpert-5x200、MIMIC5x200、COVID和RSNA四个数据集进行零拍摄图像分类评价。学习的图像-文本编码器通过匹配编码的图像嵌入和为每个疾病类别创建的提示嵌入来支持零射击预测。我们在表1中说明了结果。
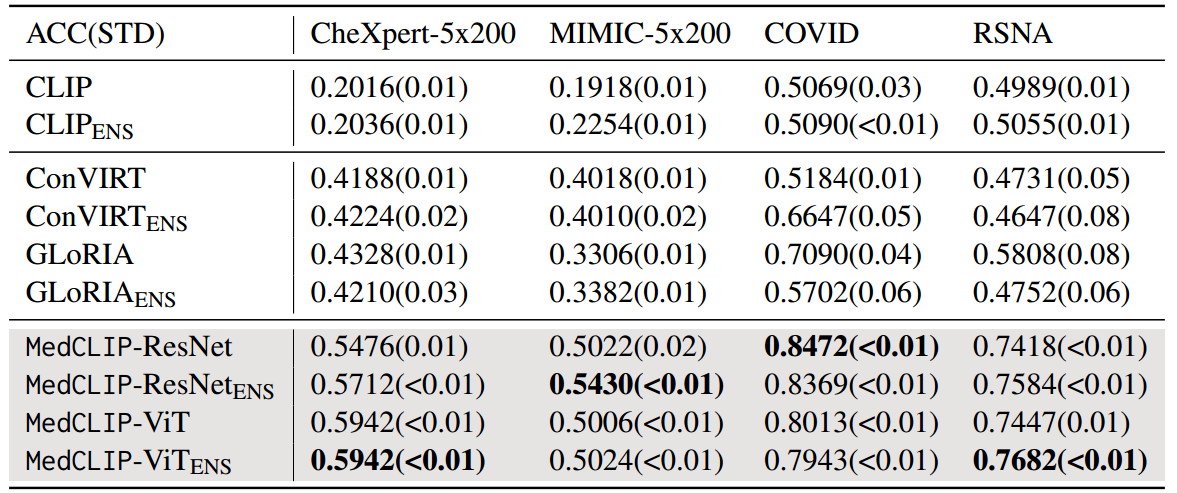
表1:四种数据集上的zero-shot图像分类任务结果。我们采用每个方法的附加提示集成版本(带有下标ENS)。考虑到提示生成过程的随机性,取5次运行的准确率(ACC)的均值和标准差(STD)。数据集的最佳分数以粗体显示。
可以发现,我们的方法在很大程度上优于所有其他基线。MedCLIP能够从即时集成中获益,从而获得更好的性能。相比之下,合奏并不总是对其他两者产生积极的影响,特别是格洛丽亚通常受到合奏的伤害。其中一个原因可能是ConVIRT和GLoRIA在对比预训练中无法区分假阴性,而这些假阴性是结合了使模型混乱的提示集成。此外,我们观察到原始CLIP模型在所有数据集上产生的预测结果与随机猜测基本相同。说明了一般网络图像文本与医学领域图像文本的差异。
有趣的是,MedCLIP对COVID数据的收益率超过0.8 ACC,而在预训练过程中没有可用的COVID-19阳性图像。为了使模型能够检测COVID-19感染,我们参考了(Smith et al ., 2020)中提出的描述:在外围和中下肺区分布中存在斑块状或融合状、带状磨玻璃样混浊或实变,以构建提示。该结果表明,MedCLIP的对比预训练使其具有域外类的可移植性。
4.5 Q2.预训练数据效率
数据效率是基于CLIP方法的一个关键挑战。可以看出,CLIP在训练阶段使用了400M的图像-文本对,这不仅计算成本高,而且由于数据有限,在医学领域也不可行。为了评估MedCLIP的数据效率,我们将预训练数据分别提取到20K、50K和200K,然后对MedCLIP进行预训练,并在CheXpert-5x200数据上记录得到的模型零射击预测结果。结果如图1所示。
我们惊讶地发现,在使用20K数据时,MedCLIP的性能优于从整个CheXpert数据集(大约200K图像-文本对)学习的GLoRIA。同样,MedCLIP击败了使用369K数据的ConVIRT。当我们纳入更多的训练数据时,MedCLIP的准确性也得到了提升。在570K样品(MIMIC-CXR + CheXpert)中,我们没有观察到零射击ACC的饱和。这标志着MedCLIP在多源数据学习方面的巨大能力。
4.6 Q3.分类微调
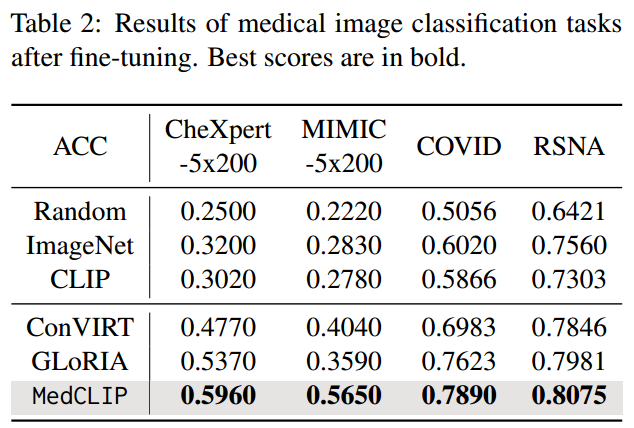
我们的目的是评估学习模型对下游监督任务的可转移性。我们绘制并冻结图像编码器,并在具有交叉熵损失的训练数据上微调随机初始化的线性分类头。结果如表2所示。我们表明,MedCLIP在所有三种方法中仍然达到了最佳性能。更重要的是,我们惊讶地发现,当对比表2和表1时,MedCLIP使zero-shot预测与监督学习模型相当。
在所有数据集上,zero-shot MedCLIP比其他监督模型表现得更好。具体来说,我们发现在COVID上,零射击MedCLIP比有监督的MedCLIP表现得更好,这证明了MedCLIP在低资源场景下的优势。相反,没有对医学领域数据进行预训练,ResNet基线的性能较差。
4.7 Q4.图像文字检索
我们选择CheXpert-5x200来评估所有模型通过图像-文本检索任务学习到的表征的语义丰富度。由于CheXpert-5x200没有公开可用的报告数据,我们使用MIMIC-CXR数据集来生成报告/句子。我们为CheXpert5x200数据集中的5个类中的每个类采样了200个句子。这将产生1000个图像和1000个句子作为检索数据集。我们使用Precision@K通过检查报告是否属于与查询相同的类别来计算前K个检索到的报告/句子的精度的图片。
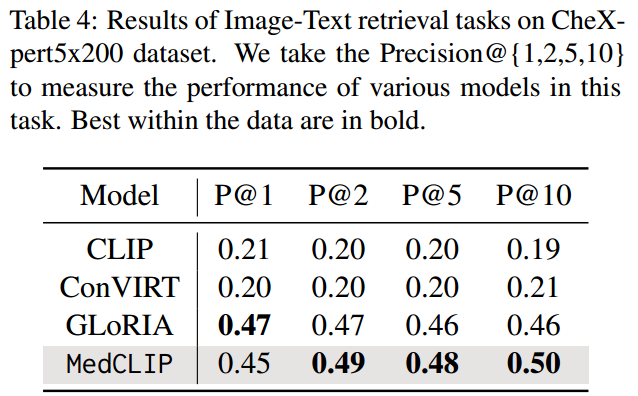
我们通过表4显示结果。可以看出,MedCLIP在所有方法中取得了最好的性能。这表明我们的方法有效地提供了检索文本所需的语义信息。我们发现,k值越高,MedCLIP的精度越高,对此现象的分析见附录A。
4.8 Q5.嵌入可视化

我们还通过绘制为CheXpert-5x200图像生成的图像嵌入的t-SNE (Van der Maaten和Hinton, 2008)来证明我们的表示学习框架的有效性。我们将其嵌入与CLIP模型嵌入进行了比较。如图4所示,我们的模型产生了更好的聚类表示。而CLIP模型的t-SNE图是均匀的。这是因为大多数医学x光片都有很高的重叠,而只有小的病变区域是不同的。尽管如此,MedCLIP仍然通过病变类型来检测群集。
5 结论
在这项工作中,我们提出了一个解耦的医学图像-文本对比学习框架MedCLIP。它以组合幅度显著地扩展了训练数据的大小。同时,医学知识的引入有助于减少假阴性。因此,MedCLIP产生了出色的预训练数据效率:它以大约10倍的数据减少了1%的ACC,超过了最先进的基线。此外,我们验证了MedCLIP在zero-shot预测、监督分类和图像文本检索任务上的突出性。期望支持医学领域的基础模型,并在资源需求低的情况下处理各种疾病的医学诊断。
局限性
这项工作利用医学领域知识来解耦医学图像和文本的对比学习。因此,它大大扩展了可用于预训练的训练数据。同时,提出的知识引导语义匹配损失修正了幼稚对比学习中出现的假否定。它仍然会遇到检测到不正确的语义标记或缺少对否定或不确定短语的检测的失败情况。一种补救方法是引入从噪声数据中学习的技术(Wang et al ., 2020, 2022),以减轻提取的语义相似矩阵中的噪声。
另一个问题是,尽管我们证明MedCLIP能够达到与微调对应的零射击预测精度相当的精度,但它仍然不适合实际使用。我们认为原因包括:(1)基于提示的推理依赖于提示质量;(2)需要更多的预训练数据来进一步增强预训练。具体来说,对于(1)点,利用提示学习方法(Zhou et al, 2022)将模型应用自动化到下游任务,而不是执行手动提示工程,是有希望的。
参考资料
论文下载(EMNLP(CCF B) 2022)
https://arxiv.org/abs/2210.10163


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











