







 本文提出了一种自适应测试框架,用于更高效、准确地评估大规模语言模型(LLM)的认知能力。通过借鉴心理测量学中的计算机自适应测试(CAT),该框架能根据模型的表现动态调整问题难度,减少测试题目数量,同时提高评估精度。研究表明,这种方法比传统基于答对率的评估方法更有效,仅需20%的题目就能达到相同精度。在对6个商业化大语言模型的测试中,GPT4在数学推理等方面表现出色,达到人类平均水平。ChatGPT虽然在某些方面表现突出,但也存在容易出错和猜测答案的情况,类似“粗心的学生”。
本文提出了一种自适应测试框架,用于更高效、准确地评估大规模语言模型(LLM)的认知能力。通过借鉴心理测量学中的计算机自适应测试(CAT),该框架能根据模型的表现动态调整问题难度,减少测试题目数量,同时提高评估精度。研究表明,这种方法比传统基于答对率的评估方法更有效,仅需20%的题目就能达到相同精度。在对6个商业化大语言模型的测试中,GPT4在数学推理等方面表现出色,达到人类平均水平。ChatGPT虽然在某些方面表现突出,但也存在容易出错和猜测答案的情况,类似“粗心的学生”。

©PaperWeekly 原创 · 作者 | 庄严、宁雨亭
单位 | 中国科学技术大学BASE课题组

论文标题:
Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective
作者:
Yan Zhuang, Qi Liu, Yuting Ning, Weizhe Huang, Rui Lv, Zhenya Huang, Guanhao Zhao, Zheng Zhang, Qingyang Mao, Shijin Wang, Enhong Chen
单位:
中国科学技术大学、认知智能全国重点实验室
链接:
http://arxiv.org/abs/2306.10512

摘要
ChatGPT 等大规模语言模型(LLM)已经展现出与人类水平相媲美的认知能力。为了比较不同模型的能力,通常会用各个领域的 Benchmark 数据集(比如文学、化学、生物学等)进行测试,然后根据传统指标(比如答对率、召回率、F1 值)来评估它们的表现。
然而,从认知科学 [1] 的角度来看,这种评估 LLM 的方法可能是低效且不准确的。受心理测量学中的计算机自适应测试(CAT)的启发,本文提出了一个用于 LLM 评估的自适应测试框架:并非简单计算答对率,而是根据各个被试(模型)的表现动态地调整测试问题的特征,如难度等,为模型“量身定制”一场考试。
以下图为例,CAT 中的诊断模型 CDM 会根据被试之前的作答行为(对/错)对其能力进行估计。接着,选题算法(Selection Algorithm)会根据该估计值选择最具信息量或最适合他的下一道题,例如选择难度和被试能力最接近的题目。如此循环往复直到测试结束。相比传统评估方法,该框架能用更少的题目更准确地估计模型的能力 [2]。
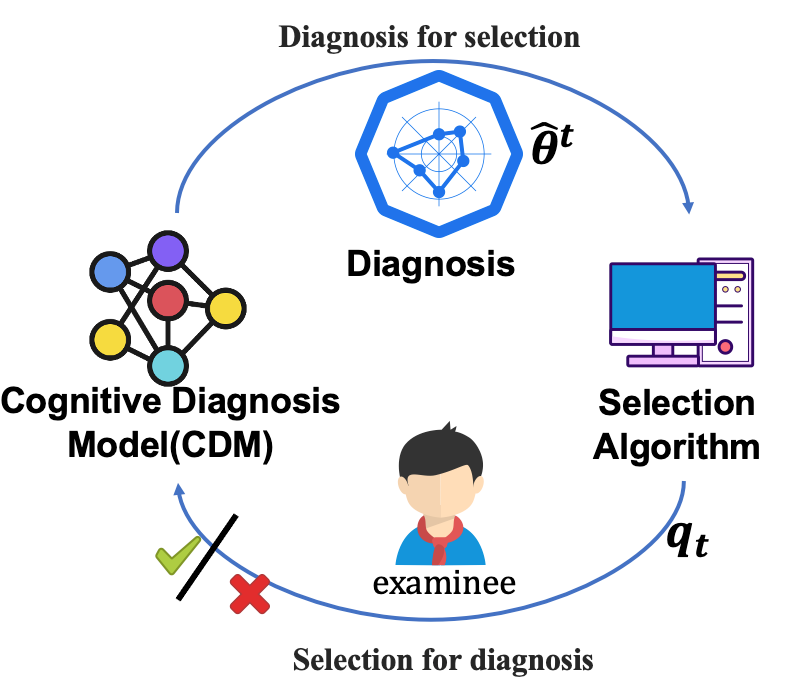
▲ 图1 CAT流程
本文对 6 个商业化的大语言模型:ChatGPT(OpenAI)、GPT4(OpenAI)、Bard(谷歌)、文心一言(百度)、通义千问(阿里)、星火(讯飞)进行细粒度的诊断,并从学科知识、数学推理和编程三个方面对它们进行了认知能力排名。其中 GPT4 显著优于其他模型,已经达到了人类平均水平的认知能力。本文的诊断报告也发现,ChatGPT 表现得像一个“粗心的学生”,容易失误,偶尔也会猜测问题的答案。
“千模千测”——这有可能成为评估大规模语言模型的新范式。

引言
近几个月来, 大规模语言模型(LLM)以其强大的能力颠覆了人们对语言模型的认知。除了传统的 NLP 任务,大模型在写作、编程、作词作曲等各方面展现出难以置信的类人水平 —— 这仅仅是 LLM 能力的冰山一角。
为了充分评估 LLM 认知能力水平,一些最初为人类设计的各类专业或学术考试被用来对模型进行评测:

▲ 图2 传统 LLM 评测方法
然而,依赖这些固定的考试并不高效:(1)它通常需要许多相应领域的专家对 LLM 的每一个回答进行评判/打分,尤其对于主观或创造性的问题。(2)模型回答过程中推理(inference)的开销是巨大的。例如,GPT3 需要在 1750 亿参数的模型上进行推理、GPT4 对每一千 tokens 收费 0.03 美元,并且限制了 API 请求的频率...
因此,本文从认知科学领域中引入了一种新的评估模式——计算机自适应测试(Computerised Adaptive Testing, CAT),建立一个自适应的、高效的评估框架:
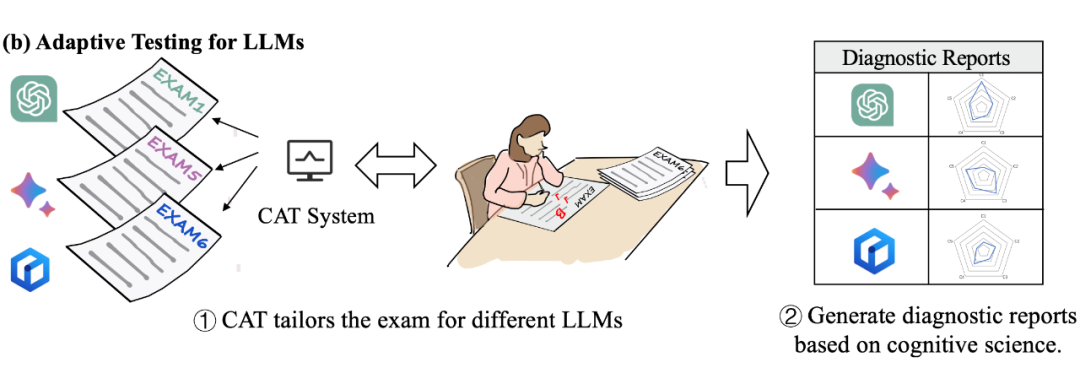
▲ 图3 自适应 LLM 评测
本文将 LLM 视为一个学生,为各个模型“定制试卷”以准确评估其能力。相比传统基于答对率的方法,它所需要的题目数量更少(降低专家人工成本)、能力估计更准,是一种更符合认知能力评估的范式。本文贡献如下:
1. 正式将心理测量学中的 CAT 引入 LLM 的评估中,分析发现每个模型的试卷中有 20%~30% 的题目是不同的,这部分题目对测试的自适应性和个性化至关重要。同时,在相同的能力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









