








最新消息!
在Meta AI发布Code Llama后仅两天的时间,WizardLM 团队基于该模型及其最新的对齐算法训练的WizardCoder-Python 34B V1.0在权威代码生成评测榜单HumanEval上即达到了惊人的 73.2% pass@1分值,同时超越了Claude-2(71.2%), 3月份版本的GPT-4(67.0%), 以及最新的ChatGPT-3.5 (72.5%)。与此同时,WizardCoder 团队也在Github和HuggingFace开源了该模型细节及权重:
Github: https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
HuggingFace:https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0
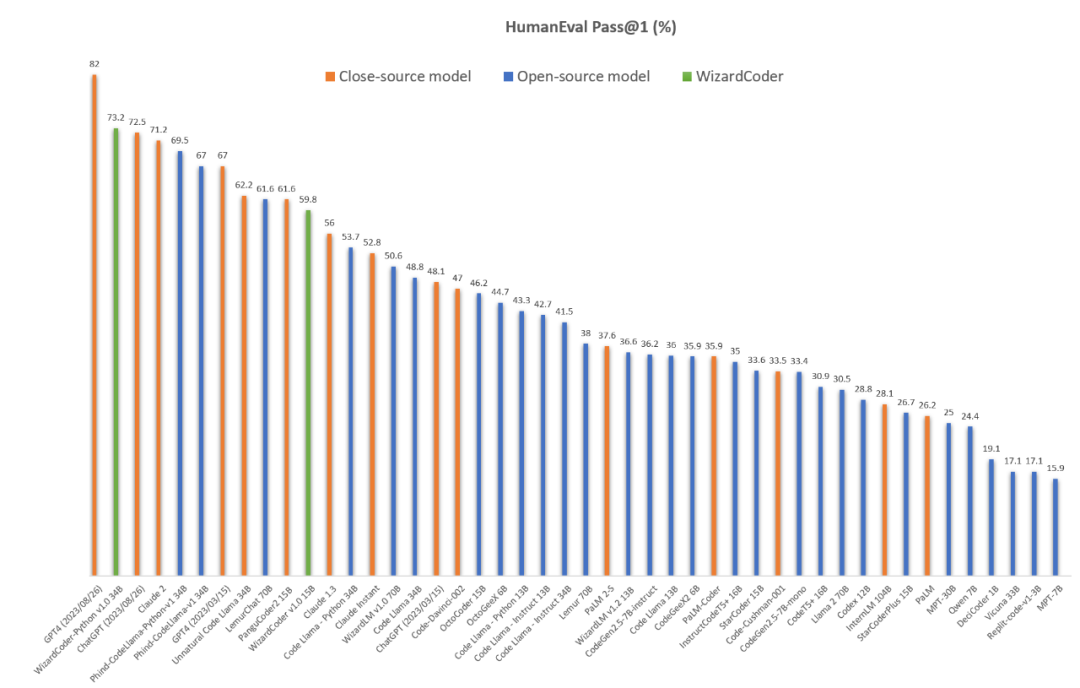
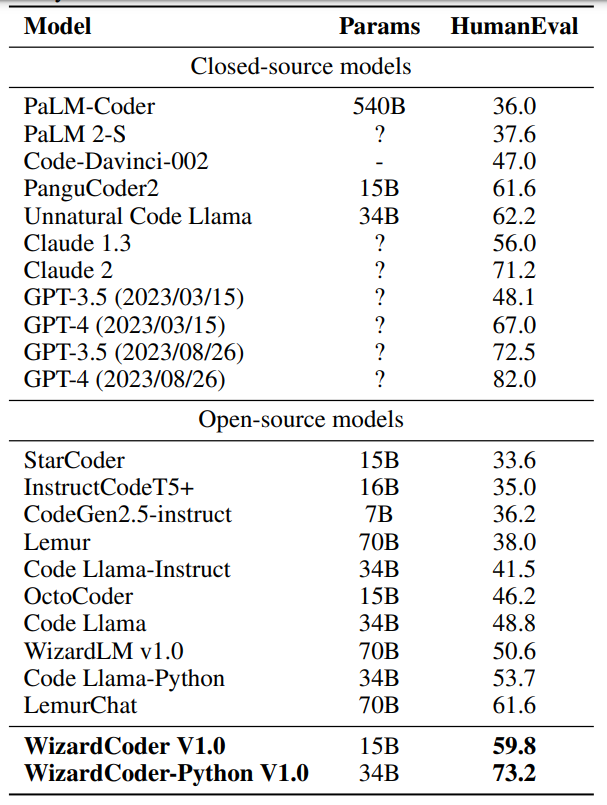
对于该全新代码模型,PaperWeekly团队将进行全面评测,并继续发布详细报道。今天,我们主要介绍Wizard家族的另一位重要成员WizardMath,及其数学能力超越ChatGPT-3.5的RLEIF算法。

前言
作为大语言模型(LLM)最重要也最具挑战性的能力之一,数学推理同时吸引了 AIGC 学术界与工业界广泛研究和关注。根据 OpenAI 相关技术报告,GPT-4 在 GSM8k 和 MATH 基准测试中取得了惊人的成绩,通过率分别高达 92% 和 42% 以上!
与此同时,在开源领域,由 Meta 主导发布的 Llama 2 更进一步提升了开源模型在这一领域的表现,达到了新的先进水平。
然而,作者团队依然注意到,目前最佳开源模型 Llama 2 在 GSM8k 任务上的通过率也仅约为 56.8%,仍远低于包括 GPT-4、ChatGPT、Claude、PalM 2 等在内的一众闭源模型性能。由于数学推理对于计算过程准确度与逻辑推理能力的严苛标准,因此追赶和提升难度也更高。
最近,在 WizardLM 团队相继开源WizardLM和WizardCoder模型后,又开源一款全新的数学推理大模型——WizardMath,它打破了闭源模型的垄断地位,显著超越 OpenAI 的 ChatGPT, Anthropic 的 Claude 以及 Google 的 PaLM 2 等 ,在参数只有 700 亿远不及他们情况之下,成为新时代的开源领军者。
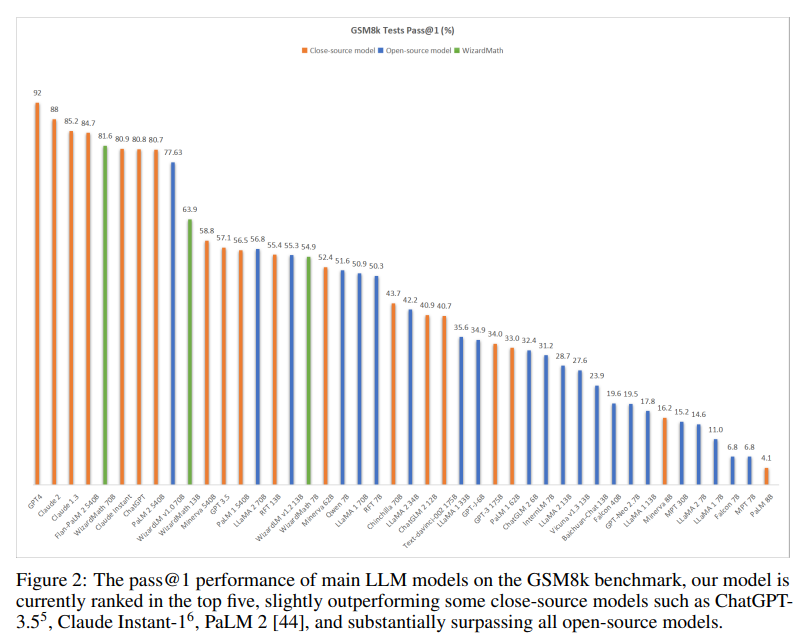
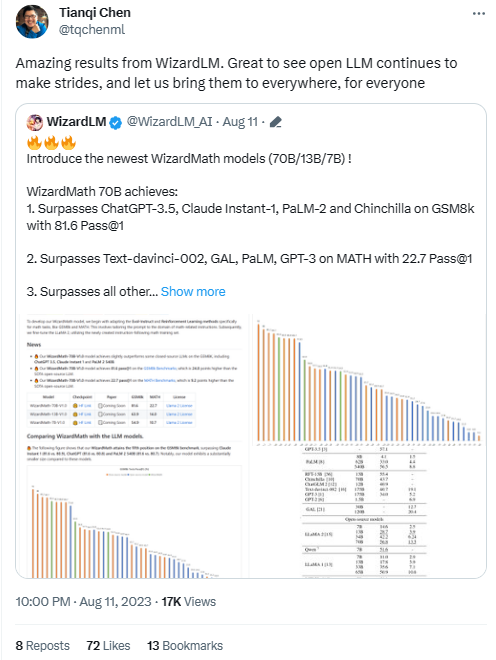
距离 WizardLM 宣布团队开源 WizardMath 仅 5 天,该模型即获得了大模型社区广泛的关注与认可。
著名 CMU 科学家,MXNet,XGBooST,TVM 等著名项目创建者,以及 OctoML 首席科学家陈天奇也祝贺 WizardMath 在开源大模型数学领域的突破。
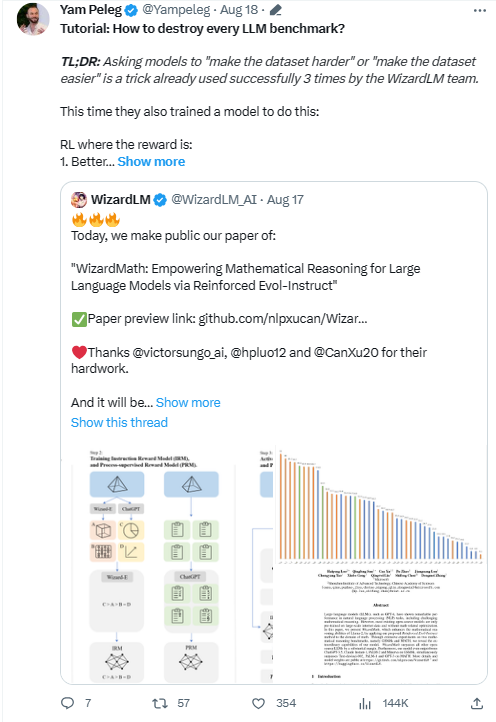
甚至著名科学家 Yam Peleg 也详细解读并转发 WizardMath 的论文:
也有国外大佬 Charles H. Martin 转发了 WizardMath 论文:
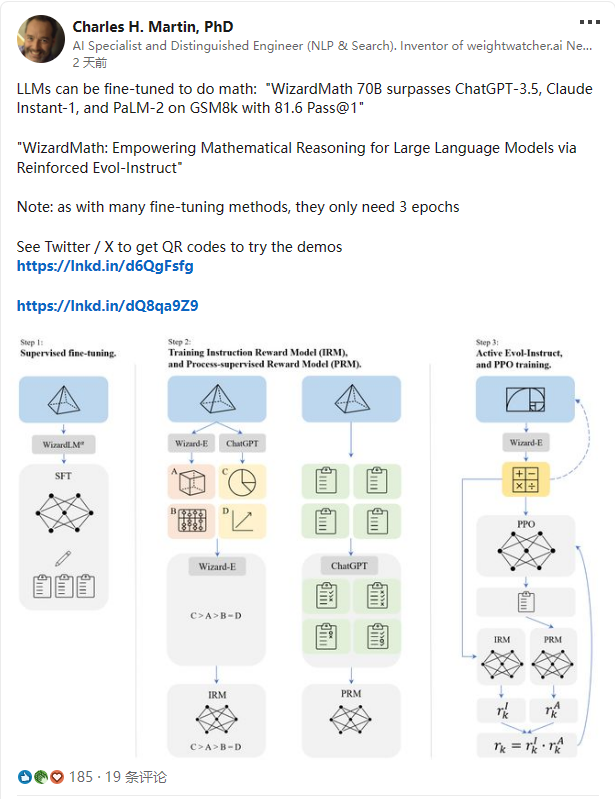

RLEIF(Reinforced Evol-Instruct)方法
WizardMath 取得成功主要依靠的就是一种成为 RLEIF 的全新强化学习方法。受 WizardLM 的 Evol
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9901
9901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









