







 本文详尽分析了大模型知识编辑的最新进展,涵盖新技术、新设定、挑战与局限性。研究集中在如何通过微调、检索增强和局部参数更新等方法,解决知识更新、模型谬误和知识泛化问题。讨论了 LTE、LoRA、MELO、StableKE 等框架,展示了它们在保留模型通用能力的同时进行知识编辑的能力。此外,还探讨了黑盒模型的知识编辑、知识编辑的稳定性和鲁棒性,以及对大模型潜在危害的分析。未来研究方向包括如何实现更高效、安全和可解释的知识编辑,以促进大模型的持续学习和应用。
本文详尽分析了大模型知识编辑的最新进展,涵盖新技术、新设定、挑战与局限性。研究集中在如何通过微调、检索增强和局部参数更新等方法,解决知识更新、模型谬误和知识泛化问题。讨论了 LTE、LoRA、MELO、StableKE 等框架,展示了它们在保留模型通用能力的同时进行知识编辑的能力。此外,还探讨了黑盒模型的知识编辑、知识编辑的稳定性和鲁棒性,以及对大模型潜在危害的分析。未来研究方向包括如何实现更高效、安全和可解释的知识编辑,以促进大模型的持续学习和应用。

随着深度学习与预训练技术的快速发展,大模型如 ChatGPT、Mistral、LLaMA、ChatGLM、文心一言、通义等在自然语言处理领域已经取得了显著的突破。大模型通过将海量的、以文本序列为主的世界知识预先学习进神经网络中,并通过参数化空间实现对知识的处理和操作,其揭示了大规模参数化神经网络在习得和刻画世界知识上的巨大潜力。不同于传统的符号知识工程,大模型的隐式参数知识具有表达能力强、任务泛化好等优点。
然而,大模型在处理和理解知识方面仍然存在一些挑战和问题,包括知识更新的困难,以及模型中潜在的知识谬误问题。随着模型参数量变大,大模型更新的成本逐渐变得非常高昂,而且更新后的模型鲁棒性难以保障。
大模型微调、检索增强(RAG)和局部参数更新都是处理大模型知识谬误问题的技术手段之一。研究大模型知识编辑技术,以便使其可以像人类每天读书、看报一样进行知识更新具有重要意义:
1)可以深入理解大模型知识存储机理;
2)实现高效、低成本地大模型知识更新以缓解知识谬误问题;
3)擦除模型中隐私、有害的信息以实现安全、可信的大模型应用。
大模型知识编辑方法一般可分为内部更新和外部干预方法。内部更新方法通过定位等方式来对大模型参数进行局部更新,外部干预法则在保留大模型原参数的前提下植入参数补丁或进行提示上下文增强。本文调研了近期的大模型知识编辑的部分工作,分为大模型知识编辑新技术、新设定和挑战与局限性三部分,最后进行总结与展望。

大模型知识编辑新技术
论文标题:
Learning to Edit: Aligning LLMs with Knowledge Editing
论文链接:
https://arxiv.org/abs/2402.11905
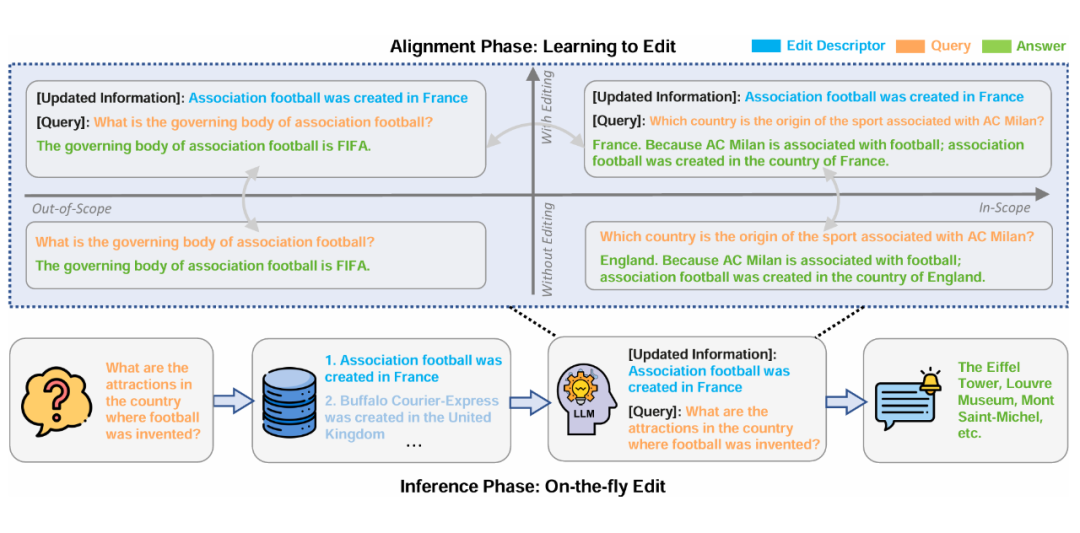
本文提出了一种全新大模型知识编辑框架 LTE(Learning to Edit),旨在解决现有编辑技术侧重于记忆更新的知识而没有考虑新知识与模型原有知识的有效整合问题。LTE 框架分为两个阶段:对齐阶段(Alignment Phase)和推理阶段(Inference Phase)。
在对齐阶段,本文利用 GPT-4 生成了 Out-of-Scope 和具有挑战性的 Free-Text, In-Scope Query-Answer Pairs,在精细设计的数据集上进行微调,以可靠地进行 In-scope 编辑,同时保留范围外信息和通用语言能力。
推理阶段利用检索,从存储的数据中检索出相关的 Edit Descriptors,以满足实时、大量的知识编辑请求。这种方法使大模型能够动态地将最新的知识应用到查询中,从而提高大模型知识编辑的速度和稳健性。
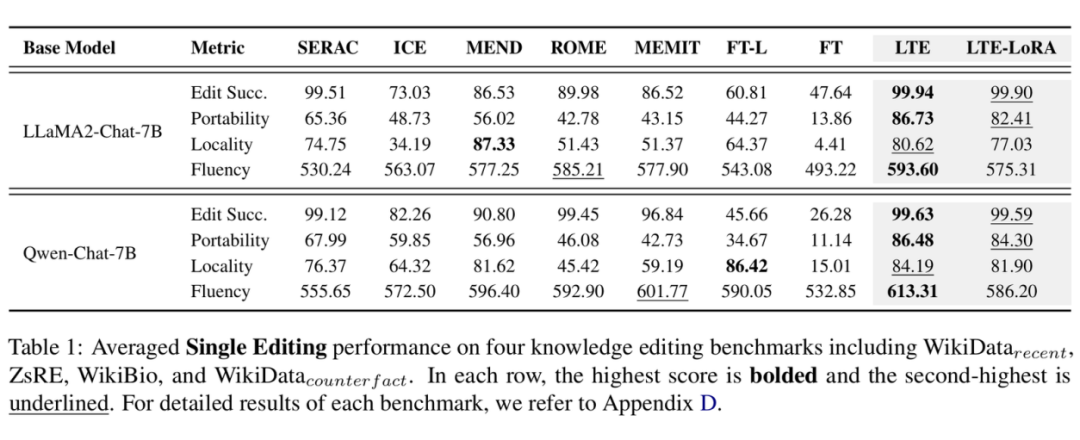
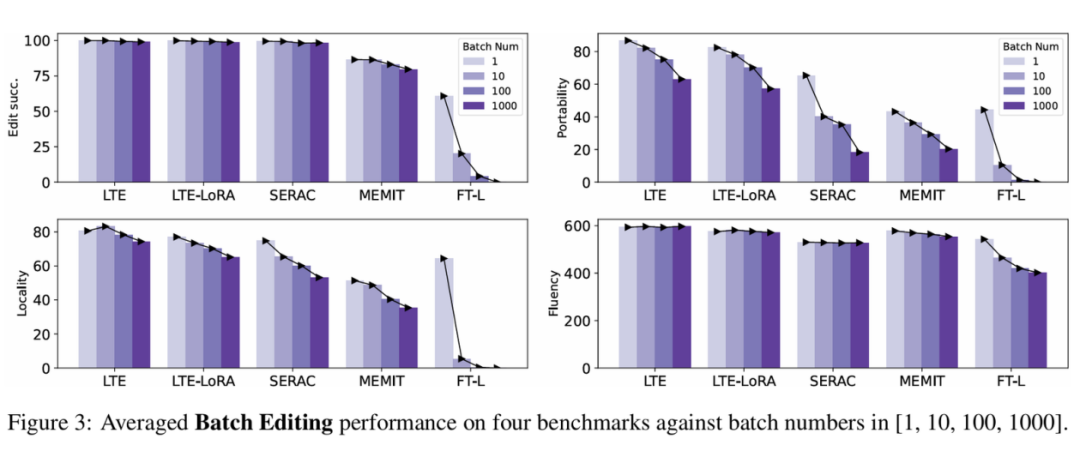
在四个主流知识编辑数据集上,LTE 方法在两个不同的大模型上均取得了优于基线的效果,展示了其在增强知识编辑能力方面的有效性,同时对大模型通用能力的干扰最小。
论文标题:
Model Editing with Canonical Examples
论文链接:
https://arxiv.org/abs/2402.06155
本文提出使用规范实例(Canonical Examples)进行模型编辑的新设定,并提出使用 Sense Finetuning 的方法进行特定行为的编辑。使用规范实例进行模型编辑的设定如下图所示:
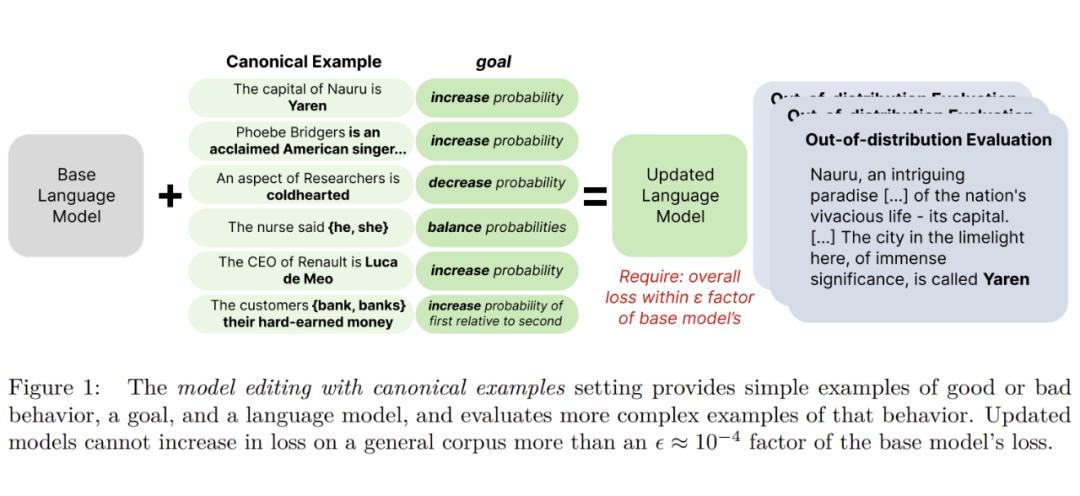
该设定满足三个条件:
(1)使用一个实例进行模型编辑使其表现特定行为。
(2)满足泛化性,这里的泛化指的不是数据分布而是关注复杂的语义(Complexity or Naturalness),比如上图中 “Out-of-distribution Evaluation” 的例子。
(3)尽量不偏离初始模型,其实就是进行模型微调时不要带来太大的副作用损害初始模型的通用能力。
在这个设定下,本文评测了 Full Finetuning,LoRA Finetuning,MEMIT 编辑 Pythia 语言模型后在六个任务(Country-Capital,Company-CEO,Stereoset,Pronoun Gender Bias in Careers,Temporal Entities,Hard Syntax)上的性能。实验结果发现 LoRA 最好。
随后本文受背包模型的启发,设计了 Sense finetuning 的方法,如下图所示:
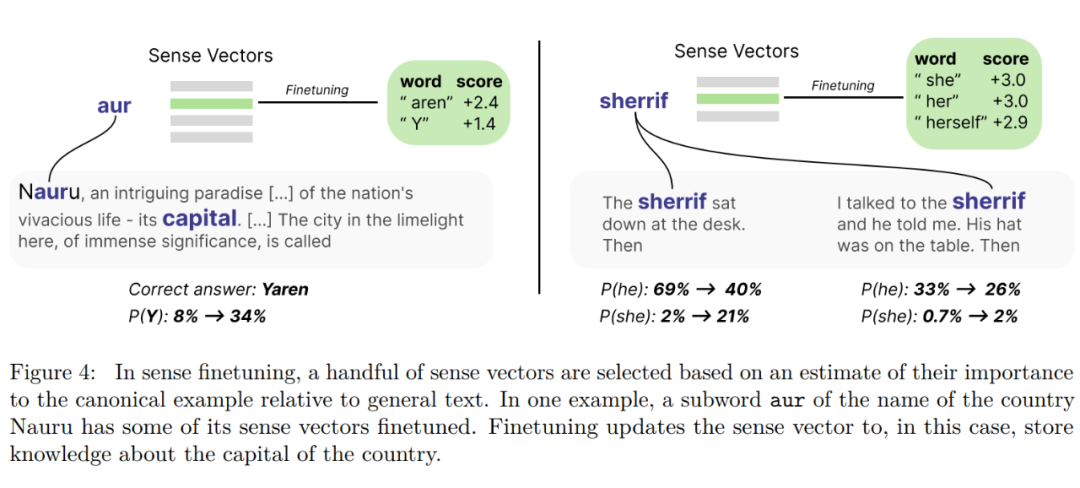
即首先选择出最重要的 Sense Vector(类似于 Word2vector),然后去微调。在 GPT-J-6B 上实验结果如下:
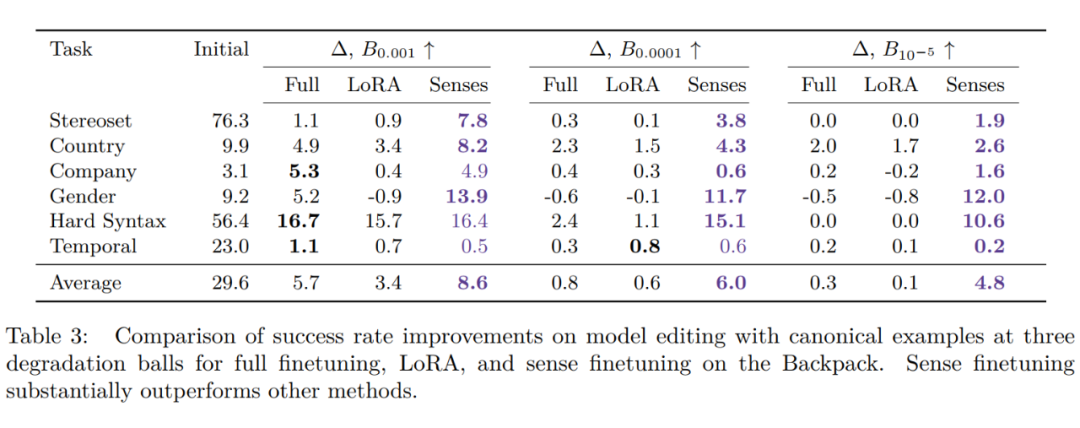
实验结果发现 Sense Finetuning 很好,且增加了可解释性。这启发未来模型的新体系架构,本文建议使用利用小型的、可适应的模型(比如这里借助背包模型的 Sense Vector,以及 Sens Finetuning 等技术)来修复和更新庞大的大型模型(比如这里的 GPT-J-6B)。
论文标题:
MELO: Enhancing Model Editing with Neuron-Indexed Dynamic LoRA
论文链接:
https://arxiv.org/abs/2312.11795
目前的大模型知识编辑方法在持续知识编辑场景无法同时兼顾所有评估指标(Edit Success,Locality,Generality,Sequential Editing,Efficiency)的性能。本文提出一种新方法 MELO,该方法通过动态激活 LoRA 块来编辑模型,并且采用了非重叠的 LoRA 块进行训练,缓解了之前知识编辑中存在的灾难性遗忘问题。
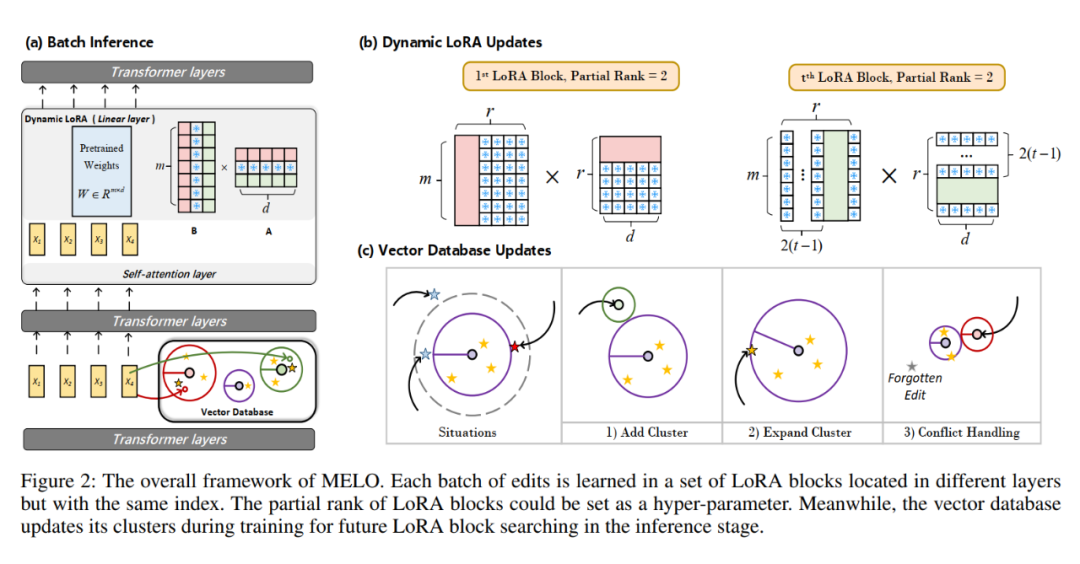
实验结果如下:
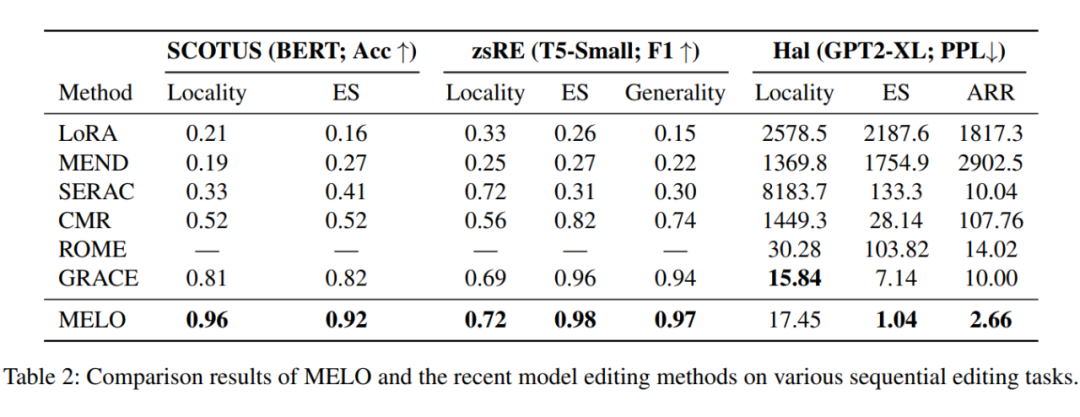
本文提出未来可以探索更有效的神经索引向量数据库,并将 MELO 扩展到更多的场景,如多模态大模型知识编辑。
论文标题:
WilKE: Wise-Layer Knowledge Editor for Lifelong Knowledge Editing
论文链接:
https://arxiv.org/abs/2402.10987
以往的方法主要关注单次编辑(如下图(a)所示),本文致力于解决持续知识编辑(如下图(b)所示)。

以往的方法经过在持续知识编辑的设置下会引发巨大的副作用(本文称为毒性),如下图所示:
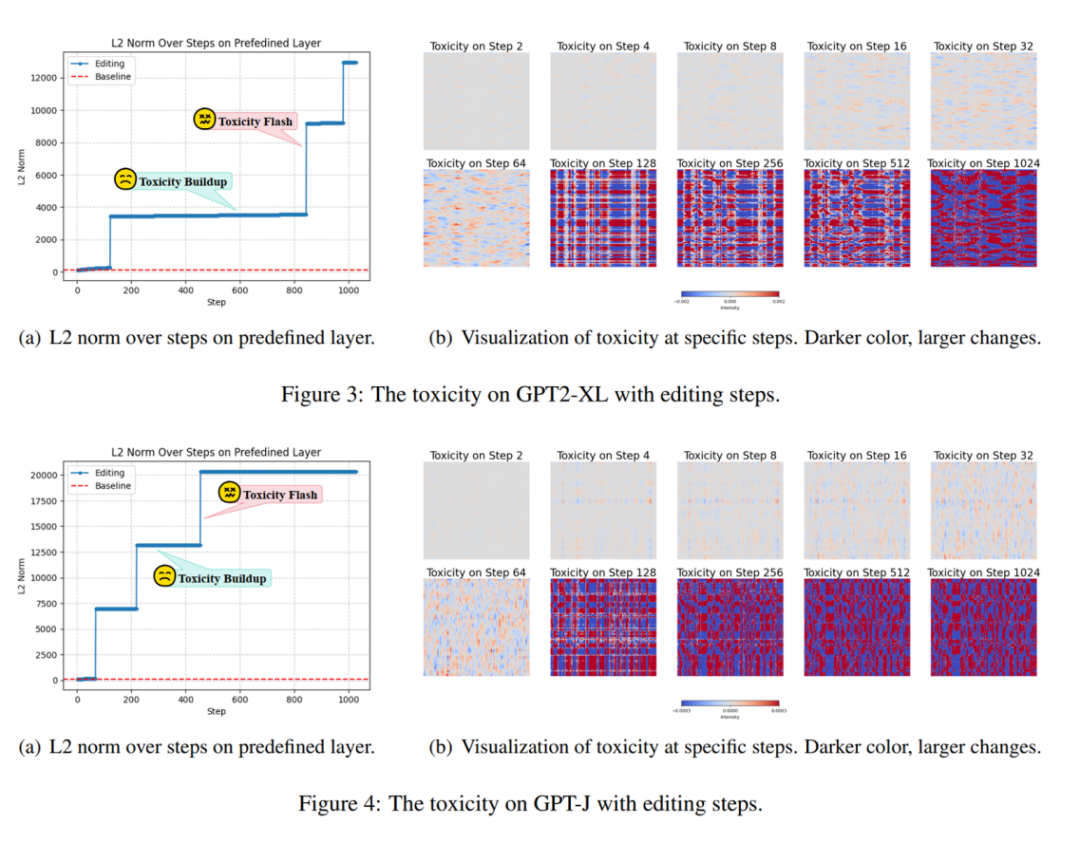
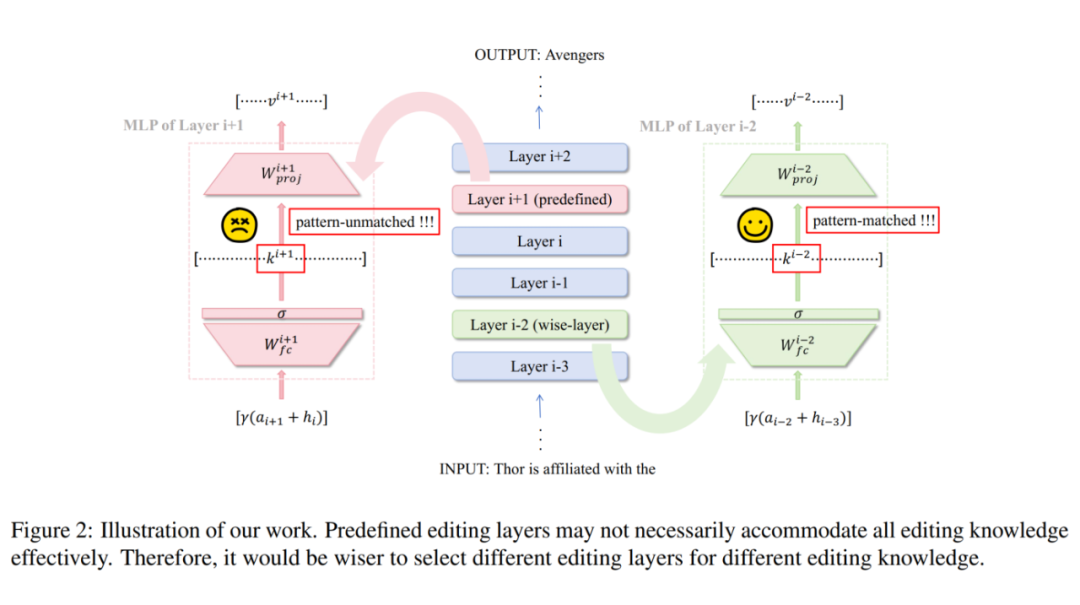
本文猜测持续知识编辑引发巨大副作用的原因如下:以往的 ROME 和 MEMIT 都是采用了预定义的层去执行模型编辑,然而不同的知识存储在不同的层中。
因此本文提出了一个新方法 WilKE,该方法首先找到存储特定知识的层,然后直接修改该层的参数。整体流程如下图所示。具体来说,存储特定知识的层是为该知识产生最大激活强度的层。随后采用 ROME 的方法编辑该层参数。
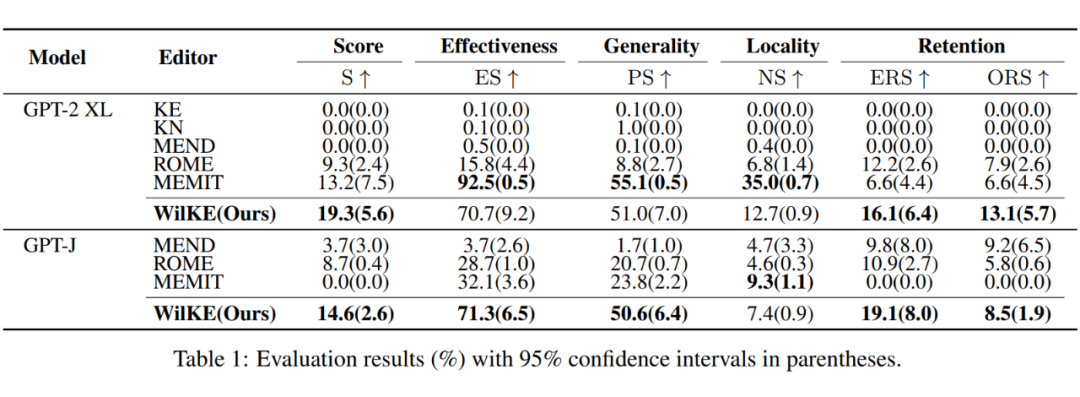
实验结果如下表,与目前流行的大模型知识编辑方法相比,WilKE 在终身编辑中实现了显著的整体性能提升。
论文标题:
Consecutive Model Editing with Batch alongside HooK Layers
论文链接:
https://arxiv.org/abs/2403.05330
本文提出了 COMEBA-HK, 是一种新型的大模型知识编辑方法,旨在解决大模型更新耗时且资源密集的问题。该方法支持连续和批量知识编辑,且对内存友好,因为它只需要存储几个大小不变的钩子层(Hook Layers)的内存。COMEBA-HK 不需要额外的训练或大型外部存储来存储编辑实例,它通过优化钩子层中的权重来实现模型行为的直接编辑。
1. 连续和批量支持:COMEBA-HK 能够在一系列连续的步骤中进行批量编辑,而不需要在每个编辑步骤后将模型重置回初始状态。
2. 内存效率:该方法只需要少量内存来存储钩子层,这些层的大小在编辑过程中保持不变。
3. 无需额外训练:与需要训练元网络或分类器的方法不同,COMEBA-HK 不需要这些额外的训练步骤。
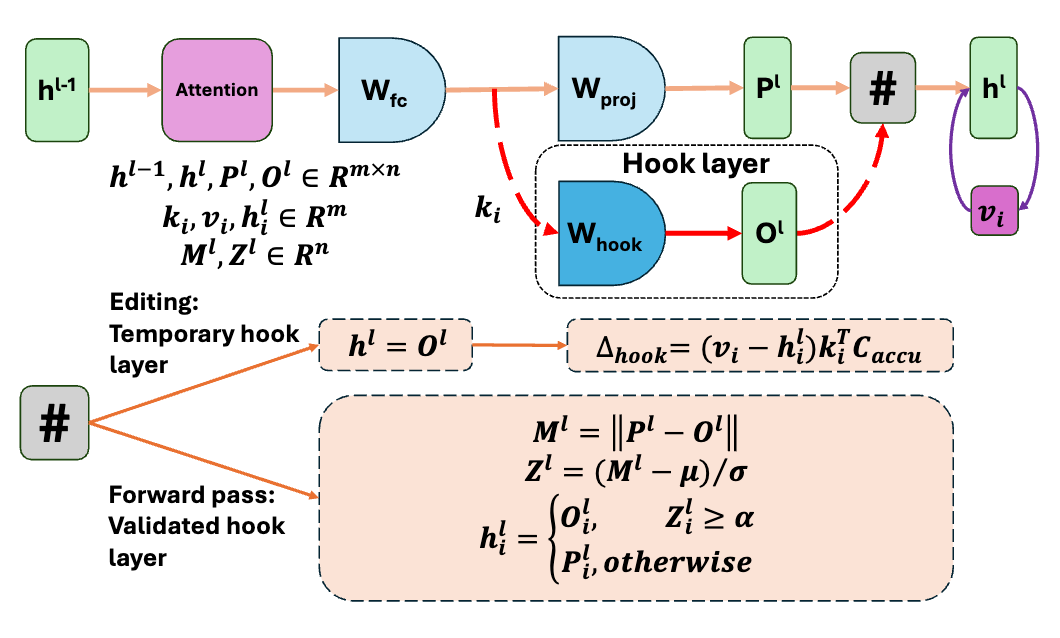
编辑机制:
COMEBA-HK 通过扩展单层编辑机制来支持连续编辑,并引入了钩子层来分离权重变化,从而避免了对原始模型权重的直接修改。
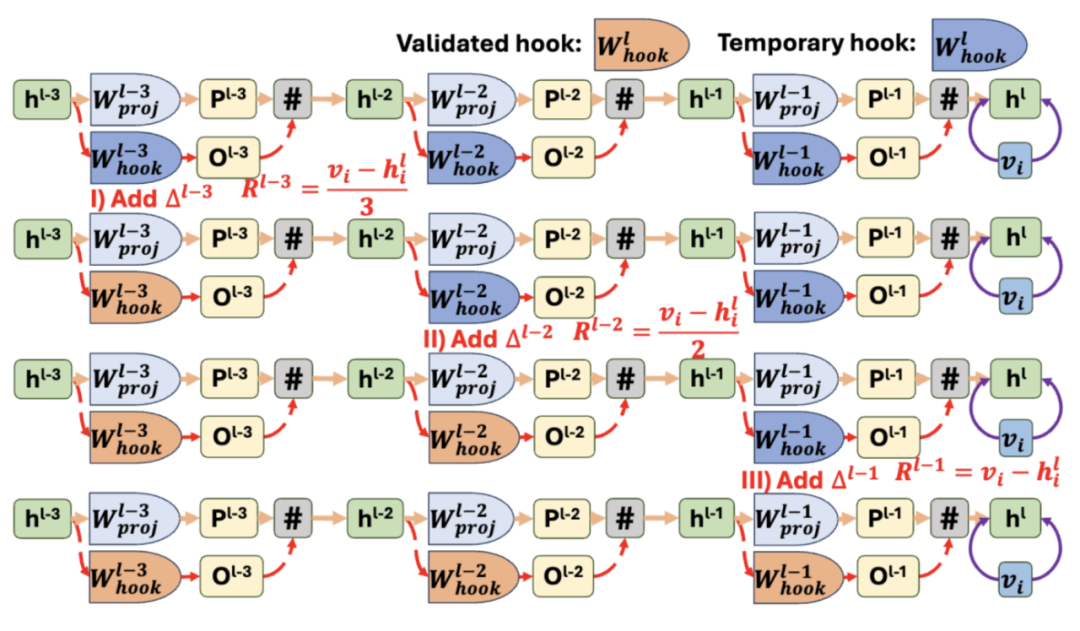
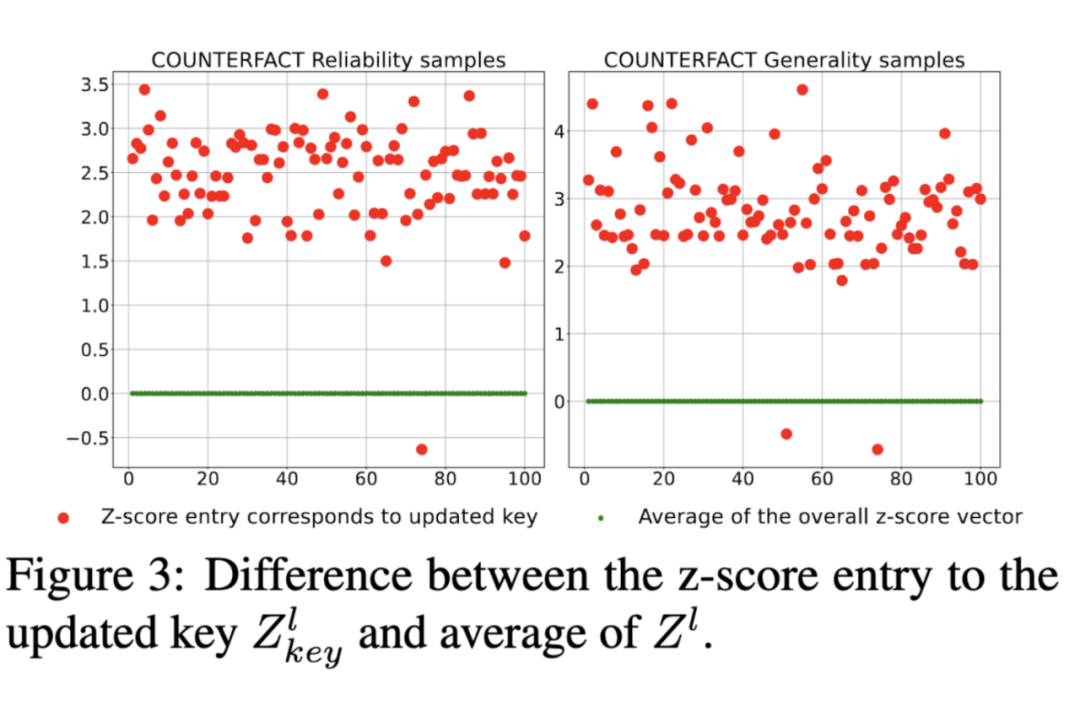
该方法使用一个新设计的变换器内存更新机制,以及一个简单但有效的局部编辑范围识别技术,用于钩子层中精确检测输入的局部编辑范围。如下图所示,几乎所有来自更新密钥的响应的 z 分数都与平均值有很大差距,可靠性样本中最低约为 1.5,一般性样本中最低为 2。
实验结果:
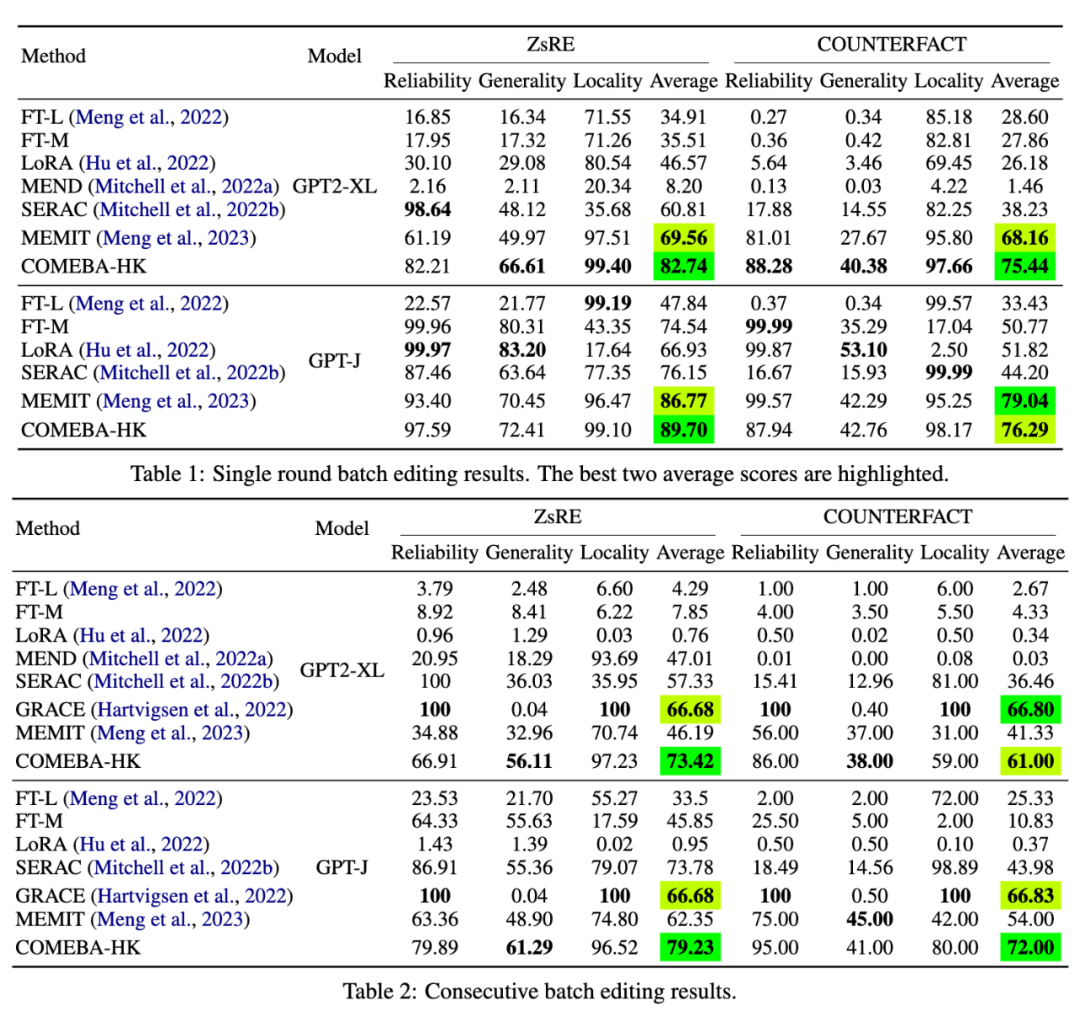
COMEBA-HK 在单轮和连续批量知识编辑场景下展现出了优越性。实验结果表明,COMEBA-HK 在多个指标上超越了现有技术,尤其是在连续编辑步骤和编辑实例数量上的稳定性。COMEBA-HK 适用于需要对模型进行定制化、成本效益高且连续编辑的场景,如文本生成、问答、推理等领域。
论文标题:
Stable Knowledge Editing in Large Language Models
论文链接:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2558
2558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









