










23年10月来自维吉尼亚大学的综述论文“Knowledge Editing for Large Language Models: A Survey“。
大语言模型(LLM)最近改变了学术界和工业界的格局,基于丰富的知识和推理能力其具有理解、分析和生成文本能力。然而,LLM的一个主要缺点是,由于其超大的参数数量,其预训练的计算成本巨大。当需要将新知识引入预训练模型时,这种劣势会加剧。因此,必须开发有效和高效的技术来更新预训练LLM。传统方法通过直接微调将新知识编码在预训练的LLM中。然而,天真地重新训练LLM可能是计算密集型的任务,并且有可能是模型更新无关的预训练知识造成退化的风险。最近,基于知识的模型编辑(KME)引起了越来越多的关注,其目的是精确地修改LLM去包含特定知识,不会对其他无关知识产生负面影响。本文旨在全面深入地概述KME领域的最新进展。首先介绍KME的一般公式,包含不同的KME策略。之后,基于如何将新知识引入预训练LLM,提供KME技术的分类,并研究现有的KME策略,同时分析每个类别方法的关键见解、优势和局限性。此外,还相应地介绍了KME的代表性度量、数据集和应用。最后,对KME的实用性和挑战进行了深入分析,并为该领域的进一步发展提出有前景的研究方向。
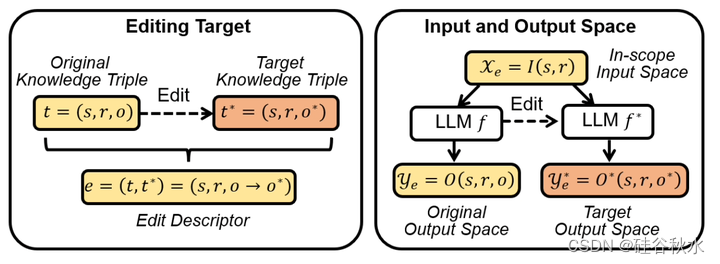
KME旨在精确修改预训练的LLM行为,更新特定知识,不会对与更新无关的其他预训练知识产生负面影响[85,111,119]。在KME中,LLM中特定知识的更新通常被表述为编辑,例如将“谁是美国总统?”的答案从“特朗普”更正为“拜登”。关于特定的编辑,KME策略通常将辅助网络(或参数集)引入预训练的模型[41,63,124]或更新(部分)参数以存储新知识,这样修改模型输出[16,39,40,64]。通过这些策略,KME技术可以将新知识存在内存中,或者将其在定位在模型参数中进行更新,从而将知识精确地注入模型中。此外,某些方法还引入了显式损失来包含更新过程,使得编辑后的模型在未修改的知识上保持一致的行为。有了这些优势,KME技术可以提供一种高效有用的方法,在没有明确的模型重训练情况下,用新知识不断更新LLM。
尽管KME与微调策略有一定的相似之处,但它在更新LLM方面具有独特的优势,值得深入研究。特别是,KME和模型微调都试图通过注入新知识来更新预训练的LLM。然而,除了这个共同的目标之外,KME更多地关注两个无法通过微调轻易解决的关键特性。(1) 局部性要求编辑后的模型不会无意中影响其他无关的具有不同语义输入的输出。例如,当更新关于美国总统的编辑时,编辑后的模型不应改变其对英国首相的了解。KME方法的实用性在很大程度上取决于它们维护不相关输入输出的能力,这是KME和微调之间的主要区别[86]。(2) 泛化性表示编辑后的模型是否可以泛化到与编辑后的知识所有关的更广泛相关输入。具体来说,它表明了模型在具有语义相似性的输入上呈现一致行为的能力。例如,当编辑关于总统的模型时,总统配偶的查询答案也应相应更改。在实践中,KME方法必须确保编辑后的模型能够很好地适应这些相关的输入文本。总之,由于这两个独特的目标,KME仍然是一项具有挑战性的任务,需要具体的策略才能达到令人满意的效果。
模型编辑是一种特殊类型的模型修改策略,修改应尽可能精确。然而,它应该准确地将预训练模型修改去编码特定的知识,同时最大限度地保留现有知识,而不影响它们在不相关输入上的行为[49]。Bau[7]首次在计算机视觉领域进行了探索。将中间层视为线性存储器,研究编辑生成对抗性网络(GAN)的潜力[37],该存储器可以被操纵,包含新颖的内容。之后,提出了可编辑训练[99],鼓励以模型不可知的方式快速编辑训练后的模型。目标是改变错误分类目标相对应的输入子集模型预测,而不改变其他输入的结果。在[94]中,作者提出了一种方法,允许通过编辑分类器的决策规则来修改分类器的行为,该方法可用于纠正错误或减少模型预测中的偏差。在自然语言处理领域,已经提出了几项工作[16,75]来执行关于文本信息的编辑。具体而言,Zhu[125]提出了一种受约束的微调损失,明确修改基于Transformer模型中的特定事实知识[107]。最近的工作[34,35]发现,Transformer中的MLP层实际上充当Key- Value存储器,从而能够编辑相应层中的特定知识。
LLM的KME任务可以广义地定义为精确修改预训练LLM行为的过程,这样可以引入新的知识来保持LLM当前性和相关性,不会对其他与编辑无关的预训练知识产生负面影响。整个过程如图所示。
面对旧信息的快速弃用和新知识的出现,已经提出了各种KME方法来更新预训练的LLM,保持其更新性和相关性。KME确保新知识可以有效地融入到预训练的LLM中,不会对与编辑无关的预训练知识产生负面影响。KME方法的分类如图所示,其方法在4个测度(局部性、泛化性、保持性和尺度性)下的比较如下表所示。
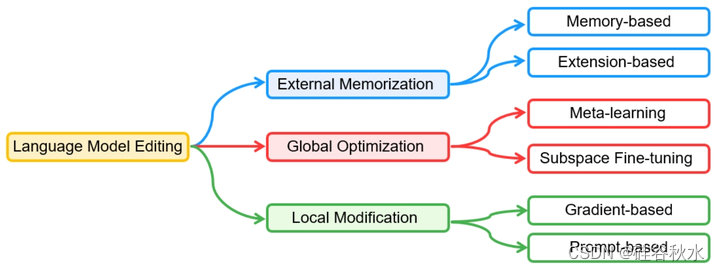
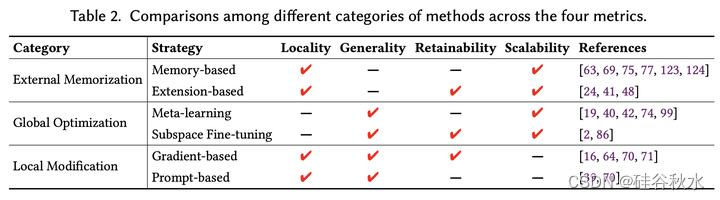
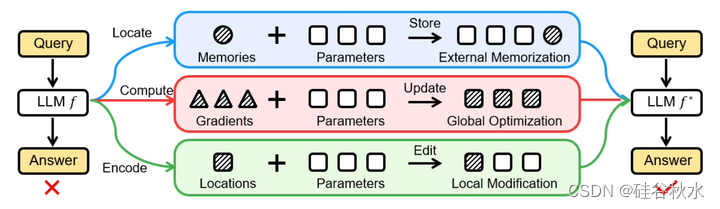
基于外部记忆的方法,利用外部存储器来存储新知识进行编辑,无需修改预训练的权重,其中预训练知识可以完全保留在LLM权重中。通过用外部参数存储新知识,基于记忆的策略能够以良好的可扩展性精确地表示新知识,因为存储器很容易扩展以包含新知识。
基于全局优化的方法,寻求在新知识的指导下进行优化,将新知识普遍纳入预训练的LLM,其中引入了量身定制的策略来限制其他预训练知识的影响,与天真的微调区分开来。然而,当应用于LLM时,这些方法可能在编辑效率方面达不到要求,因为需要优化大量参数。
基于局部修整的方法,旨在定位LLM中特定知识的相关参数,并对其进行相应更新,纳入与编辑相关的新知识。局部修整的主要优点是可以只更新一小部分模型参数,从而与基于记忆的方法相比提供了相当大的存储效率,与全局优化相比提供了计算效率。
如图是三种KME方法的示意图:
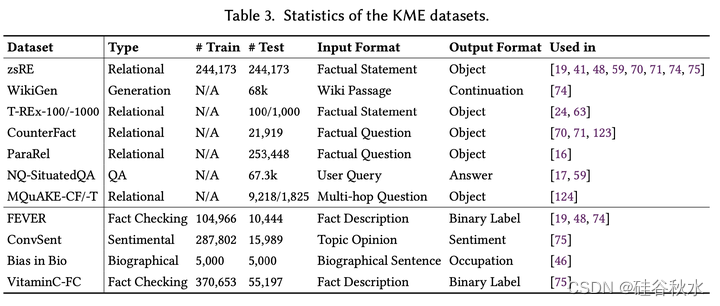
最近,已经建立了多个数据集来促进KME方法的评估。如表总结常用的数据集。具体来说,这些数据集可以分为两组:文本输出数据集(即生成任务)和分类输出数据集。数据集来自各种来源,包括知识图、维基百科页面、众包回复等,对这些进行调整,可适应不同KME的设置。
下表是KME的不同下游应用示例:问答(QA)、事实核查(FC)和自然语言生成(NLG)。
















 70
70

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









