







©作者 | 赵博
单位 | 加州大学圣地亚哥分校
来源 | 机器之心
众多神经网络模型中都会有一个有趣的现象:不同的参数值可以得到相同的损失值。这种现象可以通过参数空间对称性来解释,即某些参数的变换不会影响损失函数的结果。基于这一发现,传送算法(teleportation)被设计出来,它利用这些对称变换来加速寻找最优参数的过程。尽管传送算法在实践中表现出了加速优化的潜力,但其背后的确切机制尚不清楚。
近日,来自加州大学圣地亚哥分校、Flatiron Institute、美国东北大学等机构的研究人员发布的《Improving Convergence and Generalization Using Parameter Symmetries》论文中,展示了传送不仅能在短期内加快优化过程,而且能总体上缩短收敛时间。
此外,研究还发现,传送到具有不同曲率的最小值可以改善模型的泛化能力,这意味着最小值的曲率与泛化能力之间存在联系。研究者们进一步将传送技术与多种优化算法以及基于优化的元学习相结合,这些结果充分展示了在优化过程中融入参数空间对称性的潜力。

论文链接:
https://openreview.net/forum?id=L0r0GphlIL
代码链接:
https://github.com/Rose-STL-Lab/Teleportation-Optimization
作者主页:
https://b-zhao.github.io/

背景:对称性和传送算法
参数空间对称性(parameter space symmetry)是群 G 在参数空间(Param)上的一个作用,该作用使得损失函数 L 的值保持不变:
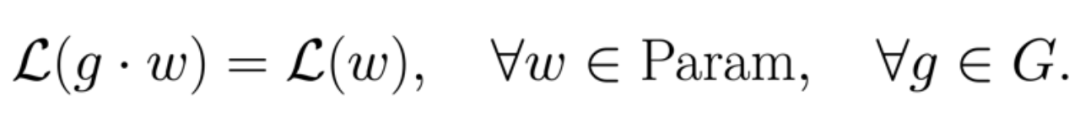
对称传送算法(symmetry teleportation)在损失函数水平集中寻找更陡峭的点以加速梯度下降:
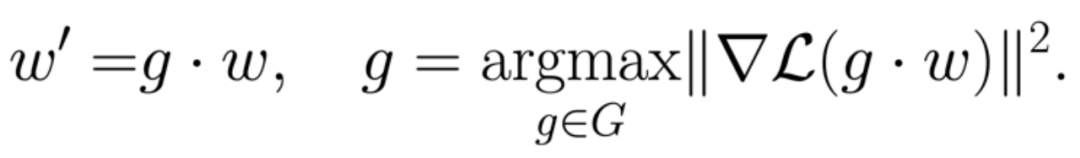
传送后,损失值不会改变。然而,梯度和之后的训练轨迹会有所不同。
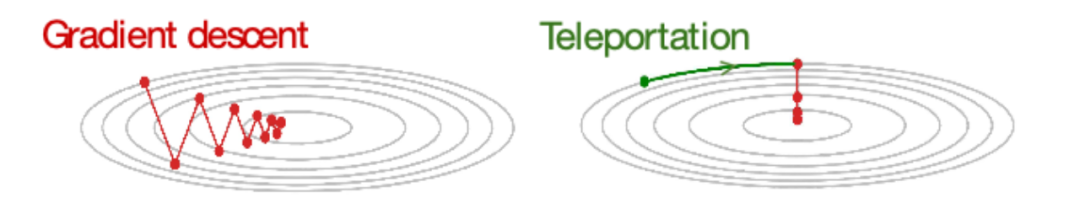

传送对收敛速度的提高
论文第一部分提供了对传送提高收敛速度的理论证明。
通过传送,随机梯度下降(SGD)会收敛到一个包含多个静止点的盆地,其中通过传送可达的每个点都是静止的。图 1 中的定理提供了损失函数梯度期望值的上限。相比之下,普通 SGD 只能保证存在一个点 wt,使得梯度最终会很小。加入传送后,对于群作用轨道上所有的点,梯度都将很小。

▲ 图1. 该定理提供了损失函数梯度期望值的上限
此外,在进行一次传送后,梯度下降的方向与牛顿法(Newton’s method)方向相同。因此,收敛速度具有一个二次收缩项,这是二阶方法的典型特征。相反,如果在相同的假设下省略传送步骤,算法的收敛速度将仅呈现线性收敛。图 2 中的定理展示了传送导致的线性和二次收敛的混合。

▲ 图2. 该定理展示了传送导致的线性和二次收敛的混合

通过传送改善泛化能力
在探索机器学习模型优化的过程中,「传送」这一概念最初被提出是为了加速收敛并提高算法的效率。然而,在该论文的第二部分,研究者们将视野扩展到了一个新的目标 —— 提升模型的泛化能力。
泛化能力通常与模型在训练过程中达到的极小值的「锐度」(sharpness) 相关。为了深入理解这一点,研究者们引入了一个新的概念 ——「极小值曲率」(curvature),并讨论其对泛化的影响。通过观察极小值的锐度、曲率与泛化能力之间的关联,研究者们提出了一种新的方法,将锐度和曲率纳入传送的目标中来提升模型的泛化性能。
图 3 通过可视化的方式展示了一个梯度流 L (w) 和一条极小值上的曲线(γ),这两条曲线的曲率对应着极小值的锐度和曲率。此外,表中还显示了测试集上的损失与锐度或曲率之间的 Pearson 相关性。在三个数据集中,锐度与验证损失呈强正相关,而极小值的曲率则与验证损失呈负相关。这些发现表明,具有较小锐度或较大曲率的极小值,可能会带来更好的泛化效果。
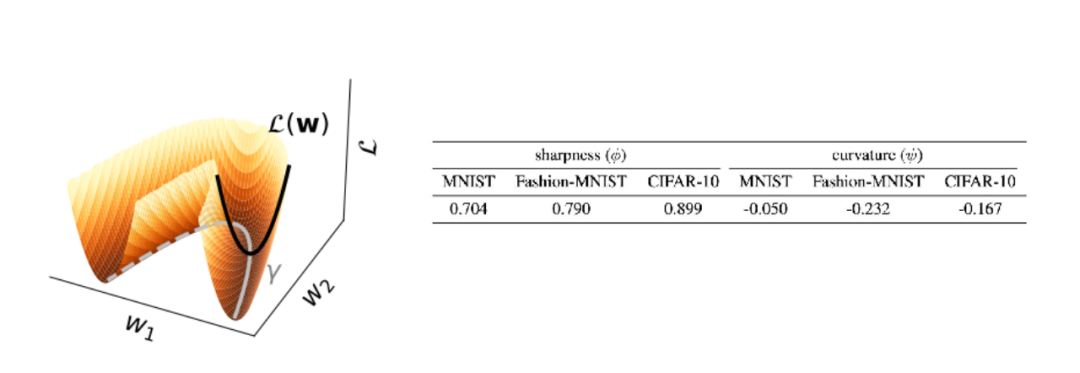
▲ 图3. 展示了一个梯度流L (w)和一条极小值上的曲线 (γ)
这些相关性的一种解释来源于损失地形(loss landscape)在不同数据分布上的变化。当数据分布发生变化导致损失地形变化时,尖锐的极小值损失增加较大(如图 4 右侧所示)。在图 4 中,曲率较大的极小值与变化后的极小值距离更远(如图 4 左侧所示)。
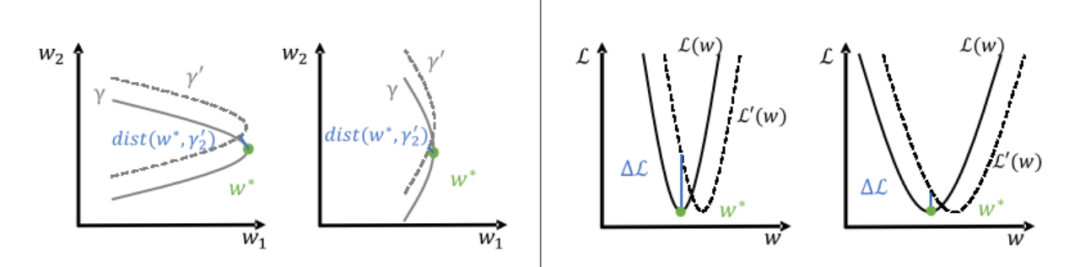
▲ 图4
取得了极小值的属性与泛化能力的相关性后,该研究人员将参数传送到具有不同锐度和曲率的区域,以提高模型的泛化能力。图 5 为在 CIFAR-10 上 SGD 的训练曲线,其中在第 20 个 epoch 进行了一次传送。实线代表平均测试损失,虚线代表平均训练损失。
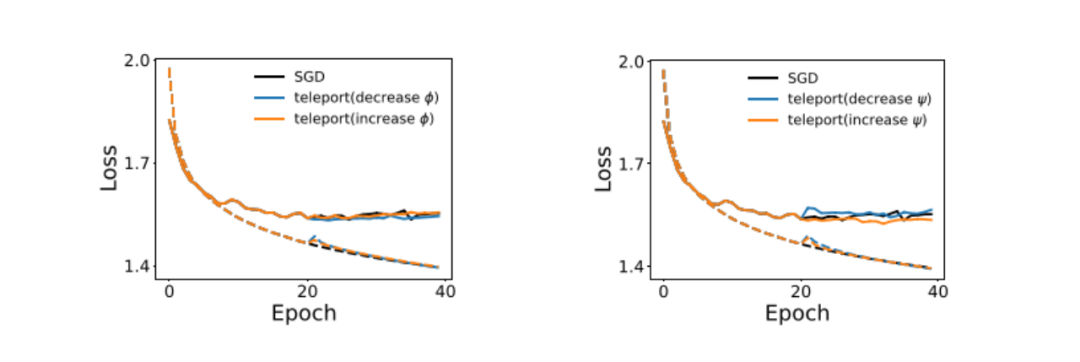
▲ 图5
传送到更平坦的点略微改善了验证损失。通过传送改变曲率对泛化能力有更显著的影响。传送到曲率较大的点有助于找到具有较低验证损失的极小值,而传送到曲率较小的点则产生相反的效果。这表明至少在局部,曲率与泛化相关。

传送和其他优化器的结合
标准优化器
传送不仅有助于 SGD 的收敛速度。为了展示传送与其他标准优化器的良好兼容性,研究者们使用不同的优化器在 MNIST 上训练了一个三层神经网络,并进行了带传送和不带传送的训练。如图 6 所示,在使用 AdaGrad、带动量的 SGD、RMSProp 和 Adam 时,传送提高了这些算法的收敛速度。
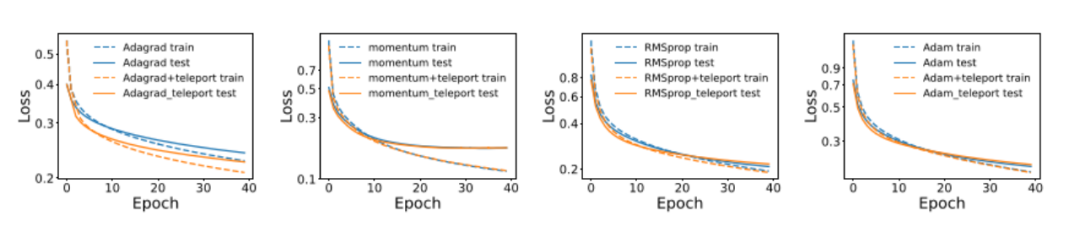
▲ 图6. 在使用 AdaGrad、带动量的 SGD、RMSProp 和 Adam 时,传送提高了这些算法的收敛速度
学习传送
受条件编程(conditional programming)和基于优化的元学习(meta-learning)的启发,研究者们还提出了一个元优化器,用于学习在损失水平集中移动参数的位置。这种方法避免了在群流形上优化的计算成本,并改进了现有的仅限于局部更新的元学习方法。
图 7 总结了训练算法。研究人员使用了两个 LSTM 元优化器 (m1, m2) 来学习局部更新 ft 和传送中使用的群元素 gt。在两层 LeakyReLU 神经网络上的实验中,他们使用了不同初始化创建的多个梯度下降轨迹上训练元优化器,并在训练中未见过的新初始值上测试收敛速度。

▲ 图7. 总结了训练算法
与基线相比,同时学习两种更新类型(LSTM (update,tele))比单独学习它们(LSTM (update) 、LSTM (lr,tele))能够实现更好的收敛速率。

总结
该论文的主要贡献包括传送加速 SGD 收敛的理论保证、极小值曲率的量化及其与泛化相关性的证据、基于传送的改善泛化的算法以及学习传送位置的元学习算法。
传送广泛适用于在损失水平集中搜索具有优秀属性的参数。对称性与优化之间的密切关系开启了许多激动人心的机会。探索传送中的其他目标是一个有潜力的未来方向。其他可能的应用包括将传送扩展到不同的架构,如卷积或图神经网络,以及不同的算法,如基于采样的优化。
关于作者
About the Author
本论文作者赵博是加州大学圣地亚哥分校的三年级在读博士,其导师为 Rose Yu。她的主要研究方向为神经网络参数空间中的对称性,及其对优化、泛化和损失函数地貌的影响。她曾获 DeepMind 奖学金,并且是高通创新奖学金的决赛入围者。邮箱:bozhao@ucsd.edu
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·















 7572
7572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









