







时隔 1 个月,面壁小钢炮 MiniCPM 系列上新,带来 MiniCPM-Llama3-V 2.5 8B,最强端侧多模态模型。
小钢炮系列通过一系列自研技术,所开创的高清图像识别(1344*1344 分辨率)、强大的 OCR 能力等,本次仍得到了延续。
8B 体量的新一代 MiniCPM-Llama3-V 2.5,仍带来一系列惊艳亮点。
最强端侧多模态综合性能:超越多模态巨无霸 Gemini Pro 、GPT-4V
OCR 能力 SOTA!180 万像素更清晰,难图长图长文本精准识别
量化后仅 8G 显存,4070 显卡轻松推理,并可在手机端以 6-8Tokens/s 速度高效运行;
图像编码快 150 倍!首次端侧系统级多模态加速;
支持 30+ 多种语言
MiniCPM-Llama3-V 2.5 发布后火速登顶 HuggingFace 热度榜 Top2,与 Meta、微软、谷歌等科技巨头共同从全球 66 万模型中脱颖而出。
当前 MiniCPM-V 系列下载总量已超 13 万,GitHub 星标 2K+。
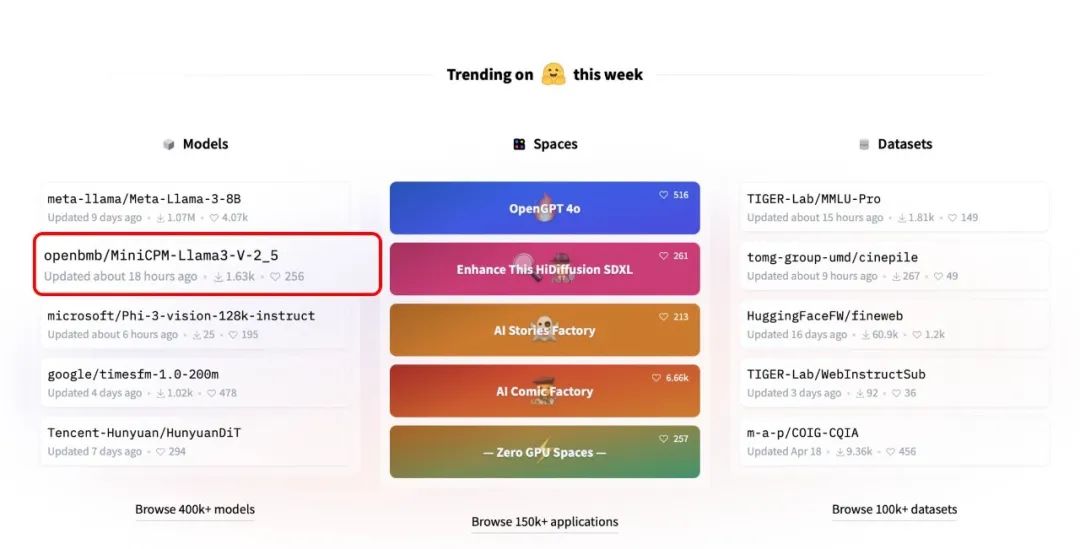
▲ 新版本MiniCPM-V小钢炮再次登顶Hugging Face趋势榜单Top2
作者:
姚远、余天予、张傲、王崇屹、崔竣博、朱宏吉、蔡天驰、赵威霖、周荣华、何志辉、邹振盛、张皓烨、胡声鼎、郑直、周界、蔡杰、韩旭、曾国洋、李大海、刘知远、孙茂松*
单位:
面壁智能,清华大学自然语言处理实验室
项目地址:
https://github.com/OpenBMB/MiniCPM-V
模型地址:
https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5
模型地址:
https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5
演示Demo:
http://120.92.209.146:8889/

简介
自 OpenAI 发布 GPT-4V 以来,多模态大语言模型技术经历了飞速发展,模型性能日新月异。随着开源社区的高速发展,模型性能及参数规模出现了一种类似于摩尔定律的发展趋势(如图 1):达到 GPT-4V 水平的模型参数规模随时间增长逐渐缩减。这也许可以称其为多模态大模型时代的摩尔定律。

▲ 图1. GPT-4V级别模型参数规模逐渐缩小,终端算力逐渐增强
与此同时,手机电脑等终端算力也在不断增强。两个趋势的叠加使得多模态大模型正在全面走向端侧,带来了了更广阔的想象空间并可能惠及更多应用场景。借助高效多模态训练技术,MiniCPM-V 系列发布了全新的 MiniCPM-Llama3-V 2.5。沿着多模态大模型摩尔定律的轨迹,MiniCPM-Llama3-V 2.5 将之前 GPT-4V 级别能力的开源模型大小由 26B 刷新到了 8B。通过一系列终端优化技术,MiniCPM-Llama3-V 2.5 首次在端侧实现了 GPT-4V 级的多模态能力。

效果展示
MiniCPM-Llama3-V 2.5 总共包括以下几个亮点能力:
1)领先的性能:MiniCPM-Llama3-V 2.5 以 8B 量级的大小超过了 GPT-4V-1106、Gemini Pro 等主流商用闭源多模态大模型。
2)优秀的 OCR 能力:OCRBench 得分达到 725,超越 GPT-4o、GPT-4V、Gemini Pro、Qwen-VL-Max 等商用闭源模型,达到最佳水平。
3)多语言支持:模型支持了德语、法语、西班牙语、意大利语、俄语等 30+ 种语言的多模态能力,并表现出了良好的多语言多模态对话性能。
4)可信行为:在 Object HalBench 的幻觉率降低到了 10.3%,显著低于 GPT-4V-1106 (13.6%),达到开源社区最佳水平。
5)高效部署:通过模型量化、CPU、NPU、编译优化等高效加速技术,实现高效的终端设备部署。
下面将通过一些具体示例来展示 MiniCPM-Llama3-V 2.5 的具体能力。
首先,MiniCPM-Llama3-V 2.5 具有良好的 OCR 能力,可以对英文文章截图进行内容提取:

▲ 图2:中文长图理解样例
MiniCPM-Llama3-V 2.5 能够理解非常规长宽比的图像输入,可以对手机文章的长截图进行总结:

▲ 图3:中文长图理解样例
同时,MiniCPM-Llama3-V 2.5 可以将密集表格数据转化为对应的 markdown 形式:
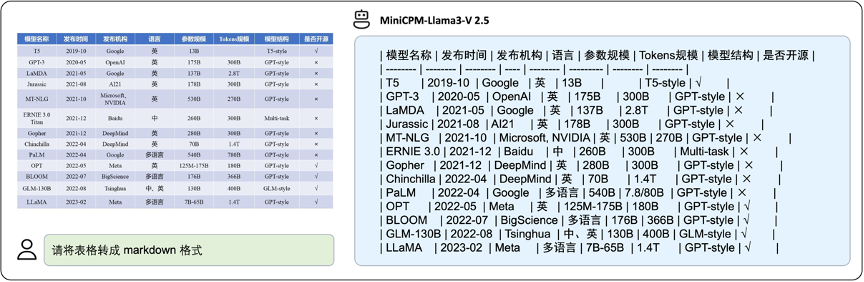
▲ 图4:中文表格转markdown样例
此外,MiniCPM-Llama3-V 2.5 可以理解复杂的流程图输入并进行分点解释:
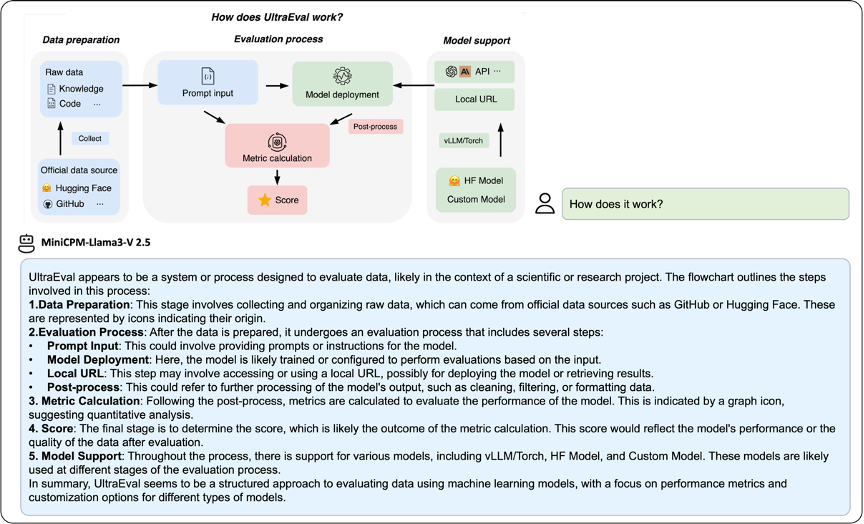
▲ 图5:英文复杂推理样例
为了更好的展示效果,MiniCPM-Llama3-V 2.5 提供了一些小米 14 Pro 上的录屏样例:
比如,MiniCPM-Llama3-V 2.5 可以针对输入的食物营养结构图片进行分析,并根据内容进行复杂饮食计划的设计:

▲ 图6:英文复杂推理实时样例 (2倍速播放)
下面是对高铁车票进行信息提取和相关提问:

▲ 图7:中文OCR实时样例 (2倍速播放)
最后,MiniCPM-Llama3-V 2.5 具有良好的多语言对话能力:
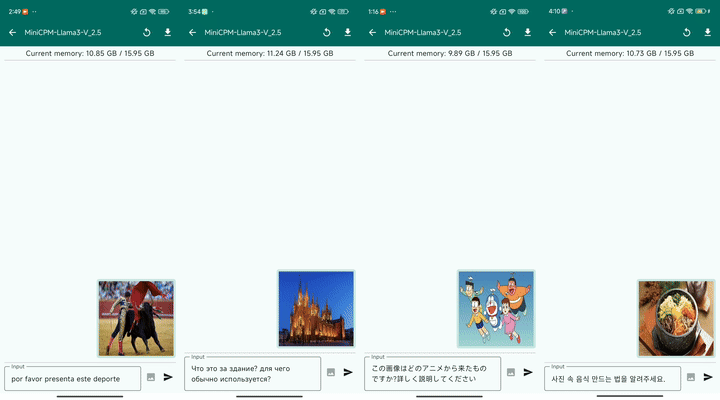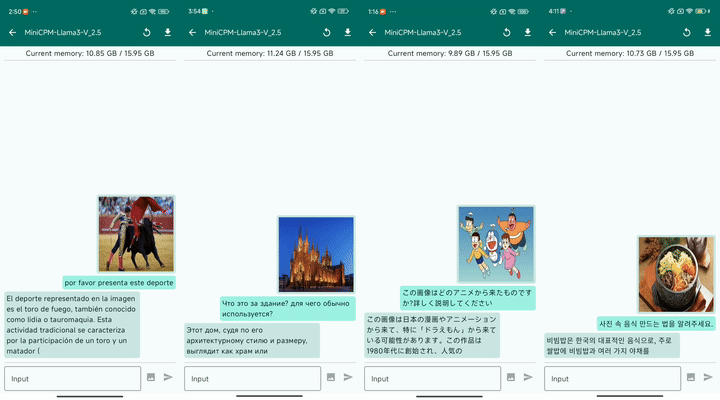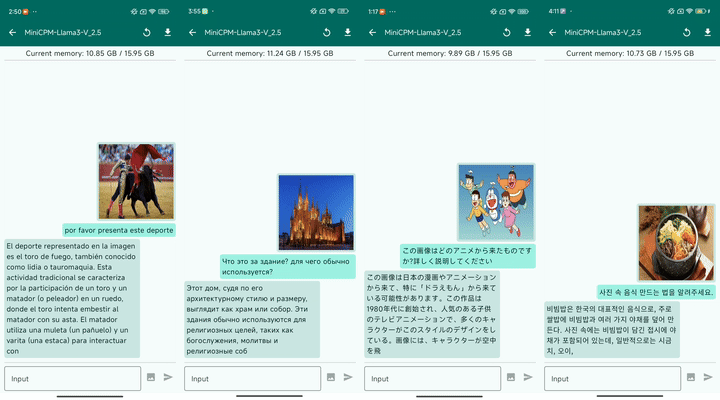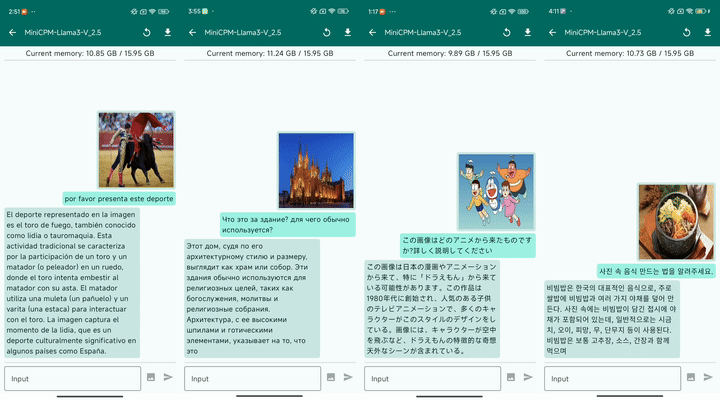
▲ 图8:多语言对话样例 (2倍速播放)

实验结果
1. 多模态基础能力评测

▲ 表1:主流多模态基准下的评测结果
MiniCPM-Llama3-V 2.5 首先在一系列主流多模态数据集上进行了效果对比 (表 1)。其中 OpenCompass 分数为 MME、MMB、MMMU 等 11 个主流多模态数据集的综合指标,可以作为总评价指标。
在表 1 中,MiniCPM-Llama3-V 2.5 取得了最高的 OpenCompass 分数 65.1。该结果超过了闭源模型 Gemini Pro 和 GPT-4V (2023.11.06)。
此外,通过对比 MiniCPM-Llama3-V 2.5 和其他 3 个基于 Llama-3 8B 的开源模型,MiniCPM-Llama3-V 2.5 显示出明显的效果优势。以代表性模型 LLaVA-NeXT Llama-3 8B 为例,MiniCPM-Llama3-V 2.5 在各评测基准均实现 3 个点以上提升。值得注意的是,MiniCPM-Llama3-V 2.5 同时具有更高的推理效率。其视觉编码结果数量范围为 96-960 tokens,小于 LLaVA-NeXT Llama-3 8B 的编码结果数量范围 1728-2880 tokens,大幅降低了计算开销。
2. OCR能力评测
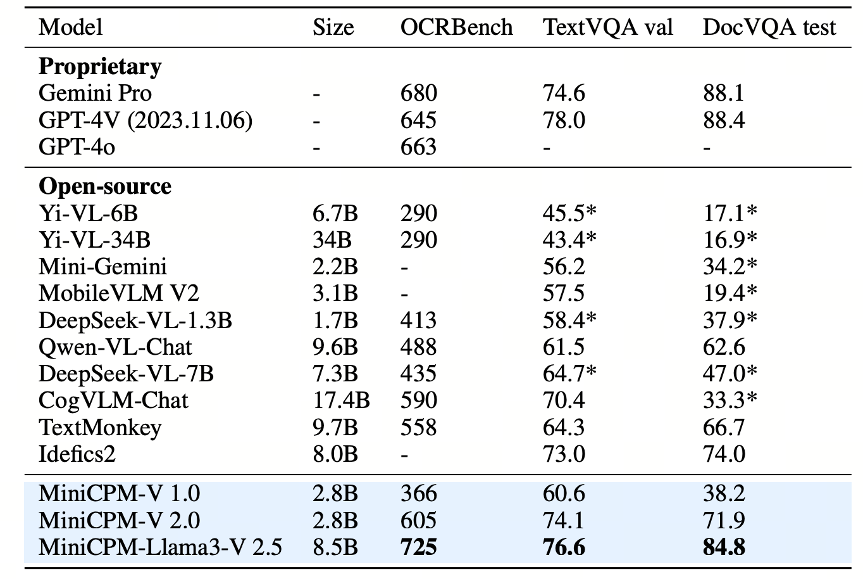
▲ 表2:OCR能力基准的评测结果
此外,MiniCPM-Llama3-V 2.5 也具有良好的场景文字理解能力。根据表 2 结果,MiniCPM-Llama3-V 2.5 可以取得最优的 OCRBench 效果,并在 TextVQA 和 DocVQA 上取得和 Gemini Pro、GPT-4V 有竞争力的结果。
3. 多语言能力评测
如图 9,相较于 Yi-VL-34B,MiniCPM-Llama3-V 2.5 展示出了较优的多语言对话效果:

▲ 图9:多语言LLaVABench评测结果

终端优化

▲ 图10:手机芯片视觉编码效率(448*448图片输入)和部署框架
不同于云端服务器,手机等终端设备的大模型部署往往受限于有限的内存(如 12-16GB)和更慢的芯片处理速度(如 8 核 CPU)。为了更流畅的手机多模态大模型体验,MiniCPM-Llama3-V 2.5 较为系统地通过模型量化、CPU、NPU、编译优化等高效加速技术,实现高效的终端设备部署。
如图 10 所示,CPU 是当前手机设备最普及的芯片类型。为保证兼容性,MiniCPM-Llama3-V 2.5 主要使用 CPU 进行语言模型部分部署。通过 4 比特量化和 llama.cpp 框架的配合,MiniCPM-Llama3-V 2.5 实现了每秒 8-9 tokens 的语言模型编码速度和每秒 3-4 tokens 的解码速度。
然而,当前手机端多模态大模型部署的图像编码方案依然非常具有挑战性。如果不采取任何优化,一张 448*448 分辨率图片编码通常需要 45s 处理时间。通过手机端编译优化、显存整理等一系列优化方式,MiniCPM-Llama3-V 2.5 将 CPU 编码延迟降低到了 5s 左右。对于高通芯片的移动手机,MiniCPM-Llama3-V 2.5 首次将 NPU 加速框架 QNN 整合进了 llama.cpp。经过系统优化后,MiniCPM-Llama3-V 2.5 实现了多模态大模型端侧图像编码 150 倍加速的显著提升(45s -> 0.3s)。
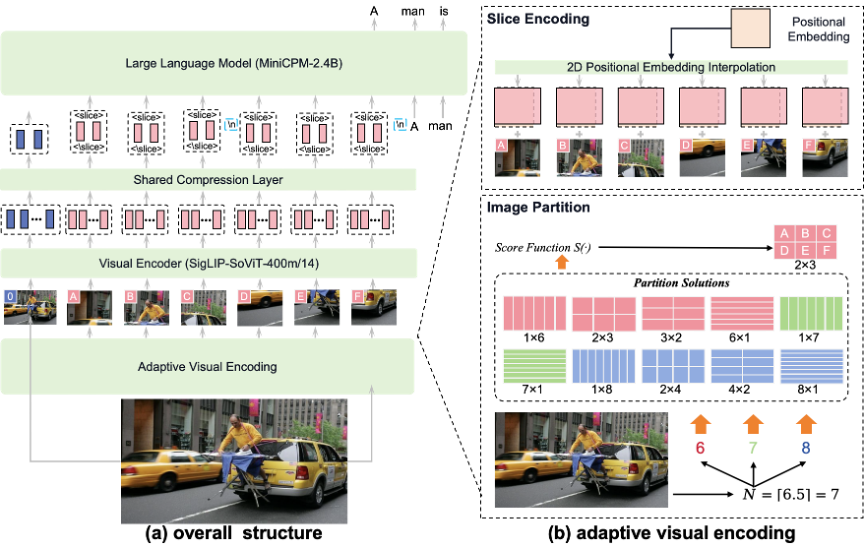
▲ 图11:模型架构及视觉编码

模型构建
MiniCPM-Llama3-V 2.5 的模型架构和训练方式概括如下文所示。
1. 模型构架
如图 11,MiniCPM-Llama3-V 2.5 的模型总共包含了 3 个组成部分:(1) 视觉编码器:SigLIP-400M;(2) 压缩层:perceiver resampler结构;(3) 语言模型:Llama-3 8B。
其中,为了应对输入图片的高分辨率和变长宽比问题,MiniCPM-Llama3-V 2.5 采用了 LLaVA-UHD 论文提出的自适应视觉编码方法。每张输入图片会首先根据其大小和长宽比计算最优切片方式,然后每个切片会根据 ViT 的预训练分辨率进行适配。最后,MiniCPM-Llama3-V 2.5 将每个处理后切片送入视觉编码器。
2. 模型训练
MiniCPM-Llama3-V 2.5 采取了多阶段训练方法,包括预训练,有监督微调和基于 AI 反馈的对齐训练。
预训练阶段的主要目的在于利用大量网络图文对(大约 500M)对齐视觉部分和语言部分。考虑到图文数据质量及训练效率,MiniCPM-Llama3-V 2.5 固定住语言模型参数,仅对视觉部分参数进行训练。
监督微调阶段,MiniCPM-Llama3-V 2.5 则使用 VQA、文档理解等多种高质量数据来学习精准多模态理解能力。此外,基于 VisCPM 提出的多模态能力的跨语言泛化技术,MiniCPM-Llama3-V 2.5 仅仅通过轻量级的多语言指令微调即完成了 30 余种语言的多模态能力泛化。
最后,MiniCPM-Llama3-V 2.5 采用 RLAIF-V 技术,通过基于 AI 反馈的对齐训练来进一步提高模型的可信回答能力。在该阶段,模型会通过分而治之的思想对不同描述进行 AI 打分,并通过分数高低构建偏好数据集来对模型进行 DPO 优化。

总结
作为面壁小钢炮系列的最新模型,MiniCPM-Llama3-V 2.5 在主流评测基准的多模态综合性能达到了 GPT-4V 水平,具有优秀的 OCR 能力、任意长宽比高清图理解能力、可信回答能力和多语言交互能力。通过一系列端侧优化技术,该模型可以在手机端部署及高效运行。MiniCPM-Llama3-V 2.5 展示出了端侧多模态大模型的巨大潜力,相信在不久的将来,会有更多更加强力的大模型出现在用户移动端,提供可靠安全的智能服务,提升用户生活工作效率,惠及更多应用场景。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









