






OpenAI GPT-4o,Google Gemini,Meta Llama3......
无论闭源还是开源,大模型技术的发展今年是你方唱罢我登场,而且迭代速度飞快,在短短一年间就有了大幅度的技术迭代更新,LoRA、模型压缩、QLoRA、DeepSpeed、Megatron-LM、Flash Attention、RLHF、DPO等等,几乎每天都有新的发展。
我们总结了算法工程师需要掌握的大模型微调技能,并制作了大模型微调技能图谱,希望可以帮助大家将知识体系梳理清楚,为未来在大模型的工作与科研道路上节省时间,提高效率!
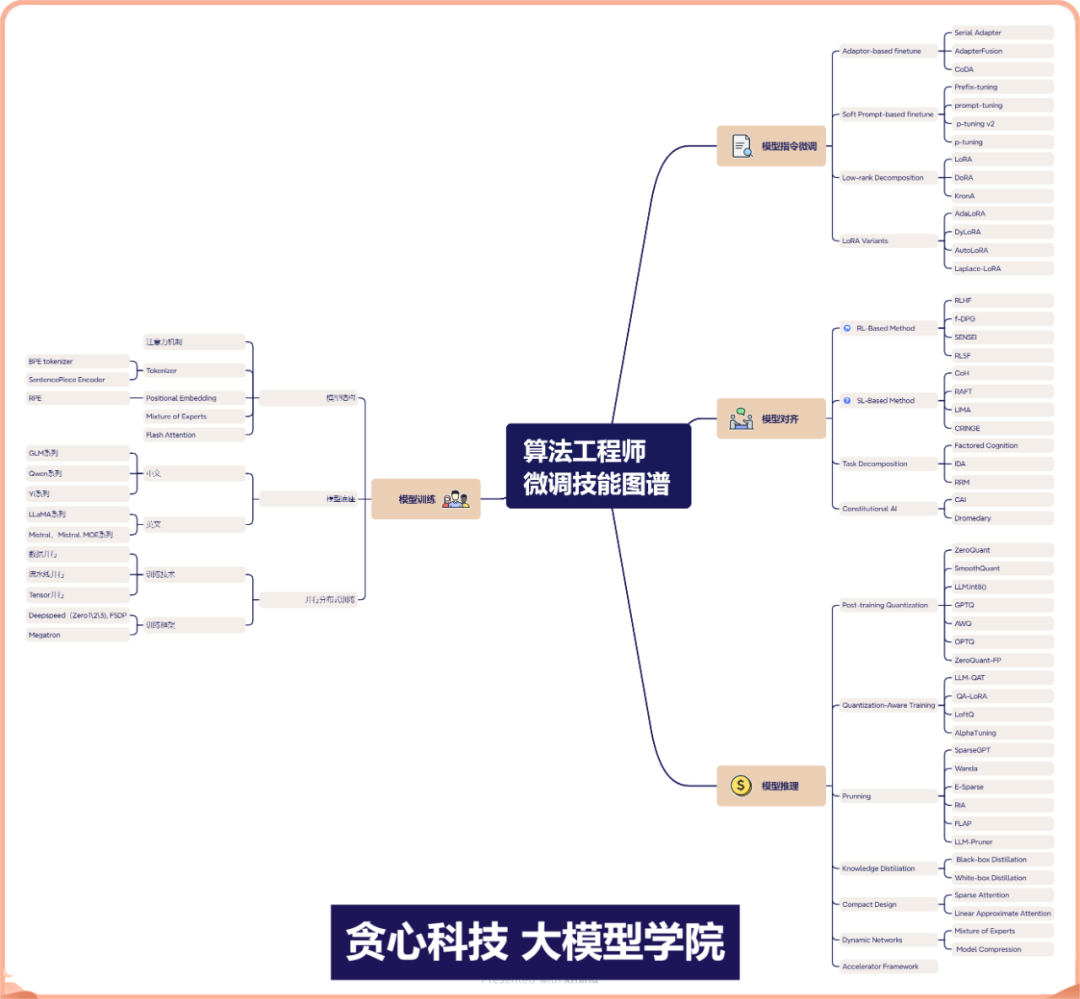
作为算法工程师,面对如此庞大又在飞速迭代的大模型技术体系,您是否有感觉自己的学习步伐有点跟不上技术的发展?或者对这些新兴技术的理解仅仅停留在应用层面上,实际上对背后的原理并没有深入剖析过?如果您希望在大模型赛道上持续保持竞争壁垒,对技术本身的深入理解是很必要的选项。
鉴于这类痛点,并迎合技术的发展,贪心科技推出《大模型微调应用实战营》,通过3个月的时间,全面掌握以上图谱中列出的知识技术以及背后的精髓,帮大家大大节省学习成本。
下面是5个阶段学习安排,感兴趣的朋友们欢迎扫码咨询。
扫描二维码,添加顾问老师咨询~

详细大纲
第一阶段:大模型基础
第一章:开营典礼
课程介绍与目标
学习安排与课程结构
学员参与要求
课程项目与技术概览
推荐工具和开源资源
第二章:大模型是怎么炼成的
大模型的概念与历史发展
关键技术和算法基础
数据准备与预处理
预训练、指令微调、对齐
模型评估以及能力分析
第三章:微调的应用场景
微调与全量训练的区别
微调在不同领域的应用案例
选择微调任务和数据
微调的效果评估方法
微调项目的规划与管理
第四章:大模型基座-理解Transformer
Transformer模型的基础架构
Self-Attention机制的工作原理
Transformer在NLP任务中的应用
Transformer模型的变种与发展
使用Transformer模型的实用技巧
Encoder和Decoder介绍
第五章:开源模型类别以及汇总
常见的中英开源大模型介绍
模型选择标准与评估
开源模型的获取与使用
社区支持与资源分享
开源大模型发展方向
第六章:【项目实战1】开源大模型以及部署
Huggingface介绍
本地下载开源模型
理解HF相应的库以及导入大模型
模型封装以及部署
性能优化与成本控制
第二阶段:大模型指令微调
第七章:指令微调基础
指令微调的概念与应用价值
指令集设计与实现
微调流程与实践技巧
性能评估与优化策略
指令微调的挑战与解决方案
第八章:LoRA参数微调
LoRA微调的方法
实施LoRA微调的步骤
LoRA微调在实际项目中的应用
性能评估与调优技巧
LoRA微调的局限与未来展望
第九章:【项目实战2】LoRA微调Alpaca项目
Alpaca项目介绍
指令数据的理解
LoRA微调的实施与调优
项目评估与效果分析
经验总结与案例分享
第十章:模型压缩
为什么需要大模型压缩
模型压缩的方法与技术
压缩对模型性能的影响
压缩模型的常见方法
模型服务化的最佳实践
第十一章:QLoRA参数微调
QLoRA微调技术介绍
微调策略与实施过程
应用QLoRA的案例
QLoRA微调的性能调优
面临的问题与解决方法
第十二章:【项目实战3】QLoRA参数微调智能客服项目
设计QLoRA微调方案
准备数据与环境配置
开源模型选择
执行微调与性能监控
项目经验分享与讨论
第十三章:DeepSpeed训练框架解析
DeepSpeed框架概述
配置与环境搭建
在大模型训练中使用DeepSpeed
分布式训练介绍
框架背后技术实现
DeepSpeed参数理解
实战案例与经验分享
第十四章:Megatron-LM训练框架解析
Megatron-LM框架介绍
框架安装与配置指南
应用Megatron-LM进行模型训练
框架背后技术实现
Megatron-LM参数理解
实战案例与经验分享
第十五章:Flash Attention技术应用
为什么需要Flash Attention
GPU计算背景知识
Flash Attention技术背后
在大模型中应用Flash Attention
实际部署与应用案例
第十六章:微调模型Benchmark
微调模型性能测试的重要性
Benchmark工具与方法介绍
执行Benchmark的步骤与技巧
结果分析与解读
Benchmark设计与业务场景
第十七章:【项目实战4】微调QLoRA+Flash Attention
结合QLoRA和Flash Attention的策略
微调与部署的一体化流程
项目实施的关键步骤
成果评估与性能优化
经验分享与问题解决
第三阶段:常用的开源模型微调
第十八章:开源模型家族以及类别
开源模型的概述
常见的开源模型分类
选择开源模型的考量因素
开源模型的获取和使用指南
维护和贡献开源模型的最佳实践
第十九章:ChatGLM开源模型家族和应用
ChatGLM模型家族介绍
ChatGLM1到ChatGLM3迭代
ChatGLM的私有化部署
ChatGLM的特色
微调ChatGLM模型的步骤和技巧
微调案例分享
第二十章:【项目实战5】ChatGLM微调医疗模型
理解需求以及技术方案设计
医疗指令数据的搜集
医疗Benchmark的获取和整理
微调ChatGLM+LoRA模型
微调案例分享
第二十一章:Qwen和YI开源模型家族和应用
Qwen和YI模型家族概述
两个模型家族的迭代
Qwen和YI大模型的私有化部署
两个大模型家族的特色
微调Qwen和YI模型的实践指南
微调案例分享
第二十二章:LLaMA开源模型家族和应用
LLaMA模型家族特点
LLaMA大模型的迭代和架构变化
LLaMA大模型的私有化部署
微调LLaMA模型的方法和建议
LLaMA模型微调的案例分析
微调案例分享
第二十三章:Mistral和Phi开源模型家族和应用
Mistral和Phi模型家族简介
Mistral和Phi在多语言中的应用
两大模型家族的特色
量大模型家族的私有化部署
微调Mistral和Phi模型的流程
微调案例分享
第二十四章:MoE模型特点以及应用
MoE(Mixture of Experts)模型概念
MoE模型在大规模数据处理中的优势
微调MoE模型的关键点
MoE模型的应用案例
MoE模型的扩展性和可维护性问题
Mistral 8x7b
微调案例分享
第二十五章:【项目实战6】Mistra 8x7B微调智能客服模型
理解需求以及技术方案设计
智能客服指令数据收集
Benchmark的获取和整理
微调Mistra 8x7b+QLoRA模型
模型评估以及验收报告制作
第二十六章:其他开源模型以及应用
Baichuan中文大模型
Falcon模型家族
Bloom模型介绍
不同领域开源模型的应用实例
微调这些开源模型的技术指导
第二十七章:开源模型特色以及选择
评估开源模型的关键标准
匹配项目需求和模型特性
实践中选择开源模型的经验分享
开源模型使用中的常见陷阱
社区和资源的重要性
第四阶段:大模型对齐
第二十八章:大模型对齐基础
大模型对齐的重要性和应用场景
基本对齐技术和方法概述
对齐过程中的数据处理和预处理
模型对齐的评估指标
大模型对齐的挑战和策略
第二十九章:用于对齐的开源数据
开源数据集的重要性和来源
选择和处理对齐用的开源数据
开源数据在模型对齐中的应用
数据隐私和伦理考量
维护和更新开源数据集
第三十章:RLHF技术和应用
RLHF(强化学习从人类反馈)技术介绍
RLHF在模型对齐中的应用案例
实施RLHF技术的步骤
RLHF技术的效果评估
解决RLHF应用中的问题
RLHF实战案例分析
第三十一章:DPO技术和应用
DPO(Direct Preference Optimization)概念
DPO在优化模型对齐中的作用
实现DPO的关键技术点
DPO应用的案例和效果分析
DPO技术的挑战和前景
DPO实战案例分享
第三十二章:【项目实战7】RLHF推荐模型对齐项目
需求分析以及技术方案设计
数据收集和预处理
训练Reward Model
训练RLHF完整微调
项目的评估和优化
第三十三章:【项目实战8】DPO推荐模型对齐项目
需求分析以及技术方案设计
对齐数据的准备和处理
执行DPO模型对齐流程
对齐效果的评估和调整
项目中遇到的挑战
第三十四章:讨论大模型对齐
当前大模型对齐技术的发展趋势
模型对齐在大模型中的真正价值
对齐在工程上挑战
模型对齐技术的伦理和社会影响
资源推荐和学习路径
第五阶段:垂直领域大模型应用
第三十五章:垂直领域大模型微调基础
垂直领域的研发符合中国现状
垂直领域大模型研发pipeline
微调大模型的基本方法和流程
选择合适的微调策略
微调中的性能优化技巧
微调项目的评估和调整
第三十六章:医疗领域大模型微调
智能问诊领域的应用场景和需求
大模型能力维度设计
领域内benchmark设计
快速测试开源模型能力并选择合适的模型
微调模型以适应医疗数据
模型部署以及RAG设计
第三十七章:金融领域大模型微调
金融领域通用大模型需求分析
金融领域大模型benchmark
XuanYuan开源项目剖析
金融领域大模型案例解读
微调模型在金融Benchmark上的评估
金融领域中的未来潜在落地场景
第三十八章:教育领域大模型微调
教育领域的大模型应用场景和需求
微调大模型进行个性化学习支持
EduChat开源项目剖析
指令数据和对齐数据的整理
Benchmark以及大模型评估
教育领域中的未来潜在落地场景
第三十九章:课程总结以及结营
课程学习要点回顾
项目成果分享和评估
学习心得和经验交流
未来发展趋势和学习路径
类别 | 说明 |
课程形式 | 线上直播+课程学习群答疑 |
课程安排 | 11次直播授课,每周1次,每次3-3.5小时 |
课程服务 | 25人以内学习群,助教答疑,保证遇到的问题被快速解决 专属咨询顾问与班主任老师全程伴学 全程直播讲解与演示+可反复观看课程视频 |

课程PPT举例

项目实战举例
课程学习群答疑举例
课程主讲

Shine老师
大模型开发与微调领域专家
中科院博士
头部金融科技公司资深算法专家
曾任埃森哲人工智能实验室数据科学家
拥有丰富的大模型微调/情感分析/博文品牌识别/问答系统等各类项目经验

李文哲
贪心科技创始人兼CEO
人工智能、大模型领域专家
多家上市公司技术战略顾问
曾任金融科技独角兽公司首席科学家
曾任量化投资初创公司首席科学家
曾任美国亚马逊推荐系统工程师
深耕人工智能领域十余年,授课培养AI学员数万人
报名咨询
扫描二维码,添加顾问老师咨询~
















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









