







©PaperWeekly 原创 · 作者 | 刘源鑫
单位 | 北京大学
研究方向 | 多模态大语言模型

论文标题:
TempCompass: Do Video LLMs Really Understand Videos?
收录会议:
ACL 2024 Findings
论文链接:
https://arxiv.org/abs/2403.00476
代码及数据链接:
https://github.com/llyx97/TempCompass
LeaderBoard链接:
https://huggingface.co/spaces/lyx97/TempCompass

背景及动机
视频大语言模型(Video Large Language Models, Video LLM)旨在将 LLM 拓展为视频-文本多模态场景下的通用智能助手。和纯文本 LLM 相比,Video LLM 具有视觉感知能力。相较于传统视觉-语言模型(Vision-Language Models, VLM),Video LLM 又继承了 LLM 强大的指令理解、逻辑推理以及多伦对话能力,从而能够更加流畅地与用户交互,应对现实世界中的复杂任务。

(a)自动驾驶
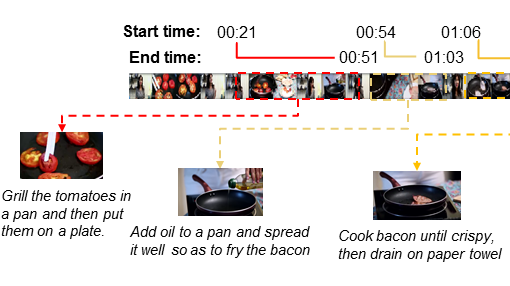
(b)视频教程
▲ 图1 需要时序理解能力的应用场景
和静态图像相比,视频数据的独特之处在于引入了时间维度。在众多视频相关的应用中,对动态时序信息的理解也是至关重要的。举例而言,在以上自动驾驶场景中,为了做出合理的驾驶决策,系统不仅要识别出道路环境中的车辆,还要进一步判断它们相对于自动驾驶车辆的速度变化与行驶方向。同样,在视频教程中,有效学习不仅涉及对单个操作步骤的认知,还包含了步骤间顺序和关联性的理解。
鉴于此,对 Video LLM 时序理解能力的评测显得尤为重要。考虑到 Video LLM 作为多模态通用智能助手的定位,构建其时序理解能力的 benchmark 应聚焦于以下几个核心特性:
多样的时序信息类型:评测应当整合多样的时序特征,例如事件顺序、物体运动方向、属性变化等,确保 Video LLM 能理解各类时序信息。
多样的任务指令形式:对于视频中同样一条时序信息,应该设计不同形式的任务指令,从而检验 Video LLM 对任务指令多样性的鲁棒程度。
开放域的视频样本类型:评测的视频样本应当涵盖不同领域类型,从而验证 Video LLMs 在理解开放领域视频内容时的泛化与适用性。
经过广泛调研,我们总结了现有视频理解 benchmark 关于以上三个方面的设计(如图 2 所示),发现它们都在其中某些方面存在不足。因此,我们提出了 TempCompass benchmark 来实现对 Video LLM 时序理解能力的全面评测。
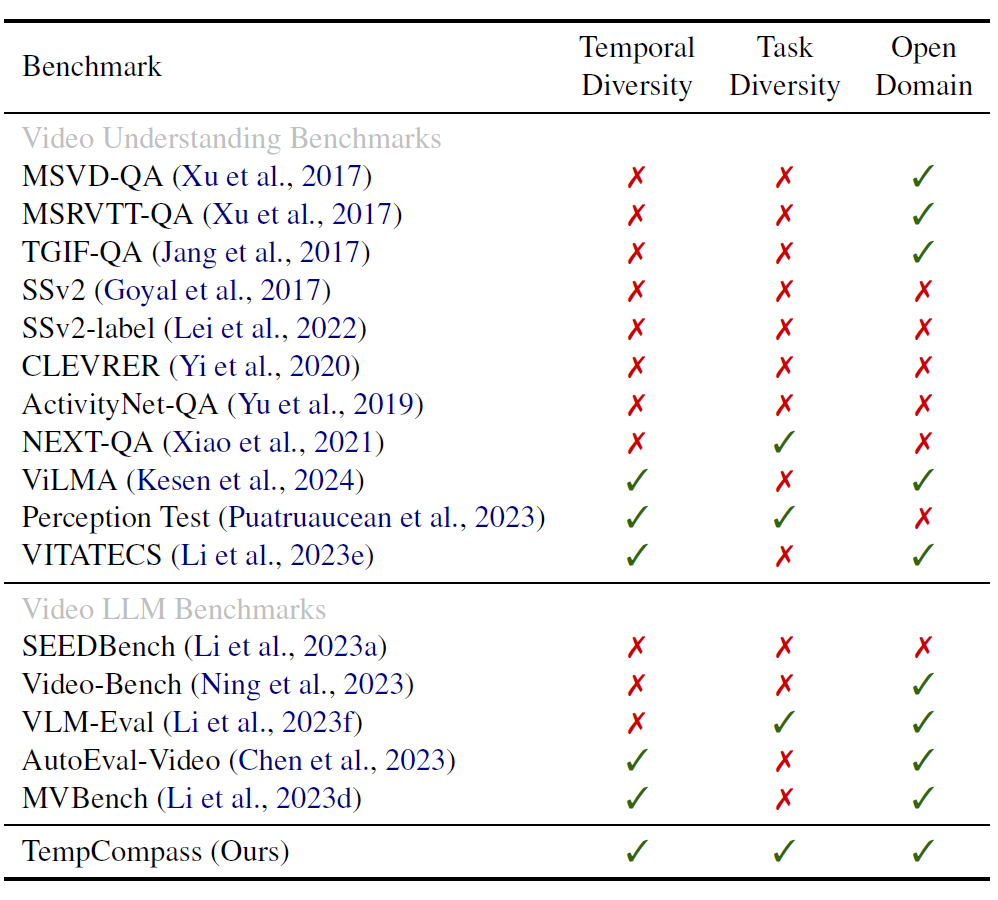
▲ 图2 不同视频理解 benchmark 对比

数据集构建
2.1 数据集结构设计
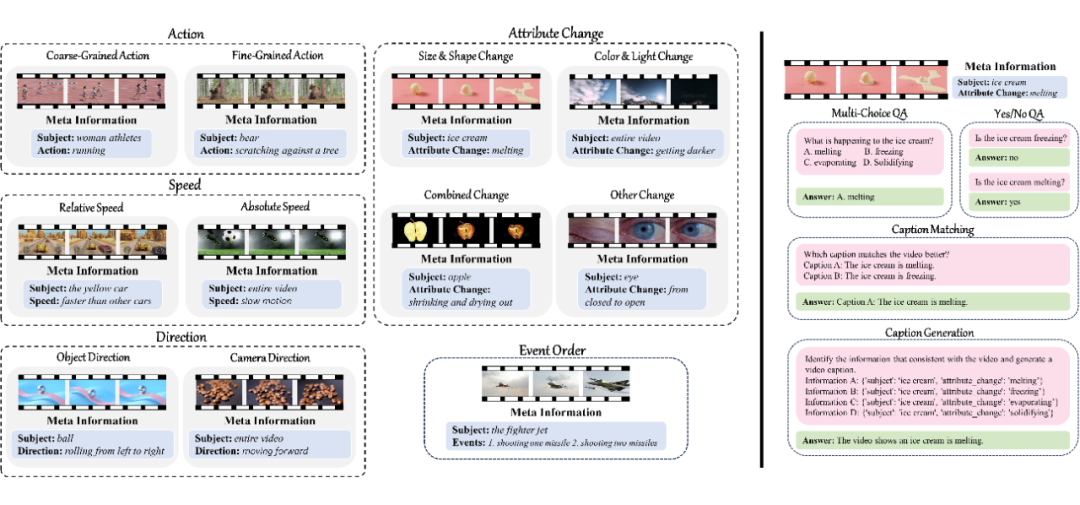
▲ 图3 TempCompass 数据集结构;时序信息类型(左);任务指令类型(右)
时序信息类型:如图 3(左)所示,我们系统性地将视频中的时序信息归纳为 5 大类型,包括动作(Action)、速度(Speed)、方向(Direction)、属性变换(Attribute Change)以及事件顺序(Event Order)。其中动作又被进一步划分为粗细两种粒度;速度方面对相对速度和绝对速度进行区分;方向方面既考虑物体的运动也涉及相机镜头的运动;属性变换也根据属性的不同进行了区分。
任务指令类型:如图 3(右)所示,我们设计了 4 种任务来探究模型对同一条时序信息的理解。多选问答(Multi-Choice QA)要求模型从给定的多个选项中找出正确答案。是非判断(Yes/No QA)要求模型判断一个陈述是否正确。视频描述匹配(Caption Matching)要求模型在两段仅在特定时序类型上有所差异的文本描述中(比如 ice cream melting和freezing),甄别出与视频内容最为贴合的一项。
最后,在视频描述生成(Caption Generation)任务中,我们向模型展示关于特定时序类型的多条元信息(Meta-Information),要求其找出和视频最相符的一条并基于此生成视频描述。
视频内容类型:根据视频主体的不同,我们将视频内容分为 9 个类型,即 People, Animals, Plants, Vehicles, Artifacts, Food, Buildings, Natural Objects, Abstract。
2.2 数据收集
2.2.1 数据收集总体流程
基于以上数据集结构设计,我们的每条数据样本需要包含 4 个元素:视频、元信息、视频内容类型以及任务指令。为了兼顾效率和数据质量,我们采用了自动生成和人工标注结合的数据收集策略,具体流程如下:
人工选择若干时序信息类型和视频内容类型。
人工收集相关视频+自动构建冲突视频。
人工标注与选定时序类型相关的元信息。
用 ChatGPT(gpt3.5-turbo)基于元信息生成任务指令。
人工检查生成指令的质量并进行修正。
2.2.2 视频收集
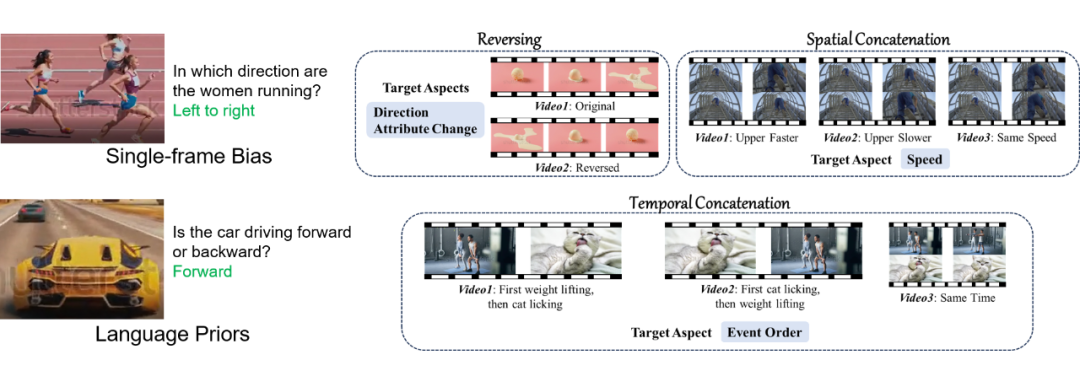
▲ 图4 单帧偏见和语言先验(左);冲突视频构建(右)
我们从 ShutterStock 网站收集原始视频,并确保这些视频未被采纳入 WebVid 数据集——该数据集广泛用于视频-语言模型的预训练,从而避免了数据信息泄露。
在某些情况下,模型即使没有真正理解视频中的时序信息也可以通过一些捷径(shortcuts)正确回答相关问题。如图 4(左)所示,模型可以依赖单帧图像偏差(Single-Frame Bias),即仅凭静止画面推测运动员从左向右奔跑;以及凭借语言先验知识(Language Priors)盲猜出视频中的车辆正向前行驶。
为了缓解评测结果受以上因素的干扰,我们在收集的原始视频基础上构造了冲突视频(Conflicting Videos)。
对于 Direction 和 Attribute Change,我们将原始视频倒放。倒放版本和原始视频总体内容一致,但是在 Direction 或 Attribute Change 方面是相互冲突的。对于 Speed,我们将一个原始视频以不同速度播放并上下拼接在一起,然后根据三种不同的拼接组合方式构造了在 Speed 方面相互冲突的三个视频。对于 Event Order,我们将两个互不相关的视频 A 和视频 B 按三种方式拼接在一起(A 先 B 后,B 先 A 后,以及 AB 同时),构成三个冲突视频。
2.2.3 任务指令收集

▲ 图5 Multi-Choice QA 任务指令生成 prompt
我们用 ChatGPT 基于人工标注的元信息生成四种任务的指令。如图 5 所示,除了元信息和指定的时序类型外,我们还给 ChatGPT 提供了详细的任务描述以及一些 in-context learning 样例,使其能够按期望的格式进行生成。关于其他三种任务的指令自动生成细节,请参考我们的论文。
2.3 数据统计
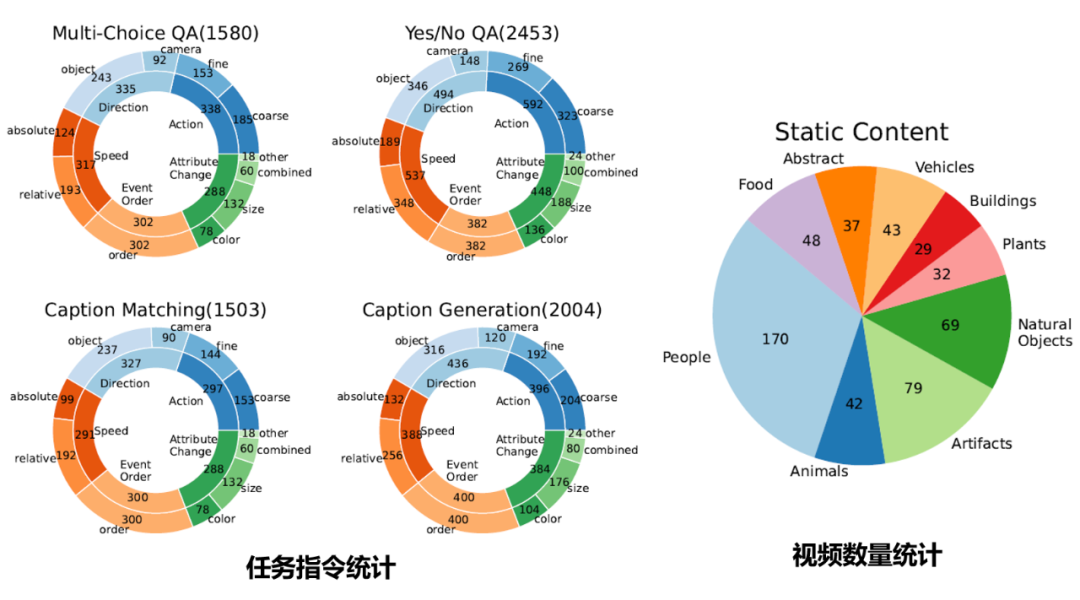
▲ 图6 数据分布统计
按照上述数据收集流程,我们总共收集了 410 条视频(每条视频可以属于多个static content)和 7,540 条任务指令。如图 6 所示,每种任务至少包含 1,500 条任务指令,并且 5 种时序信息类型下的指令数量大致是均匀分布的。
2.4 数据样例

▲ 图7 完整数据样例
图 7 展示了一个完整的数据样例,其中包括视频、元信息(Meta-Information)、视频内容类型(Static Contents)以及四个任务的指令。

评测方法
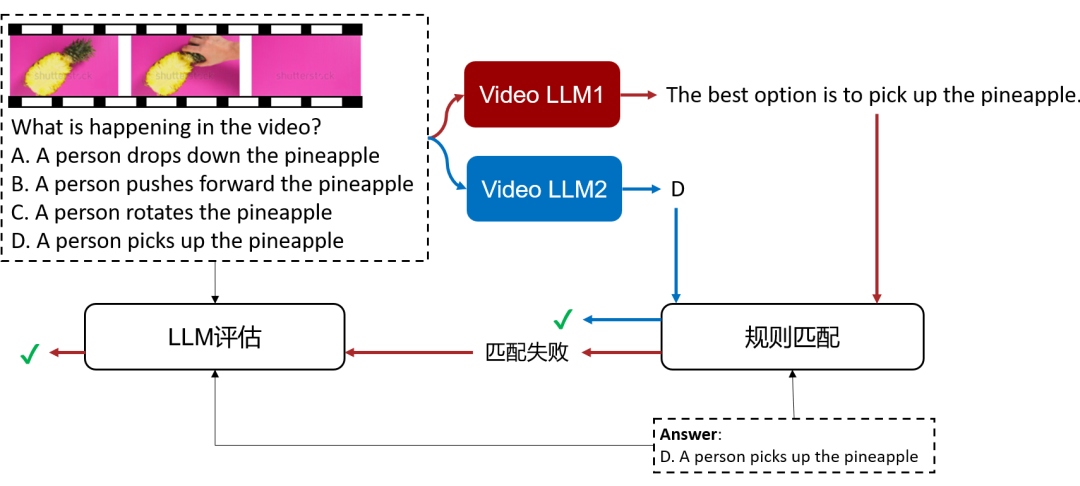
(a)评测流程

(b)LLM 自动评测 prompt
▲ 图8 规则+LLM自动评测
在 Multi-Choice QA, Yes/No QA 和 Caption Matching 这三种任务中,候选项集合是固定的。因此,我们设计了一系列基于规则的匹配方法,检查 Video LLM 的回复能匹配到某个选项。例如在图 8 中,Video LLM2 直接回复了 “D” 可以匹配为“选项 D”。
相比之下,Video LLM1 的回复 “The best option is pick up the pineapple” 无法通过规则匹配到某个选项。在这种情况下,我们利用 LLM(ChatGPT)进行评估。具体而言,我们在 prompt 中提供任务类型([X])、任务指令([question])、标准答案([ground_truth_answer])以及 Video LLM 回复([video_llm_prediction])等信息,然后让 ChatGPT 作出 “Correct” 或“Incorrect 的判断”。

▲ 图9 LLM 自动评测 Caption Generation 的 prompt
由于 Caption Generation 任务的答案是开放性的,评估生成视频描述的精确性不能简单依赖于与预设参考文本的对比。因此,我们为该任务专门设计了一个评测方案:以 Video LLM 生成的视频描述为上下文,让纯文本 ChatGPT 完成相应的 Multi-Choice QA 任务(prompt 见图 9)。
如果 ChatGPT 能够准确作答,则可推断 Video LLM 所生成的描述充分包含了所需时序信息,反之,若信息缺失或误导则 ChatGPT 应当在 Multi-Choice QA 任务上回答错误。此外,考虑到 Video LLM 生成的描述可能和 Multi-Choice QA 的所有选项均不匹配,我们还允许 ChatGPT 选择 “None of the choices are correct”。在这种情况下,Video LLM 生成的描述也被认为是不正确的。

评测结果
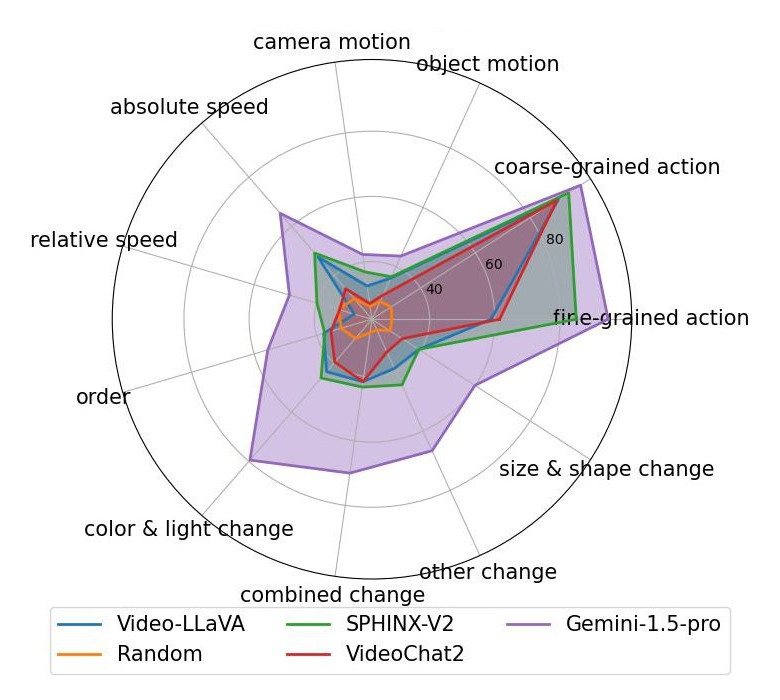
(a)Multi-Choice QA
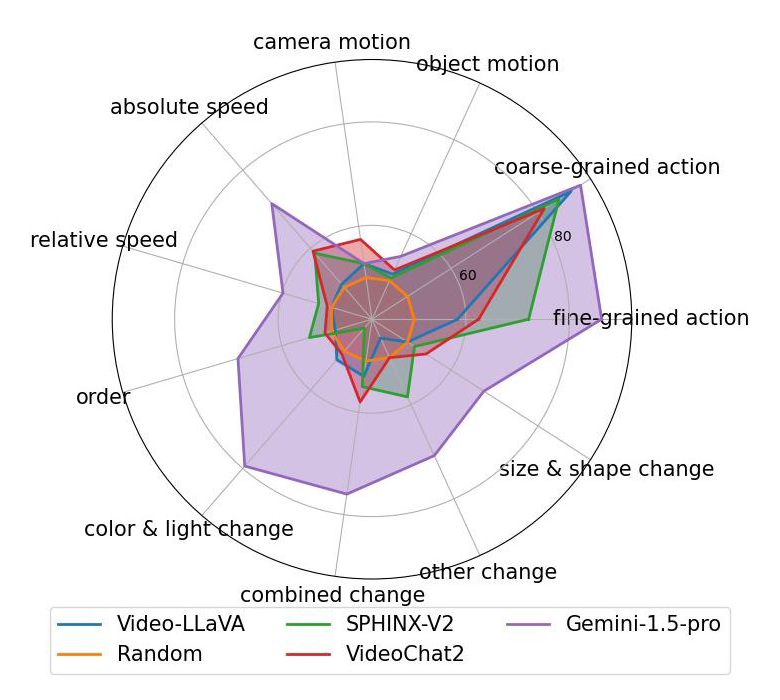
(b)Yes/No QA
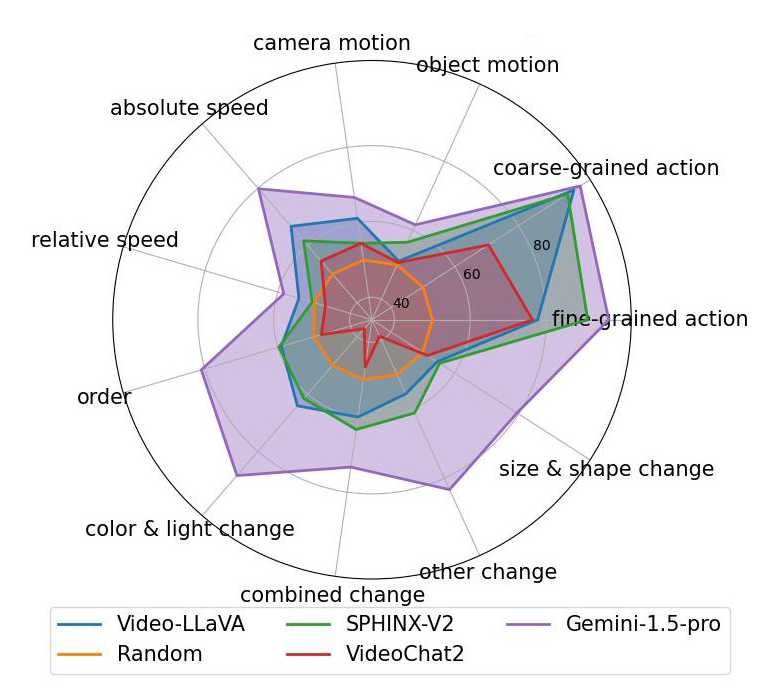
(c)Caption Matching
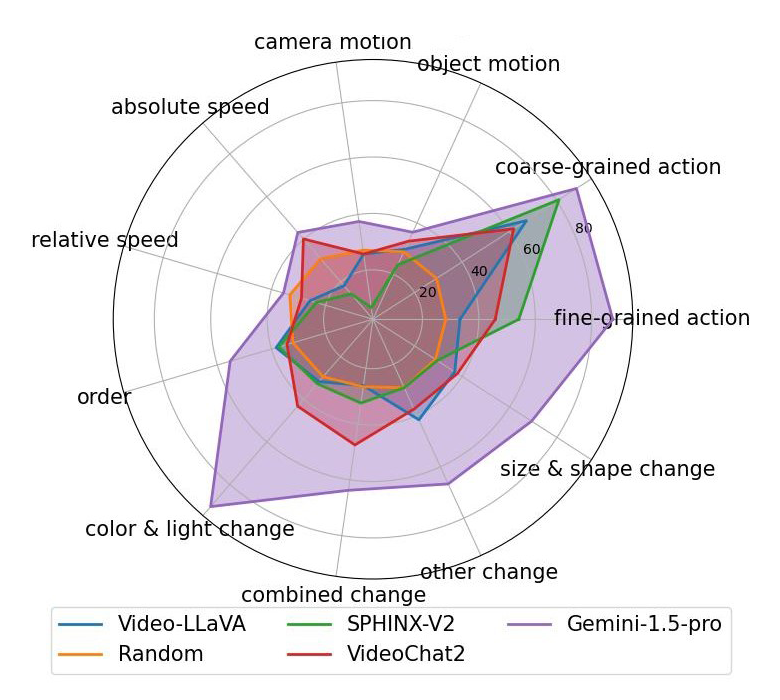
(d)Caption Generatio
▲ 图10 自动评测结果
图 10 展示了对部分多模态大语言模型(Multi-Modal Large Language Models, MLLM)的评测结果。其中 Video-LLaVA,VideoChat2 和 Gemini-1.5-pro 属于 Video LLM,天然支持视频输入。SPHINX-V2 属于 Image LLM,只支持单帧图像输入。对更多模型的评测结果请参见我们的论文。
从以上评测结果中,我们可以发现:
所有 MLLMs 在 Action 相关的两个维度上表现都不错。由于动作类型很大程度上可以根据单帧图像判断,我们可以推断这些 MLLMs 对静态视觉内容的感知能力都不错。
在需要时序理解的其他维度上,Video-LLaVA 和 VideoChat2 相比基于图像的 SPHINX-V2 没有明显的优势,说明现有开源 Video LLM 的时序理解能力还有很大的提升空间。
现有 MLLM 对任务指令类型的鲁棒性也有待提升。例如,VideoChat2 在 Caption Matching 任务上的总体效果显著比 Multi-Choice QA 和 Yes/No QA 这两个任务差。
Gemini-1.5-pro 的时序理解能力显著优于其他模型,在 Attribute Change,Event Order 和 Absolute Speed 等维度上取得了较好的效果。然而,Gemini-1.5-pro 在相对速度以及运动方向的感知上效果也还不太理想。
图 11 展示了一对冲突视频(原始视频和其倒放版本)下的 case study。我们发现,尽管三个模型在原始视频情景下都作出了正确的回答,它们在面对倒放视频时却一致出错,这揭示了它们时序理解能力的不足。同时,从这个例子中还可以看出我们自动评测方法的有效性,可以对 MLLM 开放式的回复进行准确的评测。

▲ 图11 自动评测结果 Case Study

总结
本文对 Video LLM 的时序理解能力评测进行了探究,核心贡献包括以下四个方面:
我们提出了 TempCompass benchmark,其涵盖了多样的时序信息类型、任务指令形式以及视频内容类型,可以对 Video LLM 的时序理解能力进行全面的评测。
我们创新性地构造了冲突视频,有效缓解了 single-frame bias和language-priors 对评测结果的影响。
我们设计了一套结合规则和 LLM 的自动评测方案,可以高效准确地对 Video LLM 的回复进行评测。
我们的评测结果揭示了现有 Video LLM 时序理解能力以及对任务指令鲁棒性的不足,为未来的改进方向提供了有价值的参考。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 64
64

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









