








论文标题:
SpikeLM: Towards General Spike-Driven Language Modeling via Elastic Bi-Spiking Mechanisms
论文地址:
https://arxiv.org/pdf/2406.03287
代码地址:
https://github.com/Xingrun-Xing/SpikeLM

背景
脉冲神经网络(Spiking Neural Network, SNN)通过脉冲驱动的神经元动力学方程实现二值激活特征和事件驱动的稀疏性,可以有效降低深度学习领域人工神经网络(Artificial Neural Networks, ANN)的推理功耗。由于 SNN 具有生物神经元可解释性和低功耗特性,被广泛应用于计算机视觉为任务,是类脑计算领域的主流发展方向。
近年来,基于 ANN 的大语言模型体现出了让人印象深刻的泛化能力,成为了通向通用人工智能的可能路径之一。如何把脉冲神经网络扩展到通用语言建模任务成为了需要解决的问题。目前的脉冲神经网络大多面向计算机视觉任务,直接迁移视觉任务的 CNN 和 Transformer 脉冲模型到语言任务会引起性能大幅下降。
本文的目标是实现完全脉冲驱动的通用语言建模方法,包括判别式和生成式语言任务。完全脉冲驱动指除了模型最后一层的线性层,每一层 Transformer 模块中的所有矩阵乘法都通过脉冲动力学方程转换为加法实现。尽管目前存在少量面向自然语言处理任务的脉冲神经网络工作,例如 SpikeGPT [1] 和 SpikeBERT [2],目前依然缺少完全脉冲驱动的通用语言建模方法,如表 1 所示。
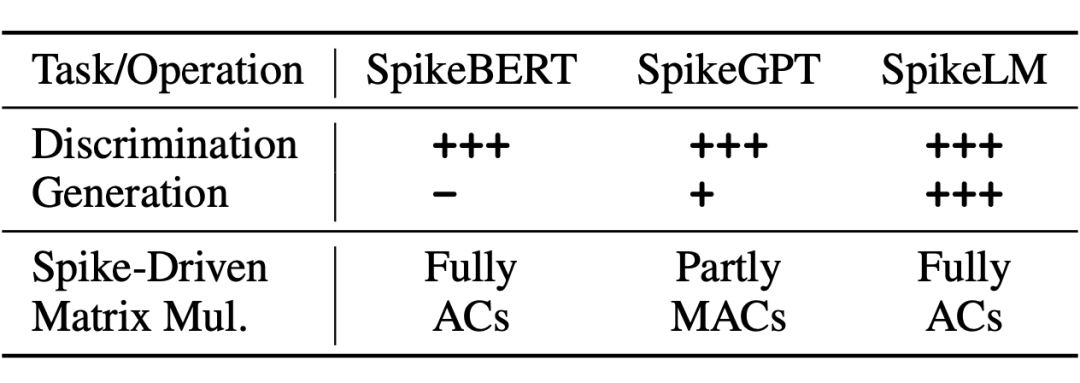
▲ 表1 SpikeLM 和 SpikeBERT,SpikeGPT 的对比。“+” 表示能力的强弱,SpikeLM 可以完成文本摘要,语言翻译等句子级别的生成任务。

本文贡献
本文提出完脉冲驱动的模型用于通用语言任务,分别使用 BERT 和 BART 结构实现判别和生成式语言任务。
提出通用全脉冲驱动的语言建模方法 SpikeLM,显著扩展了 SNN 在自然语言处理领域的应用。如表 2 所示语言建模效果超过了之前的脉冲模型的结果。
提出了松弛双向脉冲机制提升 SNN 建模能力。和传统的二值脉冲相比,我们通过脉冲方向、频率和幅度编码实现脉冲表达能力的增强;同时保证 SNN 的加法性质。
引入动态等距理论 [3],从理论上确保了松弛的双向脉冲的训练稳定性可以高于ANN 模型中的 ReLU 激活函数。由于 ReLU 激活函数稳定的优化特性,间接证明了松弛的双向脉冲编码的鲁棒性。
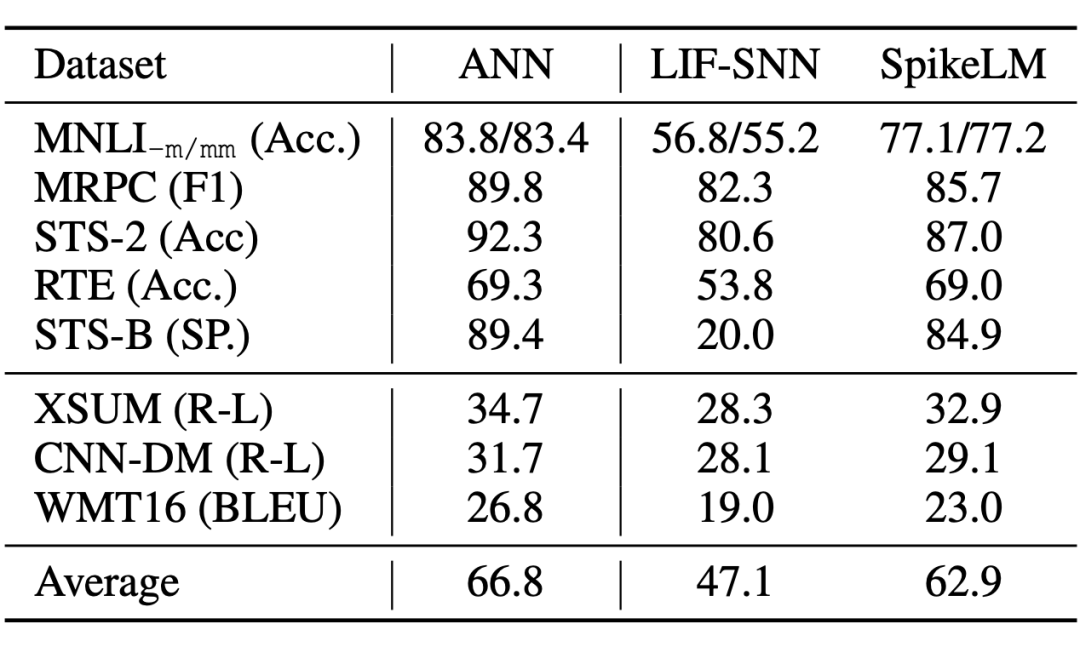
▲ 表2 ANN 和 SNN 在判别和生成类任务中的对比。SNN 和 ANN 使用相同结构的 BERT 和 BART 模型。

方法
3.1 传统的脉冲神经网络
为探索直接训练的脉冲神经网络在自然语言处理任务上的各项能力,我们首先使用广泛使用的 Leaky Integrate-and-Fire(LIF)[4] 神经元实现了脉冲驱动的 BERT 和 BART 模型。通过在 ANN transformer 的线性层和 KV-Cache 增加脉冲神经元实现。其中,脉冲神经元可以表示为:
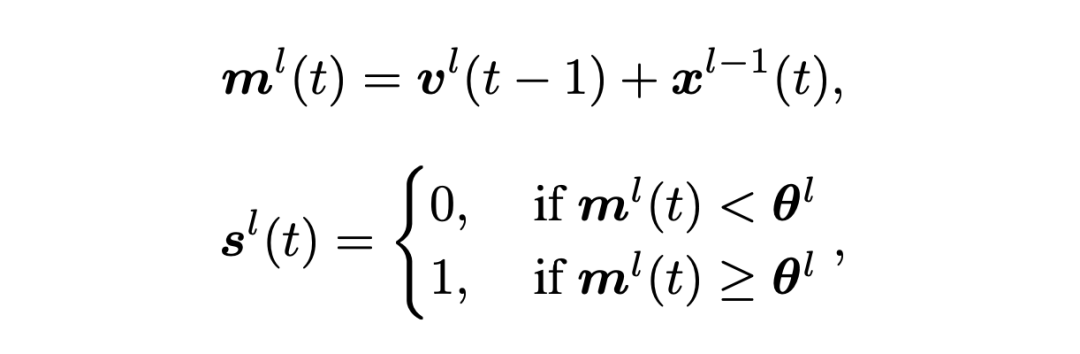
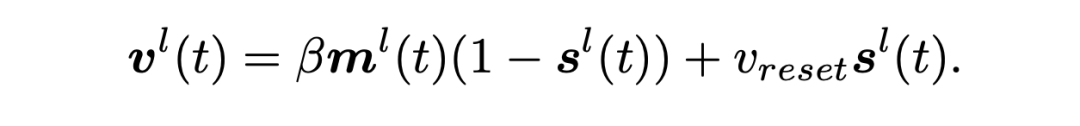
3.2 脉冲编码增强方法
然而,语言建模任务需要大量的上下文信息和深层的 transformer 结构,传统的 LIF 神经元使用简单的二值脉冲,不能编码足够的语义信息,因此在语言任务中造成了大量的性能下降。为了增加脉冲编码的语义信息,我们分别提出了一组脉冲编码方法,从脉冲的方向,频率,幅度角度全面提升脉冲语言模型的建模能力。
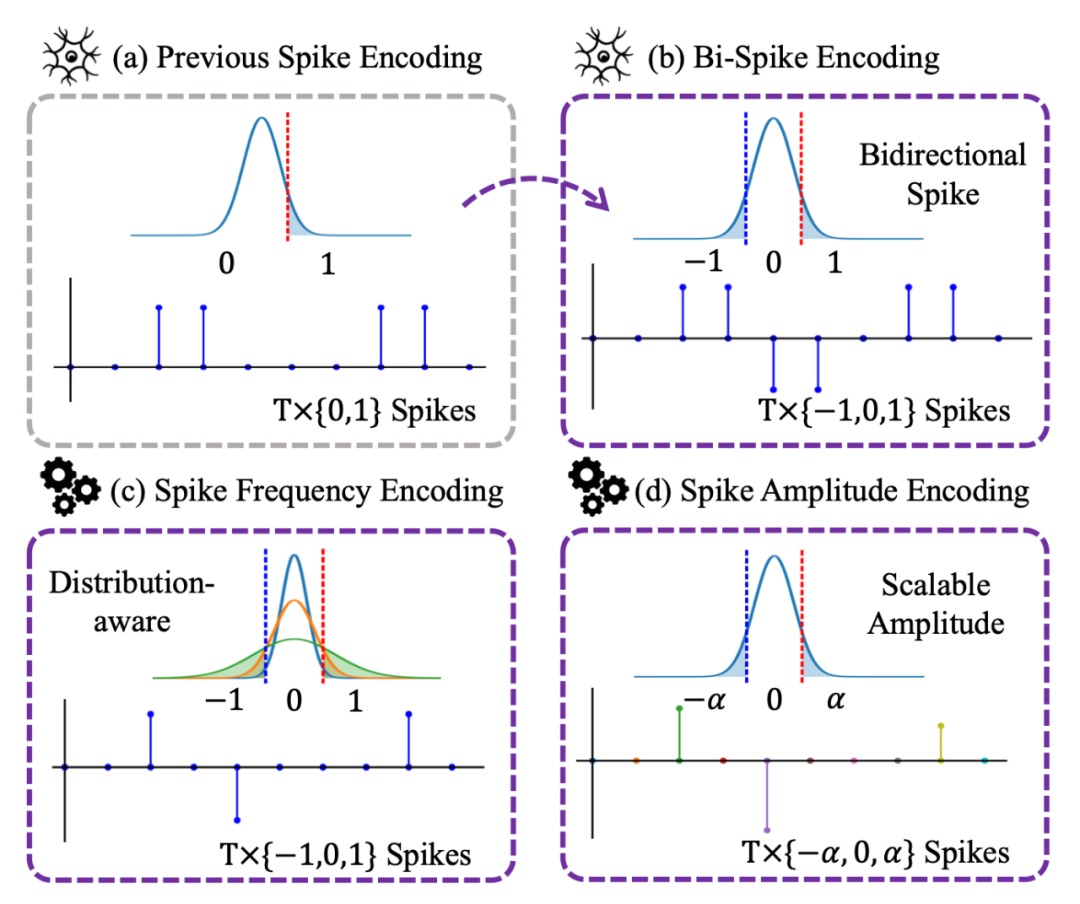
图1(a)之前的二值脉冲编码;(b, c, d)本文中的松弛的双向脉冲。我们依次进行脉冲的方向,频率和幅度编码。
双向脉冲编码:我们通过一个正向脉冲和一个负向脉冲相加定义了一种双向的脉冲编码。因此,LIF 神经元中的 {0, 1} 二值脉冲被替换为具有方向的 {-1,0,+1} 双向脉冲。双向脉冲编码的随机变量形式如下所示:
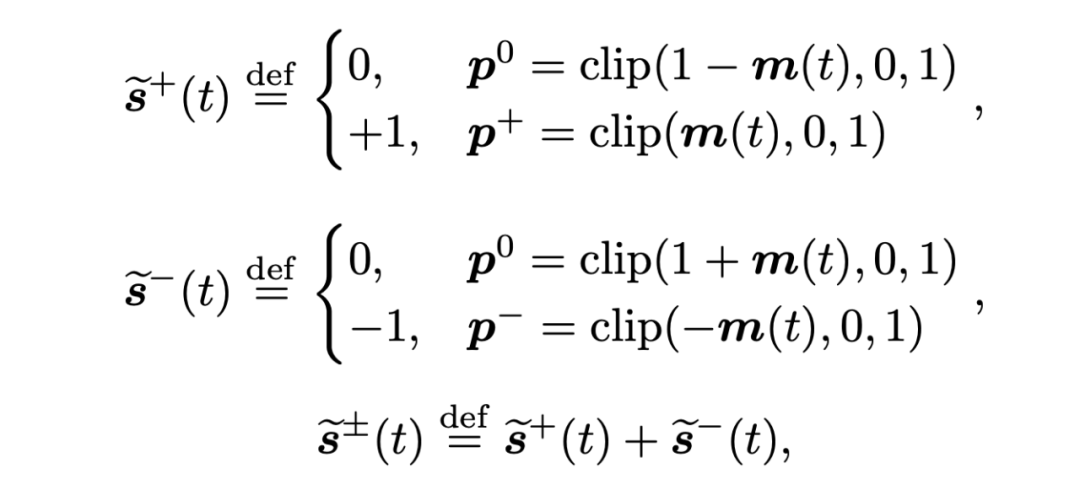
其中 m(t) 表示通时刻的神经元膜电位。相应的反向传播如下所示:
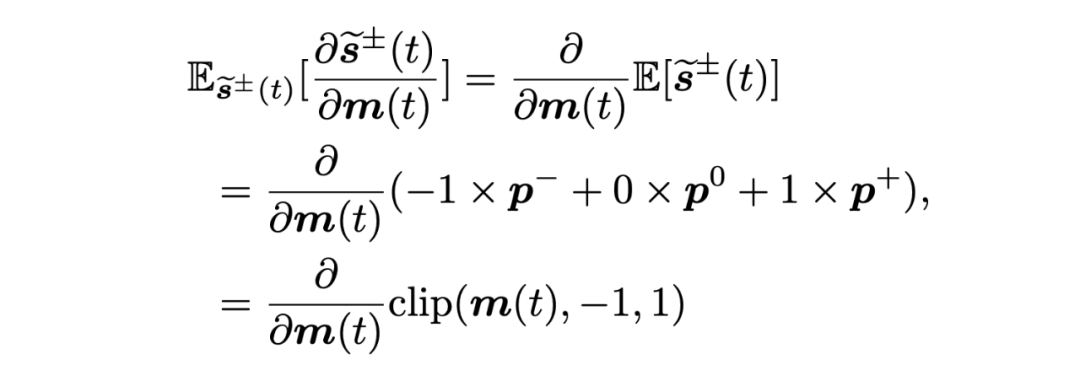
我们通过使正向脉冲的概率 p+ 或反向脉冲的概率 p- 为 1 的方式,获得双向脉冲的确定形式用于前行传播,避免随机变量形式中的采样过程:
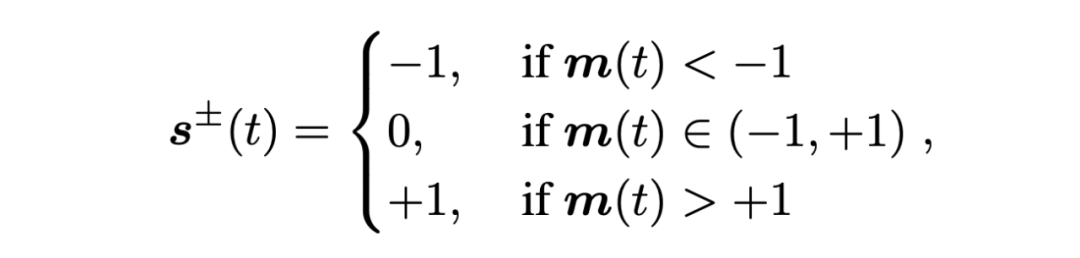
脉冲频率编码:传统的脉冲神经网络只能实现经验性的脉冲发放频率,为了实现脉冲发放频率的可控,我们提出了一种脉冲频率编码方法,可以使用超参数控制,实现了脉冲神经网络在发放率和性能之间的权衡取舍。我们通过超参数 k 控制输入的分布,当超参数 k 越大时,脉冲神经元发放率越低;当 k 越小时,脉冲表达能力越强,模型精度越高。频率编码如下公式所示:
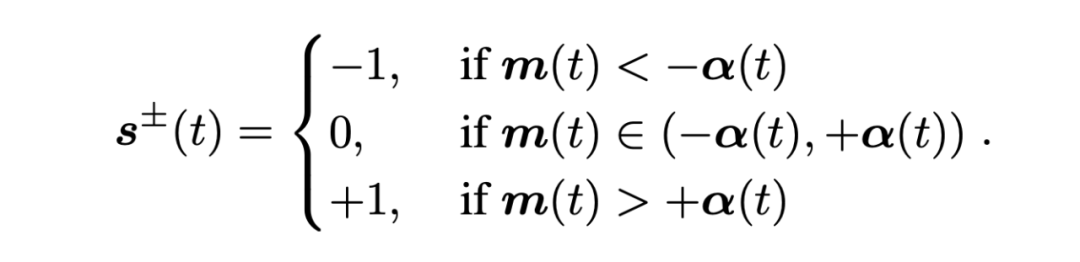
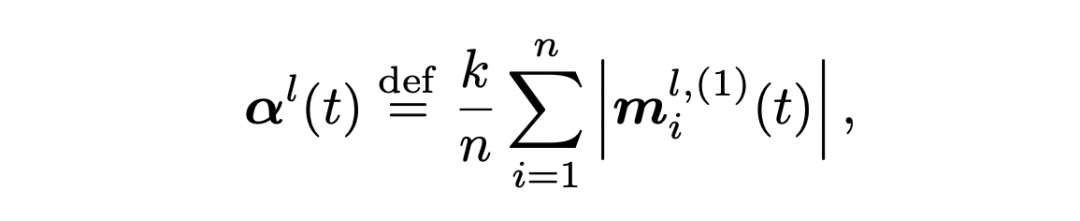
其中,alpha 使用训练数据的第一个 batch 统计获得。如下图所示,我们通过系数 alpha 改变输入分布的方差实现脉冲的频率控制。
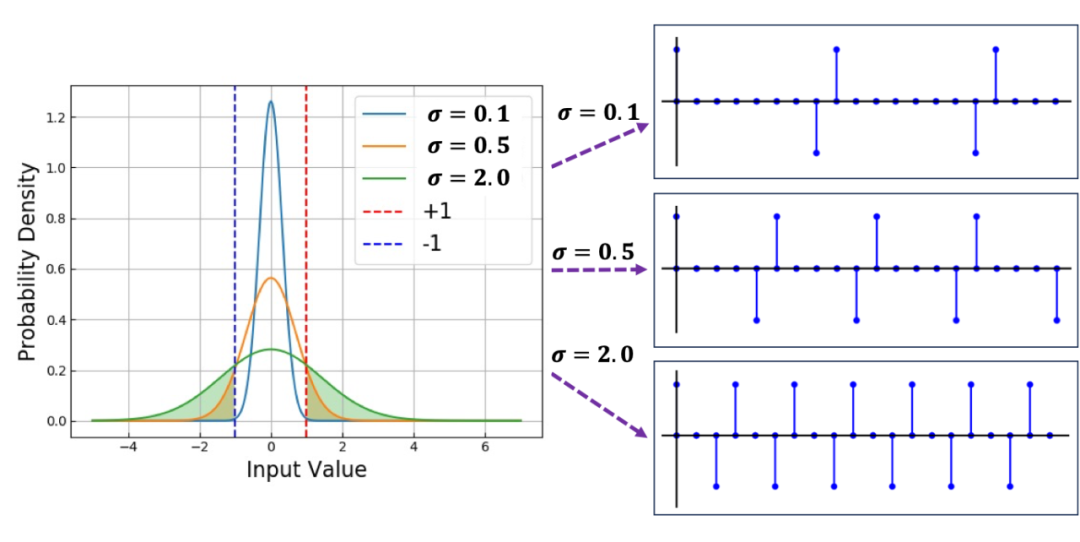
▲ 图2 膜电位分布的标准差和脉冲发放率的关系。
在选择不同 k 时,可以有效控制训练后各层的脉冲发放频率,进而更加灵活地适应不同能耗的场景。
脉冲幅度编码:为了从脉冲幅度的角度编码获得更多信息,我们使用实数的脉冲幅度,通过把编码后的脉冲和以上相同的 alpha 系数相乘得到,可以表示为:
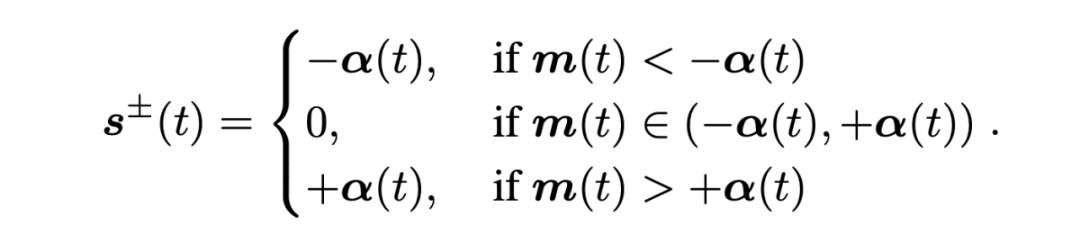
在推理阶段, alpha 系数可以和权重矩阵合并,可以保证脉冲矩阵乘法的加法性质。

实验
4.1 判别式语言模型
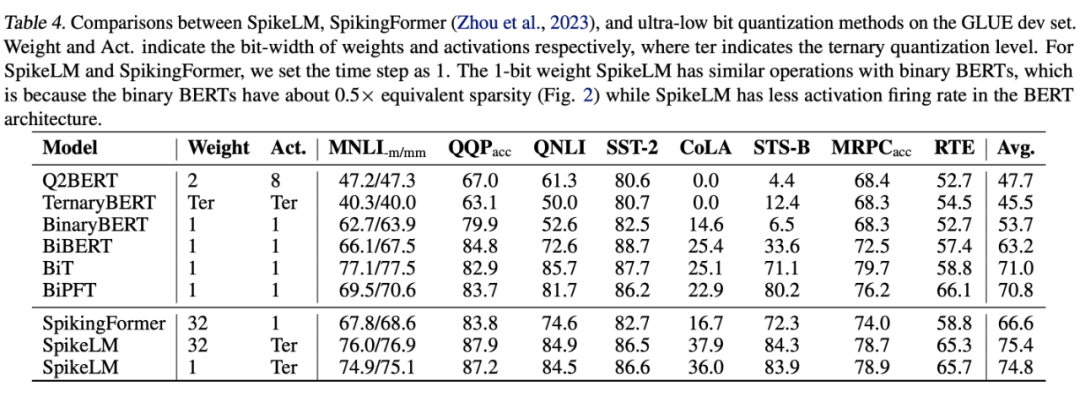
我们使用 BERT [5] 结构和 GLUE 数据集进行测试,SpikeLM 相比于 LIF 神经元实现的 BERT 脉冲模型有效提升效果;和 ANN BERT 模型相比,在时间步为 1 和 4 的条件下分别节约 12.9 和 3.7 倍能耗。
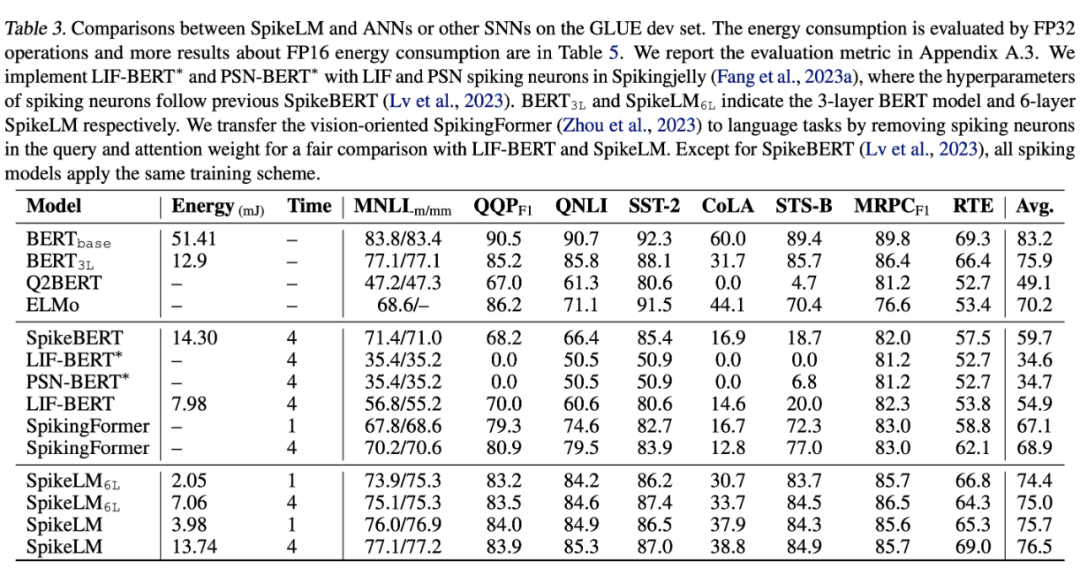
我们进一步对 SpikeLM 的权重进行 1bit 量化 [6],和极低 bit 量化模型进行对比。由于 SpikeLM 具有可控的稀疏性,在时间步为 1 时,和二值化神经网络具有类似操作数量。
4.2 生成式语言模型
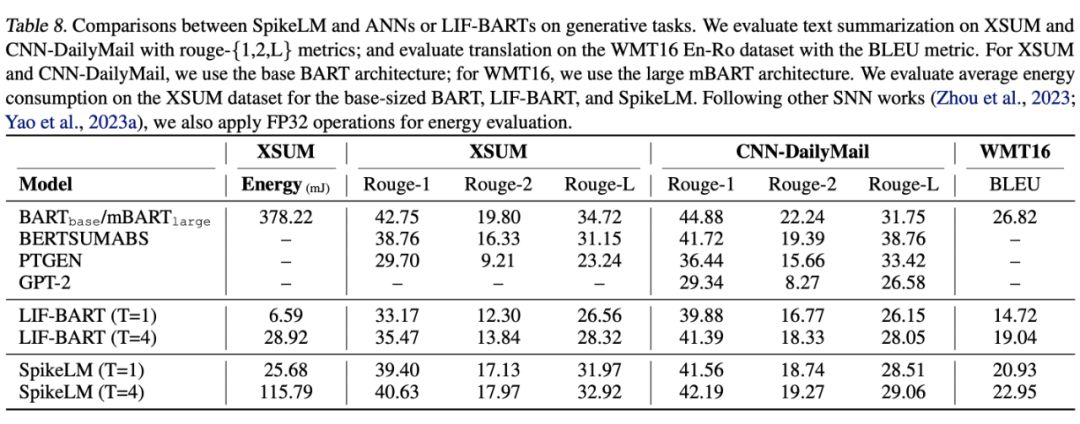
我们使用 BART-base [7] 或 mBART-large 结构的 SpikeLM 和基线模型 LIF-BART 对比。我们选择文本摘要任务和翻译任务进行评估,SpikeLM 在各类下游生成任务中可以有效减少精度损失。

结论
本文通过一系列脉冲增强方法,展示了使用脉冲方向,频率和幅度编码提升脉冲语言模型的可行性。首次证明了完全脉驱动的 transformer 模型在通用语言任务上的有效性。在未来的工作中,如何训练具有生物可解释性和低功耗特性的脉冲大模型成为了具有潜力的方向。

参考文献
[1] Zhu, R.-J., Zhao, Q., Li, G., and Eshraghian, J. K. Spikegpt: Generative pre-trained language model with spiking neural networks. arXiv preprint arXiv:2302.13939, 2023.
[2] Lv, C., Li, T., Xu, J., Gu, C., Ling, Z., Zhang, C., Zheng, X., and Huang, X. Spikebert: A language spikformer trained with two-stage knowledge distillation from bert. arXiv preprint arXiv:2308.15122, 2023.
[3] Chen, Z., Deng, L., Wang, B., Li, G., and Xie, Y. A comprehensive and modularized statistical framework for gradient norm equality in deep neural networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44 (1):13–31, 2020.
[4] Ying-Hui Liu and Xiao-Jing Wang. Spike-frequency adaptation of a generalized leaky integrate-and-fire model neuron. Journal of computational neuroscience, 10:25–45, 2001.
[5] Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
[6] Xing, X., Du, L., Wang, X., Zeng, X., Wang, Y., Zhang, Z., and Zhang, J. Bipft: Binary pre-trained foundation transformer with low-rank estimation of binarization residual polynomials. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 16094–16102, 2024.
[7] Lewis, M., Liu, Y., Goyal, N., Ghazvininejad, M., Mohamed, A., Levy, O., Stoyanov, V., and Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461, 2019.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 4579
4579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









