







©PaperWeekly 原创 · 作者 | 刘芷宁
学校 | 伊利诺伊大学香槟分校
研究方向 | 不平衡学习、可信机器学习
在深度学习中,样本不均衡普遍被认为是数据集中不同类别的样本数量不等。特别地,当训练集和测试集的类别分布不匹配时,采用处理样本不均衡的策略显得尤为重要。
然而,当训练集和测试集分布匹配,但是正负样本比例仍然是悬殊的,这种情况下是否有必要再引入处理不平衡样本的策略?例如,在自然科学领域,如预测药物与靶点结合(即正负样本)的场景中,实际情况往往是正负样本本身不均衡的。在这种情况下,使用过采样等技术人为使训练集中的正负样本比例达到 1:1 是否合理?
笔者做过相当长一段时间的不平衡/长尾问题,上述内容对两个问题答案的假设一对一错。
Q:是否应该打破正负样本 1:1 的迷信思想?
A:是的,类别不平衡的比例只是表象,并非本质。Q:当训练集和测试集分布匹配,但正负样本比例仍然悬殊,是否有必要再引入处理不平衡样本的策略?
A:通常需要,除非你只关心 overall accuracy,但这意味着你几乎不关心模型分类少数类的能力。

Q:是否应该打破正负样本1:1的迷信思想?
长话短说,正负样本并不需要是 1:1,因为类别不平衡的比例一直只是表象,问题的本质从来都是如何帮助模型对每个类(尤其是少数类)都学习到合理的表示。而后者和正负样本比例之间并没有直接的关系。
理论上如果任务足够简单(如完全线性可分,且满足 train/test i.i.d),那么无论正负样本比例多悬殊,模型都能够对测试数据进行完美分类。当然这只对一些直接使用全量数据学习的模型成立,比如决策树、SVM 等。在实际中训练 NN 需要进行 batch-wise 的随机梯度下降训练,连续多个 batch 都只有来自负类的数据会让模型很快收敛到一个 local optimal solution,将所有数据全部预测为负类。
因此出现了其他答案所提到的一些经验结果(如 1:10 等比例),这些比例应该是在特定场景下能够避免模型训练过程 collapse 的比例。
具体在特定场景下,采用什么正负比例还是需要根据实际的 task、model,和 metric 决定。我不认为这个问题存在一个可以解决一切的 magic number。
为什么正负样本比例不一定重要:一个 toy example
见下图,用一个 toy example 就可以从直觉上解释为什么正负样本的比例并不是唯一决定任务难度的因素。
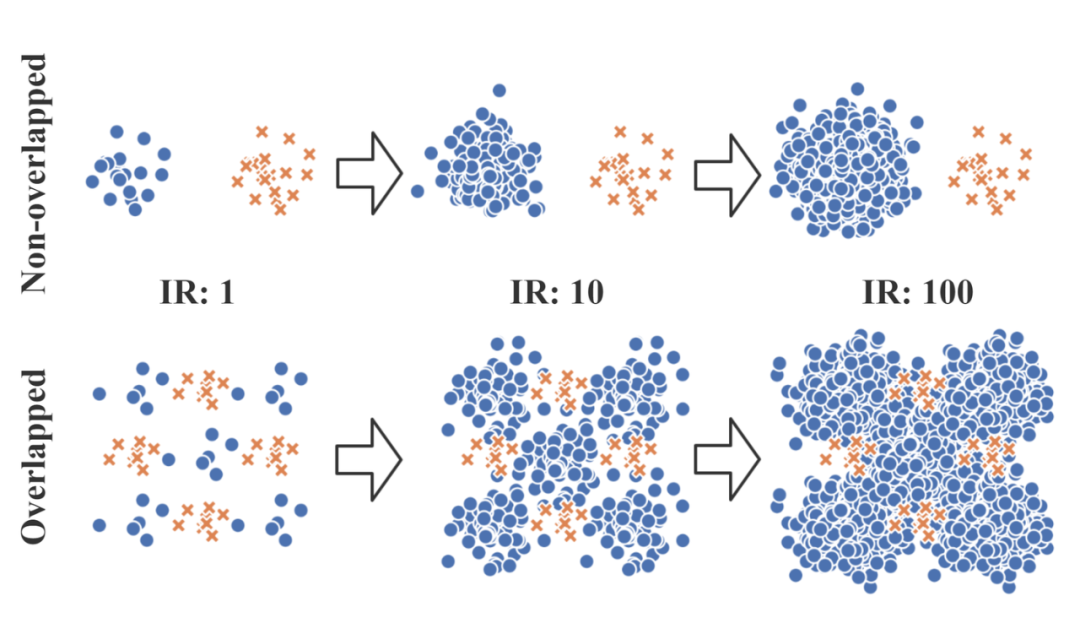
▲ 从左到右:类别比例(imbalance ratio/IR)逐渐增长。第一行:一个线性可分的简单任务。第二行:一个相对困难的复杂任务。
如果任务很简单(如上图第一行的数据分布,线性可分) ,那么即便有很悬殊的正负样本数量比例(如最右侧,正负样本 1:100),也不影响模型可以直接在原始数据上学习得到一个完美的分类边界,并实现 0 错误率:见下图第一行,即使 IR=100 模型也可以实现 0 分类错误(分类错误的 sample 由红色表示)。
而如果任务本身就很困难(如上图第二行,不同类别的 underlying distribution 有较大 overlap 且在 feature space 中有复杂的 pattern),那么即便正负样本比例差距不大,同样的模型也很难学到合理的边界(见下图第二行)。

▲ 第一列:任务示例。第二/三列:KNN/AdaBoost 分类器在每个任务上的结果。红色的点被误分类。
更多的讨论请见我们的 ICDE‘20 论文:
https://zhuanlan.zhihu.com/p/86891438

Q:当训练集和测试集分布匹配,但正负样本比例仍然悬殊,是否有必要再引入处理不平衡样本的策略?
A:通常需要,除非你只关心 overall accuracy,但这意味着你几乎不关心模型分类少数类的能力。
如上所述,如果两类样本数量悬殊且不做任何处理,模型会连续很多 batch 都只遇到来自负类的样本,这容易使其收敛到 trivial solution。将所有样本预测为负类的 trivial solution 会有很高的 overall accuracy(例如正负比 1:10000,那其 acc=99.99%)。
但通常我们都更加关心少数类样本(positive cases,例如医疗诊断中的病人、欺诈/攻击检测中的恶意用户等)并使用 balanced accuracy,macro-f1 等 metric。优化这些更加合理的 metric 就需要引入处理不平衡样本的策略。

Q:重采样之余,还有哪些方式处理类别不平衡?
重新采样改变正负样本比例只是其中一种从数据出发的方式。我开发的 imbens package 实现了为类别不平衡设计的十几种重采样技术与 ensemble 学习方法,具有与 sklearn-style 的易用 API 设计和详细的文档及示例,并已在 github 收获近 300 星,每月下载逾 2000 次:
https://github.com/ZhiningLiu1998/imbalanced-ensemble
https://zhuanlan.zhihu.com/p/376572330

▲ 一些 IMBENS 官方文档中提供的使用示例

▲ IMBENS Github Page Shot
在重采样之余,处理深度学习的不平衡有很多从其他方面入手的经典例子:
类别重加权:Class-Balanced Loss Based on Effective Number of Samples(CVPR 2019)
难例挖掘:Focal loss for dense object detection(ICCV 2017)
margin-based loss:Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss(NIPS 2019)
meta-learning 自动学习加权/采样策略:
MESA: Boost Ensemble Imbalanced Learning with MEta-SAmpler(NeurIPS 2020)
Meta-weight-net: Learning an explicit mapping for sample weighting(NIPS 2019)
设计特殊模型架构:BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition(CVPR 2020)
改变训练过程/策略:Decoupling Representation and Classifier for Long-tailed Recognition(ICLR 2020)
后验概率校正:Posterior Re-calibration for Imbalanced Datasets(NeurIPS 2020)
更多相关的技术和论文,请见我们的 awesome-imbalanced-learning 项目,已在 github 上收获逾 1.3k 星:
https://github.com/ZhiningLiu1998/awesome-imbalanced-learning
https://zhuanlan.zhihu.com/p/111460698
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 2128
2128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









