








PaperWeekly:肖博士您好,非常荣幸今天能够与我们进行一次交流。最近我们看到 Jina AI 发布了不少新模型比如 jina-embeddings-v3 还有 reader-lm, 这也让我们对您和公司的近况非常感兴趣。您可否先简单介绍一下您的公司?
肖涵:好的!非常荣幸参与这次访谈,我是肖涵,Jina AI 的 CEO。Jina AI 是一家在 2020 年成立于德国的初创公司,专注于搜索领域的底座模型的研发,比如 Embeddings, Reranker 等等。总部位于德国柏林,在北京和深圳也有少量研发,目前公司总共有 32 人。

PaperWeekly:您平时是 base 在哪里?似乎在国内并不常见您参加活动?
肖涵:我平时 base 柏林办公室比较多,有时也会去美国待一阵儿。所以我国内的活动确实因为时间地理原因,参加的并不多。每年我会回国呆一两个月,一般我不在的时候我们的 CTO 王楠博士会去出席国内活动。我一般着重参加一些国际活动,尤其是一些学术顶会,比如 ICLR, ICML, EMNLP 这些的。
PaperWeekly:所以今年年底的 EMNLP 您也会去参加么?是有发表的论文么?
肖涵:对的,EMNLP 是我非常喜欢的一个会议。11 月我会去迈阿密参加 EMNLP,我们有一篇多语言的 jina-ColBERT-v2 模型,是一个基于 Late Interaction 迟交互架构的召回模型,到时候会在 MRL workshop 里讲讲背后的训练方法和技术。这个我一会儿也会展开详细讲一下。我一般参加学术会议还是以学习为主,讲我们自己的模型这个倒是其次。主要是能够接触到聪明的年轻学生,获得很多启发和活力,这个是我非常享受的过程。
PaperWeekly:好的,非常期待您的分享!我们也是看到 Jina AI 最近好像发布了很多很火爆的模型,一会儿也请您一并分享一下。对了,您刚才说到 Jina AI 专注于搜索”底座模型“,您可否详细讲解一下什么是”搜索底座“?
肖涵:中文读起来可能稍微有点奇怪,不过我们的英文的原文是 Search Foundation Models,你去我们的官网就会看到一个醒目的大字写着 Search Foundation, Supercharged! 直译过来就是我们给你的搜索底座/底盘超充。所以搜索底座模型本身也是底座模型 Foundation Model,但是他并不是通用的底座模型,并不能像 Llama, Qwen, GPT-4o 一样可以写代码写诗,他被设计成只能做搜索相关的任务,并且针对搜索任务做了特别的设计和优化。
有些人可能会觉得只有大模型才配被称的上是底座模型,因为底座必须是通用的,搜索这种细分领域不能算。我的理解是,搜索本身是一个广泛的需求,很多智能的交互体验底层都离不开搜索,而把搜索模型做成”搜索底座“,也是我们公司的一个目标,我希望我们的模型能够向大模型一样通用,被各个公司应用到解决各种搜索相关问题上。
PaperWeekly:明白了,那具体哪些模型算是搜索底座呢?比如 RAG 么?
肖涵:RAG 太过宽泛了,他属于一种设计范式,而非单一的搜索模型。就跟计算机科学中的 divide-and-conquer,map-reduce 一样,非常宽泛,什么都可以往里划,但是具体实现千差万别。我们公司肯定会关注 RAG 的发展,但我们不会说自己是一个 RAG 公司,太空了。
具体到 Jina AI 的产品路线图来讲,我们研发的搜索底座模型主要包括 Embeddings, Reranker 和 Reader。Embeddings 就是为多语言和多模态数据设计的向量化模型,将文本或图片转化成定长向量。
Reranker 是基于 query-documents 设计的精排模型,给定一个 query 和一堆文档,直接输入模型,然后根据 query 输出文档的相关性排序。Reader 是我们最近发布的一条新的产品线,主要目标是使用生成式小模型 (SLM) 实现单文档上的智能,比如数据清理过滤提取等等。这三个模型的灵活结合可以满足开发者和企业构建类似 RAG, Agent 等上层应用,但我们本身不去做端到端的 RAG 编排系统,我们还是关注底座模型本身。
PaperWeekly:是的。向量模型确实是搜索中非常重要的一个环节。我看到 Jina AI 最近发布了 jina-embeddings-v3 和 reader-lm-1.5b/0.5b,也是获得了非常多的市场关注。您能大概介绍一下这两个模型么?
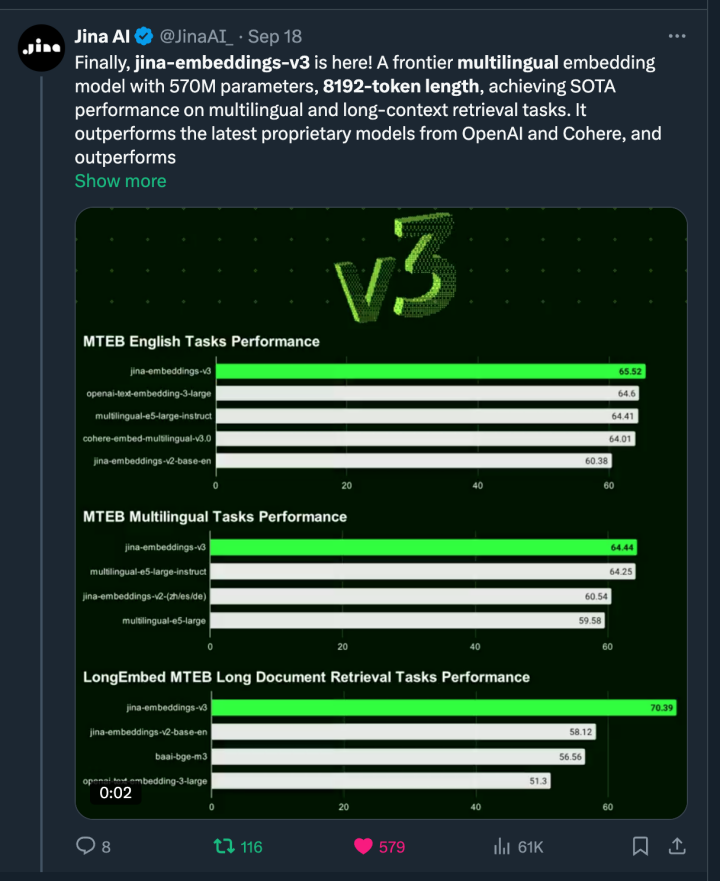
肖涵:jina-embeddings-v3 是我们 9 月 18 号发布的第三代向量模型,参数量为 0.5B。相比于 2023 年 10 月发布的 v2,主要加了多语言的支持,并且极大的提升了多任务下的性能,和进一步优化了长文本的支持,并且通过 MRL 套娃技术允许用户自由选择输出维度。在发布当日在 Huggingface 的 MTEB 榜单上,我们的 v3 不仅是 1B 参数量下性能最好的,超过了 OpenAI 的 text-embedding-large 和 Cohere 的 v3 模型(这两家都是闭源模型),也比开源多语言模型的标杆,multilingual-e5-large-instruct 好上不少。
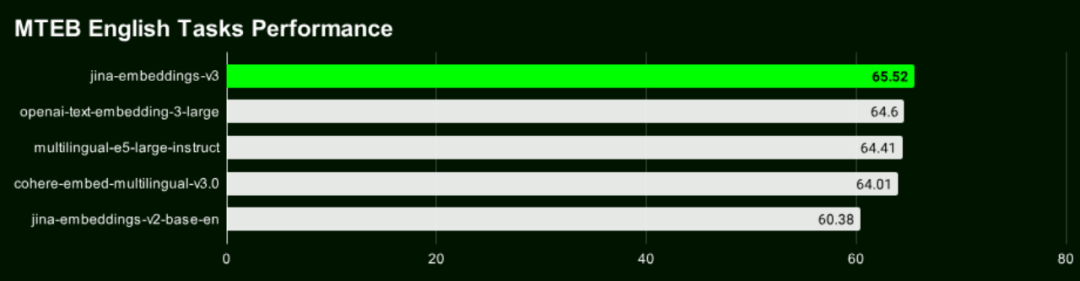
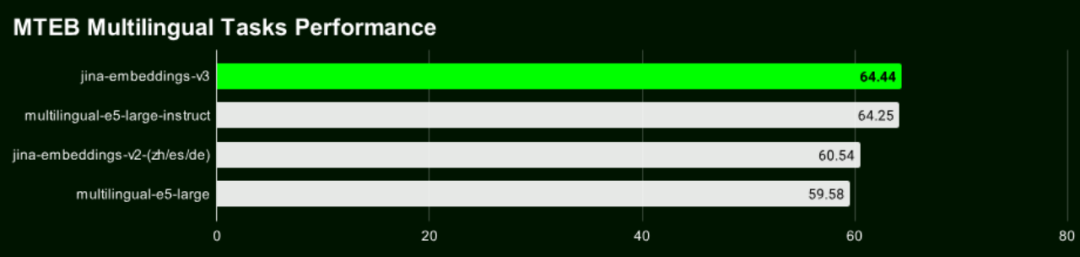
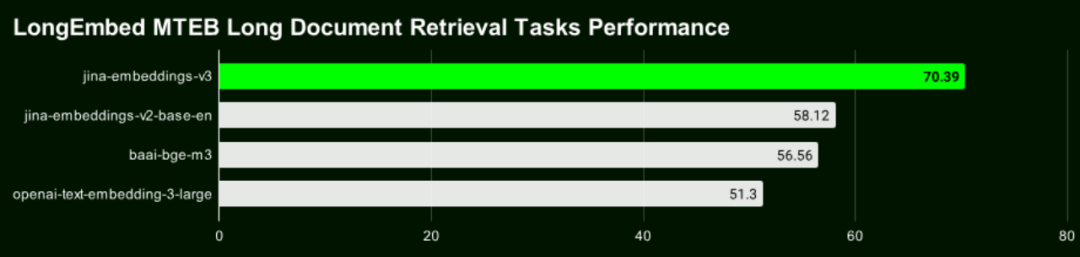
PaperWeekly:说起 v2,我好像有点印象去年 v2 当时发布时,当时是以唯一一个开源 8192 输入长度 OpenAI 的 text-ada-002 性能追平。那时好像还在 HackerNews 上引起很多讨论。所以时隔一年 v3 卷土重来了?
肖涵:可以这么说。不过去年的 v2 是一个纯英语的模型。而 text-ada-002 是一个多语言的 embedding 模型,所以当时我们说性能追平其实只是在英语任务上,有点水分在里面。
不过我们经过一年多的经验和数据积累,这期间其实我们基于 v2 又训练和发布了几个双语模型,比如德英,中英,西英,代码模型;还有包括多模态的 jina-clip,背后的 text-tower 实际上是 v2。基于迟交互的的 jina-colbert,jina-colbert-v2 背后的底座也是 v2。所有这些模型训练的经验和数据的积累,终于今天让我们在多语言任务上超过 OpenAI 和 Cohere。
PaperWeekly:那 v3 是在 v2 的基础上改进的吗,还是完全重新设计的?
肖涵:那倒不是。v3 重新设计了 XLM-RoBERTa 模型,比如使用 RoPE 去做 position embeddings 以保证长文本召回性能,FlashAttention2 去改进注意力机制的训练和推理性能。与 v2 类似,我们采用多阶段训练方式:从头开始对整个模型预训练,二段 pairwise 训练,三段 hard-negative triplet 训练。
与 v2 不同的是,我们在模型中加入了五组针对不同任务的 LoRA Adapter,分别针对 QA 检索,分类,聚类,相似匹配。在推理时,用户可以根据不同的下游任务选择适合自己的 Adapter,这样就保证了输出的 embeddings 永远是最优的。
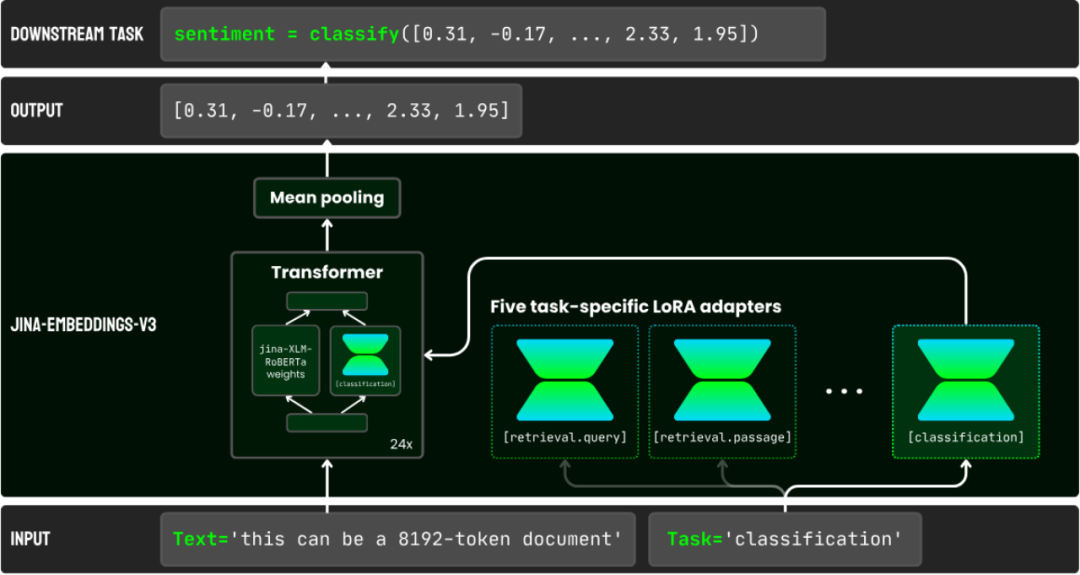
PaperWeekly:听起来 v3 背后的设计确实有点复杂。不过我有个疑问,为什么要为不同任务设计特定的 embedding 呢?我以为搜索就是计算查询和文档之间的向量相似度。
肖涵:对,大多是 embedding 模型确实是这样被使用的。但是真正做搜索系统人知道,用户输入的 query 和目标文档是异构的:比如 query 可能很短很随意的几个关键词罗列,比如"openai o1 model planning" 而目标查询文档是严肃且长的论文《Learning to Reason with LLMs》。
这一短一长不同的语言风格,其实很难被同一个模型映射到同一子空间,强行匹配的话就会出现很多问题。于是也就衍生除了一大堆启发式的算法,比如 query重写,query 扩展,document 切块 (chunking),这就是非对称检索,在客服系统中”问题“和”答案“的异构也是类似的情况,这些重写和切块的启发式算法就是为了在预处理时间就把这些异构体处理掉,然后向量模型就可以直接处理同构数据。
也有不少向量模型为了更好的编码这种异构情况时就会妥协一些其他任务上的性能(比如分类,聚类);或是既不做优化也不做妥协从而做到”通用“,结果就是每一项任务的性能都很一般。
PaperWeekly:所以 v3 在处理这类情况的时候是“既要又要”?
肖涵:是。“既要又要”就是通过训练和调用不同的 LoRA Adapter 来实现。异构搜索确实是 embedding 一大场景,但是同构匹配也是强需求:比如推荐系统中给定一篇长论文,查找最相似的几篇论文。选中某一行代码或函数,IDE 中显示项目仓库中相关的代码或函数。
我们既然目标是做搜索底座模型,那就不能按下葫芦起瓢的去优化某一任务。我们针对异构搜索、同构匹配、分类、聚类四类任务做了特别的 Adapter 设计和训练,基本上 Embedding 的使用场景都可以被划分到这四类任务上。
PaperWeekly:所以相当于 v3 走了两步?先输出一个 meta embedding,然后通过特定任务的 adapter 映射到任务空间上得到最终的 embedding?
肖涵:不是的,就只有一步。LoRA adapter 其实被插入到 24 层 Transformer 的每一层中了。你在选择一项任务时,那个任务对应的 LoRA adapter 就会被激活,从而参与到每一层的计算中来。具体的技术细节可以看我们的论文:
jina-embeddings-v3: Multilingual Embeddings With Task LoRA
https://arxiv.org/abs/2409.10173
PaperWeekly:一定仔细拜读!其实我听到 2024 年还有人这么细扣的去做向量模型还有点惊讶的。毕竟您知道,现在满天都是 LLM,向量模型似乎是上个时代的遗物。您是怎么看待这个问题的?
肖涵:确实我们 23 年 10 月刚发布 v2 的时候,有很多人会质疑我们的方向说“啊都什么年代了,还搞 embedding,不就是个 word2vec 升级版么?老土!” 我其实是这么理解的,首先我说句比较大而空的:我们 Jina AI 的工作不是 work for hype,而是 work for action。我们看中的不是热度在哪,而是实用度在哪。
其次,凡是认为向量模型还停留在 word2vec,BERT 这种的人应该多读读论文。其实 Embedding 模型和 LLM 这种生成模型都是基于 Transformer 架构的,只不过前者是 encoder-only,后者是 decoder-only,差别就在于 attention mask,其余的很多技术都是通用的。
这就意味着,二者的知识和经验是可以融会贯通的。比如我们在设计 v3 时,就借鉴了很多大模型上的一些新技术比如 RoPE, instruct tuning 还有 FlashAttention2 的实现。反过来,也有不少魔改大模型去做 embedding 的,比如 NV-Embed-v1/v2。最后,行业的发展本身也会促进 Embedding 模型本身不断的发展,比如过去一年里,多语言多模态的 Embedding 需求猛增,其下又可以细分出跨语言和跨模态。
长文本需求猛增、多粒度(比如在 chunk,token)级别的召回需求猛增,这些都促成了很多新的技术的发展,比如我们提出针对长文本 chunking 的 Late Chunking 技术《Late Chunking: Contextual Chunk Embeddings Using Long-Context Embedding Models》(https://arxiv.org/abs/2409.04701),还有基于迟交互的 ColBERT, jina-ColBERTv2 模型,这些新技术都给向量模型注入了很多的活力。
PaperWeekly:您刚才提到了 NV-Embed-v1/v2 这种基于大模型魔改的 Embedding模型,我看他们在 MTEB 排行榜上表现很好;您的团队现在积攒了不少经验了,不知道您会不会也去做大模型?
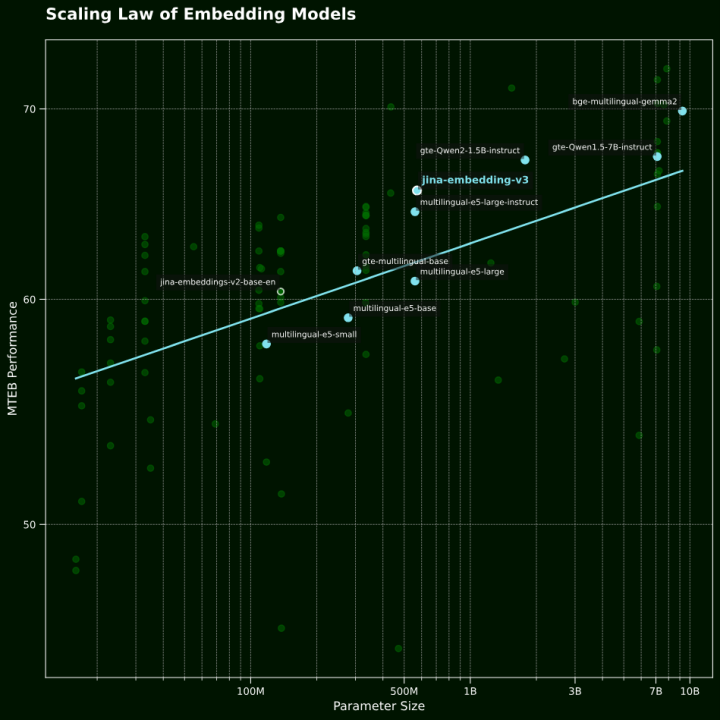
肖涵:不会。我自己并不觉得模型越大越 sexy。我认为 1B 参数量以下小模型是未来的趋势,垂直领域,为解决特定任务而设计的小模型是让我兴奋的点。比如我们看 v3 这个模型,我们可以把 MTEB 上排名前 100 的模型按照参数量大小的分数用散点图画出出来,就会得到一张 Embedding 模型的"Scaling law"。
总体趋势确实是参数越大性能越好。但是这个里面也涉及到模型训练的有效性:即通过加大参数量所带来的提升是否值得。比如我们拿 v3 和 e5-mistral-7b-instruct 比较,就会发现后者的大小是我们的 14 倍,但分数只比我们高 1%。像这种以空间换性能的交易我就认为非常不值得,为向量模型增加了很多使用门槛。这就是我为什么觉得 v3 好,在于他是 1B 以下训练最充分的模型。
PaperWeekly:所以您觉得未来是小模型 (Small language model) 的天下?
肖涵:是的。不过我一般避免谈论所谓的 End-game,“终局”,因为 AI 行业和技术都在快速发展,动不动就谈论所谓的“终局之战”显得非常不靠谱。我在此做一点阐述讲下为什么我看好小模型。
我比较喜欢车,我就拿内燃机的油车的发展来做个比喻。我们今天所说的 6 缸 8 缸大 V8 这种内燃机其实几十年前就有了。但是这些 6 缸 8 缸机的马力远远不及今天。几十年前的 8 缸机可能只有两百多匹,现在的 8 缸机马力可以上到五六百匹,如果再加上电机辅助甚至近一千匹。
但是你仔细比较发动机舱的大小和车子的整体的重量,其实并没有因为马力大而变得很夸张。也就是说内燃机通过几十年的发展,在相同的空间复杂性下,实现了更优的发动机性能。这其中很多细扣的东西,比如点火时机,排列方式,进出气阀的设计等等。
我认为大模型的发展会是也一样,我们今天拿 3B 的模型和 2022 年 3B 的模型去比,会发现今天的 3B 性能要好很多,为什么呢?因为我们对于细节的把控更成熟了。比如注意力机制的优化,比如位置信息的编码,比如训练样本的 instruction 构建方式,比如多阶段训练的引入,这些都会提升相同参数量下模型的性能,也就是“马力”更大了。
我记得之前在哪里看到过,在一九四几年有人预言美国市场上只需要四台计算机,一台给军方,一台给政府,一台给交易所,一台给研究所。结果今天计算机的发展和需求远超这个预言,除了手机笔记本等个人小型计算机,小到手表,扫地机器人,洗衣机,烤箱中都有计算机。这就有点像我们今天对于大模型发展的预测。“超算”级别的大模型会一直存在,但小而专的模型会逐渐兴起占领市场,且需求量远比“超算”更大。
PaperWeekly:这个比喻还挺有意思的,我经常听到的比喻是说当今 AI 泡沫就像当年互联网泡沫,所以经常会有人拿大模型的发展和互联网的发展去做类比。
肖涵:我觉得大模型这波还是不太像互联网,更像是计算机。互联网讲的更多的是一个网络效应,比如六度分隔社交论, page-rank 这种。而大模型和计算机类似都是输入->处理->输出的范式,硬说大模型也有网络效应我觉得比较牵强。
PaperWeekly:我看您最近还发了一个 Reader-LM,是一个 1.5B 的生成式小模型,在国际社区的热度也是很高,能讲一讲这个 Reader-LM 么?他是做什么用的?
肖涵:Reader-LM 是我们训练的首个 decoder-only 的模型,用于转换 HTML 到 markdown。也就是说输入是一个野生的 HTML 源文件,包含 css, js, 各种 tag 脚本,然后输出是一个整齐的 markdown 文本文件,可以方便作为大模型的输入。我们发布了两个模型 0.5B 和 1.5B,输入窗口大小都是 256K,都支持多语言。
PaperWeekly:这个任务似乎更适合用正则表达式来解决啊,用语言模型来做是不是有点大材小用了呢?
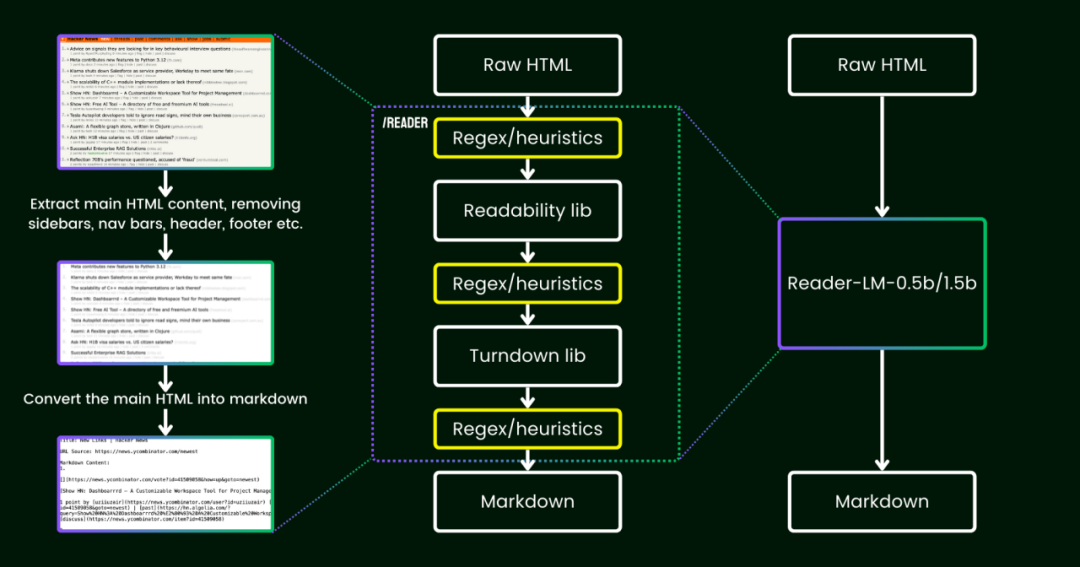
肖涵:其实 Reader-LM 这个思路的源头就是来自于我们搜索底座中的一个非常流行的产品 Jina Reader,是我们四月份的时候发布的,你可以通过在任何一个网址前面增加 https://r.jina.ai 就可以把那个网页转化成整齐的 Markdown,从而让下游的 LLM 能吃到高质量的互联网数据。Jina Reader 的背后除了比较复杂的网络技术之外,就是利用基于启发式规则和正则做的一套 HTML 到 Markdown 清理转换的工作流。从这个角度讲,你可以把 Reader-LM 看做 Jina Reader 的一个“贵替”。
PaperWeekly:我其实没太明白您这边的逻辑,为什么要打造一个“贵替”呢?Jina Reader 解决的不够完美么?
肖涵:Jina Reader 在我看来还是比较完美的:体验好,速度快,用户粘性高,口碑好。我们在这边积攒了很多 API 设计和数据过滤清理的经验。之所以我们想打造一个基于语言模型的“贵替”,是出于两点考虑。
第一,启发式规则和正则表达式的主内容提取和转化往往针对英语效果比较好,但对于多语言网页来说非常不利于维护,基本就是见一个洞补一个正则。所以想拿语言模型搞一个端到端的方案。
第二,就是我看到我们公司内部的技术路线过于偏向 Encoder-only,对于 Decoder-only 往往是道听途说,知之甚少;我们需要有更牢固的技术沉淀。正如我前面所说的,大模型和 Embedding 本身就在于一个 decoder-only 还是 encoder-only,所以从这个入手学习一下 Decoder-only 对我们构建搜索底座肯定是有帮助的。
PaperWeekly:正好您这边 Jina Reader 采集了一些数据,可以拿来训练。
肖涵:那倒不会,我们不会拿用户的请求做训练数据,数据隐私肯定是一方面;而另一方面是我们的 SLM 模型对于训练数据质量要求极高。野生的数据基本不能拿来做有效的做训练。Jina Reader 本身这个 API 确实可以看做一个比较有效的数据产生器,我们可以用它去定向的生成某个领域的训练数据。
PaperWeekly:为什么会想到用小模型来做这个任务呢?我感觉大模型直接用 Prompt+HTML 似乎也可以很好的解决这个问题啊?
肖涵:大模型上用 Prompt 确实可以解决一部分问题。但我们之所以要在这个问题上用小模型主要是观察到这个任务的特殊性。一是,从 HTML 到 Markdown 的转化其实更多的是复制粘贴,而不是“真生成”。你仔细想就会发现,和那些动不动就七步成诗写代码的 LLM 来说,这里我们并没有生成什么新东西。输出 Markdown 序列中的 Token,往往本身就是来自于输入 HTML 序列。
从模型的角度来看,相当于扫描一遍输入序列,发现重要的 Token 我就留下,不重要的(比如导航条,js 脚本,广告)我就过掉。如果非说有什么生成的成分在里面,那就是 Markdown 特有的一些格式化语法比如(### 标题, *加粗*,|表格|)。所以从直觉上讲,LLM 应该是大材小用了,这种 90% 是"抄"输入的任务,SLM 应该能够胜任。
第二个特殊性是上下文长度,很多做后端和模型的人可能对今天的 HTML 源代码长度缺乏一定的认知,在今天这种 CSS,JS 充斥的网页中,单一 HTML 的长度轻松过 100K token 长度。这就要求我们设计的 SLM 必须能够处理长文本,8K, 16K 的窗口大小在这里则完全不够用。
总结起来,我们似乎需要的是一个“浅而宽”的网络,“浅”是指复制粘贴任务似乎比较简单,感觉不用太深的 Transformer 层就可以搞定;“宽”是指能够这个网络必须能够处理长文本。
PaperWeekly:确实。“浅而宽”的小模型听起来还挺靠谱的。
肖涵:对,最终我们确实也达到了了非常好的效果,尤其是 1.5B 的效果比大模型+prompt 的还要好很不少。
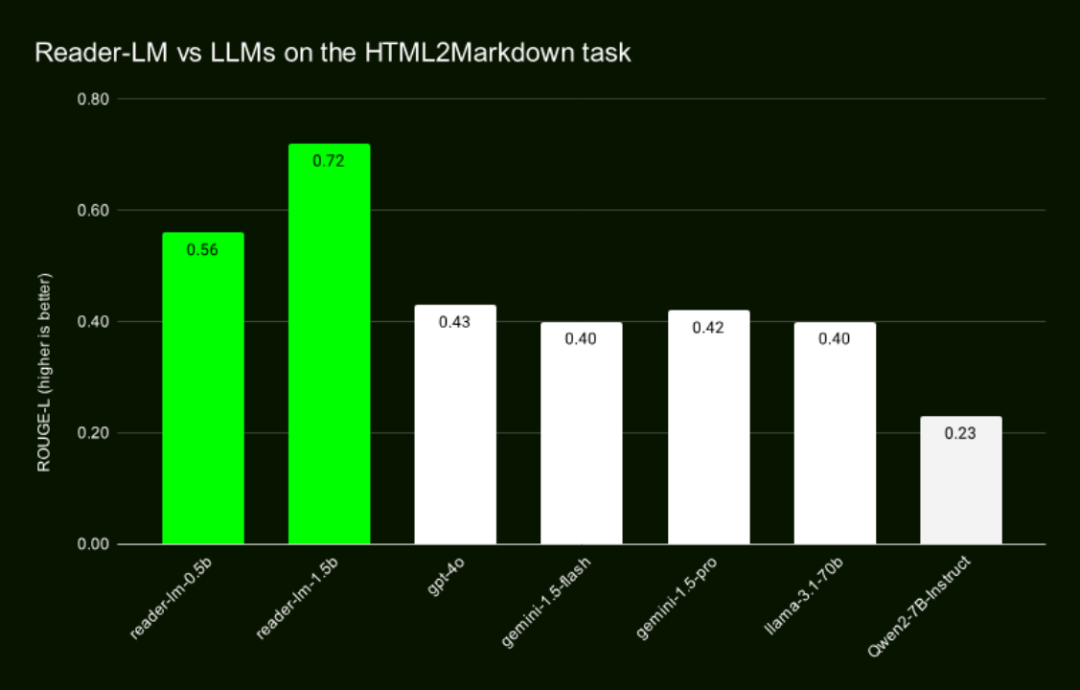
PaperWeekly:小模型的训练容易么?在这个过程中有没有遇到什么坑?
肖涵:坑还是非常多的。第一个就是我们一开始构想的所谓“浅而宽”的模型结构,实际训练起来非常困难,我们从最小的 65M 的模型开始训练,使用不同的底座模型,一直扩展到 3B 参数量都做了尝试。结果发现,模型的复制粘贴能力是需要足够深度的网络结构的。比如 65M 的模型在 1K 短序列下的复制粘贴还勉强能用,但是一旦输入序列变得更长,输出就变得非常混乱。
其实现在复盘起来,也容易从直觉上理解:虽然是“复制粘贴”这种简单任务,但在长文本下,选择哪些是需要复制到输出的,哪些是需要直接略过的,解决这个问题是需要一定的推理能力,而这种能力是层数过浅的小模型无法实现的。
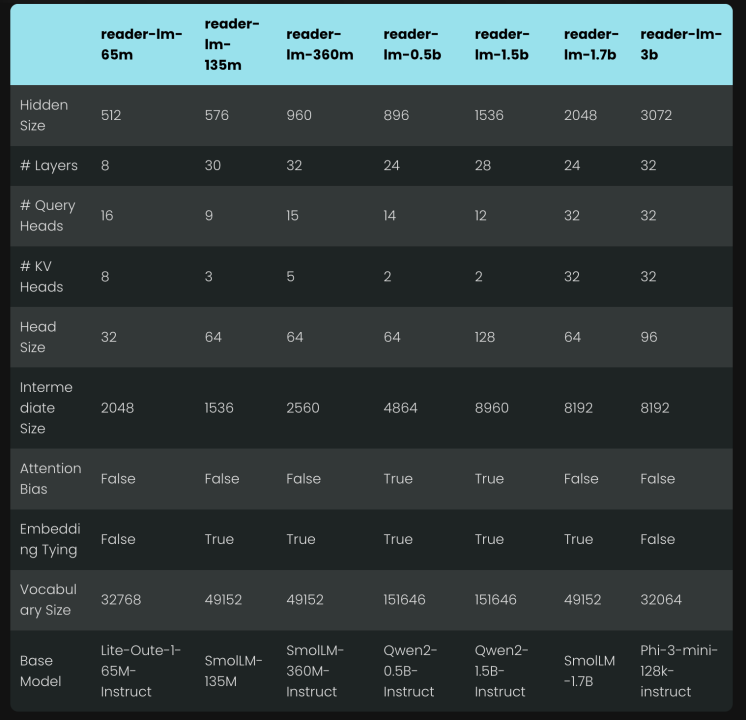
肖涵:小模型存在的另外一个问题是就是难训练。现在市面上很多小模型是从更大的模型通过一些裁剪蒸馏的方式得到的,所以是先有的大模型然后才有的小模型。小模型并不是天生就小,这就造成了这些小模型其实很难被二次训练。这就好比你拿了一大块玉原石打造成了一个小手镯,我再在这个小手镯上进行二次加工就有非常大的限制,不可能把这个手镯打造成一个玉佩。
我们在实际训练过程中发现越小的模型比如 65M 和 135M,这个问题就越明显。为了解决这个问题我们也是如同训练 embedding 一样进行了分段训练:第一阶段我们先用简单且短的(HTML, Markdown)数据对进行训练。短是指这些数据的长度小于 32K;而这里的“简单”是指没有太多的 css,js 引入的噪音,且网页内部结构相对线性,缺乏富媒体和嵌套结构。
而且我们使用 GPT-4 生成了一部分数据,生成的数据往往同质化非常严重,基本一眼就能看出来有固定的套路和模板。不过这些简单的训练数据为初始化小模型提供了很好的起点。第二阶段的训练,我们逐步加入更长和更复杂的 HTML,长度达 128K,这些数据往往来自于我们用 Jina Reader 爬取的真实数据。
PaperWeekly:感觉您特别喜欢多阶段训练和处理长文本,做向量模型用这套,做小模型也是这套。
肖涵:是的,这些“套路”都是我们积攒的一些实战经验。不过生成模型处理长文本更加吃显存,所以会引入一些特别的注意力机制的实现,比如 Ring Flash Attention (https://github.com/zhuzilin/ring-flash-attention) 还有 vLLM 实现更好的显存管理。
最终我们发布 0.5B 和 1.5B 两个模型,也是因为 0.5B是 性能达标的情况下最小的模型;而 1.5B 则是为了提升性能扩大参数量时最有效的一个模型。再大一点的模型,性能提升不明显,所以不值,不过也可能是我们的训练还不够充分。
PaperWeekly:和肖博聊了很多很硬核的技术,学到了不少干货。咱们 Reader-LM 和 Embedding 还会继续发布新的版本么?
肖涵:肯定的。Reader-LM-v2 和 Embeddings-v4 已经在规划了。不过大家不要等,v3 已经非常强大了。
PaperWeekly:期待!您对现在做 AI 的在校生有什么建议么,尤其是科研方向上的建议?
肖涵:好好学习。我离开学术圈比较久了,没有太多的实质建议。不过我一般开会的时候碰到学生都会多聊几句,大家到时候在 EMNLP 遇到我也不要害羞。

▲ 左二为肖涵博士
PaperWeekly:那您对创业者有什么建议么?或者是准备去投身 AI 创业的?
肖涵:这个我想说的可就太多了。首先我觉得有两点最宏观的需要创业者想清楚的。第一,你是真想创业当 Founder 还是想“Playing Founder”,什么叫 Playing Founder 呢?大家小时候都玩过过家家吧。我当爸爸你当妈妈,这就是"Playing Dad/Mom",角色扮演,假的,玩的。
有些人是享受这种“扮演”的感觉,并不是真的想当爸妈,也不是真的想当 Founder,这就是 Playing Founder。Playing Founder 的下场基本都是虎头蛇尾,干一两年就没动力继续了。那我觉得是一种浪费时间和自我欺骗。所以我觉得这个问题你在创业前一定要对着镜子好好问清楚自己。
第二,创业你是想“速赢”还是想“持久战”。这两个都算是创业的正常打法。速赢就是快速堆估值,在最短的时间实现成功退出。至于持久战,这就不用多解释了,大部分成功都是需要时间的积累和检验的。
有些人适合速赢,因为他的激情和兴趣来得快去得快,快速搞完一个初创再去做下一个;尤其是这两年,AI 领域的新概念层出不穷,今天 prompt,明天 agent,后天 CoT,每一个先概念也都会不断地撩拨你。打持久战的人则需要一直保持激情和耐心,静水深流,厚积薄发,甚至是忍辱负重,这些我就不多说了,大家小时候教室黑板上面贴的四字标语你就照做就 ok 了。
PaperWeekly:所以您现在在打持久战?
肖涵:是的。公司成立到现在也快 5 年了。现在的创业心态肯定和第一二年不一样。走过弯路,做过错误的决定,也用过错误的人。我也是花了四年多的时间,才想明白了自己想做什么样的公司,想明白自己愿意和什么样的团队在一起工作。
褪去了很多的掩饰和伪装,创业公司就是要做自己,不对平庸和世俗妥协。我现在做 talk 时自我介绍的时候就直接说我是 Jina AI 的 CEO,之前做过什么取得过什么我觉得没必要说。知道 Jina AI 的就是知道,不知道的就说明我还得努力。我最大的成功就是 Jina AI 的成功。
另外,很多人觉得 AI 公司靠一两个黑科技和大新闻就能出头,我不反对,但这是速赢者的思维。我也看过参与过很多讨论 AI 创业的壁垒在哪。在模型还是在应用。在我看来,壁垒不在于一个黑科技而在于一万个细节。一万个细节做的比别人好,那这个产品就是比别人好,这个公司就是比别的公司有竞争力。打持久战就是打的专注和细节,速赢派是很难理解的。
PaperWeekly:那您觉得现在是 AI 创业的最好时机么?
肖涵:创业永远没有最好的时机,而且真正的创业者也从来不会抱怨环境。创业最好的时机是昨天,其次是今天。
PaperWeekly:您现在每天还写程序么?
肖涵:写。从 Javascript 到 Python 到 LateX,什么都写,而且我特别喜欢写技术文章。我觉得 Tech Founder 最重要的就是 heads-down, hands-on,这个是不随时间和物质条件推移的。不是说我今天融了多少钱,搞了几百人的团队,我就可以夸夸其谈了。活到老、学到老、写到老。
PaperWeekly:对,我看 Jina AI 官网有非常多的高质量技术文章,不少是您写的。不过您这么投入做技术,是否会忽略公司整体的运营,比如商业化这些的思考?
肖涵:不会。商业化我永远是冲在最前面的,大到采购合同的审阅,小到 Paywall UI 的设计和措辞,细到每个国家在支付我们 API 的税收和货币,我都会事无巨细的去做。尤其是付费用户的反馈,我每一封邮件都会仔细阅读,分析用户的痛点和投诉。当团队回复的不好时,我会手把手的指导,也会自己回复客户。
很多人觉得不可思议,觉得不可能我一个人既做这个又做这个。其实也没有什么大不了的,一是 CEO 本身就需要是多面手和冲在最前面的那个人。二是这些事本来也不是什么难事,比起我读书时手推 Variational EM 的难度这都不算事儿。难就难在你愿不愿意去做而已,愿不愿意跳出舒适圈,这就是一个心态的问题。
第三就是榜样性。公司的 CEO 肯定要做标杆,值得被员工学习。员工觉得在你身边能够时时刻刻学到新东西,感受到解决问题的信心和力量。我觉得 CEO 对很多事情首先是要懂,懂>略懂>不懂>装懂。装懂最可怕:强了自尊心,惨了团队。
PaperWeekly:最后问您一个问题:您觉得 AI 领域这些方向,哪些是过热的 (over-hyped) 哪些是还不够热的 (under-hyped)?
肖涵:我觉得过热的是 LLM Framework,Orchestration 这套,比如 LangChain,LlamaIndex 这种。我不是说我不太看好这两个公司,而是我不看好这个方向。原因有三,模型迭代速度太快,所以最好学习模型的方法就是靠近模型层,而不是去通过一个高级抽象层去学模型。LangChain 和 LlamaIndex 这种就是高级抽象层。
第二,Framework 这种东西很早就有,比如 PyTorch, Tensorflow,但是我觉得在大模型时代,大家学习抽象层的动力会明显下降。2022-2023 年还好,LLM 刚兴起,学一学熟悉熟悉 Prompt 感受感受 LLM 的潜力,没啥问题。但是随着模型的发展,很多大模型可以直接从自然语言生成高质量的代码,不需要你再学一个中间语言去过渡。
就好比大家都知道 C 语言的执行效率高,但是又都懒得学,于是先 Python 写再用 Cython 完成从 Python 到 C 的翻译。如果 LLM 可以直接构造 Agent,Pipeline,甚至一步到位的给出代码,试问有多少人还愿意花精力去学一个中间层的糖水代码 (sugary syntax)?况且往往这种糖水代码本身的设计逻辑还不符合你的品味。反正我发现我自己 2024 年使用这种 Framework 的次数为 0,去年的时候好像使用过一两次吧,也不多。
第三点可能比较莫名其妙,不过我先抛出来,以后我们再看对不对:就是我认为未来的程序代码是单个文件的(Single-File System)而不是像现在文件夹里套文件夹,一个项目几百个文件。Framework 这种太重了,把一个简单的项目分散到很多很多个文件,不符合单文件的未来。所以你看我们自己的很多模型讲究长文本(比如向量模型),和单文本智能(比如 Reader-LM)。其实也是朝着这个未来做点准备。
还不够热的我觉得是 GenAI+游戏。我觉得利用多模态的 GenAI 可以极大的提高单机和多人游戏体验。尤其是过去十年开放世界游戏的普及,为 GenAI 在这方面的应用打造了一个很好的用户基础。无论是对话生成,剧情生成,任务生成,场景生成,可以做的东西太多了,而且每一个应用都是非常好的用户体验的探索。
从过去 70 年的历史上来看,计算机的发展绝对离不开游戏的发展。在 AI hype 的今天,在游戏这方面的落地我看到的还不够多。所以我认为它是 under-hyped 的。当然一个好的大型游戏研发周期比较长,有可能有游戏公司已经用上了 GenAI 去开发下一代产品我不知道而已。
PaperWeekly:非常感谢您的时间,这些访谈受益匪浅。请问我们的读者可以如何联系到您和您的公司?
肖涵:欢迎大家多关注我们的官网 (https://jina.ai) 。我们会经常更新一些技术文章和最新的成果。我们在微信公众号和海外的 X 社交账号(@JinaAI_)也有很多硬核内容。也欢迎加我微信 hxiao1987。最后就是期待和大家在 EMNLP 上相见。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









