








本文介绍 XLNet 的基本原理,读者阅读前需要了解 BERT 等相关模型,不熟悉的读者建议学习 BERT 课程 [1]。
语言模型和BERT各自的优缺点
排列(Permutation)语言模型
Two-Stream Self-Attention for Target-Aware Representations
没有目标(target)位置信息的问题
Two-Stream Self-Attention
部分预测
融入Transformer-XL的优点
Transformer-XL思想简介
Segment基本的状态重用
Transformer-XL的相对位置编码
在XLNet里融入Transformer-XL的思想
建模多个segment
相对Segment编码
XLNet与BERT的对比
XLNet与语言模型的对比
实验
Pretraining和实现
RACE数据集
SQuAD数据集
文本分类
GLUE数据集
ClueWeb09-B
Ablation对比
实验代码
语言模型和BERT各自的优缺点
在论文里作者使用了一些术语,比如自回归(Autoregressive, AR)语言模型和自编码(autoencoding)模型等,这可能让不熟悉的读者感到困惑,因此我们先简单的解释一下。
自回归是时间序列分析或者信号处理领域喜欢用的一个术语,我们这里理解成语言模型就好了:一个句子的生成过程如下:首先根据概率分布生成第一个词,然后根据第一个词生成第二个词,然后根据前两个词生成第三个词,……,直到生成整个句子。
而所谓的自编码器是一种无监督学习输入的特征的方法:我们用一个神经网络把输入(输入通常还会增加一些噪声)变成一个低维的特征,这就是编码部分,然后再用一个 Decoder 尝试把特征恢复成原始的信号。我们可以把 BERT 看成一种 AutoEncoder,它通过 Mask 改变了部分 Token,然后试图通过其上下文的其它 Token 来恢复这些被 Mask 的 Token。如果读者不太理解或者喜欢这两个 jargon,忽略就行了。
给定文本序列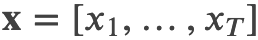 ,语言模型的目标是调整参数使得训练数据上的似然函数最大:
,语言模型的目标是调整参数使得训练数据上的似然函数最大:
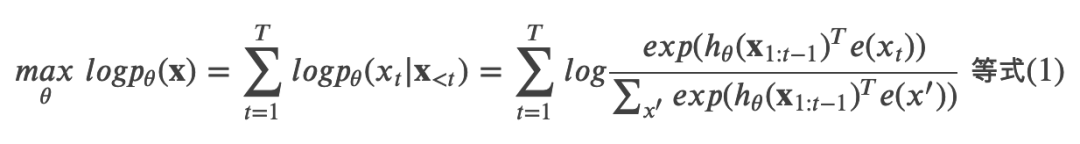
记号 ?<? 表示 t 时刻之前的所有 x,也就是 ?1:?−1。ℎ?(?1:?−1) 是 RNN 或者 Transformer(注:Transformer 也可以用于语言模型,比如在 OpenAI GPT)编码的 t 时刻之前的隐状态。?(?) 是词 x 的 embedding。
而 BERT 是去噪(denoising)自编码的方法。对于序列 ?,BERT 会随机挑选 15% 的 Token 变成 [MASK] 得到带噪声版本的![]() 。假设被 Mask 的原始值为
。假设被 Mask 的原始值为![]() ,那么 BERT 希望尽量根据上下文恢复(猜测)出原始值了,也就是:
,那么 BERT 希望尽量根据上下文恢复(猜测)出原始值了,也就是:
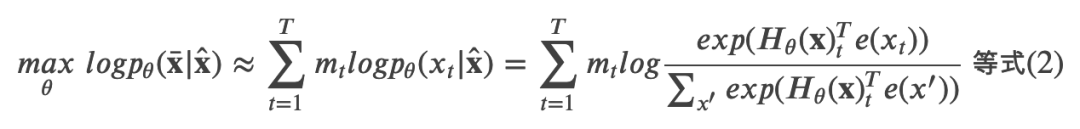
上式中 ??=1 表示 t 时刻是一个 Mask,需要恢复。?? 是一个 Transformer,它把长度为 ? 的序列 ? 映射为隐状态的序列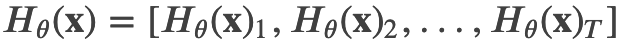 。
。
注意:前面的语言模型的 RNN 在 t 时刻只能看到之前的时刻,因此记号是 ℎ?(?1:?−1);而 BERT 的 Transformer(不同与用于语言模型的 Transformer)可以同时看到整个句子的所有 Token,因此记号是 ??(?)。
这两个模型的优缺点分别为:
独立假设:注意等式 (2) 的约等号 ≈,它的意思是假设在给定![]() 的条件下被 Mask 的词是独立的(没有关系的),这个显然并不成立,比如”New York is a city”,假设我们 Mask 住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。而公式 (1) 没有这样的独立性假设,它是严格的等号。
的条件下被 Mask 的词是独立的(没有关系的),这个显然并不成立,比如”New York is a city”,假设我们 Mask 住”New”和”York”两个词,那么给定”is a city”的条件下”New”和”York”并不独立,因为”New York”是一个实体,看到”New”则后面出现”York”的概率要比看到”Old”后面出现”York”概率要大得多。而公式 (1) 没有这样的独立性假设,它是严格的等号。
输入噪声:BERT 的在预训练时会出现特殊的 [MASK],但是它在下游的 fine-tuning 中不会出现,这就是出现了不匹配。而语言模型不会有这个问题。
双向上下文:语言模型只能参考一个方向的上下文,而 BERT 可以参考双向整个句子的上下文,因此这一点 BERT 更好一些。关于为什么 RNN 只能是单向的上下文而 BERT 可以参考整个句子的上线,读者可以参考 ELMo 和 OpenAI GPT 的问题 [2]。
排列(Permutation)语言模型
根据上面的讨论,语言模型和 BERT 各有优缺点,有什么办法能构建一个模型使得同时有它们的优点并且没有它们缺点呢?
借鉴 NADE(不了解的读者可以忽略,这是一种生成模型)的思路,XLNet 使用了排列语言模型,它同时有它们的优点。
给定长度为 T 的序列 ?,总共有 ?! 种排列方法,也就对应 ?! 种链式分解方法。比如假设 ?=?1?2?3,那么总共用 3!=6 种分解方法:
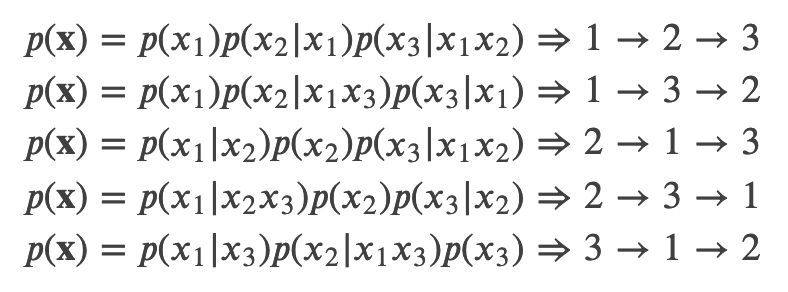
注意 ?(?2|?1?3) 指的是第一个词是 ?1 并且第三个词是 ?3 的条件下第二个词是 ?2 的概率,也就是说原来词的顺序是保持的。如果理解为第一个词是 ?1 并且第二个词是 ?3 的条件下第三个词是 ?2,那么就不对了。
如果我们的语言模型遍历 ?! 种分解方法,并且这个模型的参数是共享的,那么这个模型应该就能(必须)学习到各种上下文。普通的从左到右或者从右往左的语言模型只能学习一种方向的依赖关系,比如先”猜”一个词,然后根据第一个词”猜”第二个词,根据前两个词”猜”第三个词,……。
而排列语言模型会学习各种顺序的猜测方法,比如上面的最后一个式子对应的顺序 3→1→2,它是先”猜”第三个词,然后根据第三个词猜测第一个词,最后根据第一个和第三个词猜测第二个词。
因此我们可以遍历 ?! 种路径,然后学习语言模型的参数,但是这个计算量非常大(10!=3628800,10 个词的句子就有这么多种组合)。因此实际我们只能随机的采样?!里的部分排列,为了用数学语言描述,我们引入几个记号。![]() 表示长度为 T 的序列的所有排列组成的集合,则
表示长度为 T 的序列的所有排列组成的集合,则![]() 是一种排列方法。我们用 ?? 表示排列的第 t 个元素,而 ?<? 表示 z 的第 1 到第 t-1 个元素。
是一种排列方法。我们用 ?? 表示排列的第 t 个元素,而 ?<? 表示 z 的第 1 到第 t-1 个元素。
举个例子,假设 T=3,那么![]() 共有 6 个元素,我们假设其中之一 ?=[1,3,2],则 ?3=2,而 ?<3=[1,3]。
共有 6 个元素,我们假设其中之一 ?=[1,3,2],则 ?3=2,而 ?<3=[1,3]。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









