






改进鲸鱼优化算法(IWOA,自己融合了多策略改进,名字自己取的[破涕为笑]),具体改进公式会在readme说明文件中详细给出。
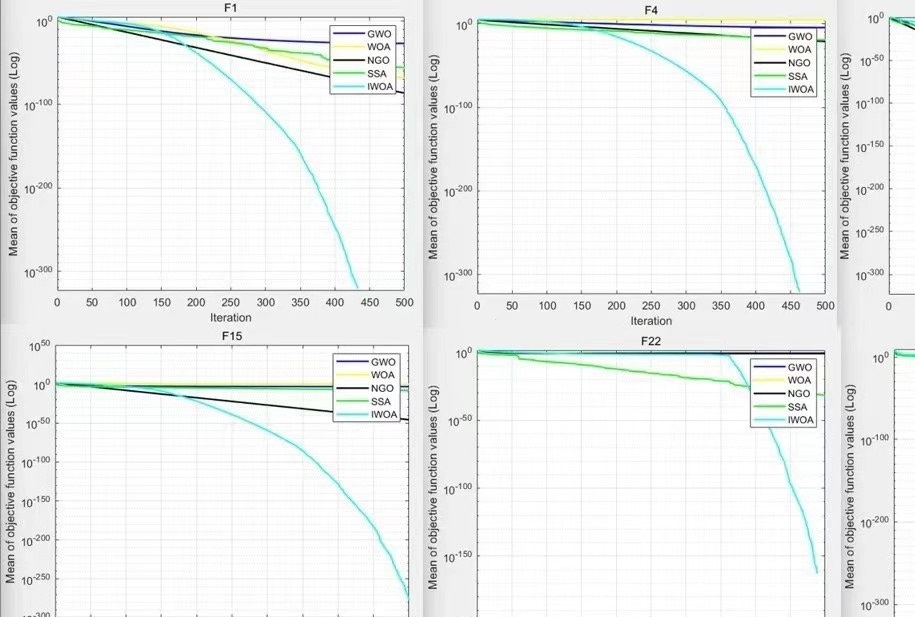
与鲸鱼算法,灰狼算法,麻雀算法,北方苍鹰算法,在初始种群为30,独立运行次数30,迭代500次做比较,效果如下。
该改进仍有很大优化空间,自己可以对参数进行优化,不同参数组合会对效果有较大影响,文件中会给出在哪优化,如何进行优化,只改了一个参数效果有了很大提升,见F4效果对比图。
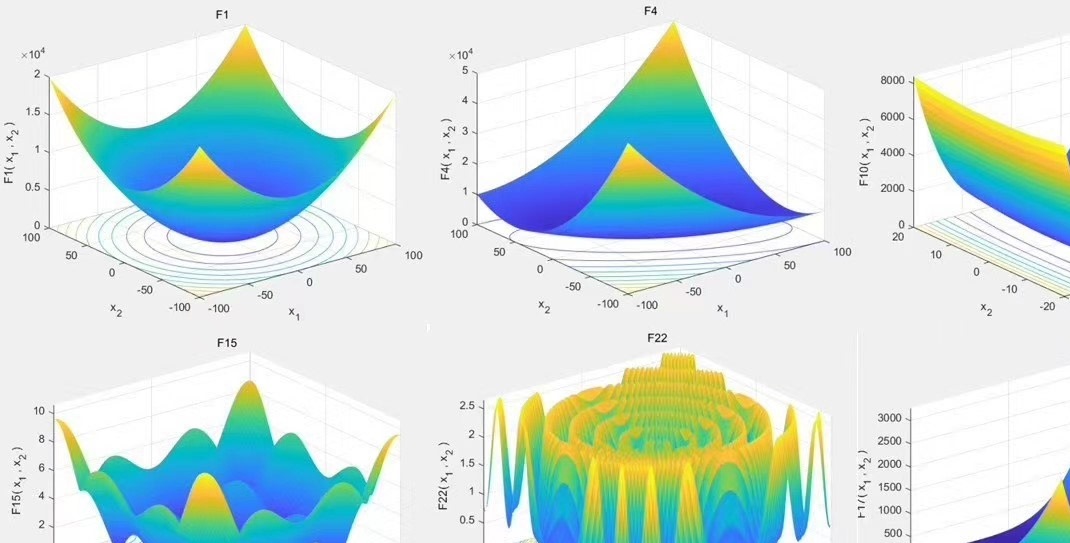
附带23种测试函数,测试函数对应波形如下,可对应收敛曲线一起看。
YID:3488721524585979
Mayaback

改进鲸鱼优化算法(IWOA,自己融合了多策略改进,名字自己取的[破涕为笑]),具体改进公式会在readme说明文件中详细给出。与鲸鱼算法,灰狼算法,麻雀算法,北方苍鹰算法,在初始种群为30,独立运行次数30,迭代500次做比较,效果如下。
在现代计算机科学领域,优化算法是解决复杂问题的重要工具。鲸鱼优化算法(IWOA)作为一种基于自然界鲸鱼行为的优化算法,已经在多个领域取得了显著的成果。然而,传统的IWOA算法在应用复杂问题时存在一些局限性,如收敛速度慢、易陷入局部最优解等问题。为了克服这些问题,本文提出了一种改进的鲸鱼优化算法(IWOA)。
在改进的IWOA算法中,我们自己融合了多策略改进,并为其命名为破涕为笑。具体的改进公式和策略会在readme说明文件中详细给出,这里不再赘述。为了评估改进后的算法性能,我们将其与其他几种优化算法进行对比,包括鲸鱼算法、灰狼算法、麻雀算法和北方苍鹰算法。
我们在实验中采用了相同的设置参数,包括初始种群数为30,独立运行次数为30,迭代次数为500次。通过对比实验结果,我们发现改进的IWOA算法在解决复杂问题时表现出更好的性能。
然而,尽管改进的IWOA算法已经取得了一定的改进效果,仍然存在一些优化空间。根据我们的实验结果,在不同的参数组合下,算法的性能会有较大的差异。我们在readme文件中详细说明了如何进行参数优化,以及优化的方向。值得注意的是,仅通过改变一个参数,我们就观察到了显著的改进效果,具体结果可参考F4效果对比图。
为了更直观地评估算法的性能,我们还提供了23种测试函数,并对应给出了波形图。这些波形图可以与收敛曲线一起观察,用于评估算法在不同问题上的表现。
综上所述,通过改进鲸鱼优化算法(IWOA),我们成功地提高了算法的性能,并在多个复杂问题中取得了良好的结果。然而,仍有一些优化空间可供进一步探索和改进。我们相信,随着更深入的研究和实验,改进的IWOA算法将在更广泛的领域发挥其优势,并为解决复杂问题提供有效的解决方案。
注意:本文所提到的IWOA算法改进是作者自行提出并进行实验的,相关的具体公式和策略会在readme文件中给出,本文不赘述。同时,参考文献和示例代码我们没有提供,读者可以参考我们提供的readme文件来了解更多详细信息。
【相关代码,程序地址】:http://lanzoup.cn/721524585979.html

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









