








 超级会员免费看
超级会员免费看

摘要
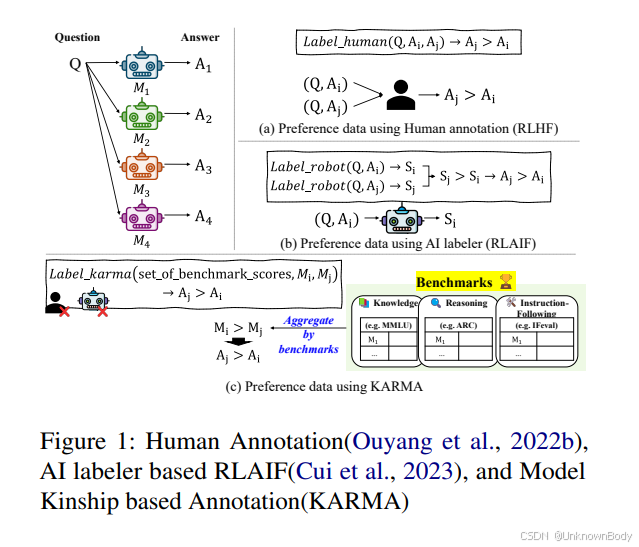
近期,大语言模型(LLM)校准领域取得了进展,旨在通过利用预训练模型生成偏好数据,从而降低人工标注的成本。然而,现有方法常常对能力差异巨大的模型的回复进行比较,只能得出表面上的区别,无法为判断何种回复更优提供有意义的指导。为解决这一局限,我们提出了基于亲属关系的偏好映射(Kinship-Aware pReference MApping,KARMA)框架,这是一种全新的框架,能够系统地将能力相当的模型的回复进行配对。通过将偏好比较限定在复杂度和质量相似的输出上,KARMA提高了偏好数据的信息含量,提升了校准信号的粒度。实证评估表明,我们基于亲属关系的方法能够带来更一致、更具可解释性的校准结果,最终为使大语言模型的行为符合人类偏好提供了一条更具原则性和可靠性的途径。
引言
使大语言模型(LLMs)与人类偏好保持一致,是人工智能领域的一项根本性挑战。校准的有效性,取决于用于指导模型输出的偏好数据的质量和特异性(Shen等人)。早期的校准方法,主要依赖带有二元偏好标签的人工标注数据集,通

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











