







 超级会员免费看
超级会员免费看
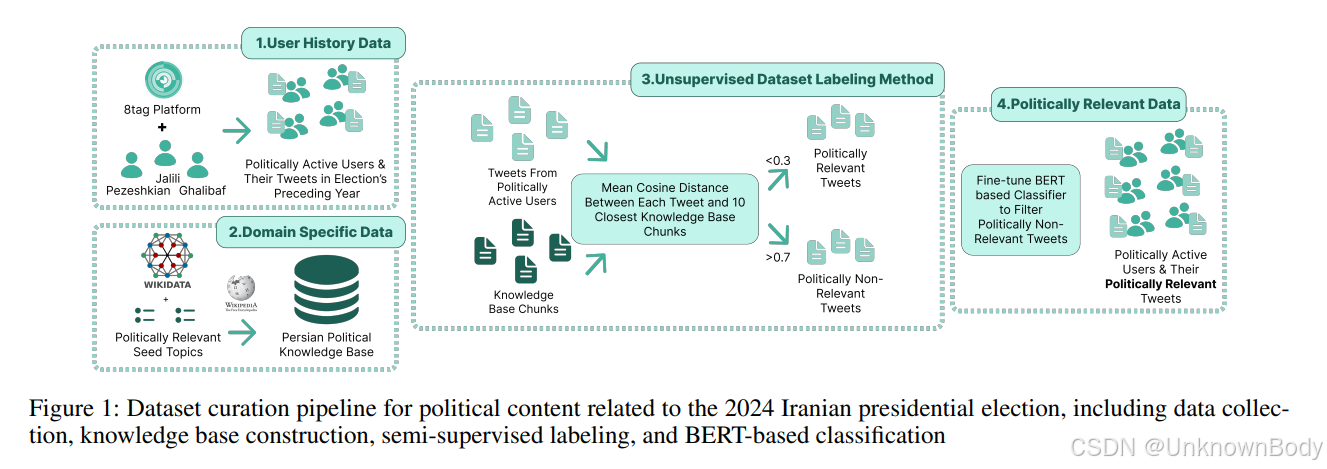
一、文章主要内容总结
本文提出了一种基于大语言模型(LLM)的社交媒体用户画像方法,旨在解决传统方法依赖大量标注数据、特征不可解释、适应性差等问题。核心流程包括:
- 数据过滤:通过半监督语义过滤方法,利用领域知识库(如维基数据)从600万条波斯语政治推文中筛选出170万条政治相关内容,构建数据集PersianPol6M。
- 画像生成:
- 抽象式画像:使用LLM生成自然语言摘要,提炼用户观点和趋势。
- 提取式画像:从推文中选取最具代表性的原文,保留用户真实表达。
- 评估框架:通过基于LLM的开卷问答任务,对比画像与完整推文历史的立场检测性能,验证信息保留能力。
实验结果表明,该方法在宏观F1分数上比传统方法和现有LLM方法高出9.8%,尤其在提取式画像中表现更优,同时减少了对标注数据的依赖。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











