








 超级会员免费看
超级会员免费看

一、文章主要内容总结
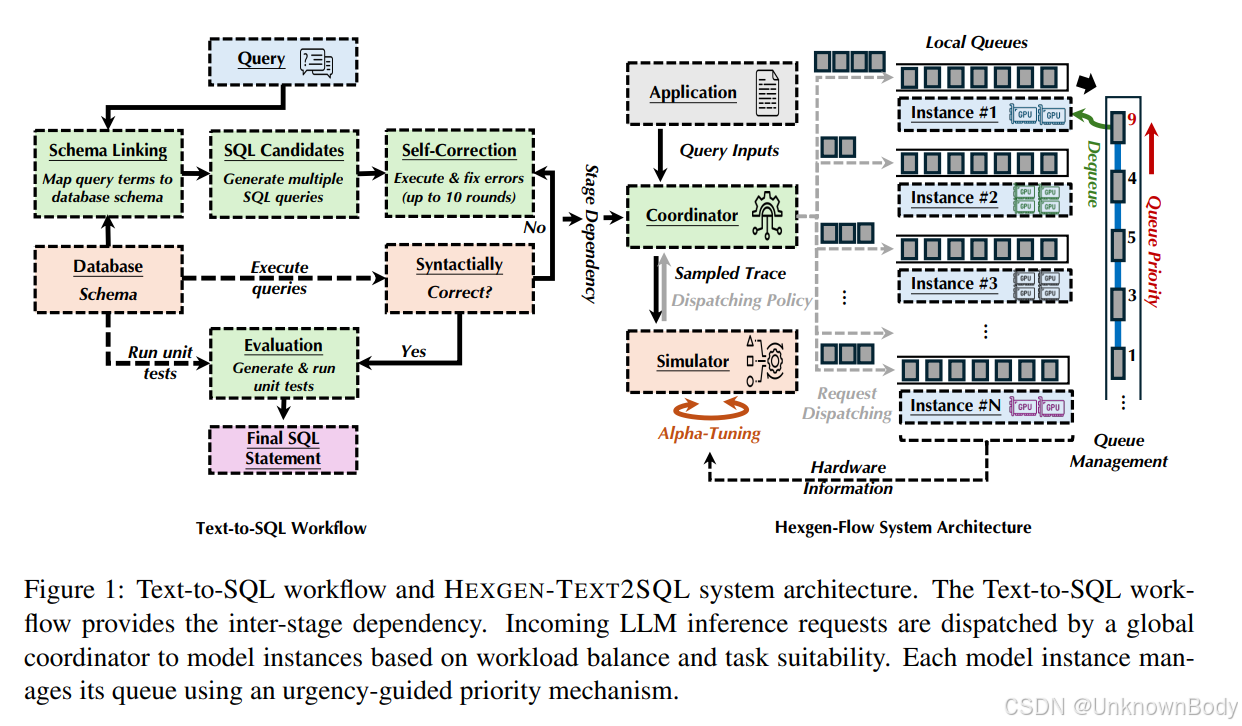
本文聚焦于基于大语言模型(LLM)的智能文本到SQL系统在异构GPU集群中的调度与执行问题,提出了HEXGEN-TEXT2SQL框架,旨在解决多阶段工作流、严格延迟约束和资源异构性带来的挑战。核心内容包括:
- 问题分析:现有LLM服务框架无法有效处理文本到SQL工作流中的任务依赖、延迟变化和资源异构性,导致服务级别目标(SLO)频繁违反。
- 框架设计:
- 分层调度策略:全局负载均衡调度器根据模型实例的处理能力和当前负载分配任务;本地优先级队列基于任务紧迫性动态调整执行顺序,支持任务抢占。
- 轻量级仿真调参:通过仿真动态调整调度超参数α,平衡任务适配性与负载均衡,提升系统鲁棒性。
- 实验验证:在真实文本到SQL基准测试中,HEXGEN-TEXT2SQL相比vLLM,延迟降低1.41倍(最高1.67倍),吞吐量提升

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











