







大家好,我技术人Howzit,这是深度学习入门系列第十四篇,欢迎大家一起交流!
深度学习入门系列1:多层感知器概述
深度学习入门系列2:用TensorFlow构建你的第一个神经网络
深度学习入门系列3:深度学习模型的性能评价方法
深度学习入门系列4:用scikit-learn找到最好的模型
深度学习入门系列5项目实战:用深度学习识别鸢尾花种类
深度学习入门系列6项目实战:声纳回声识别
深度学习入门系列7项目实战:波士顿房屋价格回归
深度学习入门系列8:用序列化保存模型便于继续训练
深度学习入门系列9:用检查点保存训练期间最好的模型
深度学习入门系列10:从绘制记录中理解训练期间的模型行为
深度学习入门系列11:用Dropout正则减少过拟合
深度学习入门系列12:使用学习规划来提升性能
深度学习入门系列13:卷积神经网络概述
深度学习入门系列14:项目实战:基于CNN的手写数字识别
深度学习入门系列15:用图像增强改善模型性能
深度学习入门系列16:项目实战:图像中目标识别
深度学习入门系列17:项目实战:从电影评论预测情感
深度学习入门系列18:递归神经网络概述
深度学习入门系列19:基于窗口(window)的多层感知器解决时序问题
深度学习入门系列20:LSTM循环神经网络解决国际航空乘客预测问题
深度学习入门系列21:项目:用LSTM+CNN对电影评论分类
深度学习入门系列22:从猜字母游戏中理解有状态的LSTM递归神经网络
深度学习入门系列23:项目:用爱丽丝梦游仙境生成文本
文章目录
深度学习能力的一种流行描述是图片数据中的对象识别。对于机器学习和深度学习中手写体识别的helloword项目就是基于MNIST数据集上的手写体识别。在这个项目里,你将发现如何用Keras深度学习库开发一个深度学习模型,在MNIST手写体数字识别任务获得显著的效果。一步步完成这个教程之后,你将了解:
- 在Keras中如何加载MNIST数据集并且针对问题开发一个基准神经网络模型。
- 如何在MNIST数据集上实现和评价一个简单的卷积神经网络。
- 如何为MNIST实现最先进的深度学习模型。
让我们开始吧!
14.1 手写数字识别数据集
MNIST问题是一个数据集,由 Yann LeCun, Corinna Cortes 和 Christopher Burges 为了在手写数字识别分类问题上评价机器学习模型而开发的。数据集是由许多扫描的文档数据集构成的,在NIST上可以获得。这也是这个数据集的名字由来,作为修改NIST或者MNIST数据集。
数字图像是从各种扫描的文档中获取的,尺寸经过标准化并且居中。使得它成为评估模型的优秀数据集,允许开发者专注在机器学习,而不是数据清理和准备。每张图片为28×28像素正方形(总共784个像素)。评估和比较模型使用标准数据集分割,60000用于训练,10000张用于测试。
这是个数字识别任务。有10个数字(0到9)或者10个类来预测。使用预测误差来展示结果,这些结果没有倒置的分类结果多。优秀结果获得1%的预测误差。通过卷积神经网络获得最好的预测误差接近0.2%。Rodrigo Benenson的网页上列出了最新结果,并提供了MNIST上相关论文的链接以及其他数据集。
14.2 在Keras中加载MNIST数据集
Keras深度学习库提供一个加载MNIST数据集的便捷方法。首次调用这个函数时会自动下载数据集,并存在你的 ~/.keras/datasets/mnist.pkl.gz目录下,大小为15MB的文件。这是非常方便开发和测试深度学习模型。为了描述如何简单的加载MNIST数据集,我们首先写点脚本下载并可视化训练集前四张图片。
# Plot ad hoc mnist instances
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# load (downloaded if needed) the MNIST dataset
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# plot 4 images as gray scale
plt.subplot(221)
plt.imshow(X_train[0], cmap=plt.get_cmap("gray"))
plt.subplot(222)
plt.imshow(X_train[1], cmap=plt.get_cmap("gray"))
plt.subplot(223)
plt.imshow(X_train[2], cmap=plt.get_cmap("gray"))
plt.subplot(224)
plt.imshow(X_train[3], cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
你能看到下载和加载数据集和调用mnist.load_data()一样简单。运行上面例子,你应该能够看到下面的图片。

14.3 多层感知器基准模型
我们真的需要一个像卷积神经网络这样复杂的模型来获得在MNIST数据集上最好的结果吗?你可以用一个非常简单的单个神经元感知器模型就能获得不错的结果。在这一部分,我们将创建一个简单多层感知器模型获得误差率近似为1.73%。我们将使用这个作为基准并与更加复杂的卷积神经网络作对比。然我们开始导入要使用的类和函数。
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.utils import np_utils
初始化一个随机生成器为常量来确保你的脚本结果具有可复制性,总是一个不错的主意。
# fix random seed for reproducibility
seed = 7 numpy.random.seed(seed)
现在我们使用Keras帮助类函数加载MNIST数据集
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
训练数据集由实例,图像宽度和图像高度的3维数组构成。对于多层感知器模型,我们必须将图片减少为像素向量,在这种情况下,28×28大小图片转成为784个像素输入向量。我们可以通过Numpy中reshape() 轻松进行转换。 像素值都是整型,因此我们可以把它们转成浮点型数值,以至于我们能在下一步轻松标准化。
# flatten 28*28 images to a 784 vector for each image
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0], num_pixels).astype('float32')
X_test = X_test.reshape(X_test.shape[0], num_pixels).astype('float32')
最后,输出变量为0-9的整数,这是个多分类问题,正因如此使用one-hot编码类值是一个很好的实践,并将整数类向量转成二进制矩阵。我们可以轻松使用keras中内置的np_utils.to_categorical()帮助类实现这一功能。
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255 X_test = X_test / 255
我们准备好创建一个简单的神经网络模型,在一个函数中定义我们的模型。如果你以后想扩展这个例子并尝试得到更好的结果,这是很方便的。
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
这是一个简单的神经网络模型,有一个和它输入端(784)一样多的隐藏层,隐藏层中神经元使用整流器激活函数,在输出层中使用softmax函数,把输出结果转成概率值,允许从10个类中选择一个作为输出的预测值。损失函数采用的是对数(Keras中称之为 categorical crossentropy)。学习权重使用的是有效ADAM梯度下降算法,下面提供了神经网络的结构摘要:
# define baseline model
def baseline_model():
# create model
model = Sequential()
model.add(Dense(num_pixels,input_dim=num_pixels, kernel_initializer='normal',activation='relu'))
model.add(Dense(num_classes, kernel_initializer='normal', activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
我们现在能拟合和评估模型,该模型适合10个时期,每200张图像更新一次。测试数据用作验证数据集,可让您在训练模型时了解模型的技巧。对于每个周期,使用verbose值为2是为了减少每行的输出值。最后,测试数据用于评估模型,并打印出分类错误率。
# build the model
model = baseline_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Baseline Error: %.2f%%" % (100-scores[1]*100))
出于完整性考虑,下面提供了完整的代码
import numpy
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.python.keras.utils.np_utils import to_categorical
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# flatten 28*28 images to a 784 vector for each image
num_pixels = X_train.shape[1] * X_train.shape[2]
X_train = X_train.reshape(X_train.shape[0],num_pixels).astype('float32')
X_test = X_test.reshape(X_test.shape[0],num_pixels).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]
# define baseline model
def baseline_model():
# create model
model = Sequential()
model.add(Dense(num_pixels, input_dim=num_pixels, activation="relu"))
model.add(Dense(num_classes, activation="softmax"))
# Compile model
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
return model
# build the model
model = baseline_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=200,verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Baseline Error: %.2f%%" % (100 - scores[1] * 100))
运行这个例子,在CPU上可能需要几分钟,你可以看下面的输出结果。这个简单的神经网络用很少几行代码定义的,获得1.91%的可喜错误率。
Train on 60000 samples, validate on 10000 samples
Epoch 1/10 8s - loss:
0.2797 - acc: 0.9209 - val_loss: 0.1413 - val_acc: 0.9576
Epoch 2/10 8s - loss:
0.1117 - acc: 0.9677 - val_loss: 0.0919 - val_acc: 0.9702
Epoch 3/10 8s - loss:
0.0718 - acc: 0.9796 - val_loss: 0.0782 - val_acc: 0.9774
Epoch 4/10 8s - loss:
0.0505 - acc: 0.9858 - val_loss: 0.0758 - val_acc: 0.9762
Epoch 5/10 8s - loss:
0.0374 - acc: 0.9892 - val_loss: 0.0670 - val_acc: 0.9792
Epoch 6/10 8s - loss:
0.0268 - acc: 0.9929 - val_loss: 0.0630 - val_acc: 0.9803
Epoch 7/10 8s - loss:
0.0210 - acc: 0.9945 - val_loss: 0.0604 - val_acc: 0.9815
Epoch 8/10 8s - loss:
0.0140 - acc: 0.9969 - val_loss: 0.0620 - val_acc: 0.9808
Epoch 9/10 8s - loss:
0.0107 - acc: 0.9978 - val_loss: 0.0598 - val_acc: 0.9812
Epoch 10/107s - loss:
0.0080 - acc: 0.9985 - val_loss: 0.0588 - val_acc: 0.9809
Baseline Error: 1.91%
14.4 MNIST简单的卷积神经网络
既然我们已经看到如何加载MNIST数据以及如何在上面训练多层感知器,是时候开发更加复杂的卷积神经网络模型或者CNN模型。Keras提供了创建卷积神经网络的能力。在这节我们将为MNIST创建一个简单的CNN,描述如何使用现代CNN实现的方方面面,包括卷积层,池化层和Dropout层。第一步是导入需要的类和函数。
import numpyfrom tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Convolution2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.python.keras.utils import np_utils
我们总是初始化随机生成器一个常量,保证结果的可复制性。
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
接下来,我们需要加载MNIST数据集并重设大小以至于能够适用于训练CNN。在Keras中,对于使用二维卷积层,期望的输入维度是[channels][width][height]。以RGB为例,第一个维度为3,分别为红,率,蓝,它像是每个彩色图片都有三种图片输入,以MNIST为例它的通道值是灰阶的,像素维度设置为1。
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][channels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype( 'float32' )
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype( 'float32' )
正如前面,把像素值标准化为0-1之间并且one-hot编码输出是一个不错的注意。
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
接下来我定义神经网络模型。卷积神经网络比标准多层感知器要复杂,因此我们将以一个简单的结构开始,并使用所有元素来到达显著效果。下面是网络摘要:
1.第一隐藏层是卷积层称之为 Convolution2D,这个层有32个特征图,所使用的大小为5×5,整流器激活函数。这是输入层,期望输入以上结构轮廓的图片。
2.接下来我们定义一个池化层,获取最大值,称之为MaxPooling2D,他的配置的池化大小为2×2.
3.接下来一层,使用dropout的正则化层,称之为Dropout。为了减少拟合,把20%的神经元排除在外。
4.接下来一层,把2D矩阵转成向量,我们称之为Flatten,它允许被标准的全连接层处理。
5.接下来是一个有128个神经元的全连接层,使用整流器函数。
6.最后,输出层有10个神经元对于10个类。softmax 为每个类输出一个概率预测
正如前面,模型使用对数损失函数和ADAM梯度下降算法进行训练。下面提供了这个网络结构的描述:
def baseline_model():
# create model
model = Sequential()
model.add(Convolution2D(32, 5, 5, border_mode= valid , input_shape=(1, 28, 28),activation='relu')
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation= 'relu' ))
model.add(Dense(num_classes, activation= 'softmax' ))
# Compile model
model.compile(loss=' categorical_crossentropy' , optimizer= 'adam' , metrics=[ 'accuracy' ])
return model
我们采用之前多层感知器一样的方法来评估模型。CNN拟合10个周期,200个批处理块。
# build the model
model = baseline_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), nb_epoch=10, batch_size=200,verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("CNN Error: %.2f%%" % (100-scores[1]*100))
出于完整性下面提供了所有代码
import numpy
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.python.keras.utils import np_utils
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][channels][width][height]
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
print(X_train.shape)
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
print(y_test.shape)
def baseline_model():
# create model
model = Sequential()
model.add(Conv2D(32, kernel_size=(5, 5),
input_shape=(28, 28, 1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
model = baseline_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200, verbose=2)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("CNN Error: %.2f%%" % (100 - scores[1] * 100))
运行这个例子,每个周期都会打印出在测试集和验证集上的精度,最后打印出分类错误率,在CPU上可能需要花费60s,总共大概需要10分钟,这依赖你的硬件。你能看到这个网络获取1% 的错误率,要好于上面简单的多层感知器。
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 120s - loss: 0.2346 - acc: 0.9334 val_loss: 0.0774 - val_acc: 0.9762
Epoch 2/10
60000/60000 [==============================] - 42s - loss: 0.0716 - acc: 0.9782 - val_loss: 0.0454 - val_acc: 0.9856
Epoch 3/10
60000/60000 [==============================] - 42s - loss: 0.0520 - acc: 0.9842 - val_loss: 0.0429 - val_acc: 0.9853
Epoch 4/10
60000/60000 [==============================] - 42s - loss: 0.0406 - acc: 0.9868 - val_loss: 0.0369 - val_acc: 0.9876
Epoch 5/10
60000/60000 [==============================] - 42s - loss: 0.0331 - acc: 0.9898 - val_loss: 0.0345 - val_acc: 0.9884
Epoch 6/10
60000/60000 [==============================] - 42s - loss: 0.0265 - acc: 0.9917 - val_loss: 0.0323 - val_acc: 0.9905
Epoch 7/10
60000/60000 [==============================] - 42s - loss: 0.0220 - acc: 0.9931 - val_loss: 0.0337 - val_acc: 0.9894
Epoch 8/10
60000/60000 [==============================] - 42s - loss: 0.0201 - acc: 0.9934 - val_loss: 0.0316 - val_acc: 0.9892
Epoch 9/10
60000/60000 [==============================] - 42s - loss: 0.0163 - acc: 0.9947 - val_loss: 0.0281 - val_acc: 0.9908
Epoch 10/10
60000/60000 [==============================] - 42s - loss: 0.0135 - acc: 0.9956 - val_loss: 0.0327 - val_acc: 0.9897
CNN Error: 1.03%
这不是一个优化的网络拓扑结构。也不是从最近的文章复制的网络结构。你有很多可能调节和改善这个模型。你能获得最好的分类错误率是多少?
14.5 MNIST的较大卷积神经网络
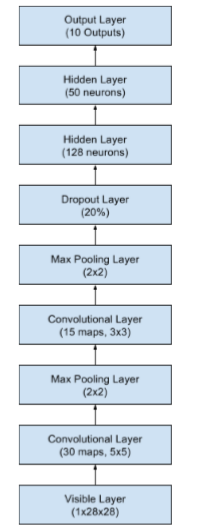
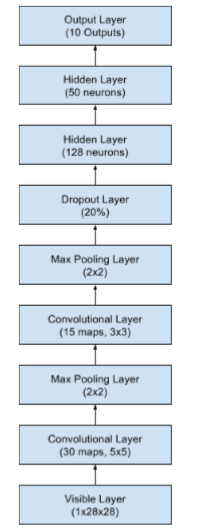
既然我们已经知道如何创建一个简单的CNN,那么让我们看看接近最新结果的模型。我们导入类和函数,然后像之前的CNN例子一样加载和准备数据集。这时我们定义一个更大的CNN结构,另外的卷积层,池化层和全连接层。网络的拓扑结构的摘要如下:
-
有30个大小为5×5特征图的卷积层。
-
通过2×2大小得块获得最大值的池化层。
-
有15个3×3大小的特征图的卷积层。
-
通过2×2大小得块获得最大值的池化层。
-
有20%的概率Dropout层。
-
扁平层(Flatten)
-
有128个神经元和整流器激活函数的全连接层。
8.有50个神经元和整流器激活函数的全连接层。
9.输出层。
下面提供了一个更大网络结构的描述:
像前面两个实验一样,模型拟合10个周期,批量大小为200。
# Larger CNN for the MNIST Dataset
import numpy
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
K.set_image_dim_ordering('th')
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][pixels][width][height]
X_train = X_train.reshape(X_train.shape[0], 1, 28, 28).astype('float32')
X_test = X_test.reshape(X_test.shape[0], 1, 28, 28).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_test.shape[1]
# define the larger model
def larger_model():
# create model
model = Sequential()
model.add(Conv2D(30, (5, 5), input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(15, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2)) model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# build the model
model = larger_model()
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=200)
# Final evaluation of the model
scores = model.evaluate(X_test, y_test, verbose=0)
print("Large CNN Error: %.2f%%" % (100-scores[1]*100))
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 45s - loss: 0.3912 - acc: 0.8798 - val_loss: 0.0874 - val_acc: 0.9726
Epoch 2/10
60000/60000 [==============================] - 43s - loss: 0.0944 - acc: 0.9713 - val_loss: 0.0603 - val_acc: 0.9800
Epoch 3/10
60000/60000 [==============================] - 43s - loss: 0.0697 - acc: 0.9781 - val_loss: 0.0377 - val_acc: 0.9880
Epoch 4/10
60000/60000 [==============================] - 44s - loss: 0.0558 - acc: 0.9819 - val_loss: 0.0331 - val_acc: 0.9885
Epoch 5/10
60000/60000 [==============================] - 44s - loss: 0.0480 - acc: 0.9852 - val_loss: 0.0300 - val_acc: 0.9900
Epoch 6/10
60000/60000 [==============================] - 44s - loss: 0.0430 - acc: 0.9862 - val_loss: 0.0293 - val_acc: 0.9897
Epoch 7/10
60000/60000 [==============================] - 44s - loss: 0.0385 - acc: 0.9877 - val_loss: 0.0260 - val_acc: 0.9911
Epoch 8/10
60000/60000 [==============================] - 44s - loss: 0.0349 - acc: 0.9895 - val_loss: 0.0264 - val_acc: 0.9910
Epoch 9/10
60000/60000 [==============================] - 44s - loss: 0.0332 - acc: 0.9898 - val_loss: 0.0222 - val_acc: 0.9931
Epoch 10/10
60000/60000 [==============================] - 44s - loss: 0.0289 - acc: 0.9908 - val_loss: 0.0226 - val_acc: 0.9918
Large CNN Error: 0.82%
14.6 总结
在这节课,你已经学习了MNIST手写数字识别问题,以及在python中使用Keras库开发深度学习模型,获得不错的结果。学完整个教程你学得:
- 如何加载MNIST数据集以及生成数据集图标。
- 如何重设MNIST数据集大小并针对这个问题开发一个简单但是效果不错的多层感知器
- 如何在MNIST数据集上使用Keras创建一个卷积神经网络模型。
- 如何在MNIST上开发和评估更大的卷积神经网络模型,能达到世界效果
14.6.1 接下来
你现在知道如何在Keras中开发和改善神经网络模型。使用数据增强来改善CNN模型性能的一个强有力的技术。在接下来的部分,你将学习Keras中数据增强的API和不同的增强技术如何影响MNIST图片。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











