







语义分割任务中遇到的对比学习
目的
通过对比学习, 学习得到一个具有更好判别性的特征表示(非直接得到标签对)
形式
- 首先通过一个网络提取到输入图像的 feature embedding,并通过伪标签/ground truth对像素进行对应的分类。
- 在特征中随机选择一个作为锚点,并根据类别选择正样本(和锚点相似的同一类别)和负样本(和锚点不相似的非同一类别)
- 将一个样本(锚点)同其它样本进行比较,通过最小化相似样本之间的距离和最大化不相似样本之间的距离来训练模型。(即利用对比损失函数,使锚点距离正样本近,距离负样本远;主要是通过对对比损失函数的反向传播改变锚点的特征完成这一任务)
- 最终在低维特征空间中,相似的样本被映射到相邻的位置,不相似的样本被映射到较远的位置。
利用对比损失函数,进行反向传播,经过对比学习的学习后,使模型能够提取具有更好判别性的,有代表性的特征表示。
理想的特征空间如下:(1.强判别能力:在该特征空间中,每个像素的特征应具有较强的分类能力;2.高度结构化:同类像素的特征应高度紧致,不同类像素的特征应尽量分散)
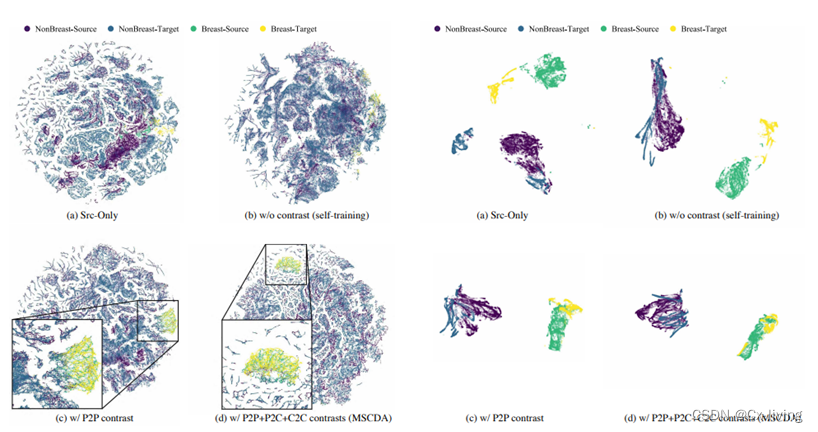
参考文章:MSCDA: Multi-level Semantic-guided Contrast Improves Unsupervised Domain Adaptation for Breast MRI Segmentation in Small Datasets
这种对比学习有利于解决域偏移问题
能解决域偏移问题,提高泛化能力
域偏移问题指的是,在训练集和测试集的数据分布存在差异时,模型性能下降的问题。
对比学习可以缓解域偏移问题的原因在于,它通过学习特征表示,使得在不同域中具有相似语义的样本在特征空间中更加接近。这样,即使在测试集中的数据分布与训练集有所不同,具有相似语义的样本仍然能够在特征空间中聚集到一起,从而保证模型的泛化能力。
具体来说,相似的样本在特征空间中聚集在一起,可以帮助模型学习到更加具有判别性的特征表示。如果不同类别的样本分布在特征空间中混杂在一起,模型学习到的特征表示可能会受到干扰,导致模型泛化性能下降。相反,如果同类别的样本在特征空间中聚集在一起,模型能够更加容易地学习到区分不同类别的特征表示,从而提高模型的泛化能力。
此外,相似的样本在特征空间中聚集在一起,也可以帮助模型更好地进行类内变化和类间区分。如果不同类别的样本混杂在一起,模型可能会将一些类内变化当作类间差异,导致模型泛化性能下降。相反,如果同类别的样本在特征空间中聚集在一起,模型能够更加容易地捕捉到类内变化和类间区分,从而提高模型的泛化能力。
因此,将具有相似语义的样本在特征空间中聚集在一起,能够帮助模型学习到更加鲁棒的特征表示,从而在未见过的测试数据上也能够得到良好的性能,从而保证了模型的泛化能力。
有助于提高模型的泛化能力,主要原因如下:
-
提高样本的区分度:对比学习通过将具有相似语义的样本在特征空间中聚集在一起,使得不同类别的样本在特征空间中的距离相对较大,同一类别的样本在特征空间中的距离相对较小,从而提高了样本的区分度,有助于模型更好地区分不同类别的样本。
-
增强模型的鲁棒性:在特征空间中,具有相似语义的样本会聚集在一起,这种聚集现象对于噪声和异常值具有一定的鲁棒性。如果在训练过程中出现一些噪声或异常值,由于它们在特征空间中离其他样本较远,对模型的影响将被降低,从而提高了模型的鲁棒性。
-
增加模型的泛化能力:当模型在训练集上训练完毕后,在测试集上进行测试,测试集中的样本可能与训练集中的样本存在一定的差异,例如存在一些新的、未见过的情况。在这种情况下,如果模型在训练集中学习到了具有相似语义的样本的特征表示,那么它就有可能将新的情况映射到这些特征空间中的区域,从而具有更好的泛化能力。
在深度学习中,模型通常是在高维特征空间中学习的,因此样本在特征空间中的位置和分布对模型的学习和泛化能力具有重要影响。如果在特征空间中,同一类别的样本聚集在一起,不同类别的样本之间距离较远,那么模型学习到的特征会更加具有区分度,使得模型更能够准确地区分不同类别的样本,从而提高了泛化能力。
具体来说,在训练过程中,模型通过学习样本之间的相似性和差异性,学习到了一种特征表示,可以将样本映射到高维特征空间中。这些特征表示具有区分度,即同一类别的样本在特征空间中距离比较近,不同类别的样本在特征空间中距离比较远。因此,当面临新的情况时,模型会将新的样本映射到与它最相似的训练集中的样本的特征空间中,从而得到一个高维特征表示。然后,模型可以使用这个特征表示进行分类、预测等任务。
需要注意的是,对于新的情况,模型可能没有学习到与之完全匹配的特征表示,因此它需要在已有的特征表示的基础上进行一些适应性调整,以便更好地适应新的情况。这个过程通常被称为fine-tuning(微调),即使用新的样本对模型进行重新训练,以便更好地适应新的情况。
注:在模型经过训练之后,得到了拟合的很好的特征空间,特征空间内相似的样本距离比较近,不相似的样本距离比较远,当遇到新的,未见过的样本的时候,提取到的特征和学习到的特征空间内的某样本相似,但单依据提取到的特征并不能完成分类,而依靠特征空间中的相似的表示,就可以将特征映射到高维空间,就可以依据这个特征进行很好的分类了。
特征表示的质量和模型的泛化能力密切相关,如何设计合理的特征表示是非常重要的















 5256
5256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









