







 本文深入探讨对比学习中正负样本选择的重要性,介绍了如何通过改进数据增强方法(如ConSERT)和优化采样策略(如Median Triplet Loss、增量式负样本学习)来提高对比学习的效果。通过分析负样本质量,研究表明并非所有负样本都有同等价值,提出关注负样本难度的选择。这些研究为对比学习领域的进一步发展提供了启示。
本文深入探讨对比学习中正负样本选择的重要性,介绍了如何通过改进数据增强方法(如ConSERT)和优化采样策略(如Median Triplet Loss、增量式负样本学习)来提高对比学习的效果。通过分析负样本质量,研究表明并非所有负样本都有同等价值,提出关注负样本难度的选择。这些研究为对比学习领域的进一步发展提供了启示。

©PaperWeekly 原创 · 作者 | 张琨
学校 | 中国科学技术大学博士生
研究方向 | 自然语言处理
在之前的介绍中,我们对自监督学习(SSL)中的对比学习(CL)进行了简单介绍,然后针对对比学习中的采样方式进行详细的分析。由于对比学习的核心思想是在向量表征空间中将正样本(positive example)与锚点样本(anchor example)之间的距离拉近,将负样本(negative example)与锚点样本(anchor example)之间的距离拉远,因此,所选取的正负样本的质量直接决定了整个方法的效果。为此,有很多研究工作集中在对比学习的采样方法中,本文针对这些方法继续进行深挖,希望能够让大家对对比学习有更深入的认识,为大家带来一些微小的启发。
在接下来的介绍中,本文首先介绍了一个在自然语言中更巧妙使用数据增强的方法,避免了在 NLP 使用数据增强面临的数据质量的问题。接下来针对对比学习中的采样方式,分别从效率,假负样本更充分的利用,以及负样本难度的选择是如何影响模型效果的这几个方面进行简单介绍。

更好的自然语言处理样本生成(ConSERT )[1]
在具体介绍针对正样本或者负样本的采样之前,首先介绍一个在自然语言处理中进行更好的数据增强的工作。该工作通过选择更合适的自然语言数据增强方法坍缩了 BERT 原生句子表示在表征空间存在的“坍缩”现象,同时也是一个标准的将对比学习应用在自然语言语义表征中的框架。
1.1 亮点
通过分析指出原生的 BERT 模型在句子语义表征中存在“坍缩”现象,即倾向于编码到一个较小的空间区域内,使大多数的句子对都具有较高的相似度分数,影响表征结果在具体下游任务中的表现
基于 BERT 模型提出了一种更好的对比学习方法,用于句子语义的表征
在监督实验,无监督实验,小样本实验中进行了充分的模型验证
1.2 方法
整体的模型框架图如下,相对于 BERT 模型而言思路非常简单,就是在输入到 encoder 的时候加了一个数据增强层。但作者进行了非常全面的考虑,例如为了避免直接从文本层面进行数据增强导致的语义变化问题,以及效率问题。作者提出直接在 embedding 层隐式生成数据增强样本,从而一方面避免以上问题,另一方面能够生成高质量的数据增强样本。
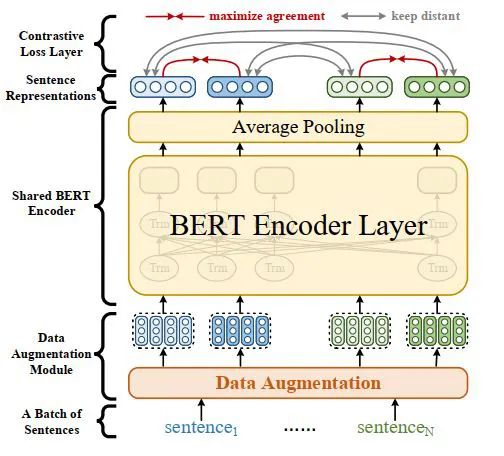
而在数据增强上,由于是在 embedding 层直接进行数据增强的,因此在这里作者选择了以下四种增强方式:
对抗攻击:通过梯度回传生成对抗扰动,将该扰动加到原本的 embedding 矩阵上
词序打乱:这个非常有意思,由于在 BERT 中是通过 position embedding 的方式显式指定位置的,因此直接将 position id 进行 shuffle 即可
裁剪:这部分分为两个粒度:a. 对某个 token 进行裁剪,直接将对应的 embedding 置为 0 即可,b. 对某些特征进行裁剪,即将 embedding 矩阵中对应列置为 0
dropout:这个就是非常简单有效的方法了,直接利用 BERT 的结构进行 dropout 操作即可
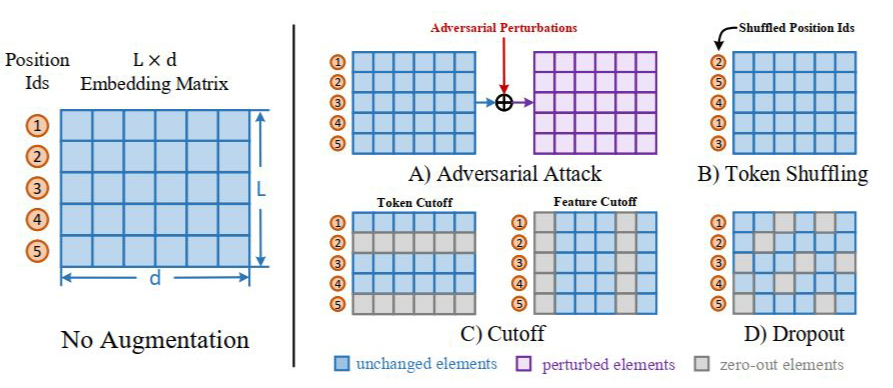
由于这些方法是直接面向 embedding 矩阵的,因此相对于显示生成增强文本的方法更为高效。针对本文的具体技术细节可以参考作者自己的解读。
1.3 实验
本文的实验也是非常充分的,作者处理利用对比学习框架进行无监督训练之外,还考虑了融合监督信号进行的增强训练,并提出了联合训练:有监督损失和无监督损失进行加权联合训练;现有监督在无监督:先用有监督损失训练模型,在利用无监督方法进行表示迁移;联合训练再
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









