







自学Java乐趣多呀,最近把《深入理解Java虚拟机》看了一遍,主要是集中于垃圾收集器和类加载的学习,因为课程多,打算过了期中评测后再把这本书完完整整地撸一遍。
前几天学习了垃圾收集器,现在来给垃圾收集器做个总结,包括判断对象是否需要回收,各种垃圾收集算法和各种垃圾收集器。写得肯定没有各路大神的详细,有问题还请多包涵。
1、判断对象是否需要被回收
垃圾收集器主要是在堆内存中回收已经没有用处的对象,那么JVM怎么才能知道一个对象是有还有用呢?一般这个需要经过两步,分别是可达性分析和判断是否有必要执行finalize()方法来自救。
判断对象是否还有用可以用一个专业的名词来代替,那就是判断对象是否还存在引用,引用分为强引用,软引用,弱引用和虚引用,至于他们的区别和特别我在这里就不阐述,下面来讲讲判断对象是否存在引用的可达性分析的流程。
1、1可达性分析
可达性可以通俗的理解为对象是否可达,那么就得有一个根节点(起始点)来做建立是否可达的标准,GC会通过一系列称为“GC Roots”的对象作为起始点,从该起始点往下开始遍历搜索,遍历的路径我们称之为引用链,很明显,若某个对象与该“GC Roots”不存在引用链,那么该对象就是不可达的,此时该对象就会被JVM进行第一次标志,列入可回收的对象中。
1、2判断是否有必要执行finalize()方法
当对象在可达性分析阶段被判断为可回收对象时,该对象并不是必须得被回收的,GC还会判断该对象是否有必要执行finalize()方法来进行“自救”。既然是是否有必要执行,那么就存在不需要执行的情况了。当该对象的的finalize()方法已经被调用过(因为finalize()只能被调用一次,即只有一次“自救”机会)或者该对象并没有覆盖finalize()方法,那么判断为没有必要执行finalize()方法,该对象会被进行第二次标志,等待被回收。
若该对象可以执行finalize()方法,那么该对象被放置在另一个成为F-Queue的队列中,然后虚拟机会触发该对象的finalize()方法。过一段时间后GC会对F-Queue里面的对象进行第二次标志,若对象执行了finalize()方法后重新获得了引用,那么该对象就会被“无罪释放了”,即将该对象从可回收对象的集合中移出。如果对象执行了finalize()方法后没有获得引用,那么该对象就被宣布死刑,等待被回收。
2、垃圾收集算法
知道了哪些对象是否可以被回收,哪些不需要回收后,GC就可以精确地回收这些对象,但是回收这些对象过程中还是有些问题的。比如如果才能做到效率高,而且可回收的对象在内存中不是连续分布的,这就意味着回收完毕后会存在内存碎片,那么即使完成了垃圾收集,但是下一次大对象在内存分配空间时,若找不到足够大的空间而不得不引发一次垃圾收集动作。对于这些问题,我们得研究一下垃圾收集算法。
2、1标记-清除算法
从字面上看就是对对象进行标记,然后将这些对象清除掉。但是很明显它没有解决我们上面提出的问题,即标记-清除算法在标记和清除过程中效率都不高,而且清除完毕后后会产生内存碎片,这都是我们不希望出现的。接着,出现了复制算法。
2、2 复制算法
复制算法实现思路是将内存平均分为两部分,对象在分配内存时只能使用其中一部分,另一部分空着。当其中一部分内存快要被对象分配用完时,就将还存在的对象复制到空余的另一半内存,然后直接把之前的内存一次性清理掉。这样就会解决了内存碎片的问题,但是美中不足的是该算法把内存缩小了一半,代价有点昂贵。
2、3 标记-整理算法
很明显,该算法跟标记-清除算法很相似,但是该算法对象内存就行了“整理”。标记-整理算法实现思路是:对对象标记完成后,并不是直接对对象直接回收,而是让存活对象都向一端移动,最后直接清掉端边界以为的内存,那么便解决了内存碎片的问题。
2、4 分代收集算法
上述的三种算法各有优缺点,研究发现,在更新旺盛的新生代区每次都有大量的对象死去,只有少量存活,那么我们可以使用“复制算法”,只是该复制算法不是按1:1分割内存,而是按照一定的比例,一般默认是8:1.在老年区,这些对象都是“老不死”的,那么就可以使用“标记-清除算法”或者“标记-整理算法”。以上说的便是取多家之长设计的分代收集算法。
3、垃圾收集器
上面理论部分说了一大堆,那么就得根据这些理论设计出实用的垃圾收集器了。HotSpot虚拟机内部的垃圾收集器如下图1所示。
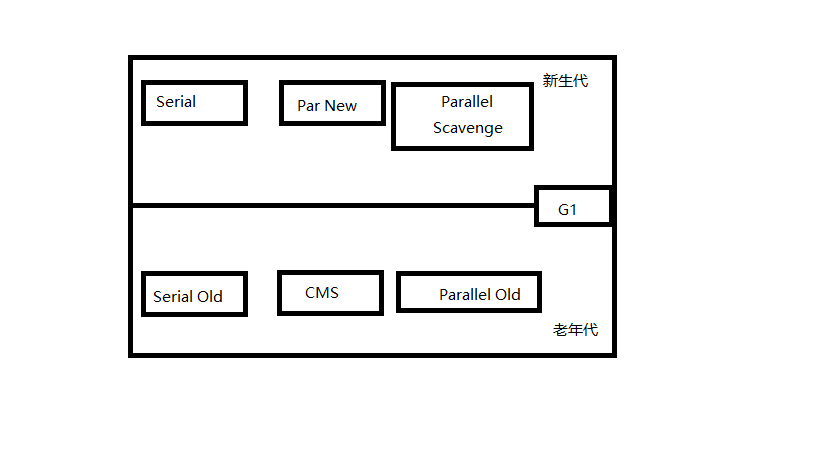
图1 HotSpot虚拟机内部的垃圾收集器
3、1 Serial收集器
Serial收集器是发展时间最长的一个垃圾收集器,Serial收集器是单线程收集器,是一款运行与新生代的垃圾收集器,故它使用的垃圾收集算法是“复制算法”,但是Serial收集器在运行时会产生“stopthe world”现象,即该收集线程运行时,会暂停其他的用户线程,知道垃圾收集完成后恢复正常,这就相当于把用户的世界都暂停了,称为“stop the world”现象。
Serial收集器优点在于简单高效,没有线程之间的开销,专心做垃圾收集,所以是运行于Client模式下的一个很好选择。
Serial Old收集器说白了就是Serial收集器的老年代版本,区别在于使用的垃圾收集算法不同,Serial Old收集器使用的是“标记-整理”算法。
3、2 ParNew收集器
从名字可以推断出Par New收集器是运行于新生代的垃圾收集器,它其实是Serial收集器的多线程版本,即在进行GC时进行多线程收集,在收集算法方面依旧使用的“复制算法”,也会产生“stopthe world”现象。该收集器是运行于Server模式下的新生代首选收集器,但它存在线程交互的开销,我们可以使用-XX:ParallelGCThreads参数来限制垃圾收集的线程数。
3、3 Parallel Scavenge收集器
单词parallel是并行的意思,所以该收集器是并行的多线程收集器,且仍是运行于新生代,采用的垃圾收集算法是“复制算法”,这些都跟ParNew收集器一样,但是它跟其他收集器的关注点不一样,其他收集器都是为了缩短“stop the world”的时间而努力,但是Parallel Scavenge收集器是一款注重可以达到一个可控制吞吐量的收集器,所谓吞吐量是CPU运行用户代码的时间与CPU总运行时间的比值。此外Parallel Scavenge收集器还有一个称为GC自适应的调节策略,这个策略是当Parallel Scavenge收集器的-XX:UseAdaptiveSizePolicy参数打开后,我们不再需要手动设置新生代的大小(-xmn)、Eden与Survivor区的比例(SurvivorRatio)、晋升老年代的对象大小阈值(-XX:PretenureSizeThreshold)等参数,虚拟机会动态地帮我们调整这些参数的大小。
3、4 CMS(Concurrent MarkSweep)收集器
CMS收集器是运行于老年代的垃圾收集器,从名字上面看出该收集器是并发多线程的收集器,且使用的是“标记-清除”算法。CMS收集器完成一次垃圾收集需要经过四个阶段,分别是:初始标记,并发标记,重复标记,并发清除。
初始标记阶段仅仅是标记一下能与GC Roots相关联的对象,速度非常快,虽然也会产生“stop the world”现象,但时间非常短,可以忽略。
并发标记阶段是与用户线程一起并发执行的,是GC Roots Tracing的过程。
重复标记阶段是对在并发标记期间新产生的垃圾对象进行标记,这个阶段也会产生“stop the world”现象,且比初始标记阶段的长一些。
并发清除阶段是与用户线程一起并发执行,对可回收对象进行清除,但是该阶段用户线程仍在运行,因此也会产生垃圾,这些垃圾被称为“浮动垃圾”,这种垃圾在本次GC是无法被清除的。
故下面说说CMS收集器的缺点。
CMS收集器对CPU资源非常敏感。我们也知道了,CMS收集器存在两次并发过程,这些过程都会拖慢用户线程。
CMS收集器不能处理浮动垃圾。刚刚介绍的浮动垃圾CMS在此次垃圾收集是无法清除的,只能留到下一次GC时清理掉。且由于用户线程在进行,所以得预留老年代的空间给用户线程使用,所以不能等到老年代满了再收集,针对这个问题,提供了“-XX:CMSInitiatingOccupancyFraction”参数来设置触发GC的内存使用百分比,但是若调节过高,当预留内存无法满足需要,会产生“ConcurrentMode Failure”失败,此时虚拟机启动后备方案,即临时启动Serial Old收集器来对老年代进行一次垃圾回收。
CMS收集器使用的是“标记-清楚”算法,因此会产生内存碎片,针对此问题,提供了“-XX:UseCMSCompactAtFullCollection”开关参数(默认是开启的),即当存在内存碎片的内存无法满足大对象分配时,会进行一次内存的整理。还提供了设置执行了多少次无整理压缩的GC后,进行一次整理压缩的GC的参数,该参数是“-XX:CMSFullGCsBeforeCompaction”,默认值为0,即每次进行FullGC都压缩整理。
3、5 G1(Garbage-First)收集器
G1收集器可以说是目前最前沿的收集器,要不然也不会带上“First”。它与CMS较为相似,但又比CMS好。G1收集器的特点在于:
使用并行与并发来缩短“stop the world”的停顿时间。
G1收集器的工作范围是新生代与老年代,其实在G1收集器里新生代与老年代不再是一个物理隔离,因为G1收集器把内存分为大小相等的独立区域,但是G1仍是使用分代收集算法,用不同的算法对新对象和熬过多次垃圾收集的对象进行清理。
G1收集器可以对空间进行整合,即消除内存碎片带来的诟病。
提供了可预测的停顿。G1除了低停顿外,还提供了可预测的时间停顿模型,能让使用者指定在长度为M毫秒的时间段内,消耗在GC上的时间不超过N毫秒。
G1收集器的运作大概可以分为四个步骤,分别是:初始标记,并发标记,最终标记,筛选回收。
可以看出这些步骤与CMS的差不多,主要是第四步有些区别,因为G1收集器是将内存分为很多个区域,因此在筛选回收时,会对各个区域的回收价值和回收成本进行排序,根据用户提供的时间模型来进行回收。
好了,写到这就结束了,该去吃个饭准备上课了。














 1499
1499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









