







 本文介绍了在Python环境下进行中文文本预处理的步骤,包括获取原始文本、中文分词、去除停用词、处理全半角字符,以及解决Python在Windows下的中文解码问题。
本文介绍了在Python环境下进行中文文本预处理的步骤,包括获取原始文本、中文分词、去除停用词、处理全半角字符,以及解决Python在Windows下的中文解码问题。
一 得到原始文本内容
def FileRead(self,filePath):
f = open(filePath)
raw=f.read()
return raw二 中文分词
参考之前的一篇博客Python下的中文分词实现
def NlpirTokener(self,raw):
result=''
tokens = nlpir.Seg(raw)
for w in tokens:
# result+= w[0]+"/"+w[1] #加词性标注
result+= w[0] +'/'#加词性标注
return result
def JiebaTokener(self,raw):
result=''
words = pseg.cut(raw) #进行分词
result="" #记录最终结果的变量
for w in words:
# result+= str(w.word)+"/"+str(w.flag) #加词性标注
result+= str(w.word)+"/" #加词
return result三 去停用词
def StopwordsRm(self,words):
result=''
print words
wordList=[word for word in words.split('#')]
print wordList[:20]
stopwords = {}.fromkeys([ line.rstrip()for line in open(conf.PreConfig.CHSTOPWORDS)])
cleanTokens= [w for w in wordList ifw not in stopwords]
print cleanTokens[:20]
for c in cleanTokens:
result+=c+"#"
print result
returnresult在这个地方我遇到了一个很烦人的问题,那就是Python的中文解码问题,在最开始的一个小时里我在在去停用词之后一直看到的结果是这样的:
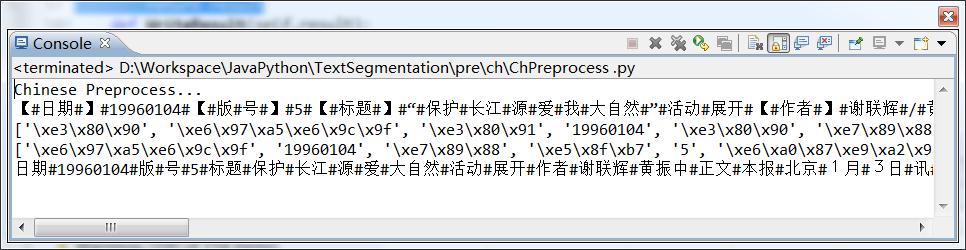
\xe3\x80\x90/\xe6\x97\xa5\xe6\x9c\x9f/\xe3\这种东西没说的肯定是解码造成的,于是开始找解决的方法。
后来找到CSDN上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2058
2058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









