







 本文记录了解决USTC-TK2016数据处理工具中遇到的两个问题:脚本找不到匹配文件和SplitCap版本问题。作者分享了修正脚本路径和更新SplitCap.exe的解决方法,以确保工具顺利运行。
本文记录了解决USTC-TK2016数据处理工具中遇到的两个问题:脚本找不到匹配文件和SplitCap版本问题。作者分享了修正脚本路径和更新SplitCap.exe的解决方法,以确保工具顺利运行。
USTC-TK2016数据处理工具:https://github.com/yungshenglu/USTC-TK2016
USTC-TFC2016数据集:https://github.com/yungshenglu/USTC-TFC2016
流量分类项目-DeepTraffic:https://github.com/echowei/DeepTraffic
关于如何运行以及下载USTC-TK2016数据处理工具,在项目的github中已经说得很详细了,本帖主要是记录一下运行过程中的报错及解决方案。
错误一:
打开 PowerShell,运行第一步 1_Pcap2Session.ps1,报错:
Error: No files matched '2_Session\AllLayers'
No files to process
Error: No files matched '2_Session\L7'
No files to process
如图:

这我就纳闷了,脚本运行所在路径既没问题,2_Session 下的文件夹也应该是自动生成的,怎么会提示没有匹配的文件呢。看了一下程序,找到原因了。按照github上的要求把USTC-TFC2016数据集下载下来并放到 1_Pcap 文件夹下,结构如下图:
1_Pcap
└─USTC-TFC2016
├─Benign
│ BitTorrent.pcap
│ Facetime.pcap
│ FTP.pcap
│ Gmail.pcap
│ MySQL.pcap
│ Outlook.pcap
│ Skype.pcap
│ SMB.7z
│ Weibo.7z
│ WorldOfWarcraft.pcap
│
└─Malware
Cridex.7z
Geodo.7z
Htbot.7z
Miuref.pcap
Neris.7z
Nsis-ay.7z
Shifu.7z
Tinba.pcap
Virut.7z
Zeus.pcap
但是代码中却是这样写的
1_Pcap2Session.ps1
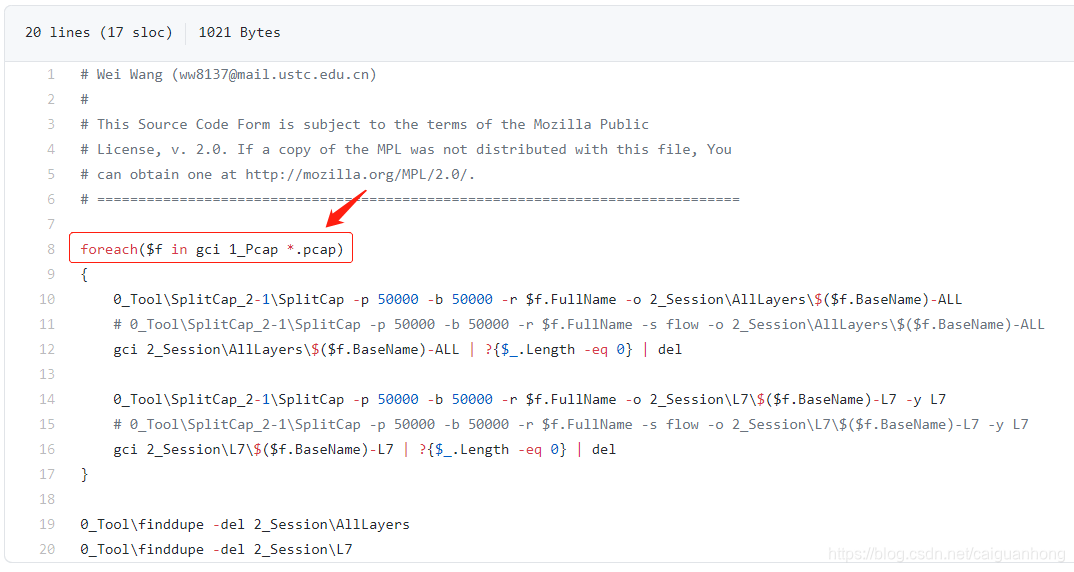
问题就出在第一行,这样肯定找不到文件啊,1_Pcap 文件夹下哪有 pcap 文件,应修改为:
#foreach($f in gci 1_Pcap *.pcap)
#更改为:
foreach($f in gci 1_Pcap\USTC-TFC2016\Benign *.pcap) #这里路径按照自己的修改,不一定和我完全一样
foreach($f in gci 1_Pcap\USTC-TFC2016\Malware *.pcap)
#分别处理恶意流量和正常流量
再次运行就不会报这个错误了
错误二:
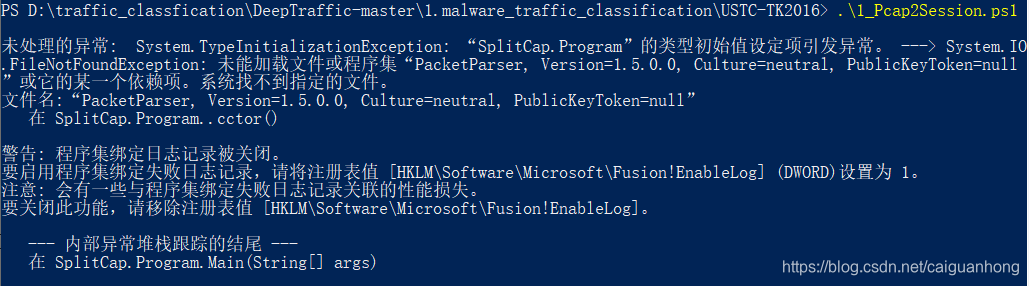
确定脚本程序没问题后接着运行,又报错了
未处理的异常: System.TypeInitializationException: “SplitCap.Program”的类型初始值设定项引发异常。 ---> System.IO.FileNotFoundException: 未能加载文件或程序集“PacketParser, Version=1.5.0.0, Culture=neutral, PublicKeyToken=null ”或它的某一个依赖项。系统找不到指定的文件。
文件名:“PacketParser, Version=1.5.0.0, Culture=neutral, PublicKeyToken=null”
在 SplitCap.Program..cctor()
警告: 程序集绑定日志记录被关闭。
要启用程序集绑定失败日志记录,请将注册表值 [HKLM\Software\Microsoft\Fusion!EnableLog] (DWORD)设置为 1。
注意: 会有一些与程序集绑定失败日志记录关联的性能损失。
要关闭此功能,请移除注册表值 [HKLM\Software\Microsoft\Fusion!EnableLog]。
--- 内部异常堆栈跟踪的结尾 ---
在 SplitCap.Program.Main(String[] args)
如图:
在看了另一位博主的文章 USTC-TK2016工具集和USTC-TFC2016数据集的使用 的下方评论区,找到了答案,原来是需要最新版本的 SliptCap。SliptCap 下载链接:https://www.netresec.com/?page=SplitCap,下下来后替换掉原来的 SplitCap.exe,SplitCap.exe 在如下位置存放
USTC-TK2016
├─0_Tool
│ finddupe.exe
└─SplitCap_2-1
ChangeLog.txt
LICENSE-SplitCap.txt
SplitCap.exe
再次运行就不会报错了,注意:运行 1_Pcap2Session.ps1 脚本花费的时间会比较长

















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









