







原始数据容易获得,但标注数据昂贵;降低存储/计算; 对高维数据降噪;对数据进行探索性分析(可视化); 非监督学习通常可作为监督学习的预处理步骤。
发现数据中分组聚集的结构:根据数据中样本与样本之间的距离 或相似度,将样本划分为若干组/类/簇(cluster)。
划分的原则:簇内样本相似、簇间样本不相似
聚类的结果是产生一个簇的集合
模糊(Fuzzy)vs.非模糊的(non-fuzzy)
l 在模糊聚类中,一个样本点以一定权重属于各个聚类簇
l 权重和为1
l 概率聚类有相似的特性
部分(Partial)vs.完备(complete)
l 在一些场景,我们只聚类部分数据
„
簇的类型
基于中心的簇 ; 基于邻接的簇 ; 基于密度的簇 ; 基于概念的簇
基于中心的簇:簇内的点和其“中心”较为相近(或相似),和其他簇的“中心”较远, 这样的一组样本形成的簇。

基于连续性的簇:相比其他任何 簇的点,每个点都至少和所属簇 的某一个点更近

基于密度的簇:簇是由高密度的区 域形成的,簇之间是一些低密度的 区域

基于概念的簇:同一个簇共享某种性质,这个性质是从整个结合推导出来的

应用:图像分割、图像压缩…
三要素
如何定义样本点之间的“远近” l 使用相似性/距离函数 n
如何评价聚类出来的簇的质量 l 利用评价函数去评估聚类结果
如何获得聚类的簇 :如何表示簇,如何设计划分和优化算法,算法何时停止
衡量样本之间的“远近”:距离、相似、邻近
距离度量函数


预处理

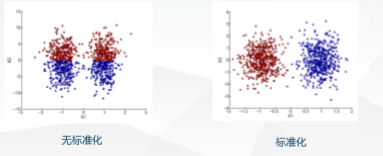
标准化:每个值减均值除以方差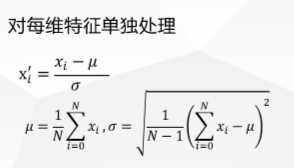

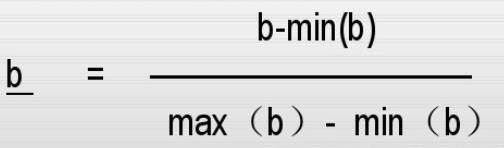
MinMax [0,1]/[-1,1]
数据归一化/正规化
sklearn:Normalizer 常用于K-Means
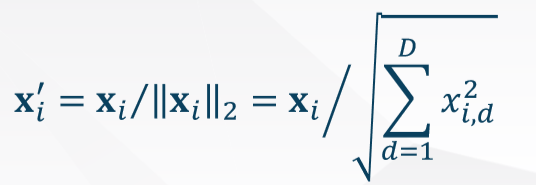
相似
余弦相似度::两变量𝐱i,𝐱j看作𝐷维空间的两个向量,这两个向量间的 夹角余弦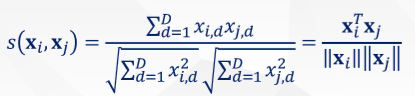
相关系数


K-means聚类
一个假设前提就是“距离”越近,相似度越大。
基于划分的聚类方法, 每个簇都用其质心(centroid)或原型(prototype)表示。
•使用欧式距离进行距离度量;每个节点都划分到最近的那个质心的簇; 𝑟ik:∈(0,1)为从属度,指示样本𝐱i是否属于簇𝑘,且
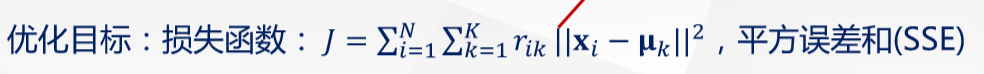
可用迭代求解(坐标轴下降法): •固定𝛍k,优化𝑟ik; •固定𝑟ik,优化𝛍k。
优化过程

K-means是在损失函数上进行坐标轴下降(coordinate descent)优化。训练集上𝐾越大,损失越小
预处理
归一化数据(e.g. 缩放到单位标准差) ;消除离群点
后处理
删除小的簇:可能代表离群点 ; 分裂松散的簇:簇内节点间距离之和很高 ;合并距离较近的簇
局限性:当具有不同的尺寸、密度、非球形时可能得不到好的结果。
优点:
• 一种经典的聚类算法,简单、快速
• 能处理大规模数据,可扩展型好
• 当簇接近高斯分布时,效果较好
优化
均值作为中心易受到影响,换用中位点作为中心比较好。均值极有可能是一个不存在的样本点,不足以代表该簇中的样本,而中值 是一个样本集合中真实存在的一个样本点 。 相对均值而言,中值对噪声(孤立点、离群点)不那么敏感















 4797
4797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









