






一. 前言
最近迷上了一款小时候的页游,但是刷副本的过程非常之枯燥,所以就自己学着做了一个脚本解放双手。文章分为俩部分,分别是教程一和教程二,教程一主要描述了如何识别页游中奇形怪状的文字或是数字以及软件的使用等,教程二主要是举例子,一个简单的流程用于快速上手,相信如果真的了解了这些,无论做什么页游脚本都会有些自己的想法。
二. 所需准备(软件)
1.按键精灵2014版
2.大漠插件
3.大漠偏色计算器
通过网盘分享的文件:按键精灵+大漠+偏色
链接: https://pan.baidu.com/s/1FopkUHyThmefU_A7kPjy1w?pwd=6666 提取码: 6666
三. 制作字库
在不同的页游中,其字体都是不同的,有的是渐变颜色组成的,有的是自创的艺术字体,所以识别它们需要不同的步骤
3.1 按键精灵嵌入大漠插件
这里就简单演示一下,按键精灵是如何调用大漠插件的,过程很简单
首先,打开按键精灵2014版,并新建一个脚本文件
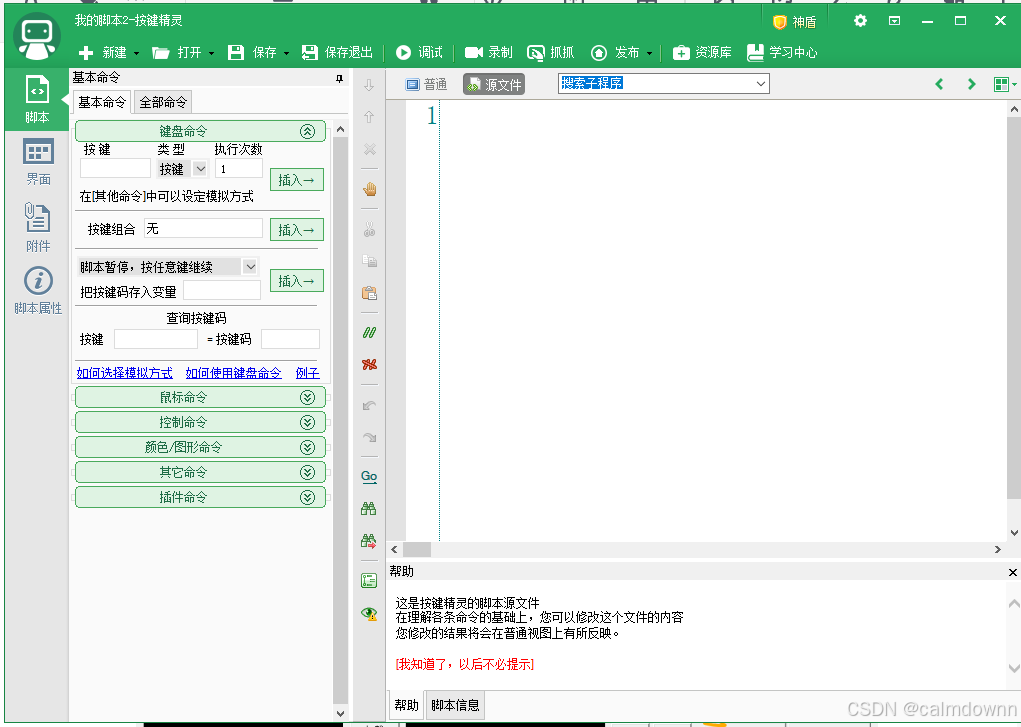
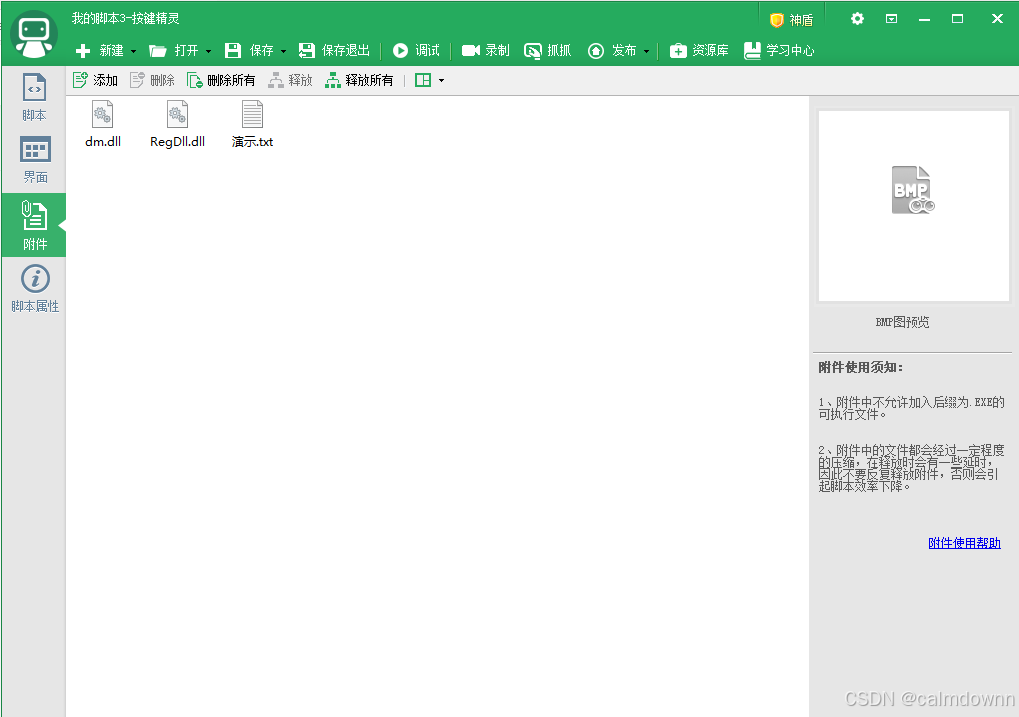
然后点击左侧的附件,我们将俩个dll文件直接手动拖过去(俩个dll文件在解压之后的大漠插件文件夹里,或者直接拖拽网盘里给出的,我将它俩放在了外面)
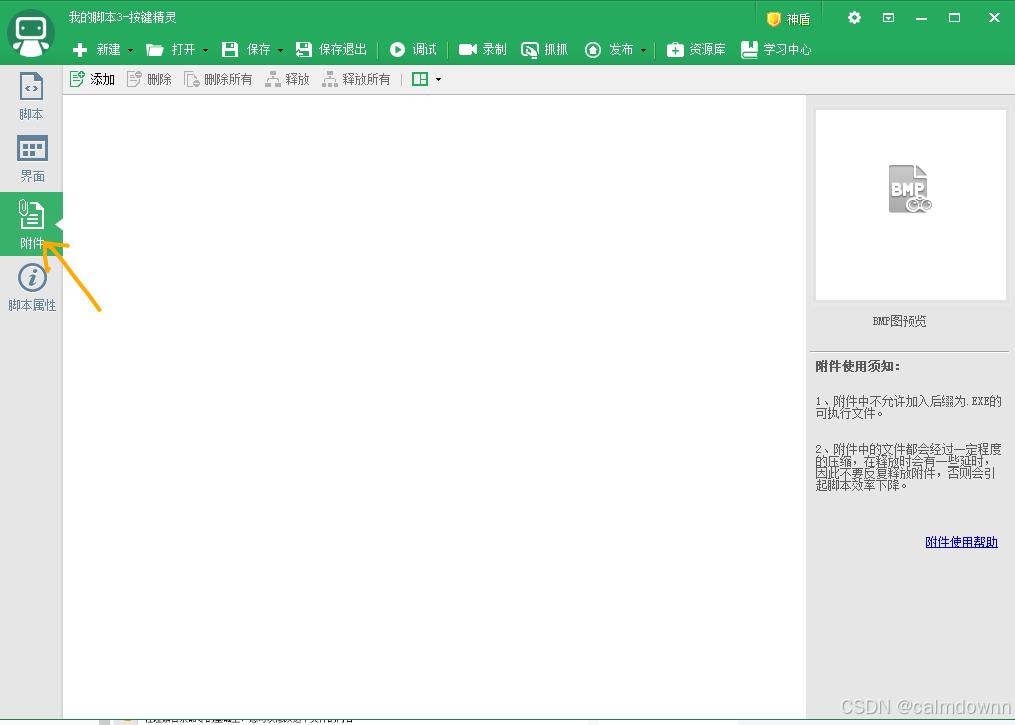
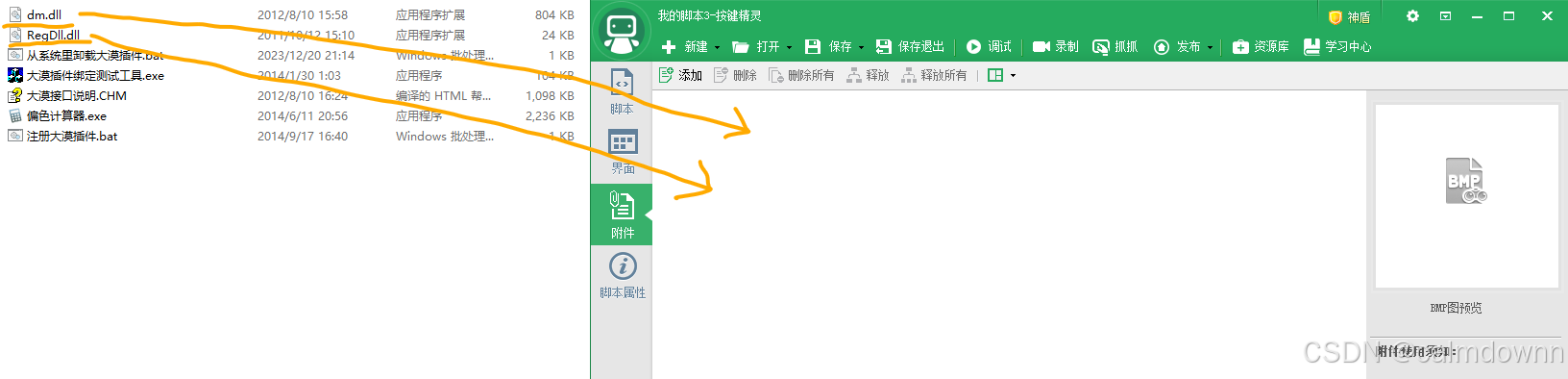
效果如下:
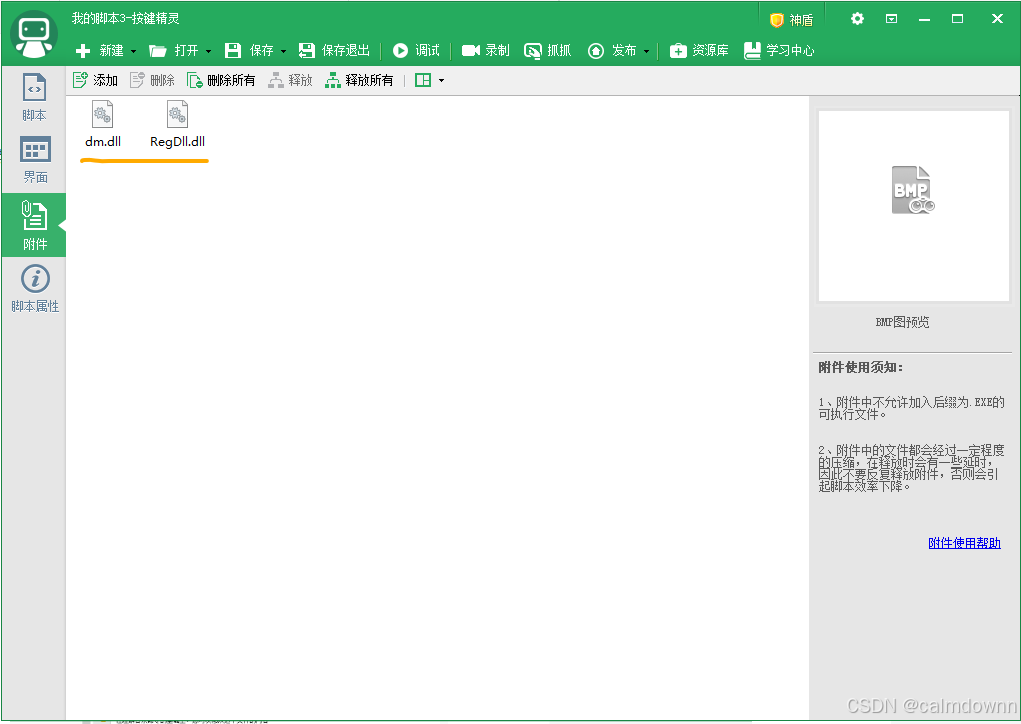
然后我们将代码复制到脚本中
PutAttachment "c:\test_game", "*.*"
PutAttachment ".\plugin","RegDll.dll"
Call Plugin.RegDll.Reg("c:\test_game\dm.dll")
Set dm = createobject("dm.dmsoft")
ver = dm.Ver()
TracePrint ver
base_path = dm.GetBasePath()
dm_ret = dm.SetPath(base_path)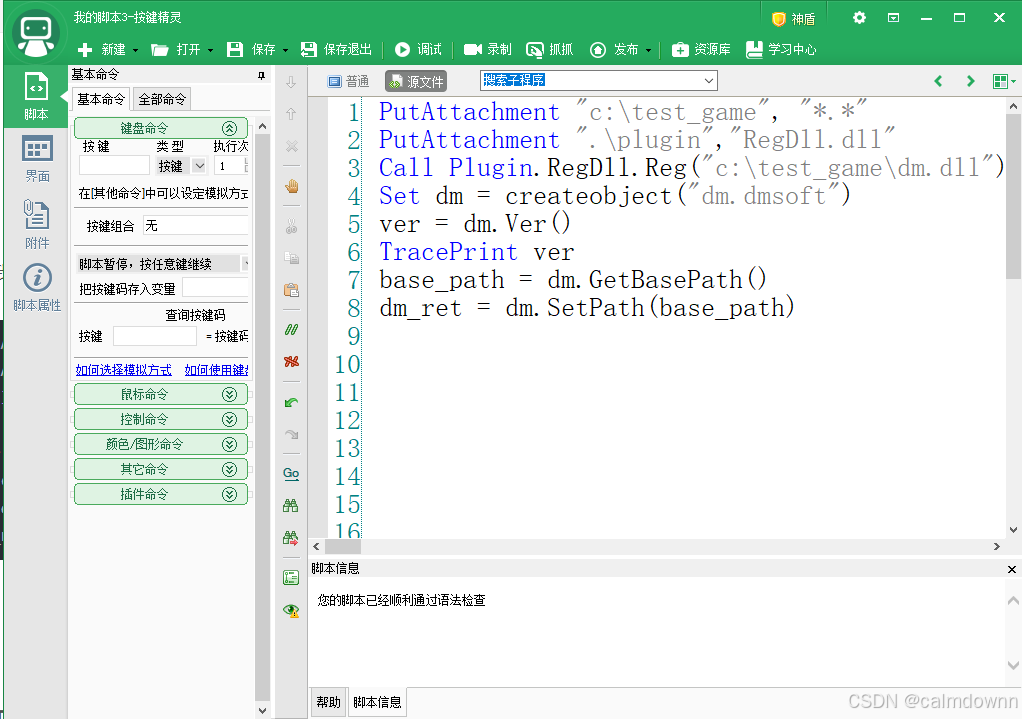
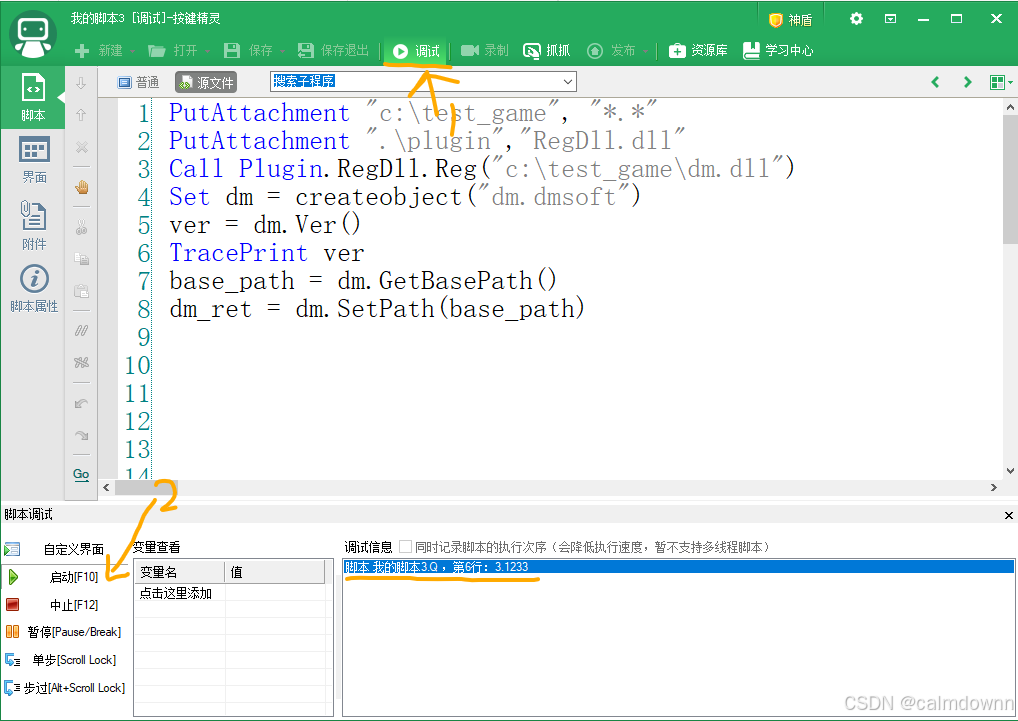
然后我们点击上面的调试,运行一下代码,出现版本信息就是调用成功了
3.2 识别简单字体
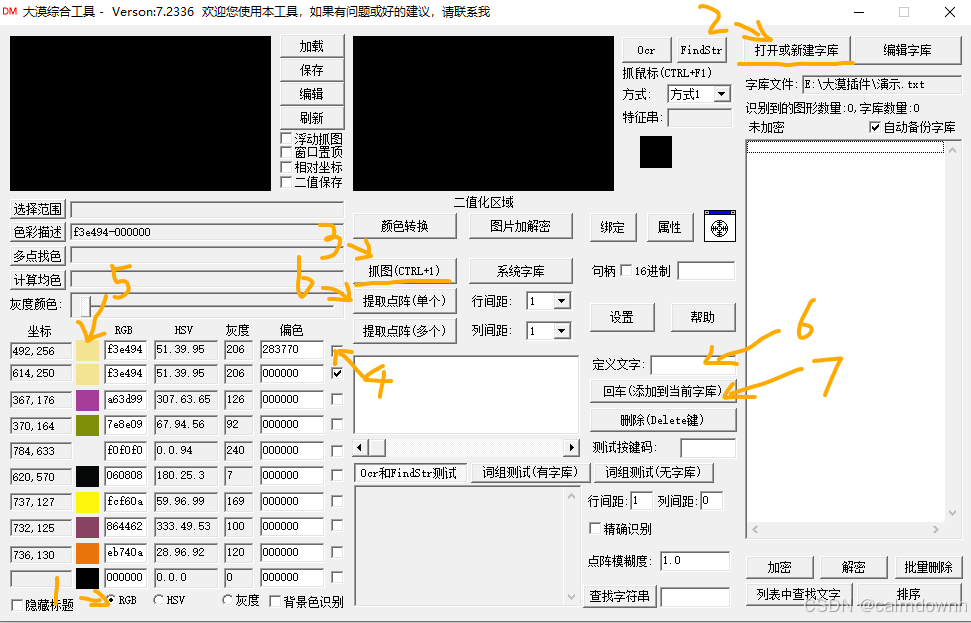
首先,打开大漠综合工具,大致使用过程如下,第一步选择左下角的RGB,此项目的是以图片中的文字颜色进行提取。第二步选择右上角的打开新建字库,新建一个空白的字库并命名,中文英文都可以。第三步选择中间的抓图也可以使用快捷键(ctrl+1),将你要识别的图片截取下来,截取成功之后按回车即可自动跳回工具。然后第四步将颜色部分的第一行进行打√,第五步点击第一行颜色区域进行颜色提取,接着第六步选择提取点阵(单个),接着第七步定义文字,最后第七步回车即可。这样说可能有点不易理解,下面简单举个例子。
举个例子,比如想获取如下图片中的文字(截图快捷键为ctrl+1,回车为确认)
![]()
首先,点击下面橘色箭头的位置,对文字的主体进行颜色提取,可以发现图片中的所有文字都是由黄色组成的,所以我们提取黄色之后在右边二值化区域中就可以看到干净的文字了
二值化:通过设定得阈值将图片中的像素颜色值分为黑色和白色,大漠综合工具里的阈值就是我们提的颜色。通俗来说就是你给他一个颜色,他会去图片里查找,找到和这个颜色相同得所有像素点,并将它们统一变为白色,剩下颜色为黑色。
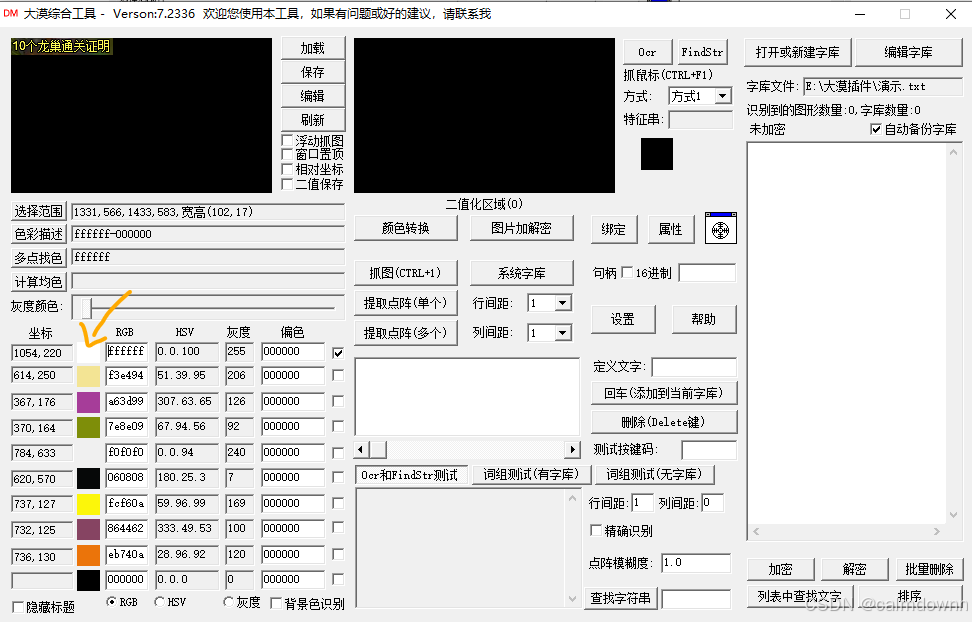
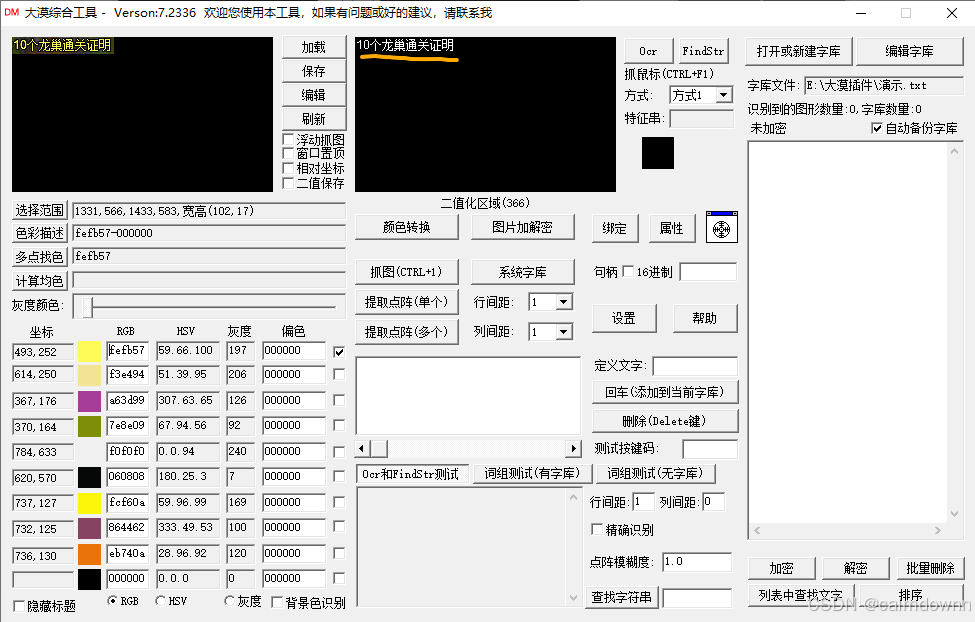
接下来, 点击提取点阵(单个),当然也可以提取为点阵(多个),区别就是单个生成的是一整串文字矩阵,而多个是会自动将文字切分开来,我这里为了方便就直接单个了
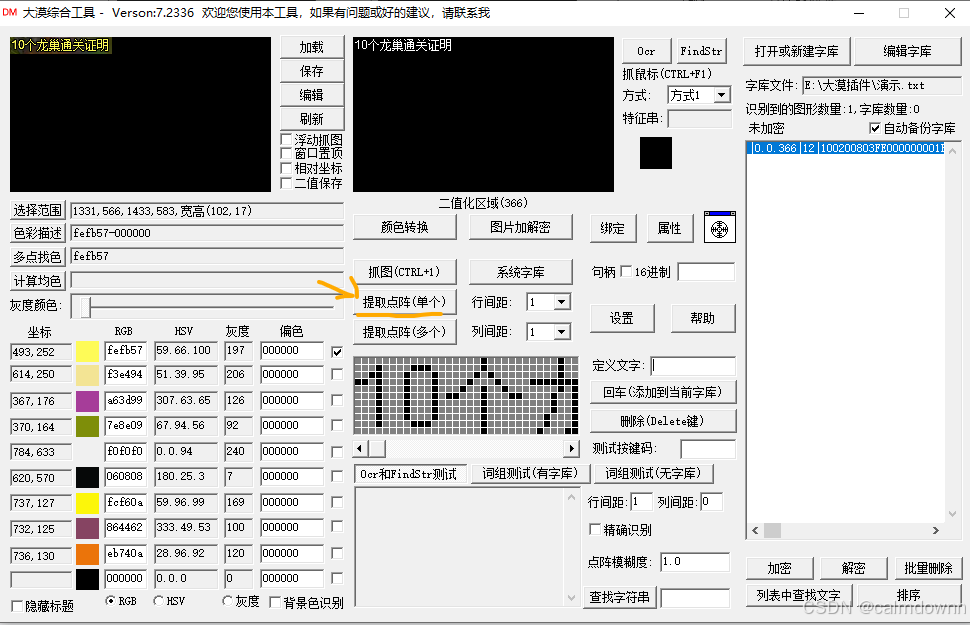
接着在定义文字处输入你自定义的字符串,最好拿英文测试,然后步骤2(测试区域)和步骤3就会自动生成了,这个字符串就是你以后用于识别固定位置图片的时候会返回的值
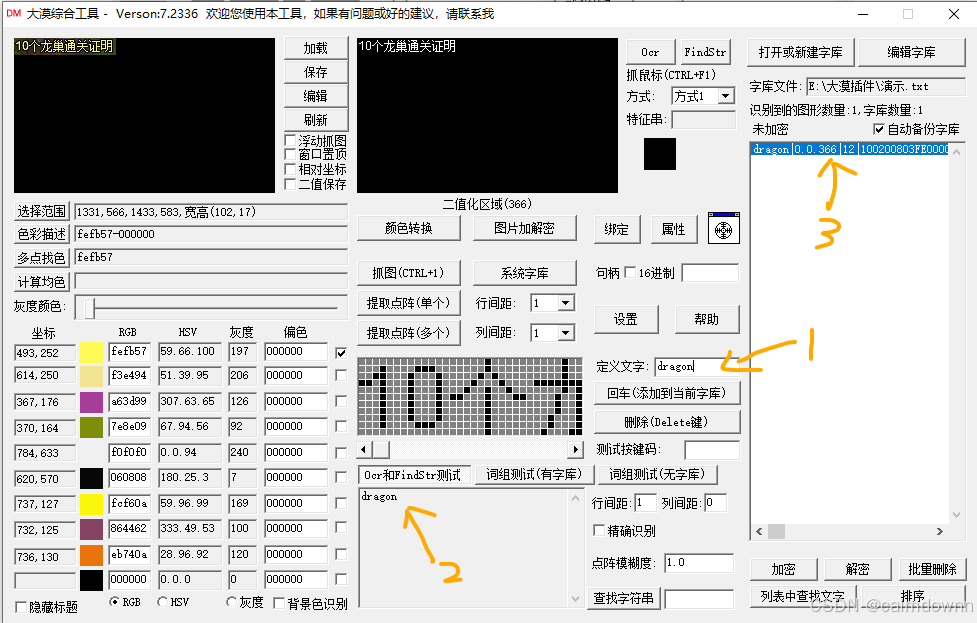
这样一个简单的自定义字库就做好了,小总结一下,首先就是截取区域图片,然后将图片中文字主体颜色提取出来,之后会自动生成在二值化区域,提取点阵,本质就是对比的矩阵结构,然后定义文字。
简单测试一下,首先打开按键精灵2014,然后将我们新建好的字库导入进去,步骤如下:
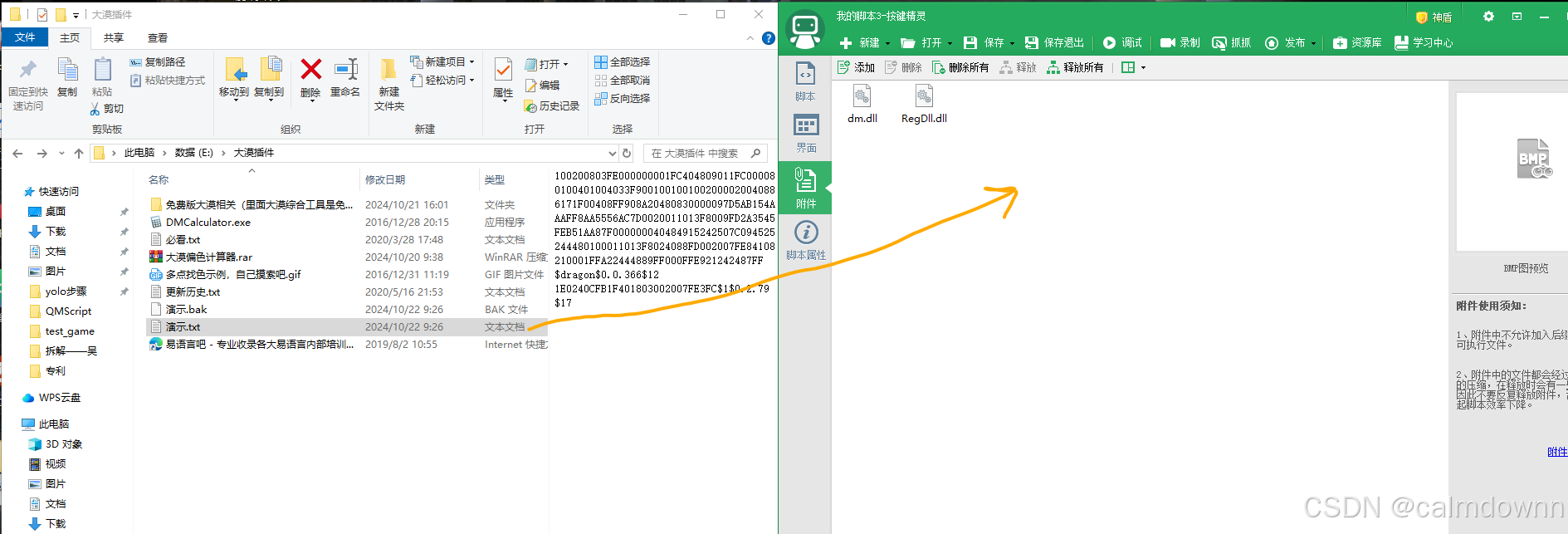
接下来,我们首先点击右上角的Ocr按钮,其会生成一段代码,我们只取最后一行
代码含义:dm.Ocr()是大漠插件中用于Ocr识别的方法,用于字库识别,前四个参数分别为截图位置的左上角x,y坐标以及右下角的x,y坐标,第五个参数代表(16进制颜色值-16进制偏色值),第六个参数代表相似度,也就是和点阵的相似程度,1.0为最相似,0.1为一点相似。上述五个参数都能在打磨综合工具中找到,自己手动填写也是可以的
s = dm.Ocr(1331,566,1434,584,"fefb57-000000",1.0)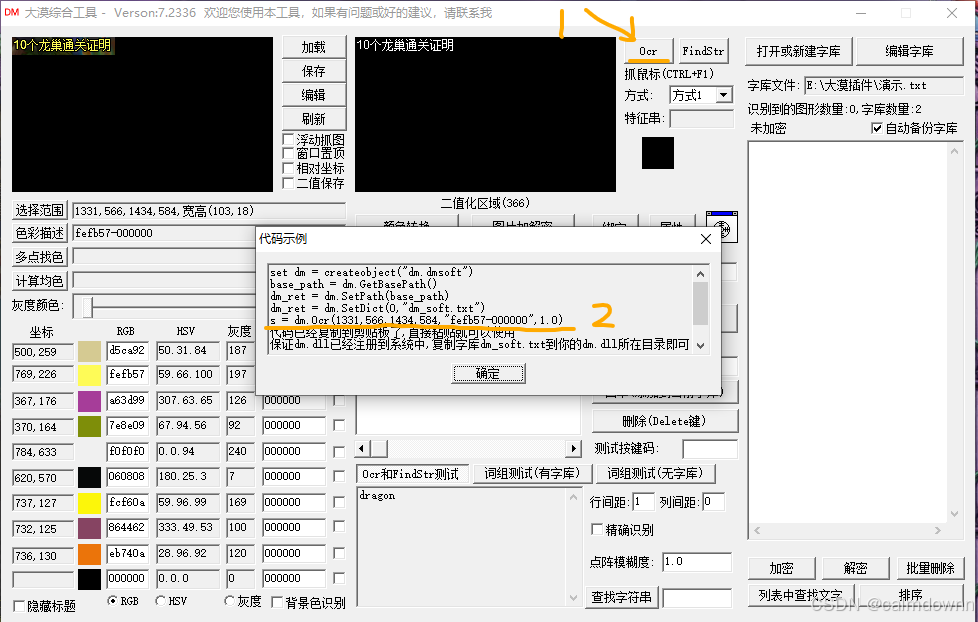
现在识别的参数有了,接下来就需要设置我们刚才新建的字库了,我这里名字为演示.txt
dm_ret = dm.SetDict(0, "演示.txt")全部代码如下:
PutAttachment "c:\test_game", "*.*"
PutAttachment ".\plugin","RegDll.dll"
Call Plugin.RegDll.Reg("c:\test_game\dm.dll")
Set dm = createobject("dm.dmsoft")
ver = dm.Ver()
TracePrint ver
base_path = dm.GetBasePath()
dm_ret = dm.SetPath(base_path)
dm_ret = dm.SetDict(0, "演示.txt")
s = dm.Ocr(1331, 566, 1434, 584, "fefb57-000000", 1.0)
MessageBox s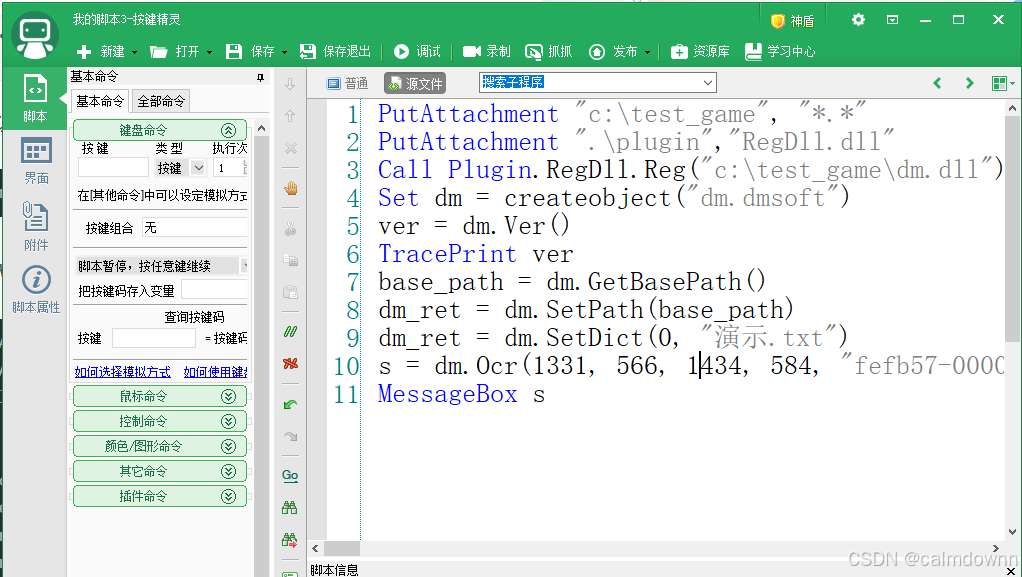
流程就是,先setDict设置字库,然后Ocr进行识别(注意你在做字库时候的坐标和实际检测坐标最好要完全一样,不然可能会有识别不准的问题),然后MessageBox弹窗一下看看是不是我们设置的字符。

如上图所示,我们可以看到代码运行成功了,右侧的文字识别为dragon了。
3.3 识别颜色复杂字体
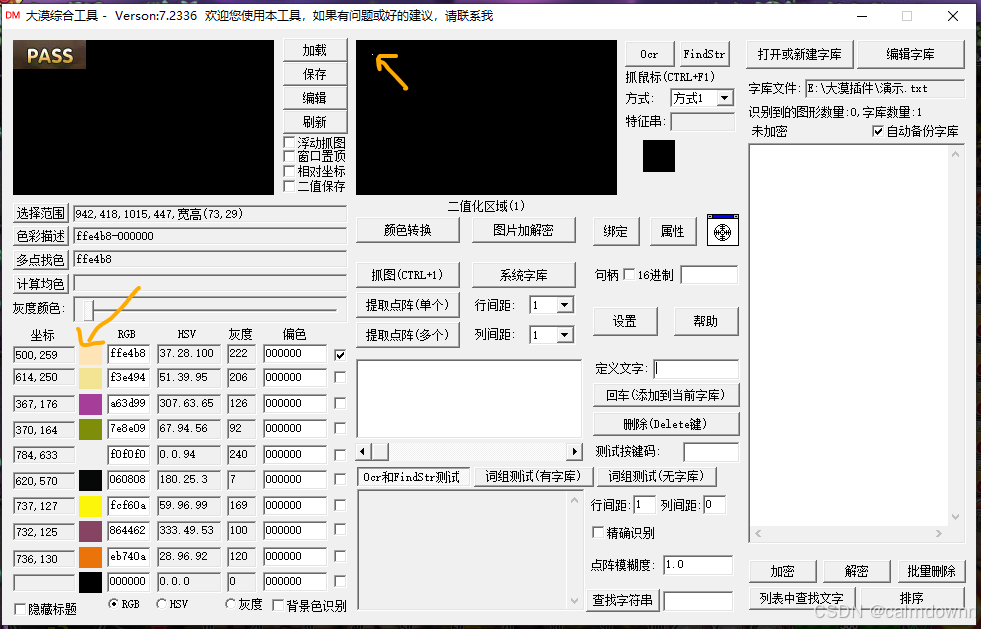
颜色复杂的字体本身含有几种甚至几十种颜色,仅仅通过一种颜色来获取字体的全部结构是不可能的,举例图片如下:

可以看出,上图中的PASS是一个多种颜色组成的渐变字体,那么只取一种颜色就会出现下图中的情况,只会生成一个白色的点,那是因为抓取的颜色是字体中唯一的颜色,字体中其他部分没有任何一个颜色和它是相同的。这时候我们就要设置其偏色值了,偏色值其实就是颜色的偏差范围。
偏色计算(科普):
1.将多种16进制颜色值分解为R,G,B并转化为10进制,方便计算
2.将最大的R,G,B颜色值和最小的R,G,B颜色值找出来,然后对应相加并除以2(大+小)/2
3.使用最大的R,G,B颜色值或者是最小的R,G,B颜色值与步骤二求出的平均R,G,B颜色值进行相减,得到的R,G,B颜色差值就是最终的偏色值了,将其转化为16进制便于使用。
偏色写法(科普):"FFA500-101010",表示增加101010颜色偏差范围进行判断
当然了,我们不可能用上述的步骤一个个算,那样太浪费时间了,接下来就要使用到了开头提到的工具--大漠偏色计算器,这个计算器可以帮助我们很轻松的就获取想要的偏色值。
还是一步一步来,首先点击抓图按键(ctrl+q),将在大漠综合工具中的生图抓取下来
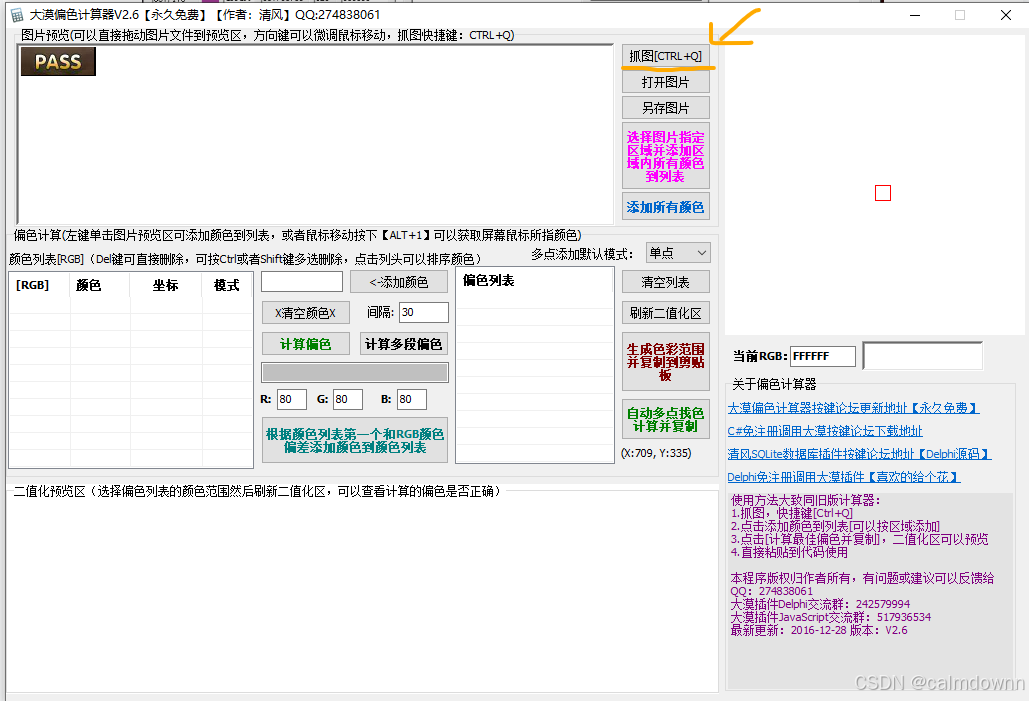
接下来,鼠标放在文字主体上,选择一个你喜欢的颜色提取出来,如下图,提取了P中某一个像素的颜色

然后点击根据第一个颜色自动添加附近其他颜色值
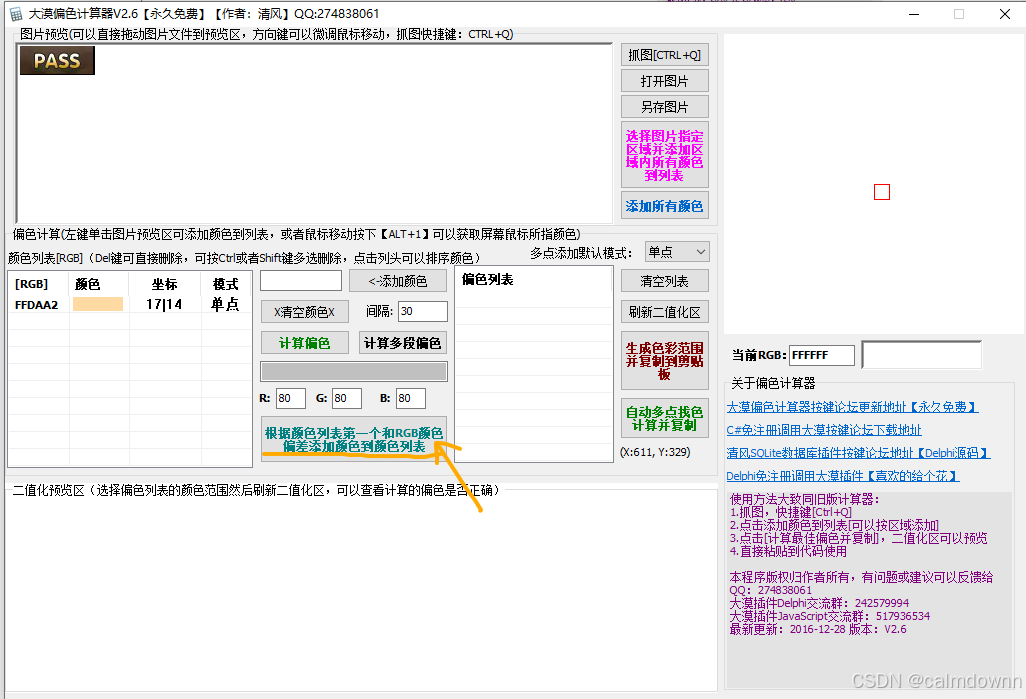
获取的其他颜色会进入到列表中
然后点击计算偏色按钮,会自动生成橘色箭头2和3,2就是其根据列表中所有颜色所计算的偏色值,箭头3是显示的二值化预览区,其效果是和大漠综合工具中的二值化区域是完全相同的,所以只需要在此区域调整到我们想要的效果即可
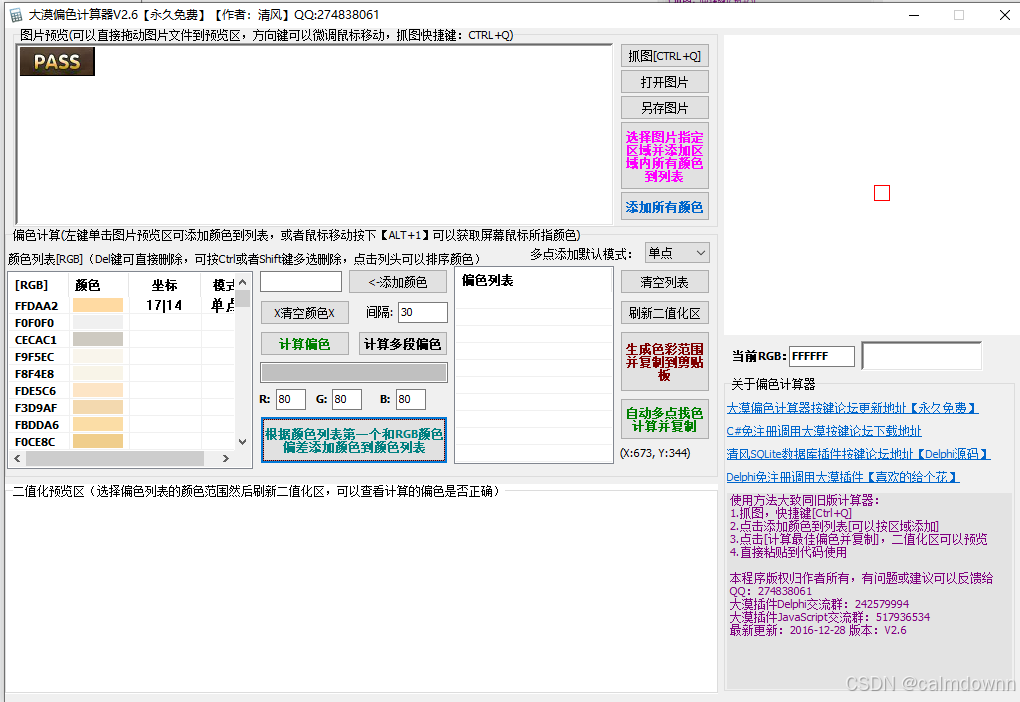
可以看出PASS的轮廓虽然出现了大部分,但是下半部分还是不太清晰,那我们就再次进行单点颜色提取,然后再重复上述的步骤,计算更复杂的偏色
既然上述的二值化区域下半部分不太清晰,那我们这次就取下半部分的颜色,选取A的最下脚的颜色,将箭头部分的颜色拉到底可以看到我们新选择的颜色,后面有个单点的标志,接下来又是基于此单点颜色的新一轮添加颜色和计算偏色
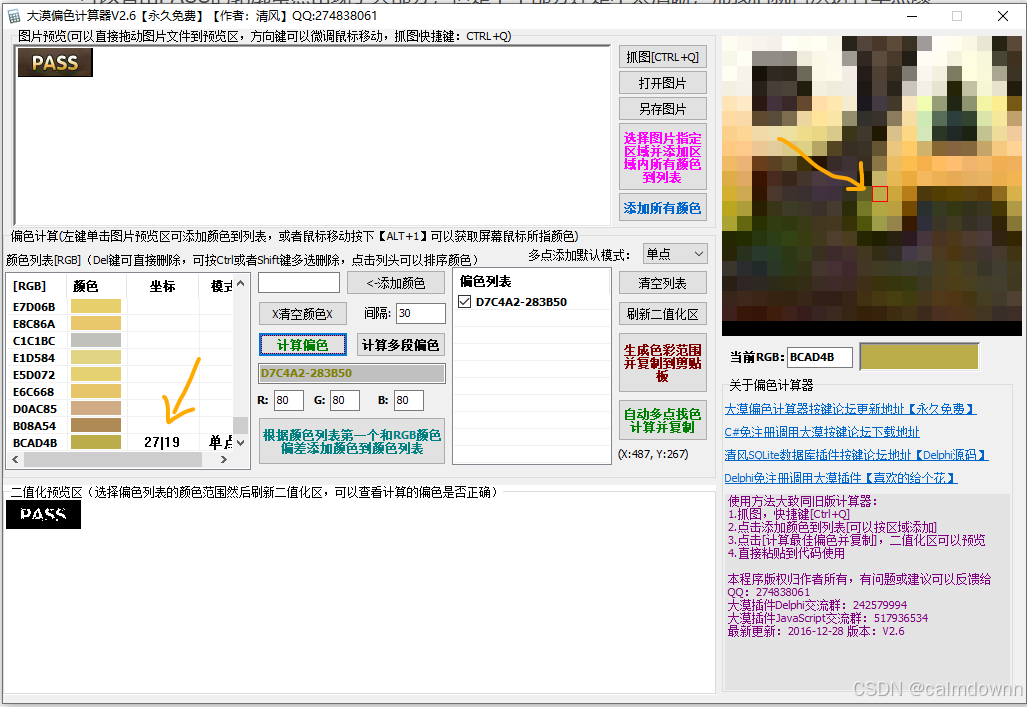
还是继续添加颜色,可以看到左边颜色又自动增加了很多。
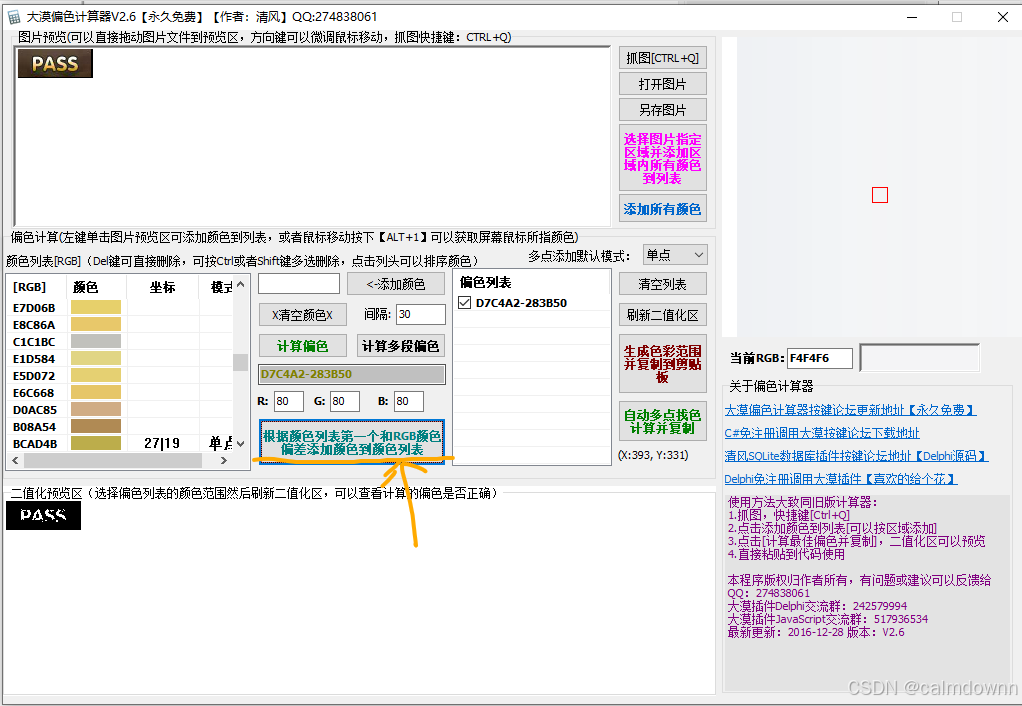
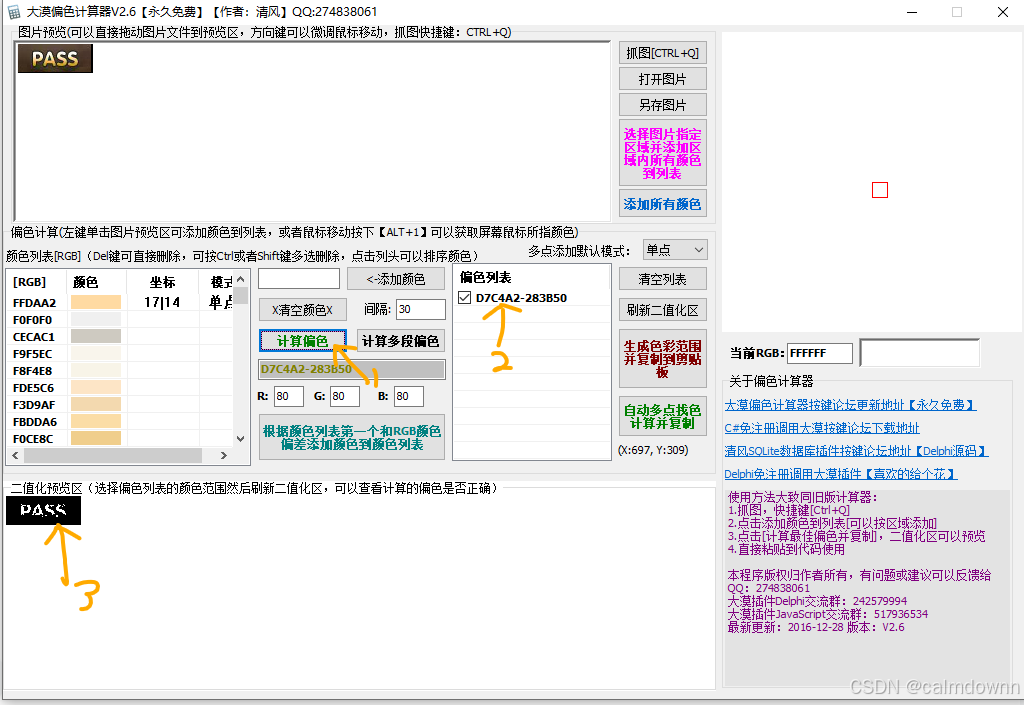
然后计算偏色,上述的过程可以多进行几次,也可以清空列表重新选基础颜色,直到选出满意的效果,可以看出经过多次提取之后,PASS字样清晰了很多。
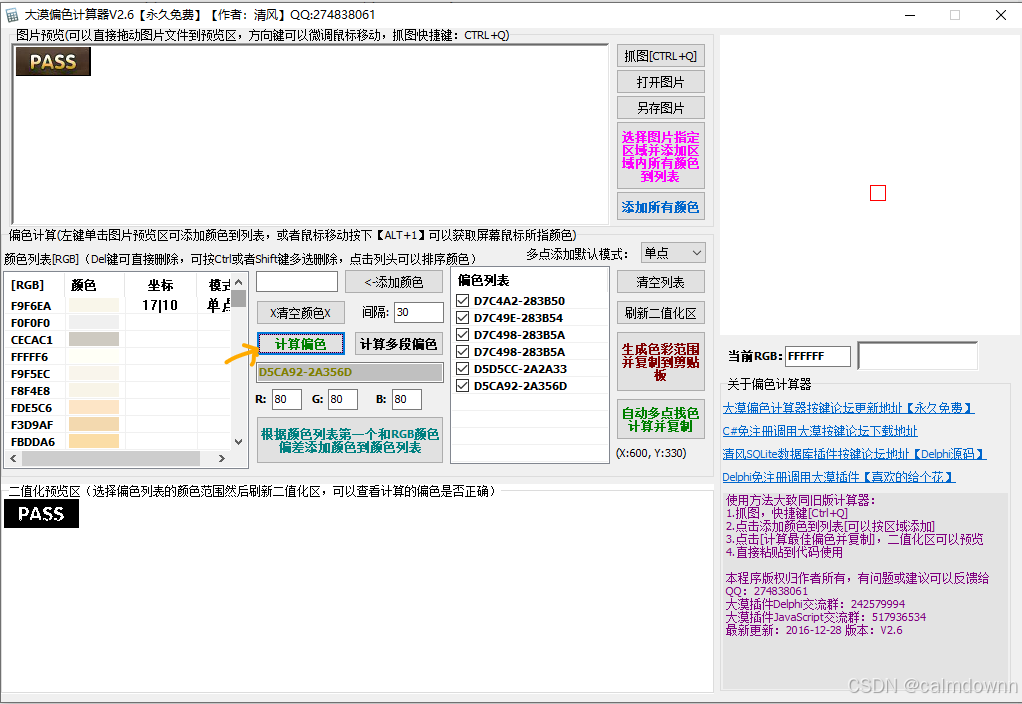
接下来,我们将偏色列表中最后一个偏色值选中,其他的都取消选择,接着点击复制到剪切板按钮
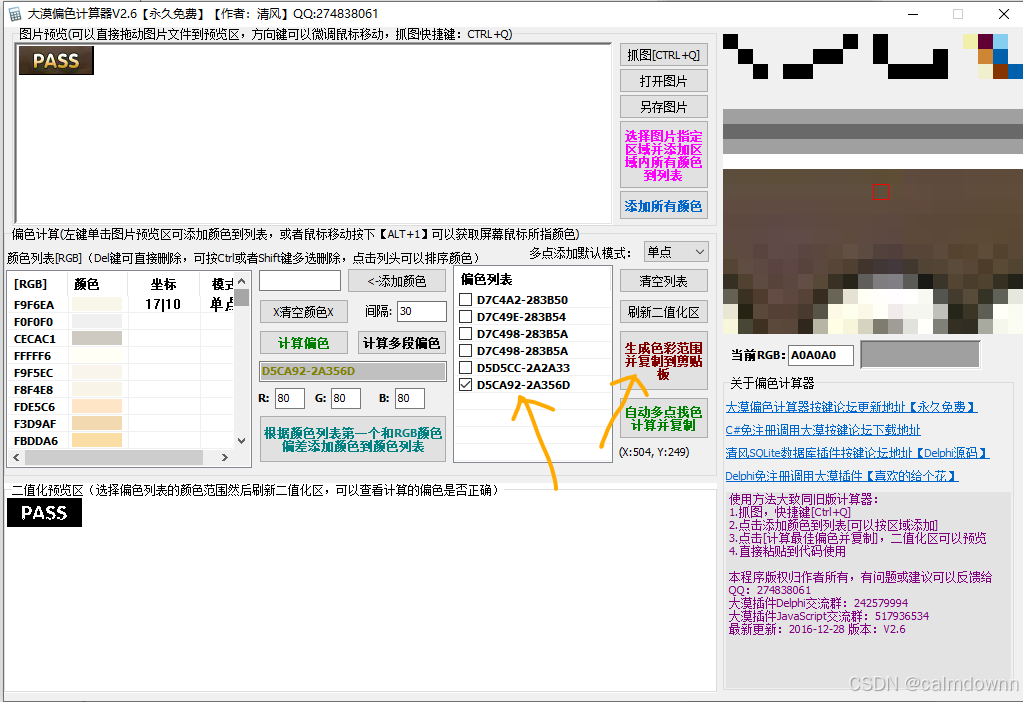
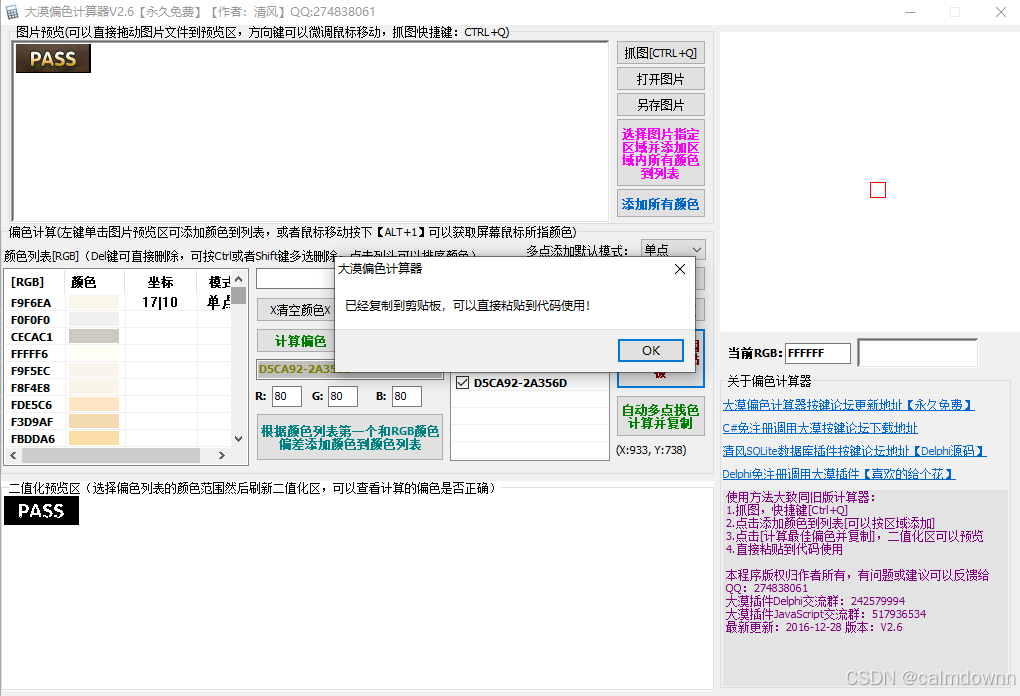
剪切板为:D5CA92-2A356D,前半段为16进制的颜色值,后半段为16进制的偏色值,我们回到大漠综合工具中,将这俩部分分别复制到图片中的俩部分,如图步骤一和步骤二,就可以看到效果图出来了,原来的二值化区域从开始的一个点已经变成能识别大部分的主体了。
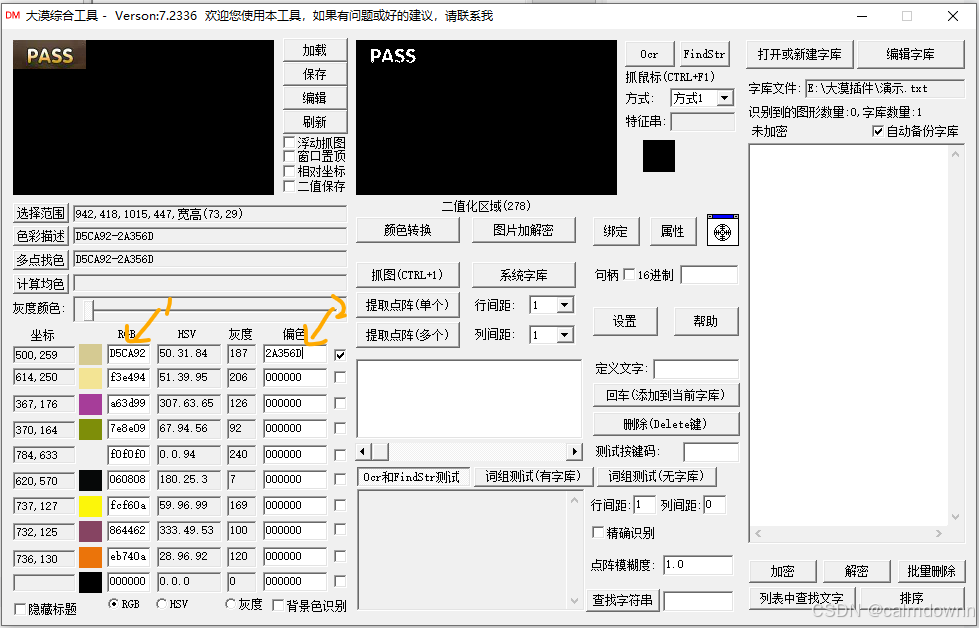
剩下的步骤还是和3.2是相同的,提取点阵,定义文字,然后可以导出Ocr使用代码进行实战测试一下。
3.4 识别颜色不停变化的字体
上一个只是文字中颜色组成较多,可是如果你遇到的每时每刻都在变换颜色的字体怎么办,那么我们上面使用偏色值的方法就不奏效了,下面我们还是使用大漠综合工具来操作,举例图片如下:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
从上述多张图片中可以看出,其颜色每时每刻都在变化的,其中任何一个数字都会变换不同的颜色,那这次我们就要观察细节了,找共通点。

图片放大后,可以看到数字1的周围是有一圈黑色像素包围, 可以试试直接取黑色然后进行二值化,还是和上面步骤相同,选中RGB,这次选灰度也可以,因为都是黑色,灰度为0也代表纯黑,然后勾选最后一行(也就是最开始默认的行全为0),这次不用再吸取颜色,只使用默认的黑色就可以,然后可以在右边的二值化区域看到数字1的雏形了
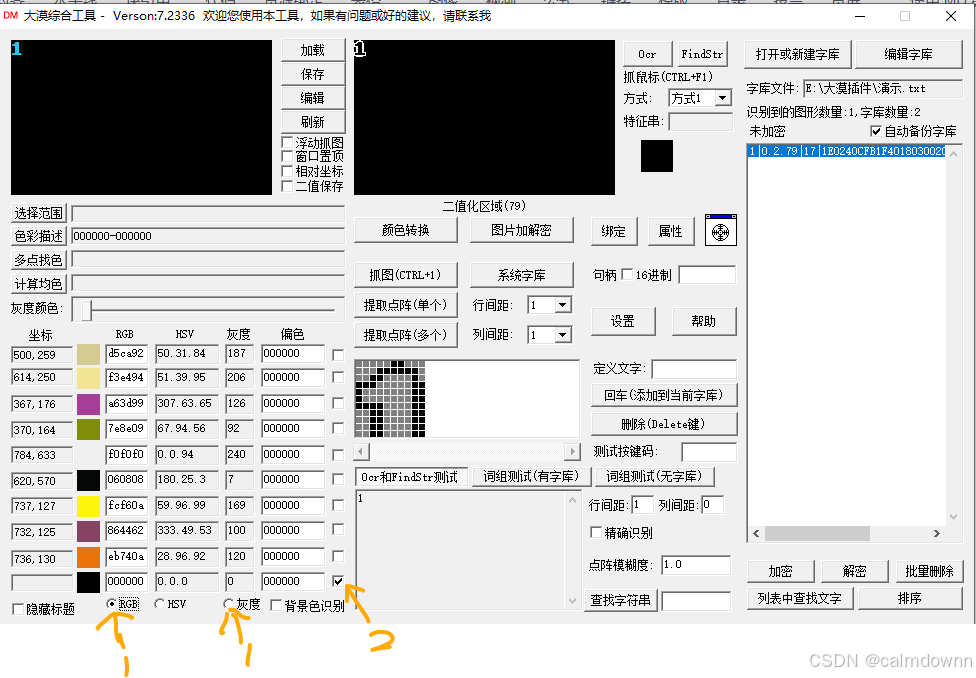
接着继续提取点阵,可以看到有1的轮廓出来了,我说一下为什么是空心的,因为我们取得是图片中的纯黑色,所以图片中得黑色仅仅是在数字旁围了一圈,所以经过二值化之后只会保留我们选取得黑色,其他不管。
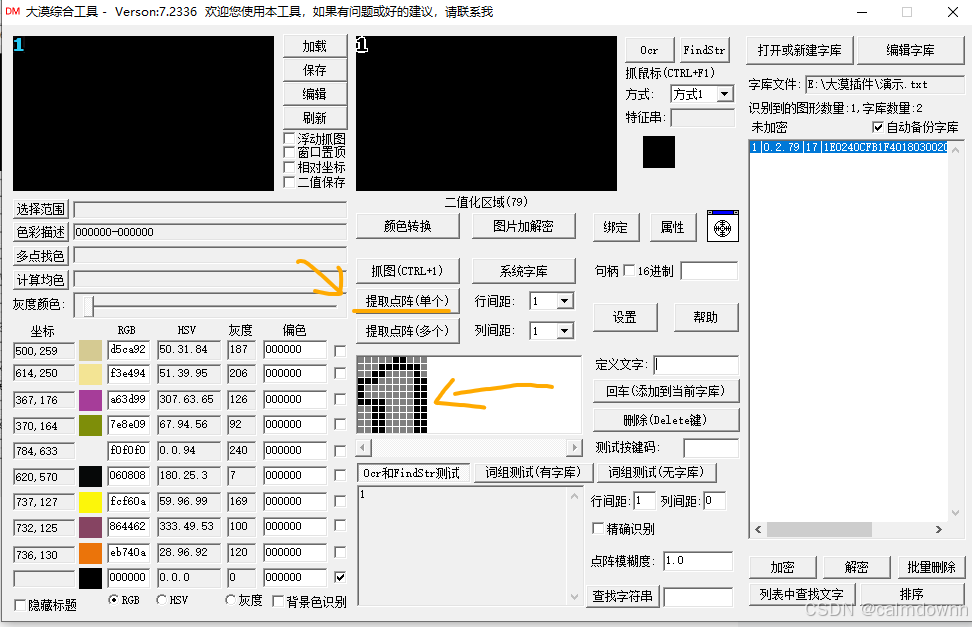
所以无论接下来数字的颜色如何变化,包围在数字外层的一圈黑是固定的,我们只需要每次在相同的位置进行截图验证,那么每次所获得的轮廓都是完全相同的,也就是点阵是一样的,这样就可以以不变应万变了。
这个简单测试一下,演示一下(过程代码就不重复写了,可以看3.2的最后部分,代码过程是相同的,换一下参数就可以了),可以看到左下角的力度可以很准确的识别出来,可以看到就算字体颜色变化也不会影响识别的准确性。
我演示的图片中是双数字识别,其实就是十位的数字我做了一个字库,个位的我也做了一个字库,然后将俩个进行拼接就得到了下图中的效果。
核心代码如下:
注意:如果你有俩个字库你就要setDict俩次,以此类推,几个字库set几次,然后在使用的时候要分开使用,比如你需要识别第一个字库中的字符,那你就dm.UseDict(0),以此类推,在调用Ocr之前一定要确保你使用的字库是正确的,每次重新dm.UseDict之后,后面所有dm.Ocr的方法使用的都是上一个UseDict的字库,所以如果上一个ocr和下一个ocr所需不同就需要重新UseDict一下。
dm_ret = dm.SetDict(0, "弹弹堂数字库左.txt")
dm_ret = dm.SetDict(1, "弹弹堂数字库.txt")
//角度左边数字
dm_ret = dm.UseDict(0)
s1 = dm.Ocr(515, 824, 529, 840, "#0-0", 0.9)
//角度右边数字
dm_ret = dm.UseDict(1)
s2 = dm.Ocr(530, 824, 542, 841, "#0-0", 0.9)
s = s1 + s2
MessageBox s
第一部分目前就这些了,下一部分就是实战了,希望大家能有所收获。

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









