







Presto的介绍
- Presto是Facebook开发的分布式SQL查询引擎,用来进行高效、实时的数据分析;
- Presto可以连接Hive、Mysql、Kafka等多种数据源,最常用的是通过Presto连接Hive数据源,可以解决Hive的MapReduce查询耗时太慢的问题;
- Presto是一个基于内存的计算引擎,它本身不存储数据,通过丰富的Connector获取第三方服务的数据,例如可以获取Hive数据源保存在HDFS上的数据,将数据加载到内存进行计算,查询数据很快。
Presto的数据模型
- Catalog:数据源,例如Hive、Mysql都是数据源,Presto可以连接多个Hive和多个Mysql;
- Schema:类似于DataBase,一个Catalog下有多个Schema;
- Table:数据表,一个Schema下有多个数据表。
Presto查询语句示例:
# 连接多个数据源进行查询
select * from hive.testdb.tableA a join mysql.testdb.tableB where a.id = b.id
# 查看Presto支持的所有数据源
show catalogs
# 查看所有Schema
show schemas
通过Presto客户端查询Presto命令
# 端口号默认是7670 --catalog指定连接的数据源 --schema指定连接的数据库
./presto-cli-0.212-executable.jar ip:端口号 --catalog hive --schema default
Presto的架构
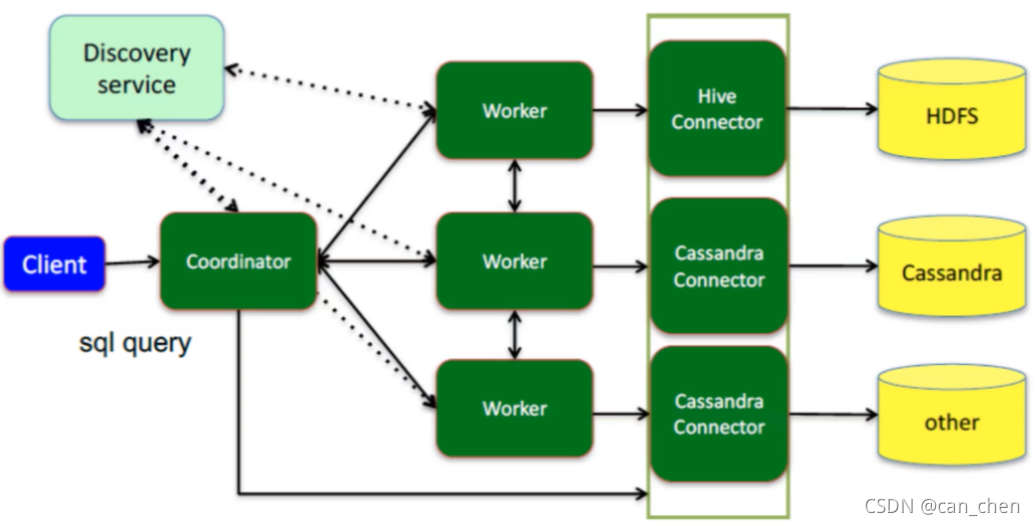
Presto也是主从架构,由三部分组成:一个Coordinator节点、一个Discovery Server节点,多个Worker节点;
Coordinator为主节点,负责解析SQL语句,生成查询计划,分发执行任务;
Discovery Server负责维护Coordinator和Worker的关系,通常内嵌于Coordinator节点;
Worker节点负责执行查询任务以及与数据源进行交互读取数据。
Presto连接Hive数据源的架构图:
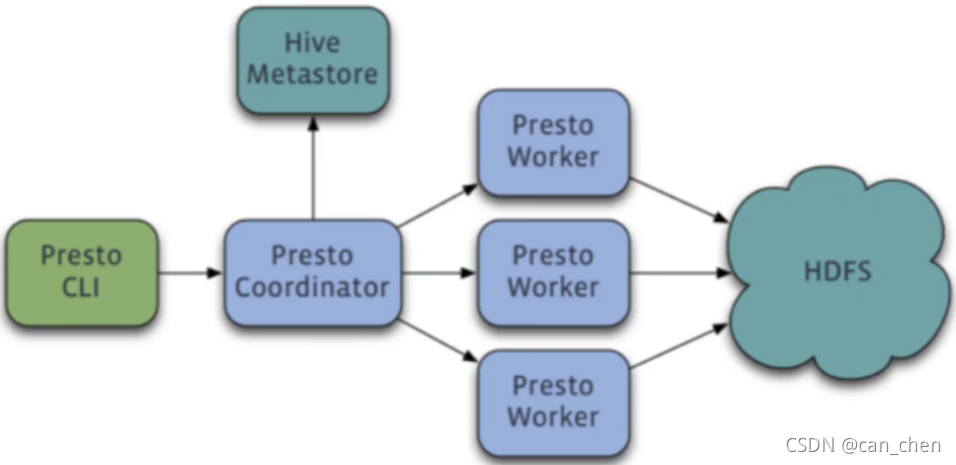
工作原理:Presto Coordinator接收Presto客户端发送的SQL语句,根据Hive的元数据信息,解析SQL语句,生成查询计划,并将任务分发给多个Worker节点,Worker节点会读取HDFS上的数据到内存中来进行计算,并将结果返回给Coordinator节点,Coordinator节点再将数据返回给Presto客户端。
Presto连接多数据源的架构图:
Java程序访问Presto
Java程序中,是通过JDBC的方式访问Presto的,就类似于通过JDBC访问Mysql数据库一样,举例如下:
<!--导入依赖-->
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-jdbc</artifactId>
<version>0.212</version>
</dependency>
public static void main(String[] args) throws SQLException {
// 注册presto驱动
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
// 获取presto连接(指定url、用户名、密码)
Connection connection = DriverManager.getConnection("jdbc:presto://192.168.110.112:7670/hive/default", "root", "123456");
// 执行SQL查询
Statement statement = connection.createStatement();
ResultSet res = statement.executeQuery("show tables");
while (res.next()) {
System.out.println(res.getString(1));
}
res.close();
// 假设表tableA有两个字段
ResultSet resultSet = statement.executeQuery("select * from tableA");
while (res.next()) {
System.out.println(resultSet.getString(1) + "---" + resultSet.getString(2));
}
resultSet.close();
connection.close();
}
Presto注意点
一般来说,使用Presto操作Hive等数据源是为了加快查询速度,并不支持通过Presto去更新Hive等数据源,例如通过Presto去操作Hive添加分区会失败。














 1450
1450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









