







下面的描述参考于这里的文档。
在早期,建立一个计算机系统是比较简单的,因为用户的期望没有那么多。从存储器的观念来看,早期的设备没有给用户提供太多的抽象。基本上设备的物理存储器的状态就如图1所示的那样。图1中操作系统从地址0开始存放,用户程序或进程从地址64KB开始存放,剩下的存储器空间可以被操作系统或用户程序使用。

在早期设备是比较昂贵的,为了更有效率的使用设备,随着时间的推移,来到了
M
u
l
t
i
p
r
o
g
r
a
m
m
i
n
g
Multiprogramming
Multiprogramming和
T
i
m
e
S
h
a
r
i
n
g
Time\quad Sharing
TimeSharing的纪元。也就是多个用户程序中的每一个都在指定的时间内运行,操作系统负责对这些用户程序进行切换,决定当前哪一个用户程序可以运行,这里多个用户程序不可能同时运行。实现
M
u
l
t
i
p
r
o
g
r
a
m
m
i
n
g
Multiprogramming
Multiprogramming和
T
i
m
e
S
h
a
r
i
n
g
Time\quad Sharing
TimeSharing的一种方法是当操作系统分配某一个用户程序A运行的时候,操作系统会给与该用户程序A接入整个存储器的权限,运行一段时间该用户程序A之后停止该用户程序A,等到轮到下一个用户程序B运行的时候,此时操作系统会先保存用户程序A的所有状态以及当前存储器中的所有内容到硬盘等存储设备中,然后加载用户程序B的状态并运行。下次再次轮到用户程序A运行的时候也会先保存其它用户程序的所有状态到硬盘等存储设备中,然后加载用户程序A的状态并运行。这里多个用户程序不会同时存在于存储器中。这种方法很大的一个问题是速度非常慢,尤其是当内存空间(也就是我们电脑的主存
R
A
M
RAM
RAM)越来越大的时候,因为这样要保存的内容也越来越多。
现在通常的做法是将这多个用户程序同时留在内存中,由操作系统来对它们进行切换。如图2所示。这里一共有三个用户程序A、B和C同时留存在内存中,每一个用户程序都分别占据整个内存空间的一小部分,由操作系统决定每一个用户程序的执行时间。

随着多个用户可以同时驻存在内存空间中,另外一个需求也随着出现了,那就是一个用户程序只能操作其自己的指令和数据,而不能操作其它用户程序的的指令和数据。随着用户需求越来越多,这时出现了地址空间的概念,地址空间是操作系统对内存空间的一种抽象,它是用户程序对内存空间的视角。在用户程序对内存空间的视角下,每一个用户程序都觉得自己独占整个内存空间(如果是32位操作系统的话,每一个用户程序都觉得自己独占4GB内存空间)。在地址空间的视角下,用户程序觉得自己的所有的内存状态都存放在这个地址空间中,例如用户程序的代码、用来跟踪程序调用,存放函数调用参数,返回值以及局部变量的栈、用于动态分配的用户自己管理的堆空间。一个用户程序的地址空间示意图如图3所示。这里展示了一个16KB大小的地址空间,这里用户程序代码从地址空间的0地址开始存放,因为代码一般在程序运行过程中是不会改变的。接下来在图所示的地址空间中是堆空间和栈空间,它们的大小在程序运行过程中会增长或减小。它们的增长方向是相反的,堆空间向着地址变大的方向增长,栈空间向着地址减小的方向增长,堆和栈的这种布局只是一个传统,其实也可以设计为其它的布局方式,但是最后选择这种传统布局的还是居多。

图3中的地址空间只是被分割成了三个部分,但是实际上可能比这个划分要细一些,如图4所示。图4中 t e x t text text区域存放代码,这部分区域的大小一般是固定大小不变的,且是只读的。 d a t a data data区域存放初始化了的全局变量和静态变量, b s s bss bss区域存放没有初始化的全局变量和静态变量。然后就是堆和栈。可以说目前绝大部分体系结构的设备都采用了这种内存空间的布局,有的可能是虚拟的地址空间,有的可能是实际的内存空间布局。

上面提到在一个用户程序的虚拟地址空间中,代码存放在从地址空间的零地址开始的一段内存空间,假设现在用户程序从其地址空间的零地址的地方开始取指令运行,但是这里的地址空间中的零地址并不是和实际的物理内存的零地址一一对应的。比如图2中的用户程序A,它占据着实际的内存空间的
320
K
B
320KB
320KB到
384
K
B
384KB
384KB的空间,因此如果用户程序A从其地址空间的零地址的地方开始取指令运行,实际上应该是从实际的内存空间的
320
K
B
320KB
320KB的地址的地方取指令开始运行。从用户程序的虚拟地址空间到其实际的物理地址的映射过程叫做内存的虚拟化,这一操作是由操作系统完成的。
下面我们来看一下一般
A
R
M
ARM
ARM单片机中内存空间的分布,一般
A
R
M
ARM
ARM单片机最常见的存储器是
F
L
S
A
H
FLSAH
FLSAH和
S
R
A
M
SRAM
SRAM。
F
L
S
A
H
FLSAH
FLSAH一般用来存放我们的程序代码(这里默认的是从
F
L
S
A
H
FLSAH
FLSAH启动的方式,如果从
S
R
A
M
SRAM
SRAM启动,代码也会放在
S
R
A
M
SRAM
SRAM中),
S
R
A
M
SRAM
SRAM用来存储程序运行过程中的相关状态,我们可以先简单的参考以下
A
R
M
ARM
ARM公司的官网的
这个位置。如图5所示。还有就是我们使用
K
E
I
L
KEIL
KEIL编译完一个
A
R
M
ARM
ARM单片机过程后我们在这个工程的
m
a
p
map
map文件的最后会看到如图6所示的内容,这里显示了我们编译之后的
B
I
N
BIN
BIN文件的大小。其中
R
W
d
a
t
a
RW\quad data
RWdata可以理解为是全局变量和静态变量,包括初始化了的核没有初始化了的,
R
O
d
a
t
a
RO\quad data
ROdata表示只读的数据,
c
o
d
e
code
code表示程序的代码,
Z
I
d
a
t
a
ZI\quad data
ZIdata表示初始化位0的数据,
Z
I
d
a
t
a
ZI\quad data
ZIdata可以简单的认为是
A
R
M
ARM
ARM单片机的工程中的
.
s
.s
.s文件中设置的堆和栈的大小,你可以通过设置
A
R
M
ARM
ARM单片机的工程中的
.
s
.s
.s文件中的堆和栈的大小为不同值然后重新编译并查看
m
a
p
map
map文件中对应于图6中的内容,你会发现
T
o
t
a
l
R
W
S
i
z
e
Total\quad RW\quad Size
TotalRWSize这一部分的大小会出现相应的变化。当然
Z
I
d
a
t
a
ZI\quad data
ZIdata肯定是包含堆和栈的,但是至于还有没有其它的内容,我这里暂时还不是太确定。当编译好的程序下载完成之后
C
o
d
e
+
R
o
D
a
t
a
+
R
W
D
a
t
a
Code+Ro\quad Data+RW\quad Data
Code+RoData+RWData会被下载到
F
L
S
A
H
FLSAH
FLSAH(假设配置为
F
L
S
A
H
FLSAH
FLSAH启动)中。在程序运行的时候
R
W
d
a
t
a
RW\quad data
RWdata,也就是全局变量和静态变量,包括初始化了的核没有初始化了的,会被首先复制到
S
R
A
M
SRAM
SRAM的开始位置,二期分配给堆和栈的空间会被初始化为0。


下面我们通过在 S T M 32 F 103 STM32F103 STM32F103芯片上的一个简单的程序来看一下 A R M ARM ARM单片机中的程序和数据的分布是否符合图4的结构,如图7和图8所示。从图7和图8我们可以看出 A R M ARM ARM单片机中的程序和数据的分布是否符合图4的结构的。


在上面的 S T M 32 F 103 STM32F103 STM32F103芯片的工程中打印出来的地址和实际的地址是对应起来的,但是对于 W i n d o w s Windows Windows等操作系统,其打印出来的地址是虚拟地址空间的地址而不是实际的物理内存空间的地址。还有就是现在有些系统为了防止黑客攻击使用了地址空间布局随机化技术,导致地址空间的布局没有遵照图4的结构。
下面再根据自己的经验介绍几个平时在 C o r t e x _ M Cortex\_M Cortex_M系列芯片调试代码的时候需要注意的点。这里我以图9中的程序为例子进行说明:
- 使用类似于关键字__attribute__((section(“.ARM.at_0xXXXXXXXX")))的方法将函数方法存储器的某一位置后,再定义一个函数指针去调用这个函数的时候这个函数指针的值必须是 0 x X X X X X X X X + 1 0xXXXXXXXX+1 0xXXXXXXXX+1,如果你使用 0 x X X X X X X X X 0xXXXXXXXX 0xXXXXXXXX作为函数指针值去调用这个函数的话会进入 H a r d F a u l t HardFault HardFault。例如我们在图9中使用关键字__attribute((section(”.ARM.__at_0x08000800")))将函数 s u b _ r o u t i n e 1 sub\_routine1 sub_routine1放到 F L S A H FLSAH FLSAH中从 0 x 08000800 0x08000800 0x08000800地址开始的地方后,定义调用该函数的函数指针值为 0 x 08000801 0x08000801 0x08000801。如果定义函数指针值为 0 x 08000800 0x08000800 0x08000800,然后用该指针值去调用该函数的话会进入 H a r d F a u l t HardFault HardFault。从图15的打印也可以看出来函数 s u b _ r o u t i n e 1 sub\_routine1 sub_routine1的地址也是 0 x 08000801 0x08000801 0x08000801。
- 还有就是在有函数调用的时候只有在大于一次递归调用的时候才会出现调用函数相应状态入栈的过程。例如在图9的程序中
m
a
i
n
main
main函数调用了函数
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1,函数
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1调用了函数
s
u
b
_
r
o
u
t
i
n
e
2
sub\_routine2
sub_routine2,函数
s
u
b
_
r
o
u
t
i
n
e
2
sub\_routine2
sub_routine2调用了函数
p
r
i
n
t
f
printf
printf。这里
m
a
i
n
main
main函数中调用函数
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1之前的相关状态以及调用完函数
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1之后的返回地址会入栈,
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1函数中调用函数
s
u
b
_
r
o
u
t
i
n
e
2
sub\_routine2
sub_routine2之前的相关状态以及调用完函数
s
u
b
_
r
o
u
t
i
n
e
2
sub\_routine2
sub_routine2之后的返回地址会入栈,
s
u
b
_
r
o
u
t
i
n
e
2
sub\_routine2
sub_routine2函数中调用函数
p
r
i
n
t
f
printf
printf之前的相关状态以及调用完函数
p
r
i
n
t
f
printf
printf之后的返回地址不会入栈,因为这里
s
u
b
_
r
o
u
t
i
n
e
2
sub\_routine2
sub_routine2函数调用函数
p
r
i
n
t
f
printf
printf就只有一级递归调用了,此时相关的状态会被放到
R
0
−
>
R
12
R0->R12
R0−>R12等通用寄存器中,
p
r
i
n
t
f
printf
printf函数的返回地址会放到
R
14
R14
R14也就是
L
R
LR
LR寄存器中。注意这里的返回地址是调用语句的下一条语句的地址加一,这里可以结合图11和图13来看,以及结合图12和图14来看。从图13中可以知道
m
a
i
n
main
main函数中调用函数
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1语句后面的语句
i
n
d
e
x
+
+
index++
index++语句的指令地址为
0
x
0800077
A
0x0800077A
0x0800077A,图11中此时栈顶指针为
0
x
20000810
0x20000810
0x20000810,也就是图11中最下边的绿色方框最左边的位置,该绿色方框最右边的位置就是
m
a
i
n
main
main函数中调用函数
s
u
b
_
r
o
u
t
i
n
e
1
sub\_routine1
sub_routine1的返回地址,我们可以看到它就是
0
x
0800077
A
+
1
=
0
x
0800077
B
0x0800077A+1=0x0800077B
0x0800077A+1=0x0800077B--------------------------------------------
从图14中可以知道 s u b _ r o u t i n e 1 sub\_routine1 sub_routine1函数中调用函数 s u b _ r o u t i n e 2 sub\_routine2 sub_routine2语句后面的语句 c = a + b c=a+b c=a+b语句的指令地址为 0 x 08000810 0x08000810 0x08000810,图12中此时栈顶指针为 0 x 20000800 0x20000800 0x20000800,也就是图12中最下边的绿色方框最左边的位置,地址 0 x 2000080 C 0x2000080C 0x2000080C开始的四个字节的地址 0 x 08000811 0x08000811 0x08000811就是 s u b _ r o u t i n e 1 sub\_routine1 sub_routine1函数中调用函数 s u b _ r o u t i n e 2 sub\_routine2 sub_routine2的返回地址,我们可以看到它就是 0 x 08000810 + 1 = 0 x 08000811 0x08000810+1=0x08000811 0x08000810+1=0x08000811







C o r t e x _ M Cortex\_M Cortex_M系列芯片调用函数的指令如图16和图17所示。


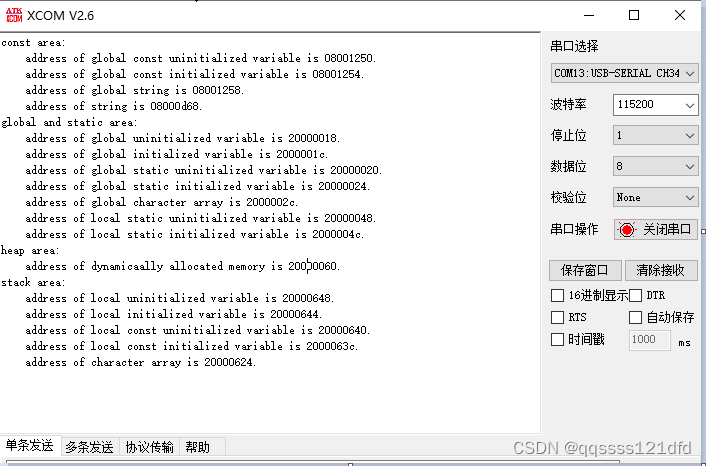
这位兄弟的代码也可以看看。关于以上部分的内容,这位兄弟的代码也非常值得一看,我怕网站内容到时候失效了,所以我把他的内容保存成了 P D F PDF PDF的形式,可以在这里下载。 根据这位哥的文章,我自己在 S T M 32 F 103 Z E T 6 STM32F103ZET6 STM32F103ZET6的芯片上也写了个工程( 工程在这里)测试了以下。代码如下,输出如图18所示。
#include "usart.h"
#include <stdio.h>
#include <stdlib.h>
#include "stm32f10x.h"
u32 global_uninitialized;
u32 global_initialized=35;
static u32 static_uninitialized;
static u32 static_initialized=85;
const u32 const_uninitialized;
const u32 const_initialized=65;
char * global_string="global memory mapping";
char global_char_array[28]="global memory mapping array";
void memory_mapping_test()
{
u32 local_uninitialized;
u32 local_initialized=35;
static u32 local_static_uninitialized;
static u32 local_static_initialized=85;
const u32 local_const_uninitialized;
const u32 local_const_initialized=65;
char * string="memory mapping";
char char_array[21]="memory mapping array";
u32 * u32_pointer=malloc(4);
printf("const area:\r\n");
printf(" address of global const uninitialized variable is %08x.\r\n",&const_uninitialized);
printf(" address of global const initialized variable is %08x.\r\n",&const_initialized);
printf(" address of global string is %08x.\r\n",global_string);
printf(" address of string is %08x.\r\n",string);
printf("global and static area:\r\n");
printf(" address of global uninitialized variable is %08x.\r\n",&global_uninitialized);
printf(" address of global initialized variable is %08x.\r\n",&global_initialized);
printf(" address of global static uninitialized variable is %08x.\r\n",&static_uninitialized);
printf(" address of global static initialized variable is %08x.\r\n",&static_initialized);
printf(" address of global character array is %08x.\r\n",global_char_array);
printf(" address of local static uninitialized variable is %08x.\r\n",&local_static_uninitialized);
printf(" address of local static initialized variable is %08x.\r\n",&local_static_initialized);
printf("heap area:\r\n");
printf(" address of dynamicaally allocated memory is %08x.\r\n",u32_pointer);
printf("stack area:\r\n");
printf(" address of local uninitialized variable is %08x.\r\n",&local_uninitialized);
printf(" address of local initialized variable is %08x.\r\n",&local_initialized);
printf(" address of local const uninitialized variable is %08x.\r\n",&local_const_uninitialized);
printf(" address of local const initialized variable is %08x.\r\n",&local_const_initialized);
printf(" address of character array is %08x.\r\n",char_array);
free(u32_pointer);
}
int main( void )
{
uart_init(115200);
memory_mapping_test();
while(1);
}
















 1914
1914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











