






以前一直以为getline函数读入缓冲区(BUFFER)的一行字符以字符’\0’结束,但是这两天在调试一段程序时发生的一些异常情况加上我查阅相关资料并进行一些测试之后 似乎 验证了这是不对的。下面就简单记录一下。
//这里是测试代码:test.c文件
#include<stdio.h>
#include<stdlib.h>
void main()
{
FILE *fp = NULL;
size_t n = 0;
char * p;
fp=fopen("test.txt", "r");
getline(&p, &n, fp);
printf("%c\n", *(p + 0));
printf("%c\n", *(p + 1));
printf("%c\n", *(p + 2));
printf("%c\n", *(p + 3));
printf("%c\n", *(p + 4));
printf("%c\n", *(p + 5));
printf("%d\n", *(p + 6));
printf("%d\n", *(p + 7));
printf("%d\n", *(p + 8));
printf("%d\n", *(p + 9));
} 以上为这次测试的测试代码,前6个字符以字符形式输出,后4个以十进制有符号数形式输出字符对应的ASCII码。图1所示为我的测试文件,这是一个仅有6个字符的文本文件。
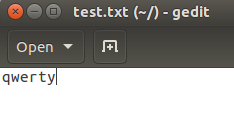
图2所示为我们的测试结果。从图2中我们可以看到文件中的6个字符输出完毕之后接下来输出的并不是0(字符’\0’的ASCII码值为0)而是10(字符’\n’的ASCII码值为10)。10之后才是0,这说明getline()函数读取的一行的结束字符并不是字符’\0’而是字符’\n’和字符’\0’。getline函数的man page 中似乎也提到了这一点。如下所示:
getline() reads an entire line from stream, storing the address of the buffer containing the text into *lineptr. The buffer is null-terminated and includes the newline character, if one was found.
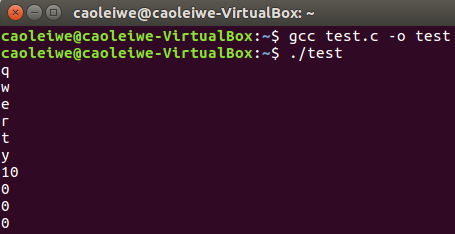
图2中最后输出的两个也是0值,这是否说明getline函数从文件流读入一行字符放入缓冲区后,缓冲区此时没有被用到的字符空间被赋予字符’\0’还有待广大网友赐教。
有关getline函数的详细介绍可以参考该函数的man page 也可以参考一下这篇文章(我大概扫了一眼觉得应该写的可以):
http://blog.csdn.net/zqixiao_09/article/details/50253883
有关输入输出流以及缓冲区的相关内容可以参考以上文章作者写的另一篇文章:http://blog.csdn.net/zqixiao_09/article/details/50234733
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











