转载地址:http://blog.csdn.net/rongyongfeikai2/article/details/40457827
1.数据挖掘与关联分析
数据挖掘是一个比较庞大的领域,它包括数据预处理(清洗去噪)、数据仓库、分类聚类、关联分析等。关联分析可以算是数据挖掘最贴近我们生活的一部分了,打开卓越亚马逊,当挑选一本《Android4高级编程》时,它会不失时机的列出你可能还会感兴趣的书籍,比如Android游戏开发、Cocos2d-x引擎等,让你的购物车又丰富了些,而钱包又空了些。
关联分析,即从一个数据集中发现项之间的隐藏关系。本篇文章Apriori算法主要是基于频繁集的关联分析,所以本文中所出现的关联分析默认都是指基于频繁集的关联分析。
有了一个感性的认识,我们来一段理性的形式化描述:
令项集I={i1,i2,...in}
且有一个数据集合D,它其中的每一条记录T,都是I的子集
那么关联规则都是形如A->B的表达式,A、B均为I的子集,且A与B的交集为空
这条关联规则的支持度:support = P(A并B)
这条关联规则的置信度:confidence = support(A并B)/suport(A)
如果存在一条关联规则,它的支持度和置信度都大于预先定义好的最小支持度与置信度,我们就称它为强关联规则。强关联规则就可以用来了解项之间的隐藏关系。所以关联分析的主要目的就是为了寻找强关联规则,而Apriori算法则主要用来帮助寻找强关联规则。
注意:因为频率=事件出现次数/总事件次数,为了方便,我们在以下都用事件出现的频数而非频率来作为支持度。
2.Apriori算法描述
Apriori算法指导我们,如果要发现强关联规则,就必须先找到频繁集。所谓频繁集,即支持度大于最小支持度的项集。如何得到数据集合D中的所有频繁集呢?
有一个非常土的办法,就是对于数据集D,遍历它的每一条记录T,得到T的所有子集,然后计算每一个子集的支持度,最后的结果再与最小支持度比较。且不论这个数据集D中有多少条记录(十万?百万?),就说每一条记录T的子集个数({1,2,3}的子集有{1},{2},{3},{1,2},{2,3},{1,3},{1,2,3},即如果记录T中含有n项,那么它的子集个数是2^n-1)。计算量非常巨大,自然是不可取的。
所以Aprior算法提出了一个逐层搜索的方法,如何逐层搜索呢?包含两个步骤:
1.自连接获取候选集。第一轮的候选集就是数据集D中的项,而其他轮次的候选集则是由前一轮次频繁集自连接得到(频繁集由候选集剪枝得到)。
2.对于候选集进行剪枝。如何剪枝呢?候选集的每一条记录T,如果它的支持度小于最小支持度,那么就会被剪掉;此外,如果一条记录T,它的子集有不是频繁集的,也会被剪掉。
算法的终止条件是,如果自连接得到的已经不再是频繁集,那么取最后一次得到的频繁集作为结果。
需要值得注意的是:
Apriori算法为了进一步缩小需要计算支持度的候选集大小,减小计算量,所以在取得候选集时就进行了它的子集是否有非频繁集的判断。(参见《数据挖掘:概念与技术》一书)。
另外,两个K项集进行连接的条件是,它们至少有K-1项相同。
知道了这些可以方便我们写出高效的程序。
3.Apriori算法例子推导
上面的描述是不是有点抽象,例子是最能帮助理解的良方。(假设最小支持度为2,最小置信度为0.6,最小支持度和置信度都是人定的,可以根据实验结果的优劣对这两个参数进行调整)
假设初始的数据集D如下:
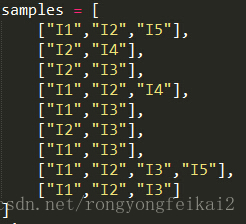
那么第一轮候选集和剪枝的结果为:
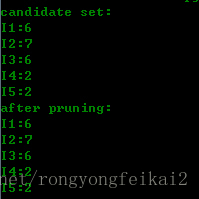
可以看到,第一轮时,其实就是用的数据集中的项。而因为最小支持度是2的缘故,所以没有被剪枝的,所以得到的频繁集就与候选集相同。
第二轮的候选集与剪枝结果为:
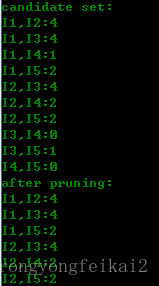
可以看到,第二轮的候选集就是第一轮的频繁集自连接得到的(进行了去重),然后根据数据集D计算得到支持度,与最小支持度比较,过滤了一些记录。频繁集已经与候选集不同了。
第三轮候选集与频繁集结果为:
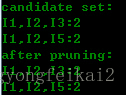
可以看到,第三轮的候选集发生了明显的缩小,这是为什么呢?
请注意取候选集的两个条件:
1.两个K项集能够连接的两个条件是,它们有K-1项是相同的。所以,(I2,I4)和(I3,I5)这种是不能够进行连接的。缩小了候选集。
2.如果一个项集是频繁集,那么它不存在不是子集的频繁集。比如(I1,I2)和(I1,I4)得到(I1,I2,I4),而(I1,I2,I4)存在子集(I1,I4)不是频繁集。缩小了候选集。
第三轮得到的2个候选集,正好支持度等于最小支持度。所以,都算入频繁集。
这时再看第四轮的候选集与频繁集结果:
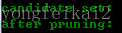
可以看到,候选集和频繁集居然为空了!因为通过第三轮得到的频繁集自连接得到{I1,I2,I3,I5},它拥有子集{I2,I3,I5},而{I2,I3,I5}不是频繁集,不满足:频繁集的子集也是频繁集这一条件,所以被剪枝剪掉了。所以整个算法终止,取最后一次计算得到的频繁集作为最终的频繁集结果:
也就是:['I1,I2,I3', 'I1,I2,I5']
那么,如何得到强规则呢?
比如对于:I1,I2,I3这个频繁集,我们可以得到它的子集:{I1},{I2},{I3},{I1,I2},{I1,I3},{I2,I3},那么可以得到的规则如下:
I1->I3^I2 0.333333333333
I2->I1^I3 0.285714285714
I3->I1^I2 0.333333333333
I1^I2->I3 0.5
I1^I3->I2 0.5
I2^I3->I1 0.5
左边是规则,右边是置信度。conf(I1->I3^I2) = support(I1,I2,I3)/support(I1)
与最小置信度相比较,我们就可以得到强规则了。
所以对于频繁集['I1,I2,I3', 'I1,I2,I5']
我们得到的规则为:
I1->I3^I2 0.333333333333
I2->I1^I3 0.285714285714
I3->I1^I2 0.333333333333
I1^I2->I3 0.5
I1^I3->I2 0.5
I2^I3->I1 0.5
I1->I2^I5 0.333333333333
I2->I1^I5 0.285714285714
I5->I1^I2 1.0
I1^I2->I5 0.5
I1^I5->I2 1.0
I2^I5->I1 1.0
从而得到强规则为:
I5->I1^I2 : 1.0
I1^I5->I2 : 1.0
I2^I5->I1 : 1.0
意味着如果用户买了商品I5,则极有可能买商品I1,I2;买了I1和I5,则极有可能买I2,如果买了I2,I5,则极有可能买I1。所以,你就知道在页面上该如何推荐了。
4.Apriori算法源码及输出
为了加强对于Apriori算法的了解,我用Python写了个简单的程序(时间仓促,没有考虑时间空间复杂度,也没有非常严谨的测试正确性),希望以后能对此程序进行修改和优化。
算法源码如下:
-
- samples = [
- ["I1","I2","I5"],
- ["I2","I4"],
- ["I2","I3"],
- ["I1","I2","I4"],
- ["I1","I3"],
- ["I2","I3"],
- ["I1","I3"],
- ["I1","I2","I3","I5"],
- ["I1","I2","I3"]
- ]
- min_support = 2
- min_confidence = 0.6
- fre_list = list()
- def get_c1():
- global record_list
- global record_dict
- new_dict = dict()
- for row in samples:
- for item in row:
- if item not in fre_list:
- fre_list.append(item)
- new_dict[item] = 1
- else:
- new_dict[item] = new_dict[item] + 1
- fre_list.sort()
- print "candidate set:"
- print_dict(new_dict)
- for key in fre_list:
- if new_dict[key] < min_support:
- del new_dict[key]
- print "after pruning:"
- print_dict(new_dict)
- record_list = fre_list
- record_dict = record_dict
- def get_candidateset():
- new_list = list()
-
- for i in range(0,len(fre_list)):
- for j in range(0,len(fre_list)):
- if i == j:
- continue
-
- if has_samesubitem(fre_list[i],fre_list[j]):
- curitem = fre_list[i] + ',' + fre_list[j]
- curitem = curitem.split(",")
- curitem = list(set(curitem))
- curitem.sort()
- curitem = ','.join(curitem)
-
- if has_infresubset(curitem) == False and already_constains(curitem,new_list) == False:
- new_list.append(curitem)
- new_list.sort()
- return new_list
- def has_samesubitem(str1,str2):
- str1s = str1.split(",")
- str2s = str2.split(",")
- if len(str1s) != len(str2s):
- return False
- nums = 0
- for items in str1s:
- if items in str2s:
- nums += 1
- str2s.remove(items)
- if nums == len(str1s) - 1:
- return True
- else:
- return False
- def judge(candidatelist):
-
- new_dict = dict()
- for item in candidatelist:
- new_dict[item] = get_support(item)
- print "candidate set:"
- print_dict(new_dict)
-
-
- new_list = list()
- for item in candidatelist:
- if new_dict[item] < min_support:
- del new_dict[item]
- continue
- else:
- new_list.append(item)
- global fre_list
- fre_list = new_list
- print "after pruning:"
- print_dict(new_dict)
- return new_dict
- def has_infresubset(item):
-
- subset_list = get_subset(item.split(","))
- for item_list in subset_list:
- if already_constains(item_list,fre_list) == False:
- return True
- return False
- def get_support(item,splitetag=True):
- if splitetag:
- items = item.split(",")
- else:
- items = item.split("^")
- support = 0
- for row in samples:
- tag = True
- for curitem in items:
- if curitem not in row:
- tag = False
- continue
- if tag:
- support += 1
- return support
- def get_fullpermutation(arr):
- if len(arr) == 1:
- return [arr]
- else:
- newlist = list()
- for i in range(0,len(arr)):
- sublist = get_fullpermutation(arr[0:i]+arr[i+1:len(arr)])
- for item in sublist:
- curlist = list()
- curlist.append(arr[i])
- curlist.extend(item)
- newlist.append(curlist)
- return newlist
- def get_subset(arr):
- newlist = list()
- for i in range(0,len(arr)):
- arr1 = arr[0:i]+arr[i+1:len(arr)]
- newlist1 = get_fullpermutation(arr1)
- for newlist_item in newlist1:
- newlist.append(newlist_item)
- newlist.sort()
- newlist = remove_dumplicate(newlist)
- return newlist
- def remove_dumplicate(arr):
- newlist = list()
- for i in range(0,len(arr)):
- if already_constains(arr[i],newlist) == False:
- newlist.append(arr[i])
- return newlist
- def already_constains(item,curlist):
- import types
- items = list()
- if type(item) is types.StringType:
- items = item.split(",")
- else:
- items = item
- for i in range(0,len(curlist)):
- curitems = list()
- if type(curlist[i]) is types.StringType:
- curitems = curlist[i].split(",")
- else:
- curitems = curlist[i]
- if len(set(items)) == len(curitems) and len(list(set(items).difference(set(curitems)))) == 0:
- return True
- return False
- def print_dict(curdict):
- keys = curdict.keys()
- keys.sort()
- for curkey in keys:
- print "%s:%s"%(curkey,curdict[curkey])
-
- def get_all_subset(arr):
- rtn = list()
- while True:
- subset_list = get_subset(arr)
- stop = False
- for subset_item_list in subset_list:
- if len(subset_item_list) == 1:
- stop = True
- rtn.append(subset_item_list)
- if stop:
- break
- return rtn
- def get_all_subset(s):
- from itertools import combinations
- return sum(map(lambda r: list(combinations(s, r)), range(1, len(s)+1)), [])
- def cal_associative_rule(frelist):
- rule_list = list()
- rule_dict = dict()
- for fre_item in frelist:
- fre_items = fre_item.split(",")
- subitem_list = get_all_subset(fre_items)
- for subitem in subitem_list:
-
- if len(subitem) == len(fre_items):
- continue
- else:
- difference = set(fre_items).difference(subitem)
- rule_list.append("^".join(subitem)+"->"+"^".join(difference))
- print "The rule is:"
- for rule in rule_list:
- conf = cal_rule_confidency(rule)
- print rule,conf
- if conf >= min_confidence:
- rule_dict[rule] = conf
- print "The associative rule is:"
- for key in rule_list:
- if key in rule_dict.keys():
- print key,":",rule_dict[key]
- def cal_rule_confidency(rule):
- rules = rule.split("->")
- support1 = get_support("^".join(rules),False)
- support2 = get_support(rules[0],False)
- if support2 == 0:
- return 0
- rule_confidency = float(support1)/float(support2)
- return rule_confidency
- if __name__ == '__main__':
- record_list = list()
- record_dict = dict()
- get_c1()
-
-
- while True:
- record_list = fre_list
- new_list = get_candidateset()
- judge_dict = judge(new_list)
- if len(judge_dict) == 0:
- break
- else:
- record_dict = judge_dict
- print "The final frequency set is:"
- print record_list
-
-
- cal_associative_rule(record_list)
算法的输出如下:
- candidate set:
- I1:6
- I2:7
- I3:6
- I4:2
- I5:2
- after pruning:
- I1:6
- I2:7
- I3:6
- I4:2
- I5:2
- candidate set:
- I1,I2:4
- I1,I3:4
- I1,I4:1
- I1,I5:2
- I2,I3:4
- I2,I4:2
- I2,I5:2
- I3,I4:0
- I3,I5:1
- I4,I5:0
- after pruning:
- I1,I2:4
- I1,I3:4
- I1,I5:2
- I2,I3:4
- I2,I4:2
- I2,I5:2
- candidate set:
- I1,I2,I3:2
- I1,I2,I5:2
- after pruning:
- I1,I2,I3:2
- I1,I2,I5:2
- candidate set:
- after pruning:
- The final frequency set is:
- ['I1,I2,I3', 'I1,I2,I5']
- The rule is:
- I1->I3^I2 0.333333333333
- I2->I1^I3 0.285714285714
- I3->I1^I2 0.333333333333
- I1^I2->I3 0.5
- I1^I3->I2 0.5
- I2^I3->I1 0.5
- I1->I2^I5 0.333333333333
- I2->I1^I5 0.285714285714
- I5->I1^I2 1.0
- I1^I2->I5 0.5
- I1^I5->I2 1.0
- I2^I5->I1 1.0
- The associative rule is:
- I5->I1^I2 : 1.0
- I1^I5->I2 : 1.0
- I2^I5->I1 : 1.0






















 3945
3945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









