







 超级会员免费看
超级会员免费看
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/130983835
GitHub 源码: https://github.com/SpikeKing/Reinforcement-Learning-Algorithm
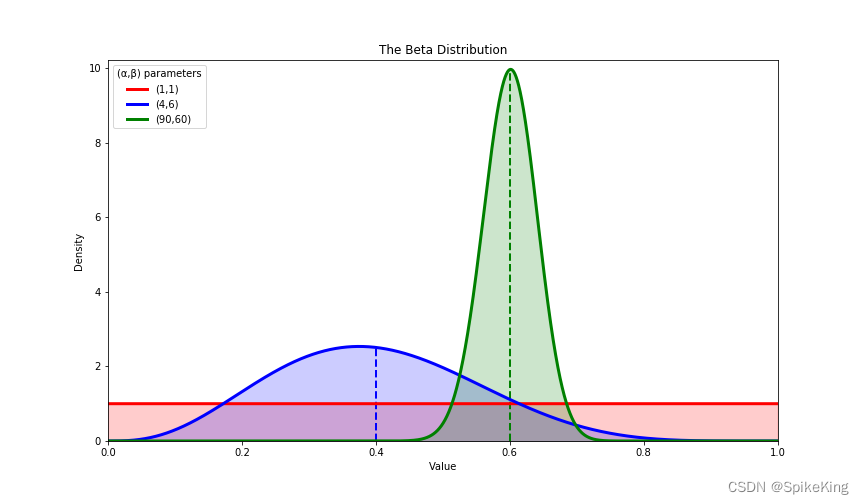
上置信界算法和汤普森采样算法是两种解决多臂老虎机问题的经典方法。多臂老虎机问题是一种探索与利用的平衡问题,即在有限的尝试次数内,如何选择最优的动作(拉动哪根拉杆)来最大化累积奖励。上置信界算法是一种基于置信区间的方法,根据每个动作的期望奖励和不确定性来计算一个上界,然后选择上界最大的动作。汤普森采样算法是一种基于贝叶斯推断的方法,根据每个动作的先验分布和观测数据来

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 5675
5675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











