







PRML Chapter 07 Sparse Kernel Machines
第六章提到的核函数和核方法,有一个显著的问题,即核函数 k ( x n , x m ) k(x_n,x_m) k(xn,xm)必须对所有的数据点都进行求值,这对于训练阶段是不可接受的,对于预测阶段,同样也是不可以接受的。因此,我们可以考虑使用稀疏核机(Sparse kernel machines),这种方法的一个典型特征是训练得到的模型仅仅依赖于少数几个数据点(也称支持向量),因此被叫做稀疏核机。
Support vector machine
支持向量机(Support vector machine)是一种典型的稀疏核机。考虑数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
m
,
y
m
)
}
D=\{ (x_1,y_1),(x_2,y_2),...,(x_m,y_m) \}
D={(x1,y1),(x2,y2),...,(xm,ym)},
y
i
∈
{
−
1
,
1
}
y_i \in \{ -1, 1 \}
yi∈{−1,1}。分类学习最基本的想法就是基于训练集
D
D
D在样本空间中找到一个划分超平面,将不同类别的样本尽量区分开来,但这样的超平面通常很多,支持向量机通过最大间隔(margin)的方法选出最优超平面。
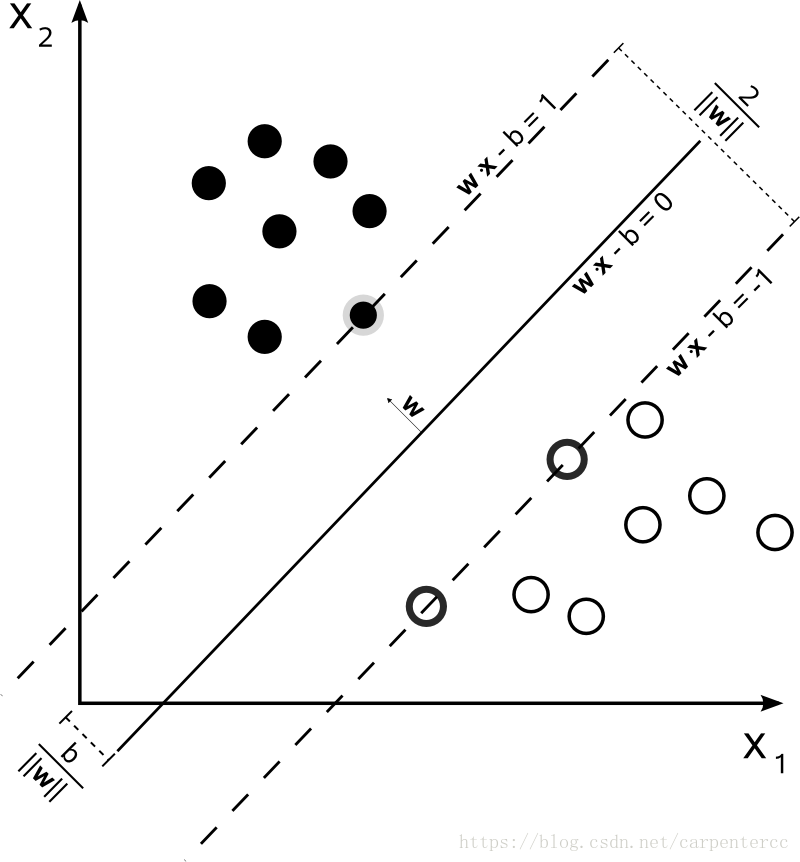
现在,考虑超平面 ω T x + b = 0 \boldsymbol{\omega}^T\boldsymbol{x}+b=0 ωTx+b=0能够将所有的数据点都正确的分类,如上图所示。可以看到,距离超平面最近的这几个训练样本点使得式(7.1)成立,
(7.1) { ω T x i + b ≥ + 1 , y i = + 1 ω T x i + b ≤ − 1 , y i = − 1 \begin{cases} \boldsymbol{\omega}^T\boldsymbol{x}_i+b \geq +1, y_i = +1 \\ \boldsymbol{\omega}^T\boldsymbol{x}_i+b \leq -1, y_i = -1 \end{cases} \tag{7.1} {ωTxi+b≥+1,yi=+1ωTxi+b≤−1,yi=−1(7.1)
因此,他们被称为支持向量(support vector),两个异类支持向量到超平面的距离之和为,
(7.2) γ = 2 ∣ ∣ ω ∣ ∣ \gamma = \frac{2}{||\boldsymbol{\omega}||} \tag{7.2} γ=∣∣ω∣∣2(7.2)
式(7.2)被称为间隔,欲找到最大间隔(maximum margin)的划分超平面,也就是要找到能满足式(7.1)中约束的参数 ω , b \boldsymbol{\omega},b ω,b,使得式(7.2)中的 γ \gamma γ最大,即,
(7.3) max ω , b 2 ∣ ∣ ω ∣ ∣ s . t . y i ( ω T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \max_{\boldsymbol{\omega},b} \frac{2}{||\boldsymbol{\omega}||} \\\tag{7.3} s.t. y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b) \geq 1, i=1,2,...,m ω,bmax∣∣ω∣∣2s.t.yi(ωTxi+b)≥1,i=1,2,...,m(7.3)
式(7.3)等价于
(7.4) max ω , b 1 2 ∣ ∣ ω ∣ ∣ 2 s . t . y i ( ω T x i + b ) ≥ 1 , i = 1 , 2 , . . . , m \max_{\boldsymbol{\omega},b} \frac{1}{2}||\boldsymbol{\omega}||^2 \\ \tag{7.4} s.t. y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b) \geq 1, i=1,2,...,m ω,bmax21∣∣ω∣∣2s.t.yi(ωTxi+b)≥1,i=1,2,...,m(7.4)
由于式(7.4)本身就是一个凸二次规划问题,因此可以直接用现成的优化算法计算其最优解,但通常使用其对偶形式,更加高效的进行计算。考虑使用拉格朗日乘子 α i ≥ 0 \alpha_i \geq 0 αi≥0,其对偶形式可以写为,
(7.5) max α ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j s . t . ∑ i = 1 m α i y i = 0 α i ≥ 0 , i = 1 , 2 , . . , m \max_{\boldsymbol{\alpha} } \sum_{i=1}^m \alpha_i - \frac{1}{2}\sum_{i=1}^m\sum_{j=1}^m \alpha_i \alpha_j y_i y_j \boldsymbol{x}_i^T\boldsymbol{x}_j \\ s.t. \sum_{i=1}^m\alpha_iy_i = 0 \\ \alpha_i \geq 0, i = 1,2,..,m \tag{7.5} αmaxi=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxjs.t.i=1∑mαiyi=0αi≥0,i=1,2,..,m(7.5)
一般来说,使用SMO(sequential Minimal Optimization)对其进行高效的求解。上述关于SVM的讨论都假设数据点线性可分,但是实际中往往会有类别重叠的情况发生,因此,我们可以引入软间隔(soft margin)的概念,使得一个数据点可以不满足约束,
(7.6) y i ( ω T x i + b ) ≥ 1 y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b) \geq 1 \tag{7.6} yi(ωTxi+b)≥1(7.6)
从而,优化目标可以变为,
(7.7) min ω , b 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 m L ( y i ( ω T x i + b ) − 1 ) \min_{\boldsymbol{\omega},b} \frac{1}{2}||\boldsymbol{\omega}||^2 + C\sum_{i=1}^m L(y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b) - 1) \tag{7.7} ω,bmin21∣∣ω∣∣2+Ci=1∑mL(yi(ωTxi+b)−1)(7.7)
其中, L L L是损失函数, C C C则作为惩罚参数,当其趋近于无穷大时,迫使所有样本都满足式(7.6),当其为有限值时,式(7.7)允许一些样本不满足约束。引入松弛变量(slack variables)代替损失函数,则软间隔支持向量机可以表示为,
(7.8) min ω , b , ξ i 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 m ξ i s . t . y i ( ω T x i + b ) ≥ 1 − ξ i ξ i ≥ 0 , i = 1 , 2 , . . . , m \min_{\boldsymbol{\omega},b,\xi_i} \frac{1}{2}||\boldsymbol{\omega}||^2 + C\sum_{i=1}^m \xi_i \\ s.t. y_i(\boldsymbol{\omega}^T\boldsymbol{x}_i+b) \geq 1-\xi_i \\ \xi_i \geq 0, i = 1, 2, ..., m \tag{7.8} ω,b,ξimin21∣∣ω∣∣2+Ci=1∑mξis.t.yi(ωTxi+b)≥1−ξiξi≥0,i=1,2,...,m(7.8)
Support vector regression
支持向量回归(Support vector regression),是一种利用支持向量进行回归预测的方法。考虑我们需要拟合的函数为,
(7.9) f ( x ) = ω T ϕ ( x ) f(\boldsymbol{x}) = \boldsymbol{\omega}^T\phi(\boldsymbol{x}) \tag{7.9} f(x)=ωTϕ(x)(7.9)
则,支持向量回归希望能够找到 f ( x ) f(\boldsymbol{x}) f(x),其与真实值 y y y的偏差为 ϵ \epsilon ϵ。这显然可以看作是以 f ( x ) f(\boldsymbol{x}) f(x)为中心,构建一个宽度为 2 ϵ 2\epsilon 2ϵ的间隔带,若数据点落入此间隔带,则认为被预测正确,因此,其具体形式可以表示为,
(7.10) min ω , b 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 m L ϵ ( f ( x ) − y i ) \min_{\boldsymbol{\omega},b} \frac{1}{2}||\boldsymbol{\omega}||^2 + C \sum_{i=1}^mL_{\epsilon}(f(\boldsymbol{x})-y_i) \tag{7.10} ω,bmin21∣∣ω∣∣2+Ci=1∑mLϵ(f(x)−yi)(7.10)
引入松弛变量 ξ i , ξ i ^ \xi_i,\hat{\xi_i} ξi,ξi^,可以将上式重写为,
(7.11) min ω , b , ξ i , ξ i ^ 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 m ( ξ i + ξ i ^ ) s . t . f ( x ) − y i ≤ ϵ + ξ i y i − f ( x ) ≤ ϵ + ξ i ^ ξ i ≥ 0 , ξ i ^ ≥ 0 , i = 1 , 2 , . . . , m \min_{\boldsymbol{\omega},b,\xi_i,\hat{\xi_i}} \frac{1}{2}||\boldsymbol{\omega}||^2+C\sum_{i=1}^m(\xi_i+\hat{\xi_i}) \\ s.t. f(\boldsymbol{x})-y_i \leq \epsilon + \xi_i \\ y_i-f(\boldsymbol{x}) \leq \epsilon + \hat{\xi_i} \\ \xi_i \geq 0, \hat{\xi_i} \geq 0, i=1,2,...,m \tag{7.11} ω,b,ξi,ξi^min21∣∣ω∣∣2+Ci=1∑m(ξi+ξi^)s.t.f(x)−yi≤ϵ+ξiyi−f(x)≤ϵ+ξi^ξi≥0,ξi^≥0,i=1,2,...,m(7.11)














 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









