







文法类型判断C++实现
编译环境:vc6 + win7 64位
源代码:
<span style="font-size:14px;">#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <string>
#include <vector>
#include <set>
#include <algorithm>
#include <cassert>
using namespace std;
const int STRING_MAX_LENGTH = 10;
#ifdef WIN32
#pragma warning (disable: 4514 4786)
#endif
/*
** 一条规则
*/
struct Principle {
string left;
string right;
Principle(const char *l, const char *r) : left(l), right(r) {}
};
/*
** 文法的四元组形式,同时将该文法类型也作为其属性
*/
struct Grammer {
set<char> Vn;
set<char> Vt;
vector<Principle> P;
char S;
int flag; // 文法类型
Grammer(void) : flag(-1) {}
};
/*
** 输入规则
*/
void input(vector<Principle> &principleSet) {
char left[STRING_MAX_LENGTH];
char right[STRING_MAX_LENGTH];
while (EOF != scanf("%[^-]->%s", left, right)) {
getchar();
principleSet.push_back(Principle(left, right));
}
}
/*
** 判断字符串(文法的左部)中是否存在一个非终结符。
*/
bool hasUpper(string s) {
return s.end() != find_if(s.begin(), s.end(), isupper);
}
/*
** 判断文法类型。
*/
void check(int &flag, const Principle &prcp)
{
switch (flag) {
case 3:
if (
1 == prcp.left.size() && isupper(prcp.left[0]) &&
(1 == prcp.right.size() && !isupper(prcp.right[0]) ||
2 == prcp.right.size() && !isupper(prcp.right[0]) && isupper(prcp.right[1]))
) {
break;
}
case 2:
if (1 == prcp.left.size() && isupper(prcp.left[0])) {
flag = 2;
break;
}
case 1:
if (hasUpper(prcp.left) && prcp.left.size() <= prcp.right.size()) {
flag = 1;
break;
}
default:
// 所有的文法规则左部都必须至少含有一个非终结符,是否应放到最前面判断
try {
if (!hasUpper(prcp.left)) {
throw exception("输入的文法错误!");
}
} catch (exception e) {
cout << e.what() << endl;
exit(-1);
}
flag = 0;
break;
}
}
/*
** 得到S, Vn, Vt
*/
void getGrammer(Grammer &G) {
G.S = G.P[0].left[0];
G.Vn.clear();
G.Vt.clear();
for (unsigned i = 0; i < G.P.size(); ++i) {
const Principle &prcp = G.P[i];
for (unsigned j = 0; j < prcp.left.size(); ++j) {
char v = prcp.left[j];
!isupper(v) ? G.Vt.insert(v) : G.Vn.insert(v);
}
for (unsigned k = 0; k < prcp.right.size(); ++k) {
char v = prcp.right[k];
!isupper(v) ? G.Vt.insert(v) : G.Vn.insert(v);
}
}
}
/*
** 判别文法并生成四元组形式。
*/
void solve(Grammer &G) {
G.flag = 3; // 从正则文法开始判断
for (unsigned i = 0; i < G.P.size(); ++i) {
check(G.flag, G.P[i]);
}
getGrammer(G);
}
/*
** 输出文法
*/
void output(Grammer &G) {
cout << "G = (Vn, Vt, P, S)是" << G.flag << "型文法\n" << endl;
set<char>::iterator ite;
cout << "Vn:" << endl;
for(ite = G.Vn.begin(); ite != G.Vn.end(); ++ite) {
cout << *ite << endl;
}
cout << endl;
cout << "Vt:" << endl;
for (ite = G.Vt.begin(); ite != G.Vt.end(); ++ite) {
cout << *ite << endl;
}
cout << endl;
vector<Principle>::iterator iter = G.P.begin();
cout << "P:" << endl;
for (; iter != G.P.end(); ++iter) {
cout << (*iter).left << "->" << (*iter).right << endl;
}
cout << endl;
cout << "S:\n" << G.S << endl;
};
int main()
{
vector<int> ivec(1,2);
Grammer G;
input(G.P);
solve(G);
output(G);
return 0;
}</span>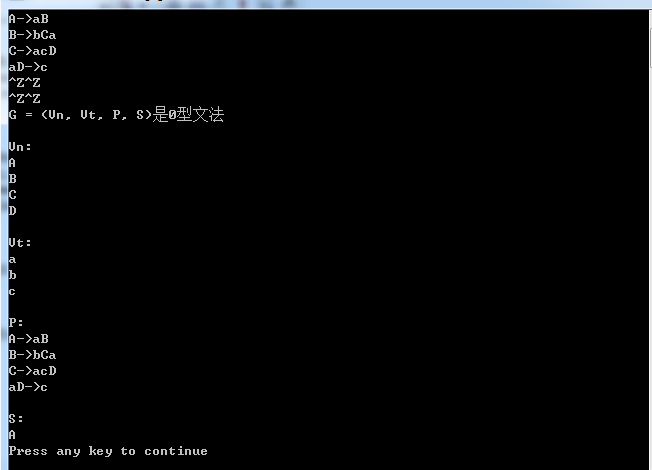
参考:
百度文库
http://blog.csdn.net/Justme0
参考作者的代码在vc6上运行会出现错误,这里修改了错误,逻辑上的思想还是作者的。最大的优点在于在判断文法类型的处理上比较简洁(相比较于我看到的其他的相关代码,例如使用多个if语句依次判断所有情况),比如有一条规则是二型的,接下来的规则会在此基础上进行判断(代码中使用一个标记来记录:flag)。节省了判断的时间。首先检测3型也具有优势,因为我们使用的计算机语言大多属于三型的。















 2434
2434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









