








ICML2019: Transferability vs. Discriminability: Batch Spectral Penalization for Adversarial Domain Adaptation
引言
对抗学习在domain adaptation中常用于adapt源域和目标域特征的分布差异性。 但是在使用对抗学习时,是否会影响到分类效果呢,即我们学到的特征是否依然能保证可区分性(discriminability)?同时对抗学习是如何提高可迁移性(transferability)的呢?本文对这两个问题就行了探讨。
- 可迁移性(transferability):将源域中学到的模型迁移到目标域的能力;
- 可区分性(discriminability):提取的特征能够被分类器分类的能力。
对抗领域自适应(Adversarial Domain Adaptation)##
对抗领域自适应可用公式-1表示:
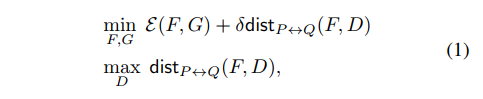
公式-1中F表示特征提取器,G表示分类器,D表示判别器。 minmax损失:对于F,G最小化有监督的损失和dist损失,训练F使得特征做到领域不可区分(表现为减少dist),同时具有可区分性(表现为减少有监督损失)。训练D使得对于F提缺的特征,D能够尽可能的区分(表现为最大化dist)。两个训练过程构成了对抗,迭代进行训练。最终的目的是学到domain-invariant且具有可区分性的特征,从而可以将源域中学到的分类器迁移到目标域。
特征的可区分性
我们使用线性判别分析(Linear Discriminant Analysis, LDA)来探究。 其实就是我们学过的Fisher线性分类器。 大概回顾下:LDA本质上就是将高维的特征映射到映射到一个空间,样本在该空间中有最大的类间距离和最小的类内距离,这样我们就可以找到一个分割面作分类。
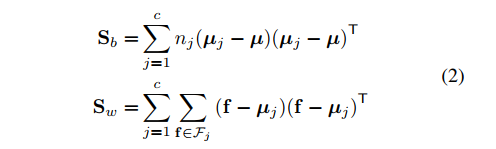
Sb和Sw是协方差矩阵,分别表示类间方差(Between class variance)和类内方差类内方差(Within class variance)。
我们需要的Fisher线性判别器的优化目标为:
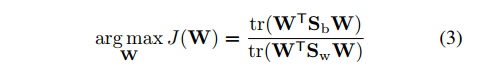
为什么这里要说这个判别器呢?主要是想利用
max
J
(
w
)
\max J(w)
maxJ(w)这个值来衡量可区分性。 直观的看,这个值越大,意味着我们能够区分类别的能力越强。
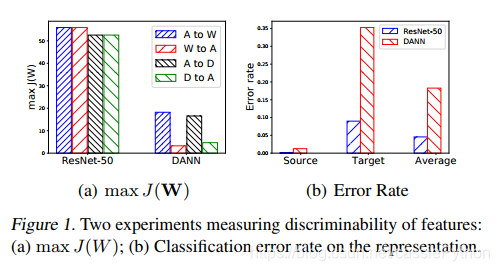
在上图(a)中,对比了ResNet-50(在ImageNet上预训练)和DANN(Domain-adversarial training of neural networks,JMLR2016)。DANN同样使用了ResNet-50的网络结构。 我们发现在Office-31这个数据库上的四个迁移任务中,DANN提取的特征的
max
J
(
w
)
\max J(w)
maxJ(w)值相比ResNet-50都很小,说明DANN提取的特征的可区分性更差,即迁移是以牺牲可区分性为代价的。
进一步的,使用一个多层感知器(MLP)对ResNet-50和DANN提取好的特征进行分类,得到图(b)的结果。可以看出DANN相比于ResNet-50错误率更高,说明了对抗领域迁移降低了特征的可区分性。
我们思考下:
- 为什么DANN提取的特征可区分性差呢?
- 我们如何在加强迁移性能的同时保证可区分性呢?
差的可区分性哪里来?
首先考虑第一个问题。使用奇异值分解(SVD)分别得到源域特征和目标域特征的奇异值和对应的特征向量:
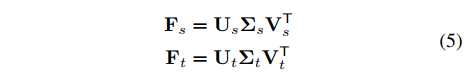
将得到的奇异值画在图上,得到图2-(a):
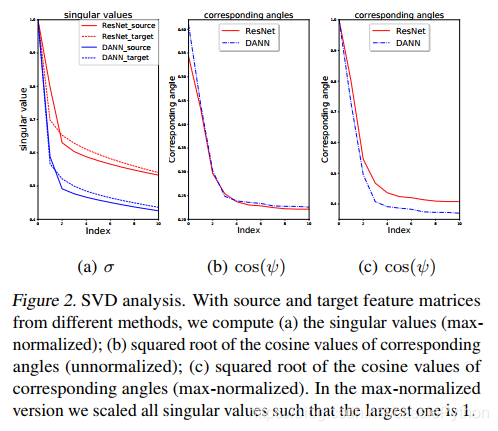
从图2-(a)中可以看出,DANN提取的特征矩阵的最大的奇异值比其它的大很多,曲线下降迅速;而ResNet的曲线平缓很多。 于是可得这种奇异值过大的差异性表征了差的可区分性。(PS. 这里作者考虑了PCA和SVD的奇异值和特征向量的含义,最大的奇异值代表最主要的成分,所以在做domain adaptation时,我们是希望源域和目标域两者的最主要成分相近,然而分类情况是复杂的,它不仅仅依赖于这个最大的奇异值,而是依赖于多个奇异值,但是从图2-(a)中可以明显的看到,domain adaptation对其它较小的奇异值做了过度的“惩罚”,由此影响了可区分性。然而作者的这种假设或者说这种对应关系是否成立呢?对于不同的网络,不同的迁移任务下都是这样吗?)
接下来我们来分析下特征矩阵的每一个主成分的可迁移性。这里要用到Principal Angles(Shonkwiler,2009),一种子空间相似度度量方法(余弦相似度)。
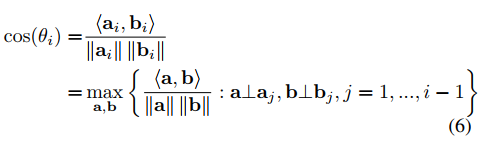
其中
a
i
\textbf{a}_i
ai表示源域特征矩阵的特征向量,
b
i
\textbf{b}_i
bi表示目标域矩阵的特征向量。然而我们在利用Mohammadi(Principal angles between subspaces and reduced order
modelling accuracy in optimization)来优化特征向量得到最小距离时,并没有成对的考虑奇异值对应的特征向量。然而在分类中,不同的特征有着不同的类别含义,如果不成对考量的话是没有意义的,因此作者提出了Corresponding Angle方法:

利用对应位置的特征值对应的特征向量来进行计算cosine角度,其中Usi表示源域特征矩阵中第i大的特征值对应的特征向量。图2-(b)©展示了top-10源域特征向量和目标域特征向量对应的角度。我们可以发现
cos
(
ψ
1
)
\cos(\psi_1)
cos(ψ1)比其它的要大得多,这说明最大的奇异值对应的特征向量在domain adaptation中起着主导作用。对于DANN,相比于ResNet-50变化曲线陡峭很多,说明DANN对于最大的奇异值对应的特征向量依赖性更强。
如此我们得到了DANN的差的可区性的原因:只有最大的奇异值对应的特征向量趋向于携带迁移的信息,其它的特征向量也可能存在domain variations,因此被过度惩罚了。这些特征向量中存在的可区分性的信息由于domain adaptation发生了丢失。
方法
在领域自适应(domain adaptation)中可迁移性和可区分性对于学得好的特征是同等重要的。如果解决上面提出的问题呢?解决思路有两方面:
- 较大的奇异值对应的特征向量对于迁移性更具有代表性,我们要充分利用这点增强迁移性;
- 相对较小的奇异值对应的特征向量对于可区分性是十分重要的,我们要充分利用这点增强可区分性。
Batch Spectral Penalization
根据前面的分析,分类器应该依赖于多个奇异值对应的特征向量,而不仅仅是大的奇异值对应的特征向量。由此我们需要对大的奇异值对应的特征向量进行惩罚,让其不要鹤立鸡群。方法如下:
- 首先对源域特征矩阵 F s F_s Fs和目标域特征矩阵 F t F_t Ft使用SVD,得到k个最大的奇异值;
- 提出Batch Spectral Penalization (BSP)这个正则项对这k个最大的奇异值做惩罚:
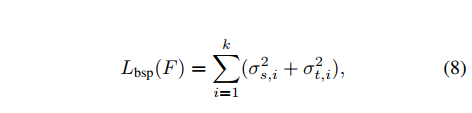
在实际使用时,对每个Batch进行该BSP约束即可。
这里有个疑问,为什么不组合起来 F s F_s Fs和 F t F_t Ft,得到矩阵 F = [ F s , F t ] F=[F_s,F_t] F=[Fs,Ft],然后对矩阵F的奇异值进行BSP的约束呢?由于源域和目标域的差异性,对F得到的奇异值可能无法同时很好的表征源域和目标域,造成潜在的distortion。因此这里分别对源域和目标域的的特征矩阵的奇异值进行约束。
计算复杂度:对于一个m*n的矩阵,SVD的计算复杂度为 O ( m 2 n , m n 2 ) O(m^2n,mn^2) O(m2n,mn2)。对于Batch Spectral Penalization的计算复杂度为 O ( b 2 d ) O(b^2d) O(b2d),其中b表示batch-size,d表示特征的维度。
使用BSP的模型
将BSP应用到对抗学习中,总的优化目标变为:
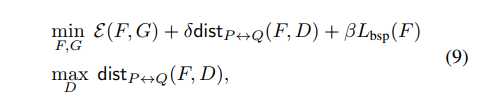
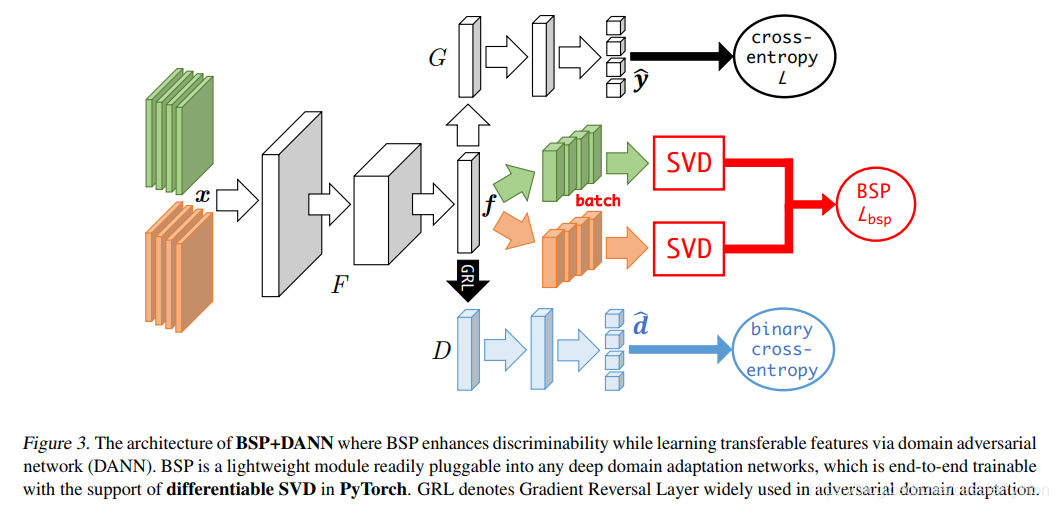
将BSP应用到DANN中,如下图所示:
理论分析
Ben-David等人(2010)对domain adpatation的基础理论进行了研究,从理论上给出了在target domain的误差的bound eT(h)由三部分组成(这个h可以理解为是用来尽可能区分两个分布的函数):
- 源域上的期望误差: ε S ( h ) \varepsilon_S(h) εS(h);
- H Δ H H\Delta H HΔH-distance(是一系列hypotheses的集合);
- 误差 λ \lambda λ
有:
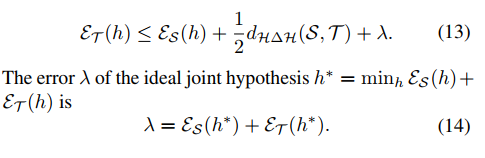
目前的对抗领域迁移实际上是对第三项做了约束(特征不可辨别),从图1-(b)我们看出这样做的误差反而是大的,而使用BSD对第三项进一步做了约束,可以对目标域的error得到一个更lower的bound。由此得到更好的结果(PS. 到底是怎么约束的?)。
代码:
github.com/thuml/Batch-Spectral-Penalization
关于domain adaptation的理论paper:
- A theory of learning from different domains;
- Analysis of Representations for Domain Adaptation


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









