






目录
1.线程池 and 数据库连接池
线程池
#include <iostream>
#include <vector>
#include <queue>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <functional>
class ThreadPool
{
public:
ThreadPool(size_t numThreads) : stop(false)
{
for (size_t i = 0; i < numThreads; ++i)
{
workers.emplace_back([this]
{
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(queueMutex);
condition.wait(lock, [this] { return stop || !tasks.empty(); });
if (stop && tasks.empty()) return;
task = tasks.front();
tasks.pop();
}
//取出任务队列中执行该任务
task();
} });
}
}
template <class F>
void enqueue(F &&f)
{
{
std::unique_lock<std::mutex> lock(queueMutex);
tasks.emplace(std::forward<F>(f));
}
condition.notify_one();
}
~ThreadPool()
{
{
std::unique_lock<std::mutex> lock(queueMutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers)
{
worker.join();
}
}
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
std::mutex queueMutex;
std::condition_variable condition;
bool stop;
};
int main()
{
ThreadPool pool(4);
for (int i = 0; i < 8; ++i)
{
pool.enqueue([i]
{ std::cout << "Task " << i << " executed by thread " << std::this_thread::get_id() << std::endl; });
}
this_thread::sleep_for(chrono::seconds(1));
system("pause");
return 0;
}
说明:
1. **初始化线程池**:在创建线程池对象时,通过构造函数指定线程池中的线程数量。线程池会创建相应数量的工作线程,并启动这些线程等待任务。
2. **添加任务**:通过 `enqueue` 函数向线程池中添加任务。每个任务都是一个可调用对象,可以是函数、lambda 表达式或者其他可调用对象。添加任务时,会将任务移动到任务队列中,并通过条件变量通知等待中的工作线程有新任务可以执行。
3. **工作线程执行任务**:每个工作线程会循环执行以下操作:
- 等待条件变量的通知,一旦有新任务到来或者线程池被停止,就会被唤醒。
- 从任务队列中取出一个任务并执行。如果任务队列为空且线程池未被停止,线程会继续等待新任务的到来。
- 执行完任务后,继续循环等待新任务。
4. **停止线程池**:当需要销毁线程池时,调用析构函数或者手动调用停止函数。停止函数会将停止标志设置为 `true`,并通过条件变量通知所有工作线程线程池即将停止。
工作线程在收到停止通知后会执行完当前任务并退出线程。
5. **资源回收**:在线程池被销毁时,会等待所有工作线程执行完当前任务并回收资源。这包括等待所有工作线程结束并调用 `join` 函数等待线程结束。
数据库连接池
#include <iostream>
#include <queue>
#include <mutex>
#include <condition_variable>
#include <thread>
#include <chrono>
// 模拟数据库连接类
class Connection {
public:
void executeQuery(const std::string& query) {
std::cout << "Executing query: " << query << std::endl;
// 模拟执行查询操作
std::this_thread::sleep_for(std::chrono::seconds(1));
}
};
class ConnectionPool {
private:
std::queue<Connection*> connections;
std::mutex mtx;
std::condition_variable cv;
const int poolSize;
public:
ConnectionPool(int size) : poolSize(size) {
for (int i = 0; i < poolSize; ++i) {
connections.push(new Connection());
}
}
Connection* getConnection() {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [this] { return !connections.empty(); });
Connection* conn = connections.front();
connections.pop();
return conn;
}
void releaseConnection(Connection* conn) {
std::lock_guard<std::mutex> lock(mtx);
connections.push(conn);
cv.notify_one();
}
~ConnectionPool() {
while (!connections.empty()) {
delete connections.front();
connections.pop();
}
}
};
int main() {
ConnectionPool pool(5);
// 从连接池中获取连接并执行查询
Connection* conn1 = pool.getConnection();
conn1->executeQuery("SELECT * FROM table1");
pool.releaseConnection(conn1);
// 可以继续获取连接并执行其他操作
return 0;
}-
Connection类模拟了一个数据库连接,其中有一个executeQuery方法用于执行查询操作。在这个方法中,会输出要执行的查询语句,并通过std::this_thread::sleep_for来模拟查询操作需要的时间。 -
ConnectionPool类是连接池类,其中包含了一个连接队列connections,一个互斥锁mtx用于保护对连接队列的访问,一个条件变量cv用于在连接队列为空时等待新连接的到来,以及连接池的大小poolSize。 -
在
ConnectionPool的构造函数中,会初始化指定数量的连接对象并放入连接队列中。 -
getConnection方法用于从连接池中获取连接。首先会对互斥锁进行加锁,然后通过条件变量等待直到连接队列不为空。一旦有可用连接,就从队列中取出一个连接并返回。 -
releaseConnection方法用于释放连接,将连接放回连接队列中,并通过条件变量通知等待的线程有新的连接可用。 -
在
main函数中,首先创建了一个大小为5的连接池pool。然后从连接池中获取一个连接conn1,执行了一个查询操作,最后通过releaseConnection方法将连接放回连接池中。
这样,通过连接池可以有效地管理数据库连接,避免频繁地创建和销毁连接,提高了数据库操作的效率和性能。
2.生产者,消费者问题
#include <iostream>
#include <thread>
#include <vector>
#include <queue>
#include <mutex>
#include <condition_variable>
using namespace std;
#define PRODUCT_SIZE 2
#define CUSTUM_SIZE 2
#define POOL_SIZE 3
mutex m;
condition_variable cv;
queue<int> que;
int num = 0;
//生产者线程。
void producter()
{
while (true)
{
std::unique_lock<std::mutex> lck(m);
while (que.size() >= POOL_SIZE)
{
cv.wait(lck);
}
int data = num++;
que.push(data);
cout << this_thread::get_id() << "produce " << data << endl;
cv.notify_all();
}
}
void customer()
{
while (true)
{
std::unique_lock<std::mutex> lck(m);
while (que.empty())
{
cv.wait(lck);
}
cout << this_thread::get_id() << "consume " << que.front() << endl;
que.pop();
cv.notify_all();
}
}
int main()
{
vector<thread> pools;
//将生产者线程加入线程容器中。
for (int i = 0; i < PRODUCT_SIZE; i++)
{
pools.push_back(thread(producter));
}
//将消费者线程加入线程容器中。
for (int j = 0; j < CUSTUM_SIZE; j++)
{
pools.push_back(thread(customer));
}
//等待线程池中,所有线程都执行完毕。
for (int i = 0; i < PRODUCT_SIZE + CUSTUM_SIZE; i++)
{
pools[i].join();
}
cin.get();
return 0;
}3.排序算法
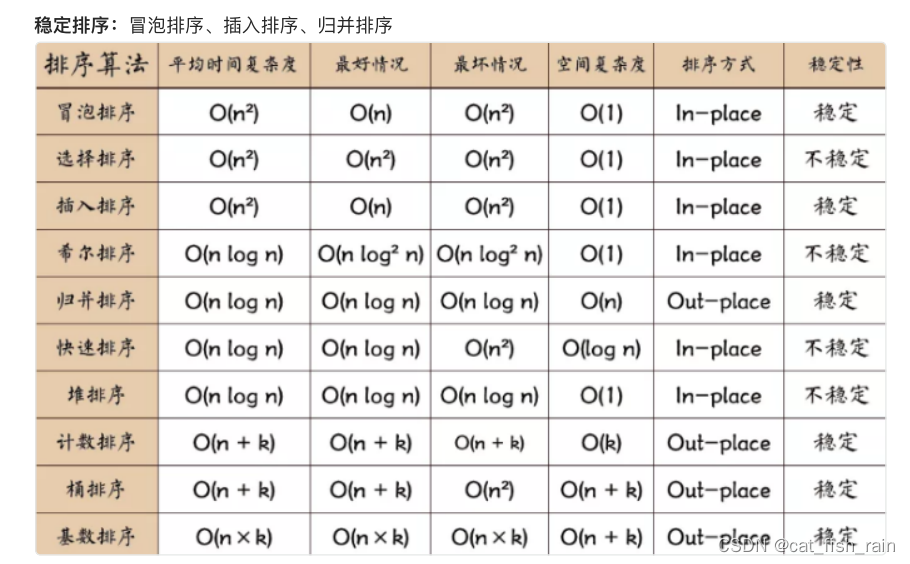
冒泡排序:N个数需要进⾏N-1次冒泡,每次冒泡确定⼀个最⼤值位置。元素交换次数为原数组逆序度。
void bubbleSort(std::vector<int> &nums, int n)
{
for (int i = 1; i < n; ++i)
{ // 冒泡次数
bool is_swap = false;
for (int j = 1; j < n - i + 1; ++j)
{
if (nums[j] < nums[j - 1])
{
std::swap(nums[j], nums[j - 1]);
is_swap = true;
}
}
if (!is_swap)
break;
}
}void insertSort(std::vector<int> &nums, int n)
{
for (int i = 1; i < n; ++i)
{
for (int j = i; j > 0 && nums[j] < nums[j - 1]; --j)
{
std::swap(nums[j], nums[j - 1]);
}
}
}
void selectSort(std::vector<int> &nums, int n)
{
for (int i = 0; i < n - 1; ++i)
{
int k = i;
for (int j = i + 1; j < n; ++j)
{
if (nums[j] < nums[k])
{
k = j;
}
}
std::swap(nums[k], nums[i]);
}
}int partition(vector<int> &v, int low, int high)
{
int pivot = v[high];
int index = low;
for (int i = low; i < high; i++)
{
if (v[i] < pivot)
{
swap(v[index++], v[i]);
}
}
swap(v[index], v[high]);
return index;
}
void quickSort(vector<int> &v, int low, int high)
{
if (low < high)
{
int index = partition(v, low, high);
quickSort(v, low, index - 1);
quickSort(v, index + 1, high);
}
}
int main()
{
vector<int> v = {1, 19, 97, 9, 17, 8};
// vector<int> v = {1, 20, 2, 3, 4, 5};
quickSort(v, 0, v.size() - 1);
for (auto i : v)
{
cout << i << endl;
}
system("pause");
return 0;
}void mergeSort(std::vector<int> &nums, int l, int r)
{
if (l < r)
{
int mid = l + (r - l) / 2;
mergeSort(nums, l, mid);
mergeSort(nums, mid + 1, r);
vector<int> tmp(r - l + 1);
int i = l, j = mid + 1;
int k = 0;
while (i <= mid && j <= r)
{
if (nums[i] < nums[j])
{
tmp[k++] = nums[i++];
}
else
{
tmp[k++] = nums[j++];
}
}
while (i <= mid)
{
tmp[k++] = nums[i++];
}
while (j <= r)
{
tmp[k++] = nums[j++];
}
for (int p = 0; p < k; ++p)
{
nums[l + p] = tmp[p];
}
}
}
void heapify(vector<int> &nums, int f, int n)
{
int left = f * 2 + 1;
int right = left + 1;
while (left < n)
{
int index = f;
if (nums[index] < nums[left])
index = left;
if (right < n && nums[index] < nums[right])
index = right;
if (index == f)
{
break;
}
else
{
swap(nums[f], nums[index]);
f = index;
left = f * 2 + 1;
right = left + 1;
}
}
}
void heapSort(std::vector<int> &nums, int n)
{
if (n < 2)
return;
// 从最后⼀个⽗节点调整为最⼤堆
for (int i = n / 2 - 1; i >= 0; --i)
{
heapify(nums, i, n);
}
// 最⼤值放最后,将剩下调整为堆
for (int i = n - 1; i > 0; --i)
{
std::swap(nums[0], nums[i]);
heapify(nums, 0, i);
}
}














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









