







- 常规卷积,每个输出通道一个过滤器(Filter)
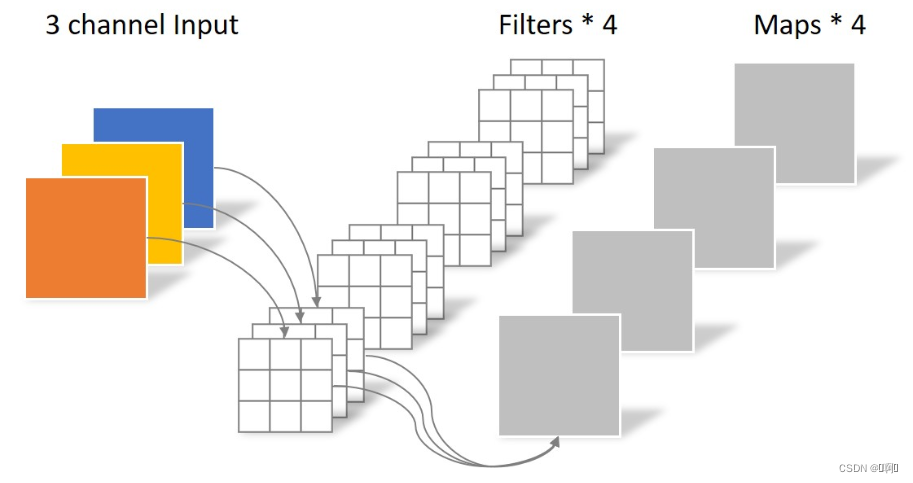
考虑单输出通道的情况(Filters = 1)
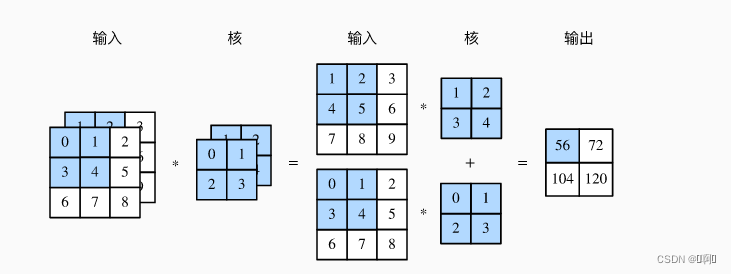
import torch
import numpy as np
X = torch.randn([16,3,4,4])
conv2 = torch.nn.Conv2d(3,4,kernel_size=3, padding=1, stride=2)
Y = conv2(X)
torch.Size([4, 3, 3, 3])
参数个数:4 × 3 × 3 × 3 = 108
- Separable Convolution这类卷积在Transformer的FFN中出现过
它将卷积分为两步,Depthwise Convolution与Pointwise Convolution。
- Depthwise Convolution:
相当于把输入的三通道视为3个单通道进行卷积
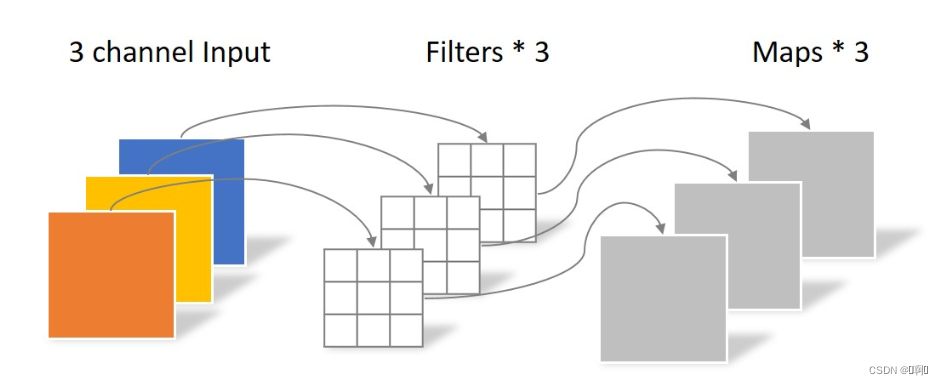
参数量:3 × 3 × 3 = 27
但是这种运算对输入层的每个channel独立进行卷积运算后就结束了,
没有有效的利用不同map在相同空间位置上的信息。因此需要增加另外
一步操作来将这些map进行组合生成新的Feature map,即接下来的
Pointwise Convolution
- Pointwise Convolution
这个就是普通卷积,只不过卷积核大小一定是1×1×c_in
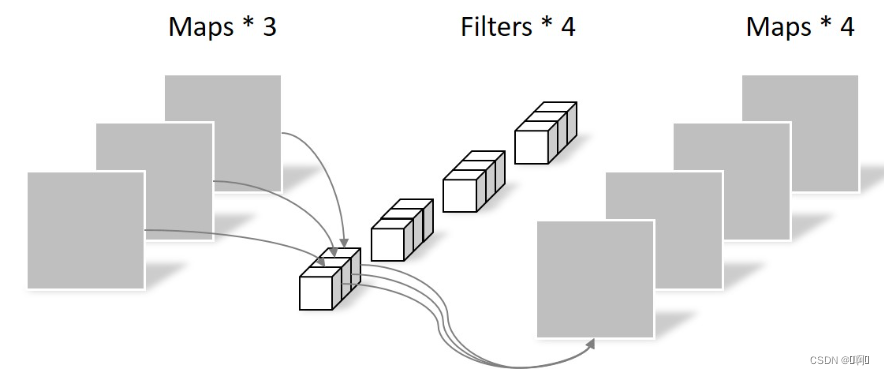 参数量:1 × 1 × 3 × 4 = 12
参数量:1 × 1 × 3 × 4 = 12
至此,输出的形状与常规卷积相同,但是总参数量仅为39.
所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成
新的Feature map。有几个Filter就有几个Feature map
class Separable_Convolution(nn.Module):
def __init__(self,c_in,c_out):
super(Separable_Convolution, self).__init__()
# 也相当于分组为1的分组卷积
self.Depthwise_Convolution = nn.Conv2d(in_channels=c_in,
out_channels=c_in,#这里的输出通道
kernel_size=3,
stride=1,
padding=1,
groups=c_in)#这个是关键,这个值必须能被out_channel整除
self.Pointwise_Convolution = nn.Conv2d(in_channels=c_in,
out_channels=c_out,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self,input):
out = self.Depthwise_Convolution(input)
out = self.Pointwise_Convolution(out)
return out
X = torch.randn([16,2,64,64])
Separa_conv= Separable_Convolution(X.shape[1],4)
Y = Separa_conv(X)
print(Y.shape)
-
以下参考
-
group参数,默认为1,也就是在通道维上将输入的所有通道视为1组。参数量为k²c1c2, 很好理解,每个输入c1个通道,需要k×k的卷积核映射到输出的一个通道, 输出有c2个通道, 所以需要c1×c2个卷积核
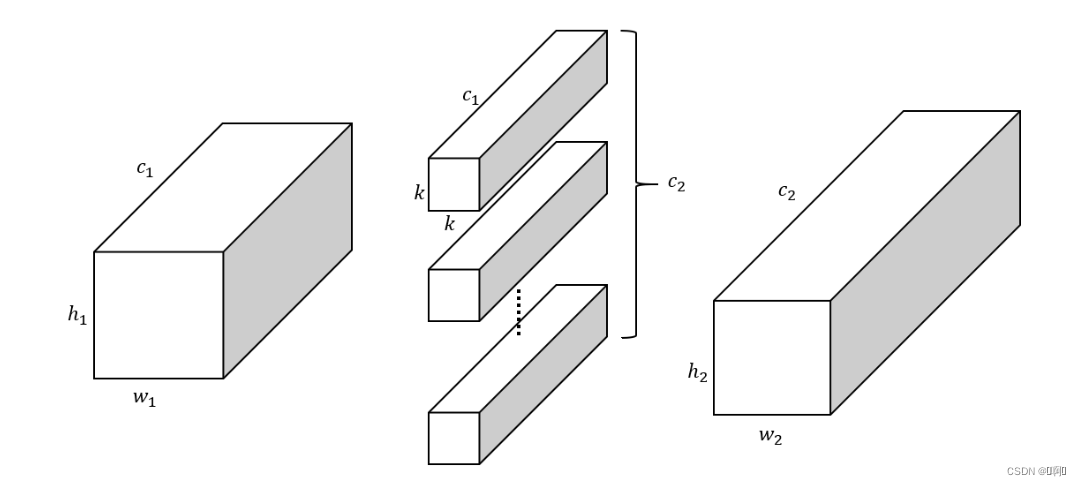
-
当设置为group=2时,相当于把输入按照通道切成两块,每一块进行独立的卷积,参数量为(k²c1c2)/2
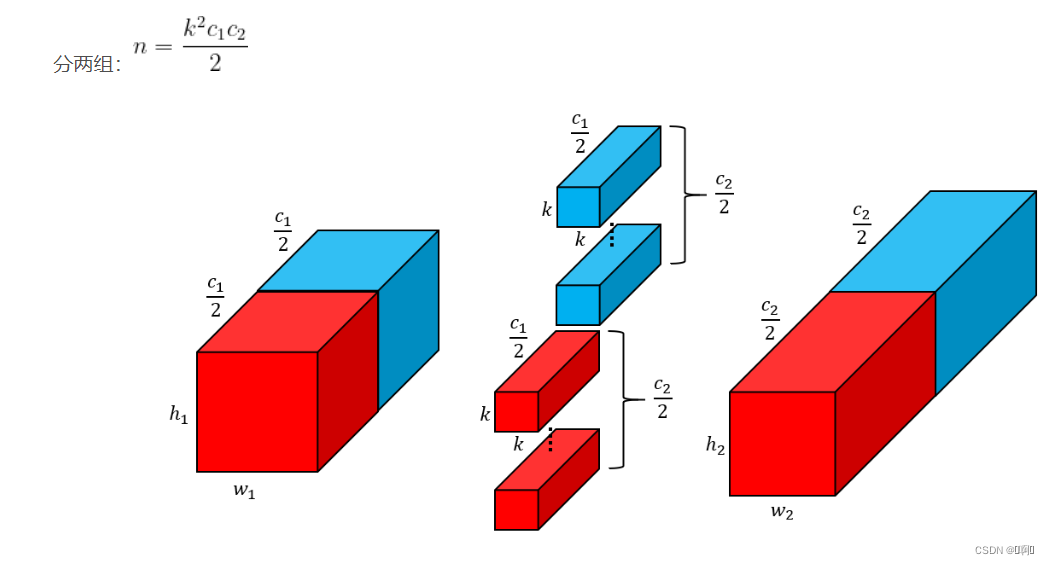
-
当设置为group=4时,参数量为(k²c1c2)/4
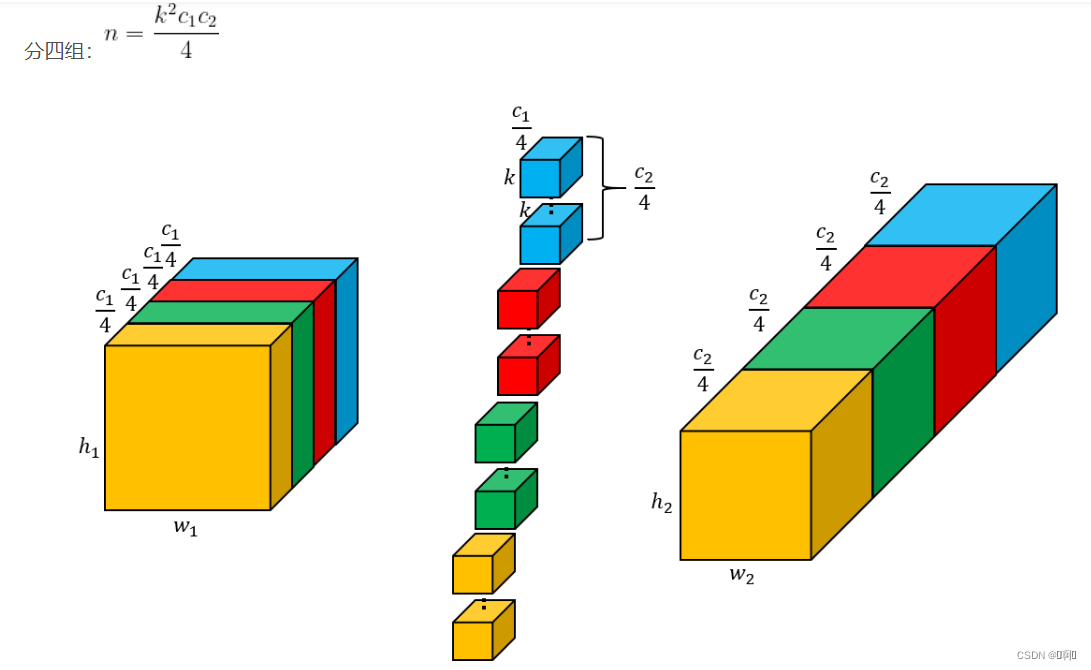
- 当group = out_channel,也就等价于Depthwise Convolution















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









