







转载的老板请注明出处:http://blog.csdn.net/cc_xz/article/details/78689998万分感谢!
在本篇中,你将了解到:
1.多线程和多进程的基本概念。
2.一些常用的线程锁。
3.如何实现线程间通信。
4.Python的进程和进程池。
多线程/进程的基本概念:
Python是运行在Python虚拟机种,而创建的多线程只是在Python虚拟机中的虚拟线程,而不是在操作系统中的真正的线程。也就是说,Python中的多线程,是由Python虚拟机来进行轮询调度,而不是操作系统。这极大的降低了Python多线程的可用性。
多线程可以使同程序同时执行多个任务。线程在执行过程中与进程存在区别,在每个独立的线程中,都分别存在程序运行的入口、顺序执行序列以及程序的出口。并且线程必须依附在某个程序中,由程序来控制多个线程的运行。
线程的基本操作:
线程具有5种状态,状态转换的过程如下:
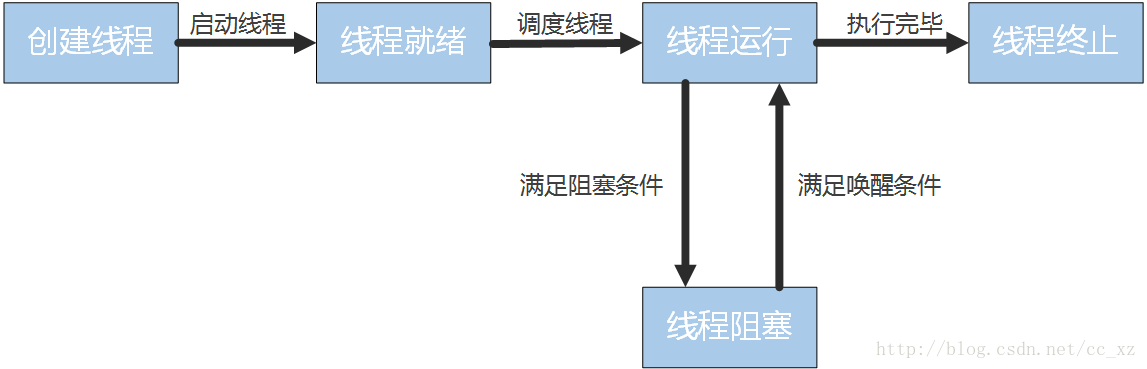
而线程和进程都是操作系统控制程序运行的基本单位,系统可以利用这两个特性对程序实现高并发。而线程和进程的主要区别如下:
1、一个程序至少有一个进程;一个进程中至少包含一个线程。
2、进程在内存中拥有独立的存储空间,而多个线程则共享它所依赖的进程的存储空间。
3、进程和线程对操作系统的资源管理的方式不同。
3.1、由于多个线程共享一个进程的存储空间(内存地址),也就是说多个线程是共享堆栈和局部变量的。即:多个线程只是一个进程中不同的执行路径(例如由多个线程执行同一个类),所以在进程中,一个线程崩溃就等于整个进程都崩溃掉了(共享一个存储空间)。
3.2、而由于进程具有独立的存储空间,所以当一个进程崩溃后,如果此进程没有其他交互式操作,是不会对其他进程产生影响的。(例如A进程负责读取,B进程负责写入,B进程所写入的数据是由A进程提供的,当A进程崩溃后,B进程没有正确的数据源,这就是影响到了B进程。而当B进程崩溃后,由于A进程是提供数据的,它无需考虑关于写入的问题,所以对A进程不会产生影响。)
而Python多线程的问题在于GIL的存在。在CPython(使用最广泛的Python解释器)中,GIL是一个全局线程锁。即:在解释器执行任何代码时,都必须获得这把锁。所以虽然CPython的线程库是直接封装了操作系统的原生线程/进程,但CPython的线程/进程作为一个整体,同一时间只能有一个线程运行在解释器中,而其他线程都处于等待着GIL将锁释放。
使用_thread模块创建线程:
Python中的多线程有两种使用方法,使用函数或用类包装线程对象。例如:
import _thread
import time
def print_time(threadName, delay):
count = 0
while count < 5: # 每个线程执行5次。
time.sleep(delay) # 给线程延时
count += 1 # 线程没执行一次,就记录一次。
print(threadName,
time.ctime(time.time())) # 分别输出线程名称和当前时间。
def start_thread():
"""
调用_thread库创建两个线程,第一个参数为该线程所需实现的功能,将函数做为参数。
值得注意的是:
当调用一个函数时,函数后带有括号,表示调用函数执行后返回的结果(return)
当调用函数不带有括号时,则表示调用这个函数本身。
接着分别输入线程名称和执行线程时延时的时间。注意,这两个参数仍然会被print_time获得并调用。
"""
_thread.start_new_thread(print_time, ("Thread-1", 1))
_thread.start_new_thread(print_time, ("Thread-2", 3))
start_thread()
time.sleep(30) # 主线程延时30秒,否则主线程迅速结束,子线程自然被销毁。输出结果为:
Thread-1 Tue Oct 10 18:29:52 2017
Thread-1 Tue Oct 10 18:29:53 2017
Thread-1 Tue Oct 10 18:29:54 2017
Thread-2 Tue Oct 10 18:29:54 2017
Thread-1 Tue Oct 10 18:29:55 2017
Thread-1 Tue Oct 10 18:29:56 2017
Thread-2 Tue Oct 10 18:29:57 2017
Thread-2 Tue Oct 10 18:30:00 2017
Thread-2 Tue Oct 10 18:30:03 2017
Thread-2 Tue Oct 10 18:30:06 2017
使用Threading模块创建线程:
使用Threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法即可:
import time
import threading
"""
*threading.Thread* 新建一个类,继承自threading.Thread类,通过该类创建多线程。
"""
class MyThread(threading.Thread):
"""
*threadID* 在初始化MyThread对象时,为新线程(对象)指定的ID号。
*name* 同理,为新线程(对象)指定的名称。
*counter* 在线程运行时,使用延时来模拟线程工作,定义每次线程执行延时多久,单位是秒。
"""
def __init__(self, threadID, name, counter):
# 调用父类的初始化方法,将子类(自身)作为参数。
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
"""
重写父类的方法,启动新线程时将执行此方法,并且线程执行何种任务需要在此方法中定义。
现有新线程分别在开始运行和结束运行时输出当前线程名称。
另外,执行自定义的print_time()方法。
"""
def run(self):
print("Starting " + self.name)
self.print_time(self.name, self.counter, 3)
print("Exiting " + self.name)
"""
print_time()方法是线程实际执行的任务。
*threadName* 自定义的当前线程名称。
*delay* 线程延时秒数。
*counter* 线程执行次数。
while用于循环执行线程,当counter的值大于0时,则一直循环线程。而每次循环结束后,都将counter的值减1。
在执行过程中进行延时和输出当前时间。
"""
def print_time(self, threadName, delay, counter):
while counter:
time.sleep(delay)
print(threadName, time.ctime(time.time()))
counter -= 1
# 创建对象
thread1 = MyThread(1, "Thread-1", 1)
thread2 = MyThread(2, "Thread-2", 2)
# 启动新线程。
thread1.start()
thread2.start()
# 同直接调用_thread不同,继承自threading.Thread的子类,可以在主线程结束后继续执行。
print("退出主线程") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









