






http://www.nvidia.com/attach/941771?type=support&primitive=0
06年底nv发的文章,从g80到fermi架构之前的nv显卡都是秉承g80的architecture,所不同的是各个部件有所增减,或者微调。
之前做ps3,学习的7系列的gpu知识,很多放在g80架构上都是“错的”了,g80架构看得很high,真是无愧于革命性的一代产品。
这个是overivew的图:

很多东西都很熟悉了,所以挑一些重要的记录吧:
unified shader
这里和console上编程有不同的就是,unified shader的分配是由driver和gpu内部的机制来分配,会根据shader的指令数,vertex和fragment数量比等预判vs和ps的计算量之间的关系,来进行计算资源的分配。
unified shader最大的好处是让资源分配更加市场经济,根据需要来分配,以至于一定程度上消除了vs和ps的瓶颈(但是也不绝对了)
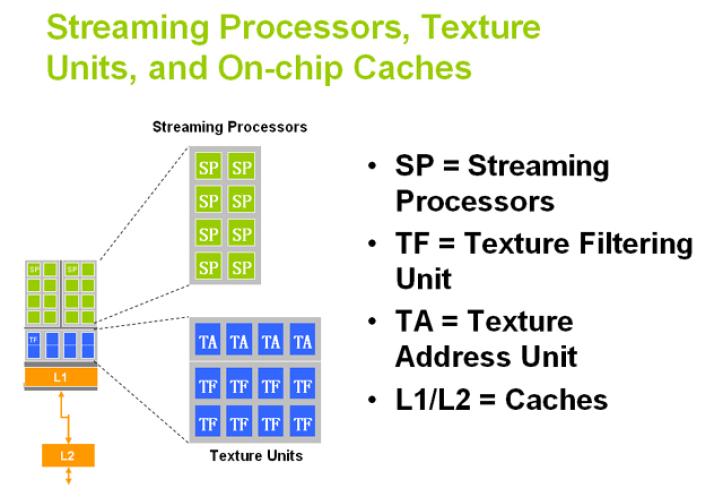
- 这个是一个unified shader的内部结构图,里面包括sp,ta,tf,cache。
- 内部做的时候,alu和sample运算时各自独立的,可以并行。
JIT Compiler
这个倒是以前没见过的东西,原来写shader的时候,对于coder来讲是像写java,编出来的code虽然也是汇编的,但是仍然是中间代码,在runtime的时候driver会把这个asm转成真正gpu使用的机器码,有点意思。
stream processor
真正做计算的unit:
- 由不同于其他unit的时钟周期来驱动,比如这里的http://www.nvidia.com/object/product_geforce_gts_240_us.html,可以看到graphics clock和processor clock两个周期,graphics clock可以做像vertex assembly一个周期生成一个triangle这种情况。
- 可以dual issue
- 是scalar processor----这个是比较关键性的改动相比于之前的vector processor,现在又转变成scalar计算了。我们一般写cg,hlsl时候,compiler还是会变成vector based asm,在8800里面会被转成scalar code(太tmd神奇了)。
- 另外有一点是,里面做性能对比的时候是128scalar processor和32个vector processor做的对比,性能说要高2倍,这里的128对32,也就意味着是本身1个vector processor也是类似4个scalar processor组成的,有点意思。
其他:
- csaa
- zcull
- bilinear anisotropic filter nearly free
- geometry shader
- stream output
总结:
除了对graphics coding有很多指导外,整个architecture的设计则破除了之前的种种不灵活(vector processor, non-unified shader)变得更加灵活和高效,可以看做是算法上的一种进步,在理论计算能力上有限进步下,取得了更大的实际计算能力。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









