









一、前言
最近基于MFC对话框,编写一个字节转码小工具(数值与字节码的相互转换,包括大小端和swap形式,数据包括整型、浮点型数据)。在使用串口、网络通信、嵌入式软件开发时,大小端字节序和Byte Swap是很常见的事情,许多工具软件诸如Modbus Poll和Modbus Slave都提供了数值(short,unsigned short,int, unsigned int,long long,unsigned long long,float,double等数值)的4种表示方式:Big-endian(大端)、Little-endian(小端)、Big-endian byte swap、Little-endian byte swap。如下图所示,Modbus Poll和Modbus Slave的Display菜单显示了这种情况:
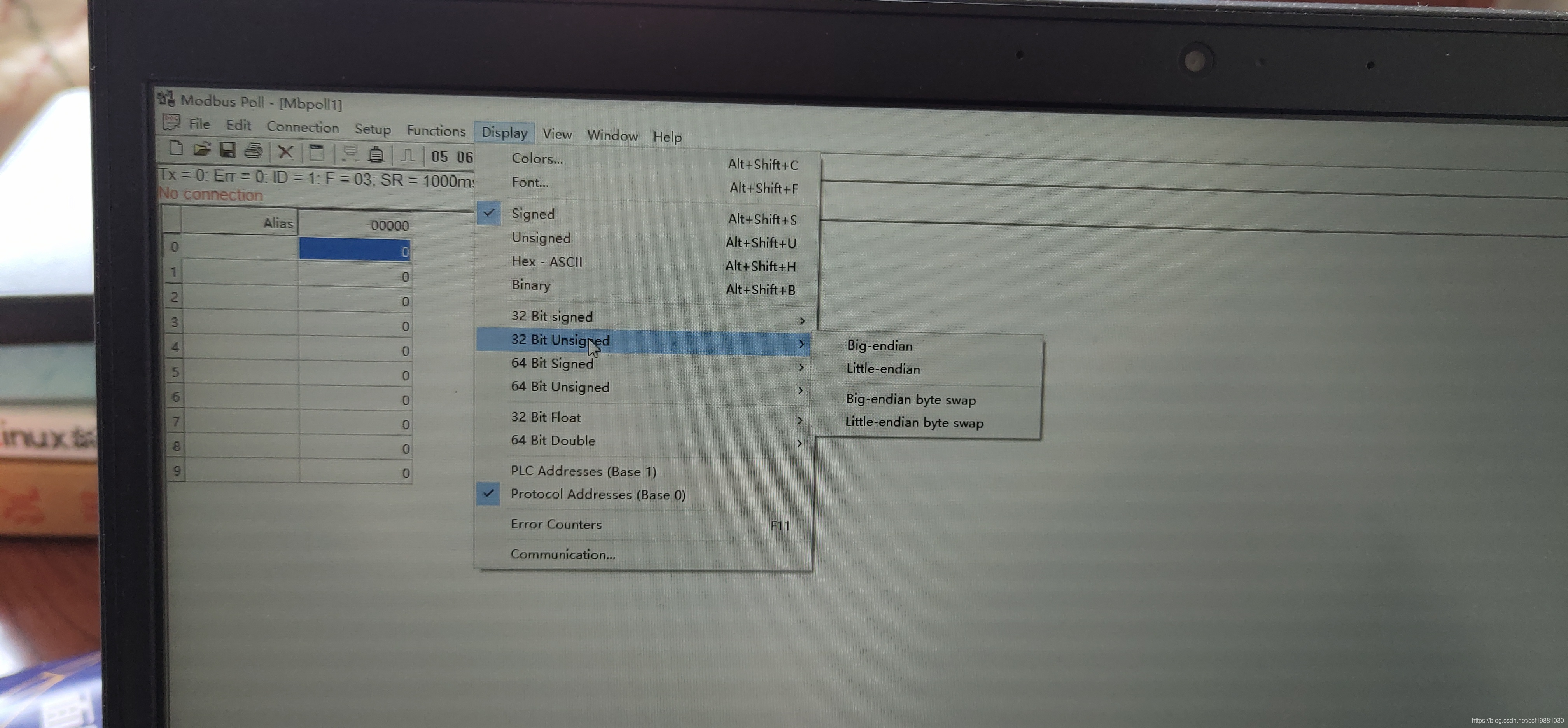
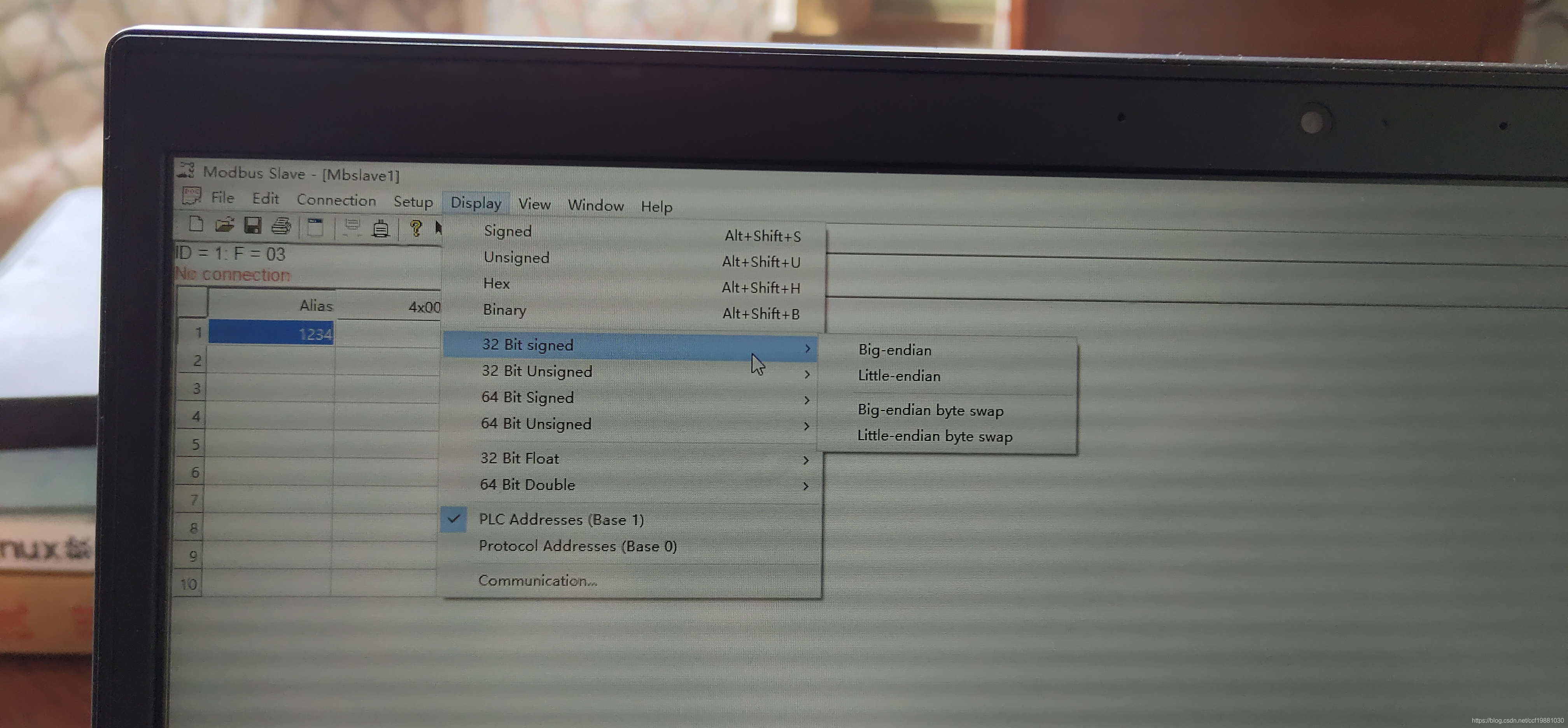
二、字节序(Endian),大端(Big-Endian),小端(Little-Endian)
1、处理器字节顺序和数据表示形式:
计算机处理器根据CPU处理器体系结构以大或小字节序格式存储数据。 操作系统(OS)不会影响系统的持久性。 大端字节顺序被认为是标准的或中性的“网络字节顺序”。 大尾数字节排序是一种易于理解的形式,也是十六进制计算器最常显示的顺序。常见的CPU处理器的大小端情况如下表所示:
| 处理器 | 大小端情况 |
|---|---|
| Motorola 68000 | Big Endian |
| PowerPC (PPC) | Big Endian |
| Sun Sparc | Big Endian |
| IBM S/390 | Big Endian |
| Intel x86 (32 bit) | Little Endian |
| Intel x86_64 (64 bit) | Little Endian |
| Dec VAX | Little Endian |
| Alpha | Bi (Big/Little) Endian |
| ARM | Bi (Big/Little) Endian |
| IA-64 (64 bit) | Bi (Big/Little) Endian |
| MIPS | Bi (Big/Little) Endian |
大小端的字节序硬件将它们的最高有效字节(MSB)和最低有效字节(LSB)彼此相反的顺序存储在内存中。 因此,大小字节序系统之间的数据交换(包括转换为网络字节序字节顺序)通常需要通过字节交换数据来实现字节序转换。 这仅适用于二进制数据值,不适用于文本字符串。
2、内存中的字节顺序和数据表示:
大端字节顺序是指最高有效字节在先的顺序。 这意味着代表最大值的字节排在第一位。 正整数以这种方式打印。 数字“ 1025”表示代表“ 1000”的第一个数字。 这是人类最舒适的表示。 首先以字节为单位表示此最高有效值,以表示计算机内存。 数字1025以十六进制表示为0x0401,其中0x0400表示1024,而0x0001表示数字1。总和为1025。在此大端字节序的数表示中,最高有效(更大的值)字节首先列出,即高位字节放在低位地址。
可以看到,字长是一个因素,它决定了使用多少字节来表示数字。Endian字节顺序影响整数和浮点数据,但不影响字符串,因为它们保持程序员查看和预期的字符串顺序。
Decimal: 1025
- 16 bit representation in memory:
- Big Endian:
Hex: 0x0401
binary: 00000100 00000001- Little Endian:
Hex: 0x0104
binary: 00000001 00000100
- Little Endian:
- Big Endian:
- 32 bit representation in memory:
- Big Endian:
Hex: 0x00000401
binary: 00000000 00000000 00000100 00000001 - Little Endian:
Hex: 0x01040000
binary: 00000001 00000100 00000000 00000000
- Big Endian:
Decimal: 133124
- 32 bit representation in memory:
-
Big Endian:
Hex: 0x00020804
binary:00000000 00000010 00001000 00000100 bits 31-25 bits 24-16 bits 15-8 bits 7-0 -
Little Endian:
Hex: 0x04080200
binary:00000100 00001000 00000010 00000000 bits 7-0 bits 15-8 bits 24-16 bits 31-25
-
Decimal: 1,099,511,892,096
- 64 bit representation in memory:
- Big Endian:
Hex: 0x0000010000040880
binary: 00000000 00000000 00000001 00000100 00000000 00000100 00001000 10000100 - Little Endian:
Hex: 0x8008040000010000
binary: 10000100 00001000 00000100 00000000 00000100 00000001 00000000 00000000
- Big Endian:
当前常用的字节序一般就两种,大端序和小端序。
大端序:ABCD
小端序:DCBA
小端Byte swap: CDAB
大端Byte swap: BADC
下面列出四种字节序的表达方式。在对应平台下,内存布局为{0x00,0x01,0x02,0x03}的四字节,表示为十六进制的值就如下面代码所示的。
ENDIAN_BIG = 0x00010203, /* 大端序 ABCD */
ENDIAN_LITTLE = 0x03020100, /* 小端序 DCBA */
ENDIAN_BIG_BYTESWAP = 0x02030001, /* 中端序 CDAB, Honeywell 316 风格 */
ENDIAN_LITTLE_BYTESWAP = 0x01000302 /* 中端序 BADC, PDP-11 风格 */
三、核心功能代码
#pragma once
//#include <type.h>
#include <algorithm>
#include <array>
#include <regex> // for std::regex_match
#include <iostream>
using namespace std;
// 自定义
typedef unsigned char uint8;
typedef unsigned short uint16;
typedef unsigned int uint32;
#ifdef WIN32
typedef unsigned __int64 uint64;
typedef __int64 int64;
#else
typedef unsigned long long uint64;
typedef long long int64;
#endif
typedef char int8;
typedef short int16;
typedef int int32;
#include <string.h>
// 数组
#include <string>
#include <vector>
typedef std::string String;
typedef std::vector<uint8> Uint8Array;
typedef std::vector<uint16> Uint16Array;
typedef std::vector<uint32> Uint32Array;
typedef std::vector<uint64> Uint64Array;
typedef std::vector<int8> Int8Array;
typedef std::vector<int16> Int16Array;
typedef std::vector<int32> Int32Array;
typedef std::vector<int64> Int64Array;
typedef std::vector<float> Float32Array;
typedef std::vector<double> Float64Array;
typedef std::vector<std::string> StringArray;
typedef std::vector<Uint8Array> Uint8sArray;
namespace ByteConvertTools
{
// 输入的byte数组中获取指定类型的数据
// 支持int16,int32,int64,float,double
template<typename T>
bool get_data(T& _return, const uint8* buffer, size_t buffersize,
uint16 offset_bytes, bool isLittle, bool isSwapByte)
{
uint32 totalByteNum = buffersize;
uint32 byteNum = sizeof(T);
uint32 regNum = byteNum / 2;
uint32 startPos = offset_bytes;
uint32 endPos = startPos + byteNum;
if ((regNum == 0 || byteNum % 2 != 0) || (startPos > totalByteNum || endPos > totalByteNum)) {
return false;
}
// 获取模板参数T的具体类型(int16,int32,int64,float,double)
auto& type = typeid(T);
if ((type == typeid(double) || type == typeid(int64) || type == typeid(uint64)) ||
(type == typeid(float) || type == typeid(uint32) || type == typeid(int32)) ||
(type == typeid(int16) || type == typeid(uint16))) {
Uint8Array tmp8; Uint16Array tmp16(regNum);
/*
不同的计算机体系结构使用不同的字节顺序存储数据。
“大端”表示最高有效字节在单词的左端。即最高位字节存放在字节数组的低位
“小端”表示最高有效字节在单词的右端。即最高位字节存放在字节数组的高位
*/
if (isLittle) {
// 小端字节序 dcba
std::copy(buffer + startPos, buffer + endPos, std::back_inserter(tmp8));
}
else {
// 大端字节序,则将字节数组进行反转 abcd
std::reverse_copy(buffer + startPos, buffer + endPos, std::back_inserter(tmp8));
}
memcpy(tmp16.data(), tmp8.data(), byteNum);
if (isSwapByte)
{
std::reverse(tmp16.begin(), tmp16.end());
Uint8Array tmp1(byteNum);
memcpy(tmp1.data(), tmp16.data(), byteNum);
std::reverse(tmp1.begin(), tmp1.end());
memcpy(tmp16.data(), tmp1.data(), byteNum);
}
memcpy(&_return, tmp16.data(), byteNum);
return true;
}
return false;
}
template<typename T>
bool get_data(T& _return, const Uint8Array& buffer,
uint16 offset_bytes, bool isLittle, bool isSwapByte)
{
return get_data(_return, buffer.data(), buffer.size(), offset_bytes, isLittle, isSwapByte);
}
// 判断本台机器是大端字节序还是小端字节序
bool isLittleEndian()
{
int iData = 1;
char *p = (char*)&iData;
if (*p == 1)
{
return true;
}
else {
return false;
}
}
// 将int16,int32,int64,float,double等转换成16进制字节数组
template<typename T>
bool convertToBytesArray(Uint8Array& _return, const T value, bool isLittle, bool isSwapByte)
{
uint32 byteNum = sizeof(T);
// 将T类型(int16,int32,int64,float,double等)的内容拷贝至tmp8中
Uint8Array tmp8(byteNum);
Uint16Array tmp16(byteNum / 2);
bool isLocalMachineLittleEndian = isLittleEndian();
if (isLittle == isLocalMachineLittleEndian) // 如果是小端
{
memcpy(tmp8.data(), &value, byteNum);
}
else {
memcpy(tmp8.data(), &value, byteNum);
// 将小端字节序转换成大端字节序或者将大端字节序转换成小端字节序
std::reverse(tmp8.begin(), tmp8.end());
}
// 交换相邻的两个字节
memcpy(tmp16.data(), tmp8.data(), byteNum);
if (isSwapByte)
{
std::reverse(tmp16.begin(), tmp16.end());
Uint8Array tmp1(byteNum);
memcpy(tmp1.data(), tmp16.data(), byteNum);
std::reverse(tmp1.begin(), tmp1.end());
memcpy(tmp16.data(), tmp1.data(), byteNum);
}
memcpy(tmp8.data(), tmp16.data(), byteNum);
_return = tmp8;
return true;
}
// c++用正则表达式判断匹配字符串中的数字数值(包括负数,小数,整数)MFC编辑框判断数值
static bool isStrNumber(String strInput)
{
//正则匹配数值包括负数 小数 整数
std::string strPattern{ "-[0-9]+(.[0-9]+)?|[0-9]+(.[0-9]+)?" };
std::regex re(strPattern);
bool retMatchStr = false;
retMatchStr = std::regex_match(strInput, re);
return retMatchStr;
}
};
四、软件相关介绍:

具体的实现代码见Github仓库-ByteTranscodingTool
本程序是采用Visual Studio 2013编写的,采用的基于对话框界面,特性如下:
1、支持int16,int32,int64,uint16,uint32,uint64,float,double转换成16进制的字节码
2、支持16进制的字节码转换成对应的int16,int32,int64,uint16,uint32,uint64,float,double,支持大小端和Byte Swap的四种组合:
(1)大端
(2)小端
(3)大端,Byte Swap
(4)小端,Byte Swap














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









