






 本文介绍了Vivado工具中的逻辑优化过程,涉及逻辑设计错误检测、优化设置策略,以及多种优化选项如常量传播、进位优化和MBUFG优化。文章详细讲解了如何避免错误和定制优化流程以提升设计效率。
本文介绍了Vivado工具中的逻辑优化过程,涉及逻辑设计错误检测、优化设置策略,以及多种优化选项如常量传播、进位优化和MBUFG优化。文章详细讲解了如何避免错误和定制优化流程以提升设计效率。
逻辑优化
逻辑优化确保在尝试放置之前进行最高效的逻辑设计。它执行网表连接检查,以警告潜在的设计问题,例如具有多个驱动器和非驱动输入。逻辑优化还执行块RAM功率优化。通常,设计连接错误会传播到逻辑优化步骤失败。在运行之前使用DRC报告确保有效连接非常重要实施
逻辑优化跳过已设置DONT_TOUCH属性的单元和网络的优化设置为TRUE值。逻辑优化还跳过直接具有应用的时间约束和例外。这样可以防止约束在目标对象被优化远离设计。逻辑优化也跳过的优化具有物理约束的设计对象,如LOC、Bel、RLOC、LUTNM HLUTNMREG和LOCK_ PINS。每个优化阶段结束时的信息消息提供由于约束而阻止的优化数量的摘要。关于的特定消息哪个约束阻止了可以使用-debug_log开关生成哪些优化。用于运行逻辑优化的Tcl命令是opt_design。
常见设计错误
一个可能导致逻辑优化失败的常见错误是使用未驱动的LUT输入,其中LUT逻辑方程使用该输入。这会导致以下错误:
当从多个集合逻辑时省略连接时,经常会发生此错误来源。逻辑优化识别单元名称和引脚,以便可以追溯到其源定义。
可用逻辑优化
Vivado工具可以对内存中的设计进行逻辑优化。
重要!逻辑优化可以通过选择相应的命令选项。仅运行那些指定的优化,而禁用所有其他优化,即使是那些通常默认执行。
下表描述了当选择了一个以上的选项。这种排序确保了最有效的优化执行。
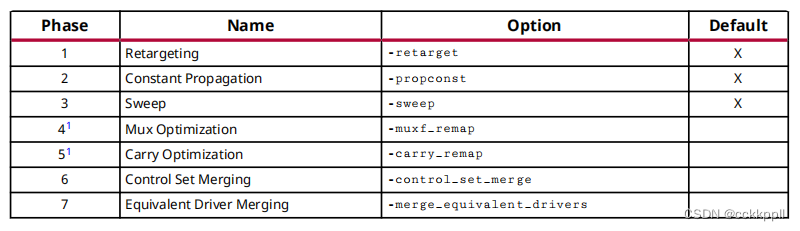
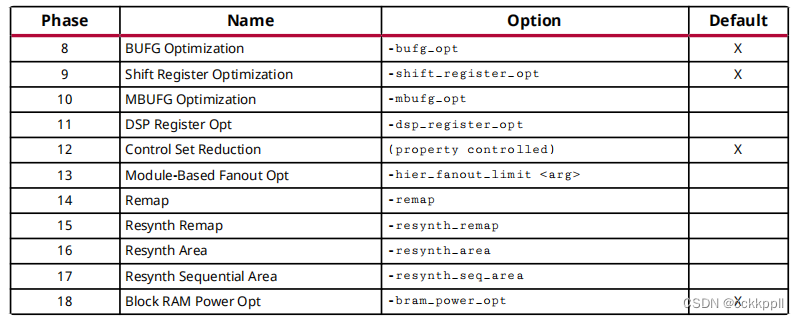
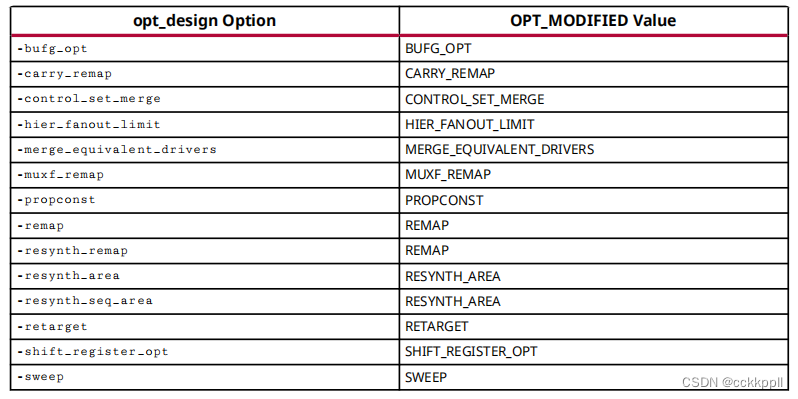
在基元单元上执行优化时,该单元的OPT_MODIFIED属性更新以反映对单元执行的优化。当多重优化在同一单元格上执行时,OPT_MODIFIED值包含中的优化列表他们发生的顺序。下表列出了各种的OPT_MODIFIED属性值opt_design选项:
重定目标(默认)
将设计从一个设备族重定目标到另一个时,将一种类型的块重定目标另一个例如,将实例化的MUXCY或XORCY组件重定目标为CARRY4块或者将DCM重定为MMCM。此外,逆变器等简单电池被吸收到下游逻辑。当下游逻辑无法吸收反相器时,反转为推到驱动器前面,消除了驱动器及其负载之间的额外逻辑级别。转换后,驱动器的INIT值被反转,设置/重置逻辑被转换为确保同等功能。
恒定传播(默认)
常量传播通过逻辑传播常量值,结果是:
•消除了逻辑:
例如,输入为常数0的AND。
•简化的逻辑:
例如,具有常数1输入的3输入AND被减少为2输入AND。
•冗余逻辑:
例如,具有逻辑0输入的2输入OR被简化为导线。
扫描(默认)
Sweep删除无负载单元和未连接的网络,并进行其他优化,例如下列的
•在宏引脚、触发器D引脚上执行打结
•复制驱动多个OBUF的触发器
•基于反馈回路,根据MMCM补偿属性的变化进行更新
•如果只使用一个输出,则将双端口RAM重定向到单端口
•针对区域优化SRLC32E/SRLC16E/ODDR/IDDR/CARRY4单元(如果可能)
•删除未使用的IDELAYCTRL,并将IO分组为最佳数量的IDELAYCTRL
•插入IBUF和OBUF,使某些细胞的连接合法化
Mux优化
将MUXF7、MUXF8和MUXF9基元重映射到LUT3以提高可路由性。你可以限制通过使用MUXF_REMAP信元属性而不是-muxf_remap选项。在各个MUXF基元上,将MUXF_REMAP属性设置为TRUE。
注:不适用于AMD Versal™。
提示:要在执行mux优化后进一步优化网表,请结合mux优化使用重映射(opt_design-muxf_remap-remap)。
进位优化
将进位链的CARRY4和CARRY8基元重映射到LUT,以提高可路由性。什么时候使用-carry_remap选项运行时,只有单级进位链转换为LUT。你可以使用carry_REMAP控制任意长度的单个进位链的转换单元格属性。CARRY_REMAP属性是一个整数,用于指定最大进位链要映射到LUT的长度。CARRY_REMAP属性应用于CARRY4和CARRY8基元和链中的每个CARRY基元必须具有相同的值才能转换为LUT。支持的最小值为1。
示例:一个设计包含长度为1、2、3和4的CARRY8基元的多个进位链。这个以下在所有CARRY8基元上分配CARRY_REMAP属性:
在opt_design之后,只有长度为3或更大的CARRY8基元的进位链保持映射至CARRY8。长度为1和2的链被映射到LUT。
注:不适用于Versal。
提示:即使进一步优化,将长进位链重新映射到LUT也可能显著增加延迟通过添加重新映射选项。AMD建议只重新映射较小的承载链,这些承载链由一个或两个级联的CARRY基元。
控制集合并
将逻辑等效控制信号的驱动器减少为单个驱动器。这就像一个反向扇出复制,并产生更适合于基于模块的复制的网络。
等效驱动程序合并
将所有逻辑等效信号的驱动器减少为单个驱动器。这与控制集类似合并,但应用于所有信号,而不仅仅是控制信号。您可以使用来限制等效驱动程序和控制集合并的范围EQUIVALENT_DRIVER_OPT单元格属性。设置EQUIVALENT_DRIVER_OPT属性
注:有些接口需要从FF驱动程序到接口引脚的一对一映射,并将这些映射合并逻辑上等效于单个驱动器的信号可能导致不可改变的网络。在这种情况下,设置将DONT_TOUCH属性设置为TRUE,或将其上的EQUIVALENT_DRIVER_OPT属性设置为KEEP寄存器。
BUFG优化(默认)
逻辑优化在时钟网络和高扇出非时钟网络(如设备范围的重置)上保守地插入全局时钟缓冲器。在Versal设备中,插入BUFF_FFabric时钟缓冲器在高扇形非时钟网络上。对于7个系列设计,只要不插入总共12个全局时钟缓冲器,就插入时钟缓冲器超过。对于UltraScale、UltraScale+和Versal设计,总共插入24个时钟缓冲区不超过全局时钟缓冲区,不包括BUFG_GT缓冲区。对于非时钟网络:
•扇出度必须高于25000。
•网络驱动的逻辑的时钟周期低于设备/速度等级特定限制。
MBUFG优化
对于Versal设备,一种新的多时钟缓冲器(MBUFG)提供除以1、2、4、8的时钟其O1、O2、O3、O4输出上的时钟输入。MBUFG时钟输出均在同一线路上布线全局时钟路由资源,并且仅在它们通过到达BUFDIV_LEAF路由时进行划分贝尔斯。MBUFG驱动的时钟消耗更少的路由资源,并且时钟偏斜最小化由同一MBUFG驱动的时钟之间的同步CDC路径,因为公共节点更接近源和目的地。MBUFG优化转换由公共驱动器或时钟驱动的并行时钟缓冲器将诸如MMCM、DPLL或XPLL的块(CMB)修改为MBUFG。如果并行时钟的分频因子被公共时钟的1、2、4、8分频。对于CMB则相移必须为0并且占空比必须为50%。如果时钟网络由BUFG具有冲突的约束,例如CLOCK_DELAY_GROUP或USER_CLOCK_ROOT转型也是
只有在安全的情况下才会发生转换而不会破坏定时约束。支持以下转换:
•连接到CMB的并联BUFGCE连接到MBUFGCE。
•并联BUFGCE_DIV,连接到MBUFGCE的公共时钟驱动器。
•并联BUFG_GT,连接到MBUFG_GT的公共时钟驱动器。
除了使用-mbufg_opt选项进行全局优化外,您还可以控制使用MBUFG_GROUP属性将所选BUFG转换为MBUFG。您必须设置MBUFG_GROUP对直接连接到时钟缓冲器的网段的约束。这个以下示例显示了应用于两个时钟网络的属性,这两个时钟网由时钟缓冲区:
下图中的图片显示了一个MMCM驱动几个BUFFCE缓冲器。这个CLKOUTn驱动时钟是CLKOUT1驱动时钟的1、2、4、8的整数除法。之后MBUFG优化-将四个BUFGCE转换为单个MBUFGCECLKOUT1驱动的时钟连接到MBUFGCE I引脚。由驱动的负载BUFGCE连接到MBUFGCE O1、O2、O3、O4引脚。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











