







上篇说过通过splitPk的方式将一个sql查询分成多个,进行并行查询可以大幅度的提高导数速度。
例如一张表
id name score
id单调递增, name是 aaa->zzz score是1->100 这种是完美数据,无论取哪个都会拆分的很均匀
但是生活中的数据千奇百怪。。。。有时候会发现splitPk速度确实有提升,但是还是很慢?
那怎么办呢?
例如
height name score 数据1000w
height=168-172 这个区间占了900w 其余的分布在150-190之间
name 是张三 李四 汉字这种
score 优秀 良好 这种
那么貌似只能选取height作为拆分了。但是存在一个问题,数据很集中,而且数据很联系。
splitpk=height 那么默认channel=10 会有50+1个task。如下
select table where height <150
select table where 150< heigth<153
select table where 153< heigth<155
.....
select table where 168< heigth<172 重点
....
select table where 190< heigth
select table where heigth is null
如上。这个168-172还是一个区间。你其他50个任务会很快的完成,但是你这个任务会一直占据时间,所以并不会大幅度加快你的导数速度。
实例
splitPk=product_key
被看似均匀的拆分为51个任务

17:03:20 taskId[22]开始 17:03:21 taskId[22]结束,肯定任务很少。

 截取几段主要的说明下
截取几段主要的说明下
2021-07-02 17:08:40.793 [job-0] INFO StandAloneJobContainerCommunicator - Total 4225857 records, 2602955571 bytes | Speed 4.80MB/s, 18105 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 58.593s | All Task WaitReaderTime 2,003.005s | Percentage 98.04% =50/51
具体表现在 Percentage 98.04% 代表task完成了多少个。 Percentage只有splitPk的时候才有,
Percentage=98.04%的任务一直跑了十多分钟才完成。说下问题,数据有1000w,任务完成98,但是数据才完成了40%,这是明显不合理的,说明有个task数据特别多。
解决办法。

String splitModel = configuration.getString(Key.SPLIT_MODE, "sample");
LOG.info("splitModel is {}", splitModel);
if ("sample".equalsIgnoreCase(splitModel)){
sampleSqlTemplate = "SELECT * FROM ( SELECT %s FROM %s SAMPLE (%s) %s ORDER BY DBMS_RANDOM.VALUE) WHERE ROWNUM <= %s ORDER by %s ASC";
splitSql = String.format(sampleSqlTemplate, splitPK, table,
percentage, whereSql, adviceNum, splitPK);
}else if("count".equalsIgnoreCase(splitModel)){
sampleSqlTemplate = "SELECT %s FROM ( SELECT /*+ parallel(a,4) */ %s, count(1) row_cnt FROM %s a %s group by %s ORDER BY row_cnt desc) WHERE ROWNUM <= %s ORDER by %s ASC";
splitSql = String.format(sampleSqlTemplate, splitPK, splitPK, table, whereSql, splitPK, adviceNum, splitPK);
}
原先oracle取数都是通过sample函数随机取数,然后划分范围,在某些时候,sample的结果可能不太令人满意。。。。
那么新增另外一种切分方式,count。之前数据不是都堆积168-172中间吗?那么只要我根据height groupby了 这些数据肯定分散了,168 100w 169 100w ....172 100w,
然后划分任务的时候虽然不均匀,但是相对均匀,其他任务也会很快跑完,但是最后会剩下168,169,170,171,172总共5个任务一直跑。远比168-172划分为一个任务的并行度快。
优化的结果

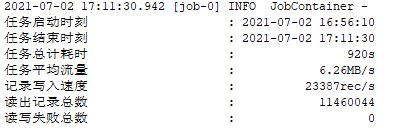
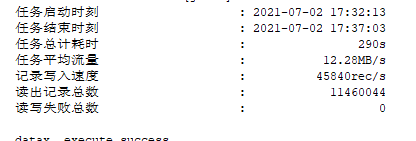
总结下:datax原先的取数sql不适合于: 没有主键单调递增的表,同时数据分布不均并且比较集中的表,或者数据量大的字段的值比较大(会被都排到sample取值最后的那个区间)
所以对以上情况进行改进,取出数据量最大的几个字段,然后对他们进行划分区间,是可以解决以上问题的
但同样存在问题于,数据分布均匀,那么count模式是不适合的,还是用原先的模式好。














 4019
4019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









