






目录
问题引入
知识蒸馏中用soft target代替hard target,那么soft target、hard target到底是什么?对他们该如何理解?
下面做一个简单快速的说明
理解soft target、hard target
首先:都是概率分布
首先,hard target、soft target都是标签(Labels)的概率分布。
以手写数字识别任务为例
样本

标准答案(ground truth)
ground truth / hard label y y y :2
hard target、soft target的不同
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| hard target | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| soft target | 0.02 | 0.035 | 0.6 | 0.2 | 0.005 | 0.02 | 0.02 | 0.03 | 0.04 | 0.03 |
或者看下面这张直方图,更直观地体现了hard target和soft target的区别
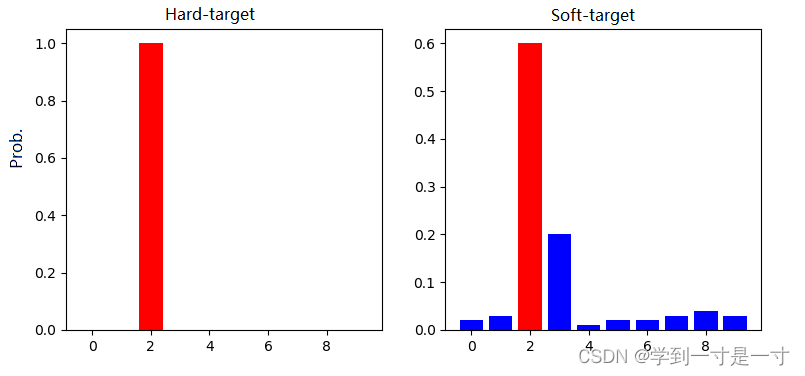
也许这张图还不足以让我们感受到soft target的优势,那么下面这张图就更好地说明了soft target优于hard taget的地方:携带更多 Teacher Model 学到的有用信息
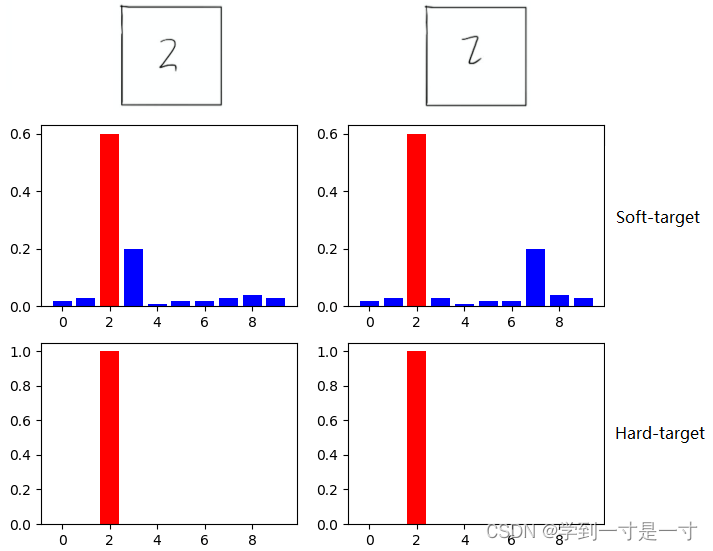
“ 能携带更多信息 ”, Hinton 在知识蒸馏鼻祖论文(Distilling the Knowledge in a Neural Network)中的描述是:
One of our main claims about using soft targets instead of hard targets is that a lot of helpful information can be carried in soft targets that could not possibly be encoded with a single hard target.
实验结果也表明:使用soft target得到的Student Model拥有更好的拟合能力。
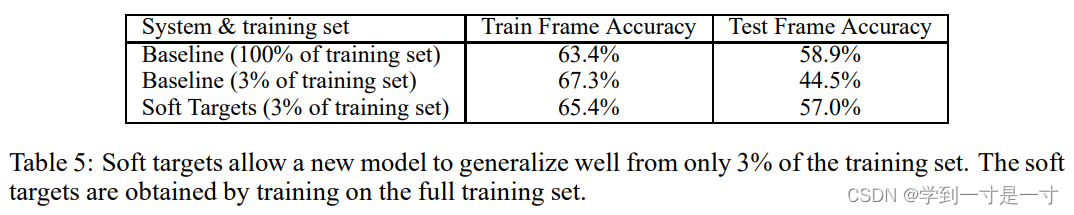
如何soft(软化)
温度T
上面说明了soft target比hard target好在哪,那么知识蒸馏是怎么得到soft target的呢?
答案:引入温度T。
回顾
化学蒸馏:A+B的混合物,想要分离A、B。已知 T A 沸点 < T B 沸点 T_{A沸点}<T_{B沸点} TA沸点<TB沸点。那么就能通过蒸馏的方式:当 T A 沸点 < T 蒸馏 < T B 沸点 T_{A沸点}<T_{蒸馏}<T_{B沸点} TA沸点<T蒸馏<TB沸点,A被
“蒸” 出去了,瓶子里留下的是B,且能在另一端收集到A——达到了分离的目的。
知识蒸馏:
q
i
=
s
o
f
t
m
a
x
(
z
i
)
=
e
x
p
(
z
i
/
T
)
∑
j
e
x
p
(
z
j
/
T
)
q_i=softmax(z_i)=\frac{exp(z_i/T)}{\sum_jexp(z_j/T)}
qi=softmax(zi)=∑jexp(zj/T)exp(zi/T)
Using a higher value for T produces a softer probability distribution over classes.
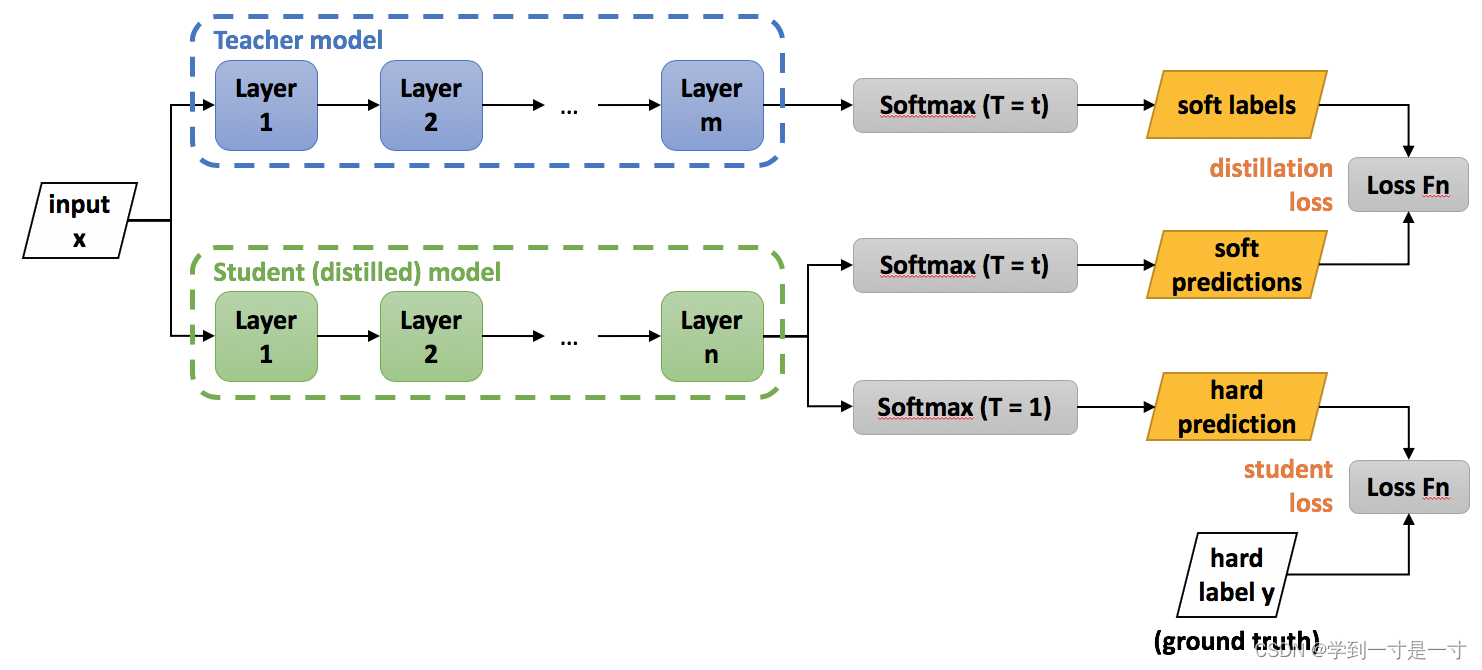
soft target就是上图中的soft labels。
步骤
S1: 得到训练好的Teacher Model(训练数据为hard labels)
S2:
Teacher Model(T=t)得到soft targets
S3:
Student Model(T=t)、Student Model(T=1)分别得到soft predictions、hard predictions。
Distillation Loss: 将上一步得到的soft targets与soft predictions作交叉熵
Student Loss: hard predictions与hard labels作交叉熵
总的损失函数是这两部分的加权,分别赋予权重
β
、
α
\beta、\alpha
β、α
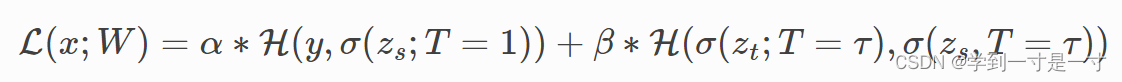
S3: 最后作测试令Student Model(T=1)
关于梯度下降更新logits的部分可后续更新,但我自己已经推好了😁















 1991
1991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









