






一.知识蒸馏综述
1.简介
大模型在部署到资源有限的设备上(手机、嵌入式设备等)会遇到体积和速度问题,知识蒸馏作为有代表性的模型压缩和加速的技术之一(其他还有:参数裁剪和共享、低秩分解和Transferred compact convolutional filters等),近年来受到了学术界和工业界的广泛关注。
为了在资源有限的设备上部署深度模型,Bucilua 等人在2006年首次提出了模型压缩技术来迁移大模型或集成模型里的信息去训练小模型而精度不会有显著的下降。随后,Hinton 2015年正式在论文Distilling the knowledge in a neural network中提出了知识蒸馏的概念,这算是知识蒸馏的开山之作,也是绝对的经典之作。
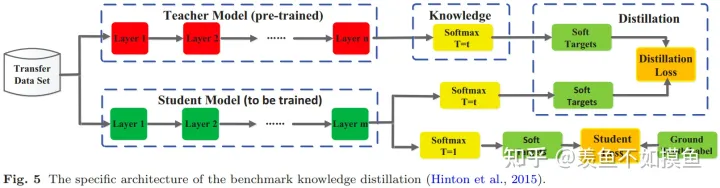
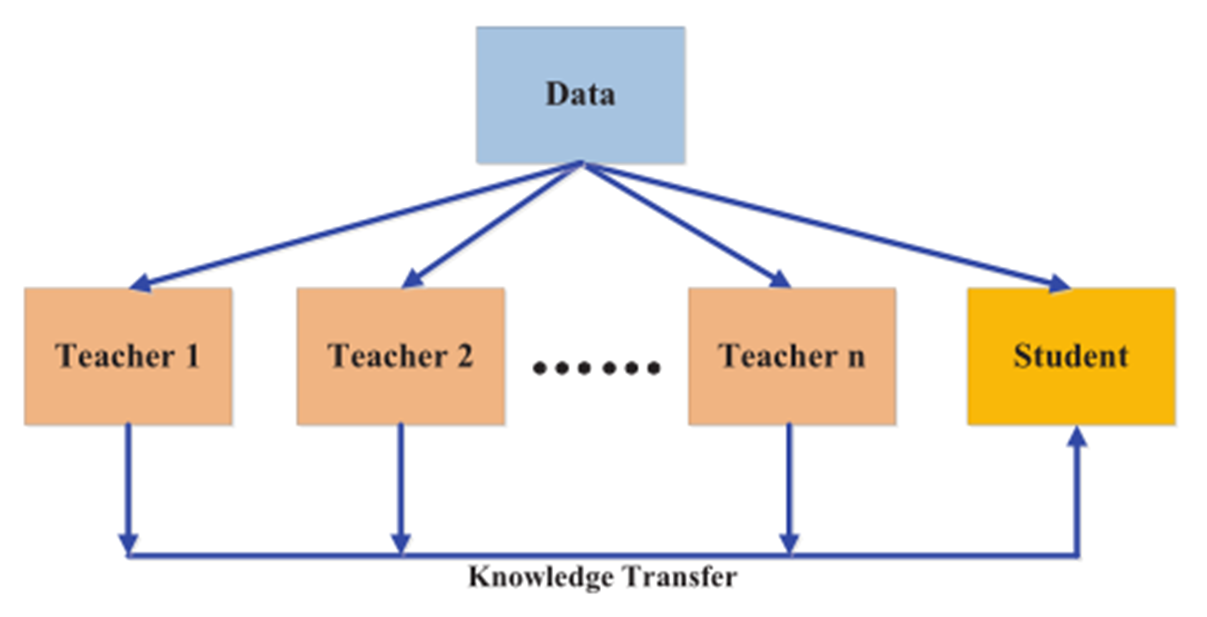
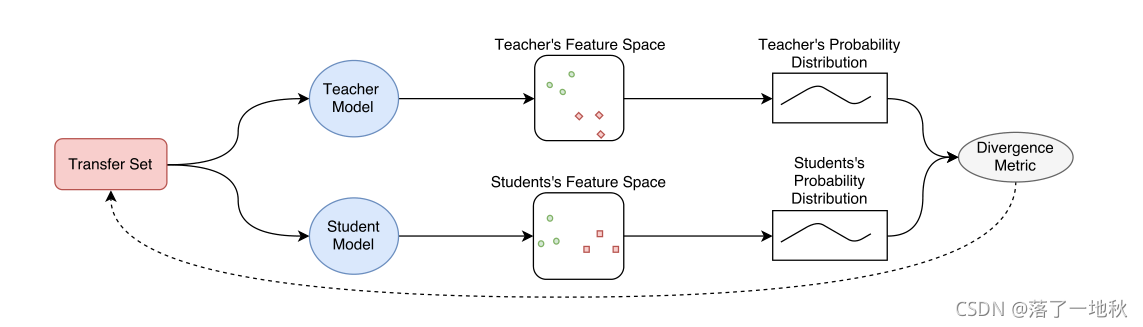
图1展示了知识蒸馏的基本架构,主要由知识、蒸馏算法和teacher-student架构三个部分组成。
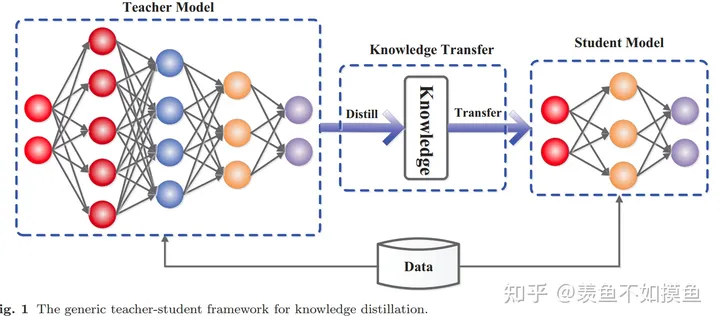
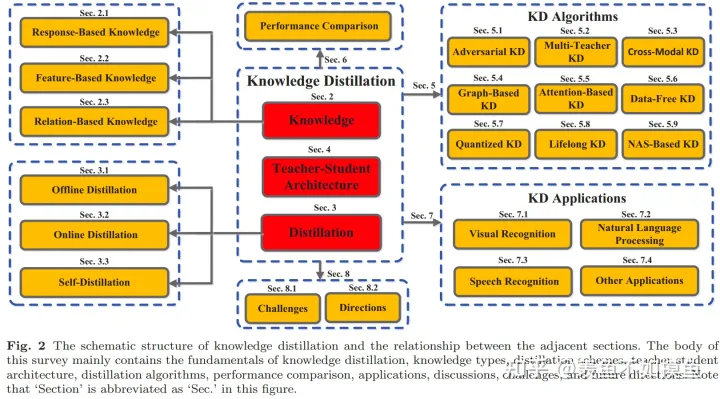
图2为本篇综述的结构,主要包括前面提到的知识蒸馏系统的三个主要部分,此外还有性能比较和总结展望。
2.知识
在原始或者说早期的知识蒸馏技术里,student学习的是teacher的logits(对于分类任务而言,一般将进softmax之前的scores叫做logits,softmax输出的概率分布叫soft labels,当然了,后者也有叫logits的)。后来为了改善知识蒸馏的效果,各路大佬开始花式开发各种特征用于学习,整体大致可以分为三类,response-based knowledge, feature-based knowledge and relation-based knowledge。
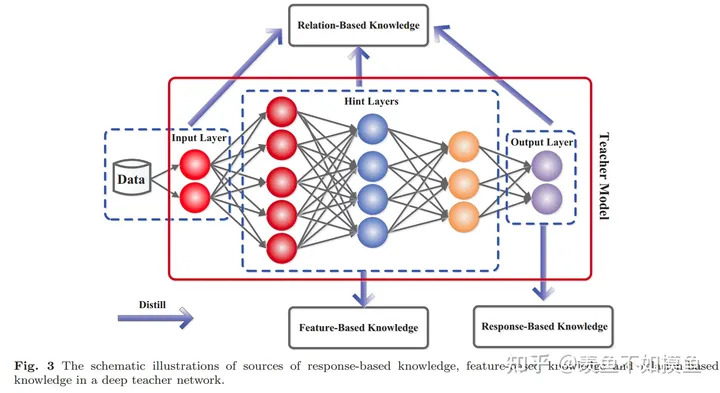
2.1 Response-Based Knowledge
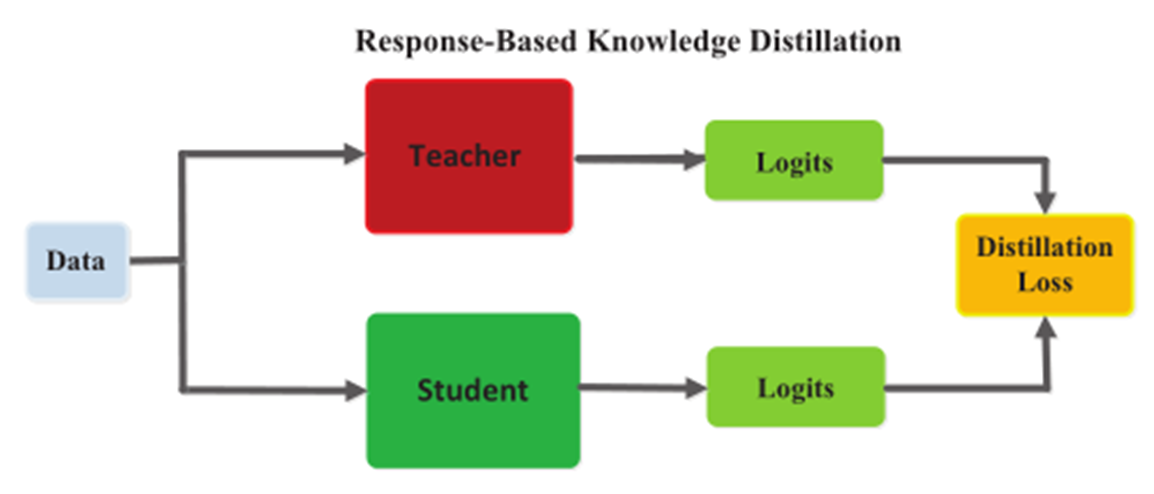
Response-Based Knowledge一般是指teacher模型最后一层的响应,即logits。主要思想就是让student直接模仿teacher最后的预测。
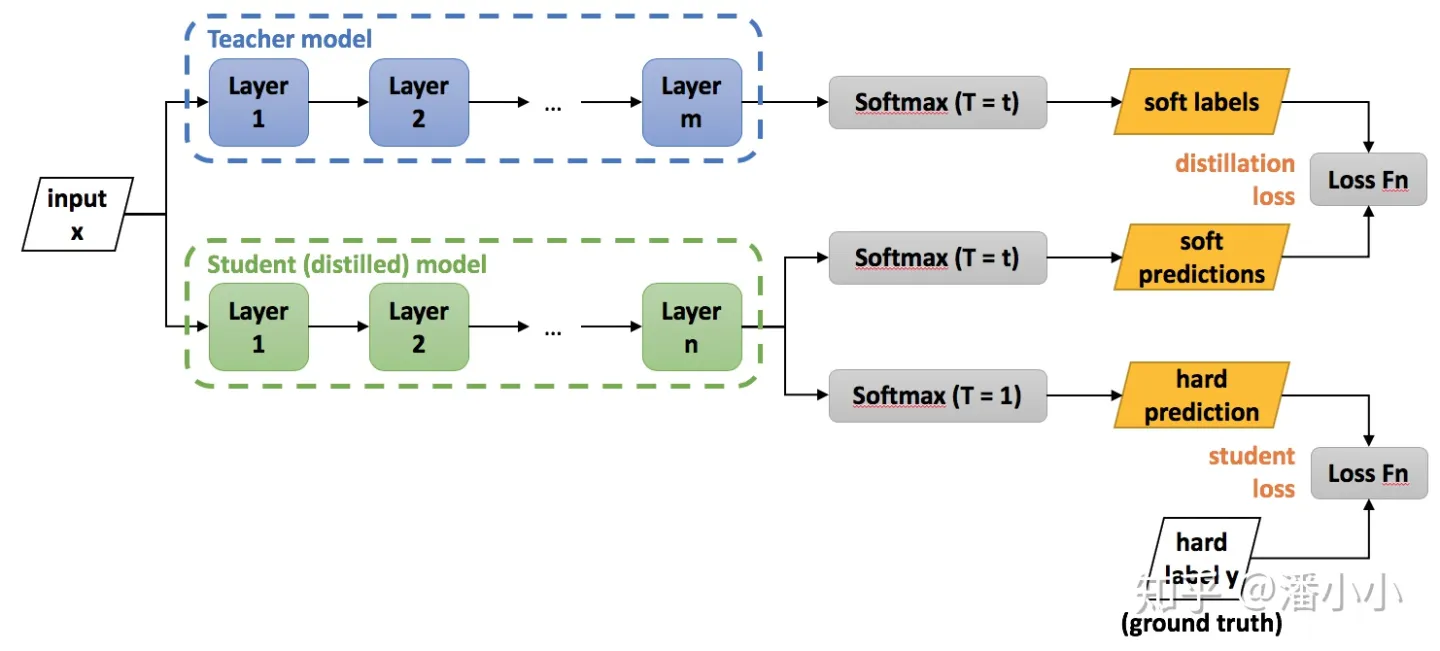
分类任务中最常用的基于响应的知识就是soft targets,即softmax输出的概率分布,一般可以用KL散度作为损失函数。
![]()
![]() 表示logit的KL散度损失,
表示logit的KL散度损失,![]() 和
和![]() 表示师生的logit。
表示师生的logit。
图5是Hinton论文中经典知识蒸馏的架构,可以看到分成了上下两个部分,下面部分的student loss是我们非常熟悉的学习ground truth label的部分,上面的distillation loss是学习soft targets的部分。图片里的有个略显奇怪的温度系数T,这里重点提一嘴,这算是对softmax的一个非常棒的改动,不仅在知识蒸馏领域有奇效,在近来非常火热的对比学习领域也发挥着重要作用。不过温度系数T在这两个领域又有所不同,在知识蒸馏里,一般是在高温T下去蒸馏知识(有化学蒸馏那味儿);而在对比学习领域,一般需要比较小的温度系数来放大差异,让学习过程更加聚焦在hard 负例上。关于细节,有兴趣的同志可以参考【经典简读】知识蒸馏(Knowledge Distillation) 经典之作 - 知乎和你似乎来到了没有知识存在的荒原 - 知乎等。
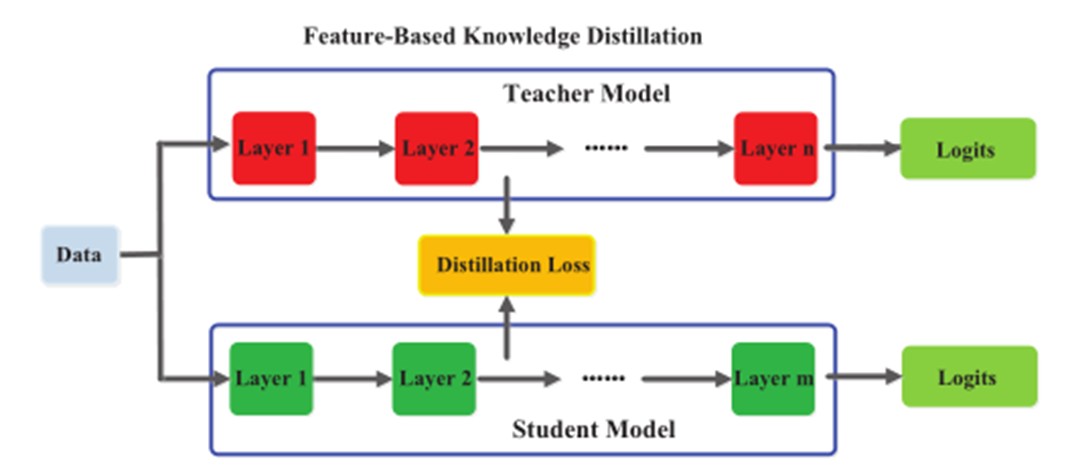
2.2 Feature-Based Knowledge
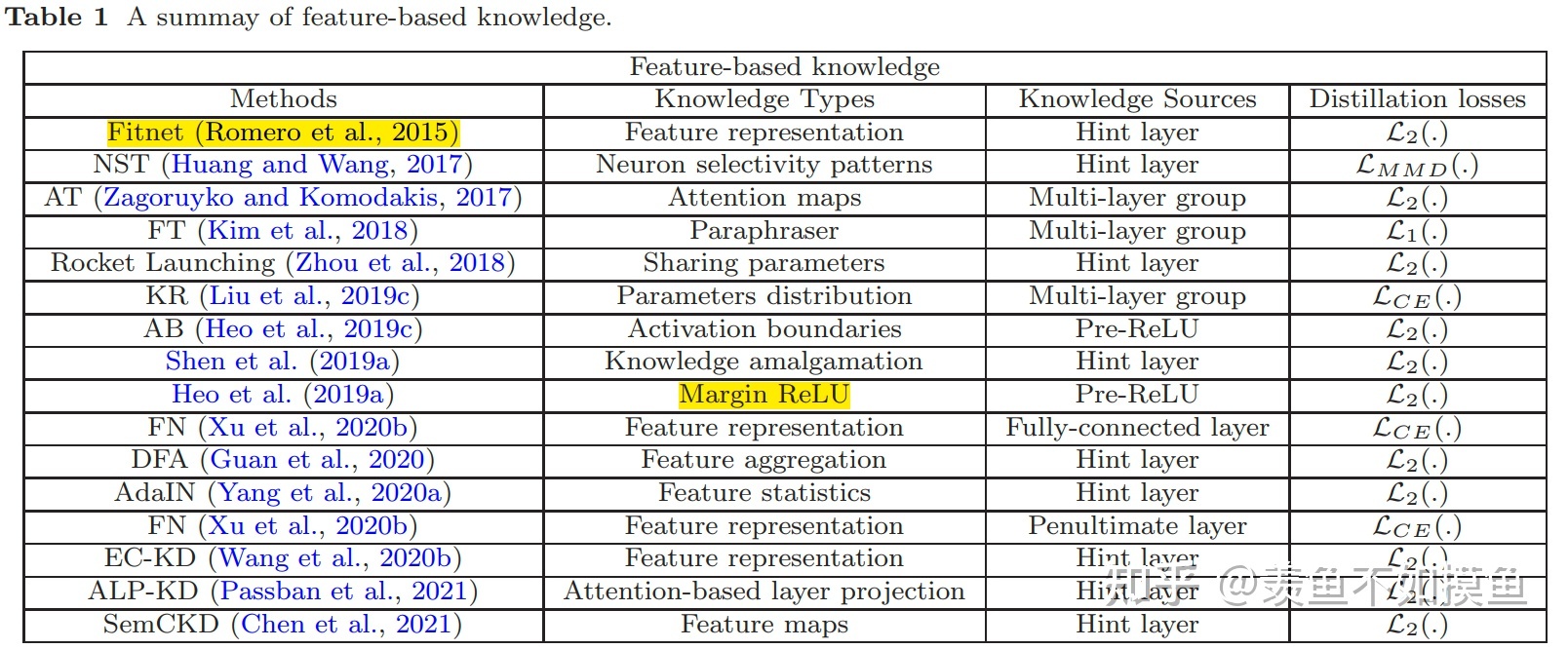
所谓的基于特征的知识其实就是中间层的输出,自从2015年的Fitnets之后,出现了很多花式利用各种中间层特征进行蒸馏的研究,详见表1。
这里重点提一下中间层匹配涉及到的一个层间匹配问题,对于离线蒸馏而言,student可能层数会小一些,如何将teacher的层与student的层进行对应或匹配就是个关键问题。大多数情况下,层间匹配只能靠经验或者实验。不过2021年,Chen等人提出了跨层知识蒸馏,通过注意力机制来为每个student层分配合适的teacher layers。另外,中间层的特征维度可能会不匹配,需要根据情况进行投影或者说变换。
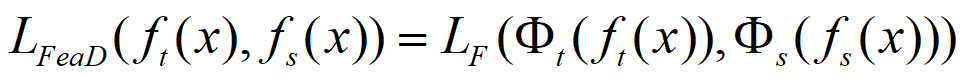
![]() 和
和 ![]() 分别为师生中间层的特征图.
分别为师生中间层的特征图. ![]() 和
和![]() 为变换函数,通常用于教师和学生模型的特征图形状不相同的情况。
为变换函数,通常用于教师和学生模型的特征图形状不相同的情况。![]() 表示用于匹配师生特征图的相似性函数。
表示用于匹配师生特征图的相似性函数。
2.3 Relation-Based Knowledge
Relation-Based Knowledge是指不同层或样本之间的关系,这里的对象我们可以自由构造,比如两个层之间的关系、三个层之间的关系、两个样本之间的关系、三个样本之间的关系等等。具体的,比如我们面对的是一个文本相关性任务,可以让student去学习teacher输出的不同样本对的相关性,即teacher认为两个文本的相关性是多少,则student就去学习尽量做到同样的相关性。
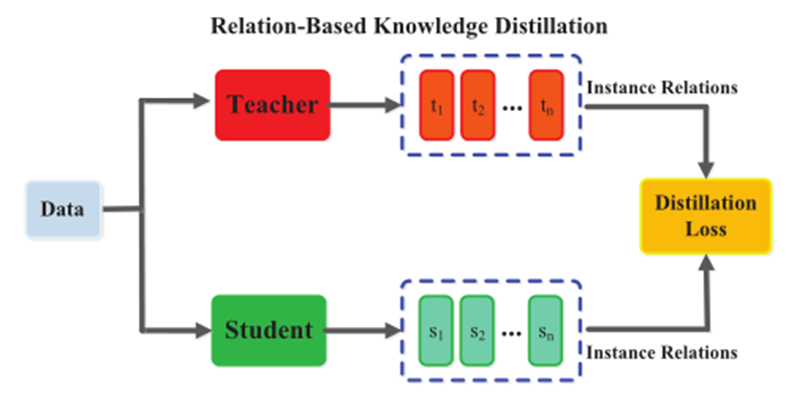
基于特征映射关系的 :
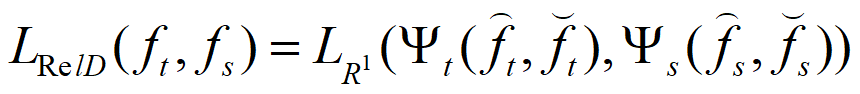
![]() 和
和 ![]() 分别为师生的特征图。
分别为师生的特征图。 ![]() 和
和 ![]() 指师生模型中特征图对的相似性函数。
指师生模型中特征图对的相似性函数。 ![]() 表示师生特征图之间的相关函数。
表示师生特征图之间的相关函数。
· 基于实例关系的:
![]()
t、s分别为师生的特征表示集。 ![]() 和
和![]() 是
是 ![]() 和
和 ![]() 的相似函数。
的相似函数。
![]() 是师生特征表示之间的相关函数。
是师生特征表示之间的相关函数。
3.Distillation Schemes
知识蒸馏一般可以分为离线蒸馏、在线蒸馏和自蒸馏三种架构。
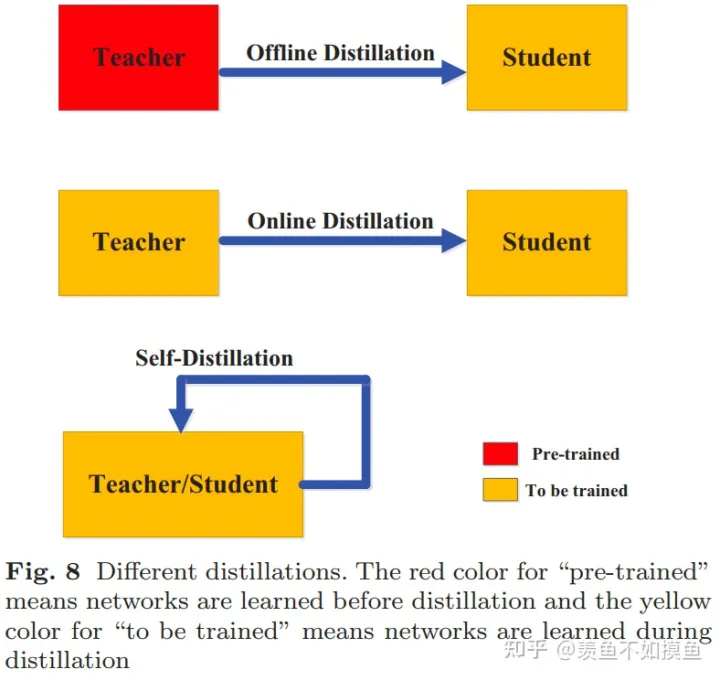
3.1 Offline Distillation
预训练teacher
工业界用的比较多的是离线蒸馏,学生向预先训练好的老师学习,简单易于实现。离线蒸馏的主要关注点在知识的获取选择和损失函数的设计上。离线蒸馏的主要问题是大的teacher和小的student之间存在着model capacity gap,可能小的student就没有办法学得特别好,因为可能能力确实有限。这与人类的师生关系其实有本质的不同,人类的teacher和student只有闻道有先后的差别,没有human capacity gap。因此在人类的学习过程中,经常出现学生超过老师的情况,但在离线蒸馏中,学生往往很难超过老师。
3.2 Online Distillation
师生同时更新,整个框架端到端可训练。(如相互学习)
相互学习(DML):student相互学习,泛化能力更好。效能随着网络数量增加而增加。
3.3 Self-Distillation
指不通过新增一个大模型的方式找到一个teacher模型。因能学到增益信息而收益。
- 1)伪孪生网络。
- ①同步蒸馏 ②多阶段蒸馏
- 2)类Deep Supervision 。即将模型中较深层网络结构作为teacher蒸馏原模型中较浅层的网络结构。
- 3)上述两类的混合使用。
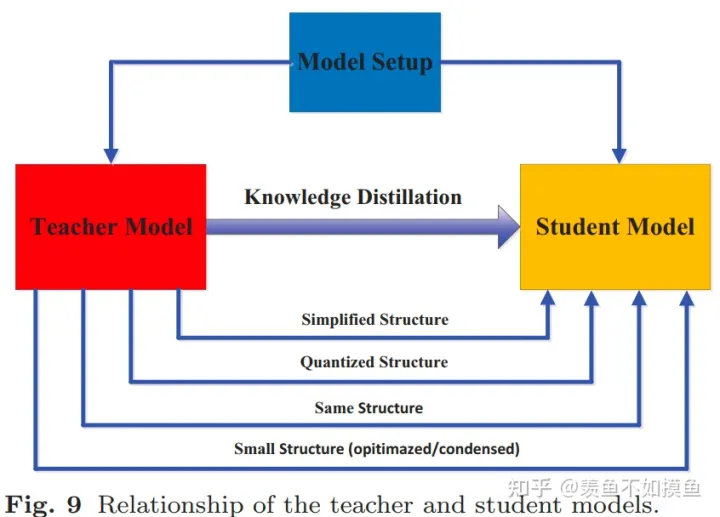
4.Teacher-Student Architecture
这个部分不想多说,有兴趣的朋友可以关注一些关于缓解model capacity gap的工作,比如teacher assistant、residual learning等等。另外,还有一些利用depth-wise separable convolution、neural architecture search (or NAS)和强化学习等方式设计更高效的student结构的工作。
 5.Distillation Algorithms
5.Distillation Algorithms
大部分情况下我们还是使用single-teacher distillation,但下面的某些Distillation Algorithms或许可以起到锦上添花的作用。
- Adversarial Distillation 对抗蒸馏
- Multi-Teacher Distillation 多教师蒸馏
- Cross-Modal Distillation 跨模态蒸馏
- Graph-Based Distillation 基于图的蒸馏
- Attention-Based Distillation 基于注意力的蒸馏
- Data-Free Distillation 无数据蒸馏
- Quantized Distillation 量化蒸馏
- Lifelong Distillation 终身蒸馏
- NAS-Based Distillation 基于NAS的蒸馏
1.对抗蒸馏
对抗蒸馏(Adversarial Distillation)是一种知识蒸馏的方法,它通过引入对抗性训练来提高模型的鲁棒性和泛化能力。与传统的知识蒸馏方法不同,对抗蒸馏不仅关注模型之间的相似性,还考虑了模型对抗样本的鉴别能力。
在对抗蒸馏中,通常包括两个网络:教师网络(Teacher Network)和学生网络(Student Network)。教师网络是一个预训练的强大模型,具有较高的准确性和鲁棒性。学生网络是一个较浅的模型,需要从教师网络中蒸馏知识。
对抗蒸馏的核心思想是在训练过程中引入对抗样本,并通过优化学生网络使其能够正确分类对抗样本。具体而言,对抗蒸馏包括以下步骤:
-
教师网络的训练:首先训练教师网络,使用标准的监督学习方法,使其达到较好的性能。教师网络作为知识的提供者,将其输出视为目标分布。
-
学生网络的初始化:初始化学生网络,通常采用与教师网络相同的网络结构,但参数是随机初始化的。
-
对抗训练:通过对抗训练的方式,迭代地调整学生网络的参数,使其输出分布逼近教师网络的输出分布。具体步骤如下:
-
输入样本的扰动:对输入样本进行扰动,引入噪声或变换,增加样本的多样性。
-
学生网络的前向传播:将扰动后的输入样本输入到学生网络中,获取学生网络的输出。
-
教师网络的前向传播:将扰动后的输入样本输入到教师网络中,获取教师网络的输出。
-
对抗损失计算:根据学生网络和教师网络的输出,计算对抗损失,衡量学生网络的输出分布与教师网络的输出分布之间的差异。
-
反向传播与参数更新:根据对抗损失,反向传播误差,并更新学生网络的参数,使得学生网络逐渐逼近教师网络的输出分布。
-
-
辅助目标的训练:除了对抗损失,可以结合其他辅助目标来训练学生网络,例如交叉熵损失函数或其他蒸馏损失函数。这些辅助目标可以帮助学生网络更好地学习教师网络的知识。
对抗蒸馏的目标是使学生网络具有与教师网络相似的分类性能,并且在面对对抗样本时能够保持鲁棒性。通过引入对抗样本和对抗训练,对抗蒸馏能够提高模型的泛化能力和抗扰动能力,从而在面对复杂的现实场景中取得更好的表现。
1) 生成合成数据用作训练数据集/增强训练数据集。
![]()
![]() 和
和![]() 为师生模型输出。
为师生模型输出。![]() 表示给定随机输入向量
表示给定随机输入向量![]() 由生成器
由生成器![]() 生成的训练样本。
生成的训练样本。 ![]() 为蒸馏损失,用于强制预测概率分布和基本真值概率分布之间的匹配。
为蒸馏损失,用于强制预测概率分布和基本真值概率分布之间的匹配。
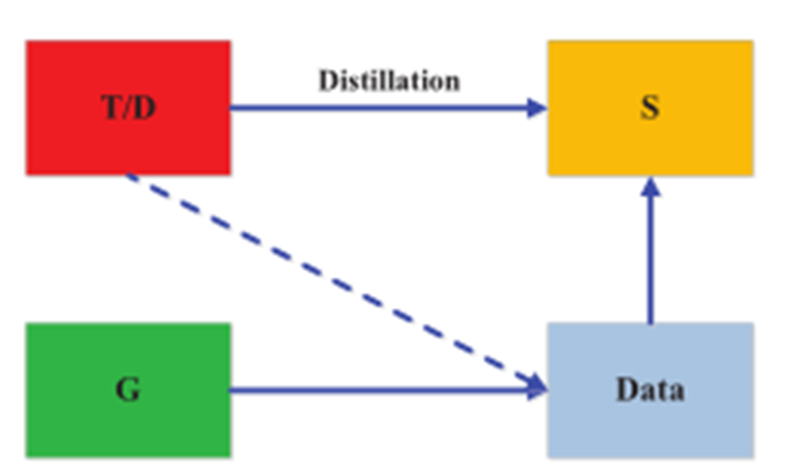
2)引入独立鉴别器,student作生成器模仿teacher
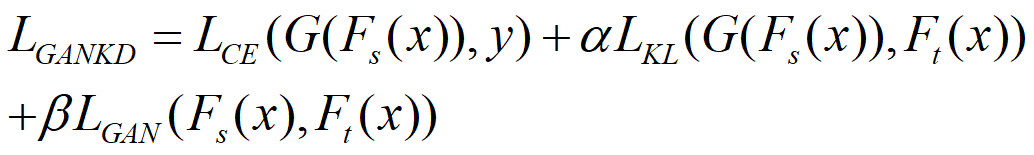
其中![]() 为student网络,
为student网络, ![]() 表示生成对抗网络中使用的典型损失函数,以便师生间的输出尽可能相似
表示生成对抗网络中使用的典型损失函数,以便师生间的输出尽可能相似
3)在线方式进行,师生共同作生成器。
2.多教师蒸馏
多教师蒸馏(Multi-Teacher Distillation)是一种知识蒸馏的方法,它通过同时蒸馏多个教师网络的知识来提升学生网络的性能。相比于传统的单一教师蒸馏,多教师蒸馏可以利用不同教师网络的多样性和丰富性,从而获得更全面的知识传递。
在多教师蒸馏中,通常包括一个学生网络(Student Network)和多个教师网络(Teacher Networks)。每个教师网络都是一个独立的模型,具有不同的架构或参数初始化。学生网络通过同时学习多个教师网络的知识来提高自己的性能。
多教师蒸馏的核心思想是将不同教师网络的预测结果作为辅助目标来训练学生网络。具体而言,多教师蒸馏包括以下步骤:
-
教师网络的训练:针对不同的教师网络,使用标准的监督学习方法进行训练,以获得具有丰富知识的教师模型。
-
教师网络的预测:使用已训练好的教师网络对输入样本进行预测,得到多个教师网络的预测结果。
-
学生网络的训练:将教师网络的预测结果作为辅助目标,与真实标签一起用于训练学生网络。通过最小化学生网络的预测与教师网络预测之间的差异,将教师网络的知识传递给学生网络。
-
蒸馏损失函数的定义:通常使用交叉熵损失函数来衡量学生网络的分类性能。同时,为了传递教师网络的知识,可以定义额外的辅助目标损失,如平均软标签损失(Mean Soft Labels Loss)或特定的蒸馏损失函数。
通过多教师蒸馏,学生网络能够从多个教师网络中获得更丰富的知识,并综合各个教师网络的预测结果来提高自己的性能。多教师蒸馏可以增强模型的泛化能力,减少过拟合问题,并在复杂任务中取得更好的性能表现。
二、经典论文
这里只推荐一篇经典论文,Hinton 2015年的知识蒸馏开山之作,论文链接:https://arxiv.org/pdf/1503.02531.pdf
另外推荐几篇相关博客:
【经典简读】知识蒸馏(Knowledge Distillation) 经典之作 - 知乎
以上两章入门应该足矣,其实入门主要看看【经典必读】就行了,综述主要是为了有一个比较全面的了解。实践篇有缘再见吧。
其他经典论文:
中文综述:知识蒸馏研究综述 https://cjc.ict.ac.cn/online/bfpub/hzhxv-2022124104143.pdf
知识蒸馏资源库:https://github.com/FLHonker/Awe
学习笔记:
1.介绍
模型就像一个容器,训练数据中蕴含的知识就像是要装进容器里的水。当数据知识量(水量)超过模型所能建模的范围时(容器的容积),加再多的数据也不能提升效果(水再多也装不进容器),因为模型的表达空间有限(容器容积有限),就会造成underfitting;而当模型的参数量大于已有知识所需要的表达空间时(容积大于水量,水装不满容器),就会造成overfitting,即模型的variance会增大(想象一下摇晃半满的容器,里面水的形状是不稳定的)。
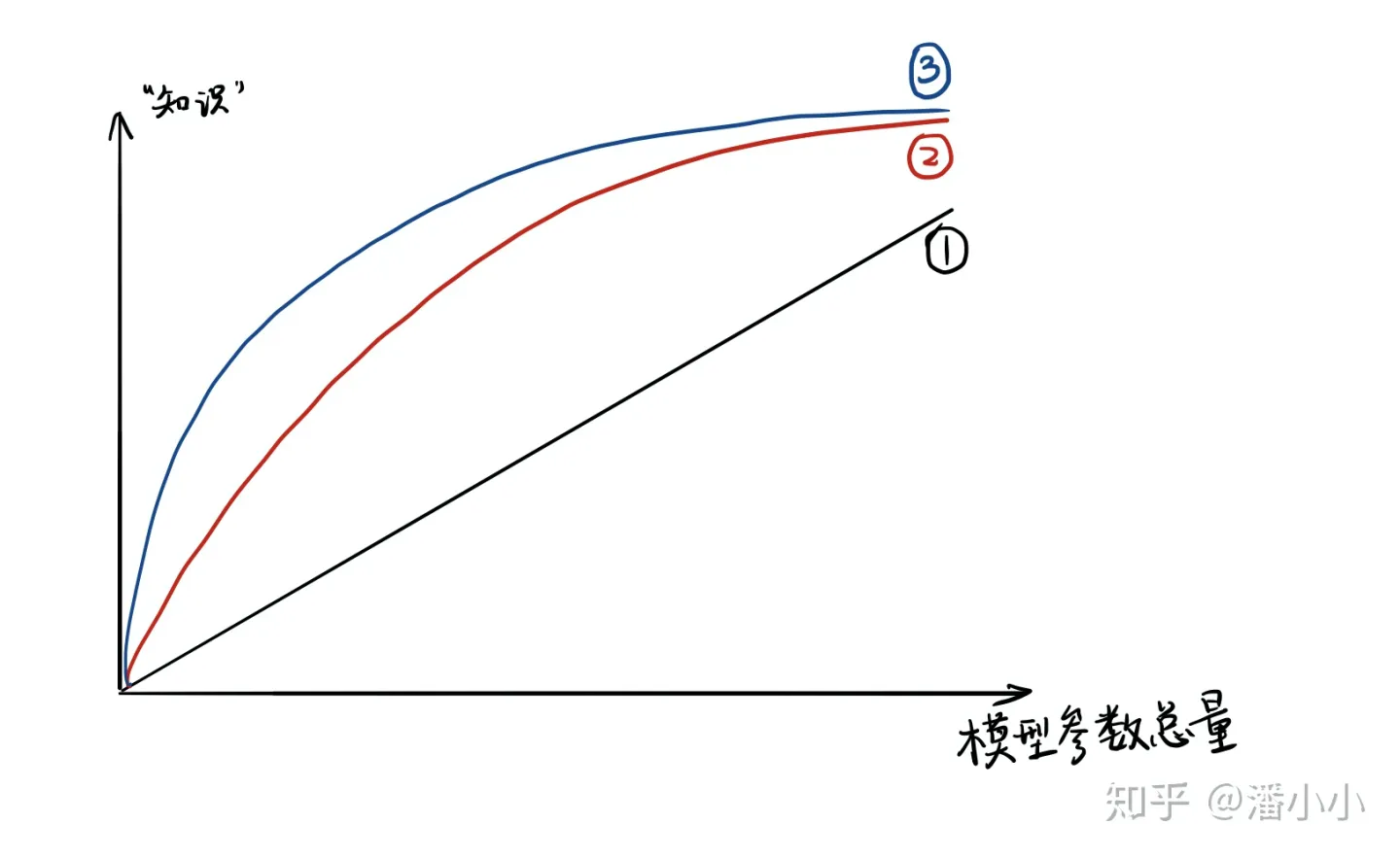
- 模型的参数量和其所能捕获的“知识“量之间并非稳定的线性关系(下图中的1),而是接近边际收益逐渐减少的一种增长曲线(下图中的2和3)
- 完全相同的模型架构和模型参数量,使用完全相同的训练数据,能捕获的“知识”量并不一定完全相同,另一个关键因素是训练的方法。合适的训练方法可以使得在模型参数总量比较小时,尽可能地获取到更多的“知识”(下图中的3与2曲线的对比).
2.知识蒸馏的理论依据
1.Teacher Model和Student Model
- 原始模型训练: 训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
在本论文中,作者将问题限定在分类问题下,或者其他本质上属于分类问题的问题,该类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。
2. 知识蒸馏的关键点
如果回归机器学习最最基础的理论,我们可以很清楚地意识到一点(而这一点往往在我们深入研究机器学习之后被忽略): 机器学习最根本的目的在于训练出在某个问题上泛化能力强的模型。
- 泛化能力强: 在某问题的所有数据上都能很好地反应输入和输出之间的关系,无论是训练数据,还是测试数据,还是任何属于该问题的未知数据。
而现实中,由于我们不可能收集到某问题的所有数据来作为训练数据,并且新数据总是在源源不断的产生,因此我们只能退而求其次,训练目标变成在已有的训练数据集上建模输入和输出之间的关系。由于训练数据集是对真实数据分布情况的采样,训练数据集上的最优解往往会多少偏离真正的最优解(这里的讨论不考虑模型容量)。
而在知识蒸馏时,由于我们已经有了一个泛化能力较强的Net-T,我们在利用Net-T来蒸馏训练Net-S时,可以直接让Net-S去学习Net-T的泛化能力。
一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“soft target”。
【KD的训练过程和传统的训练过程的对比】
- 传统training过程(hard targets): 对ground truth求极大似然
- KD的training过程(soft targets): 用large model的class probabilities作为soft targets
KD的训练过程为什么更有效?
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。
【举个例子】
在手写体数字识别任务MNIST中,输出类别有10个。

假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富。
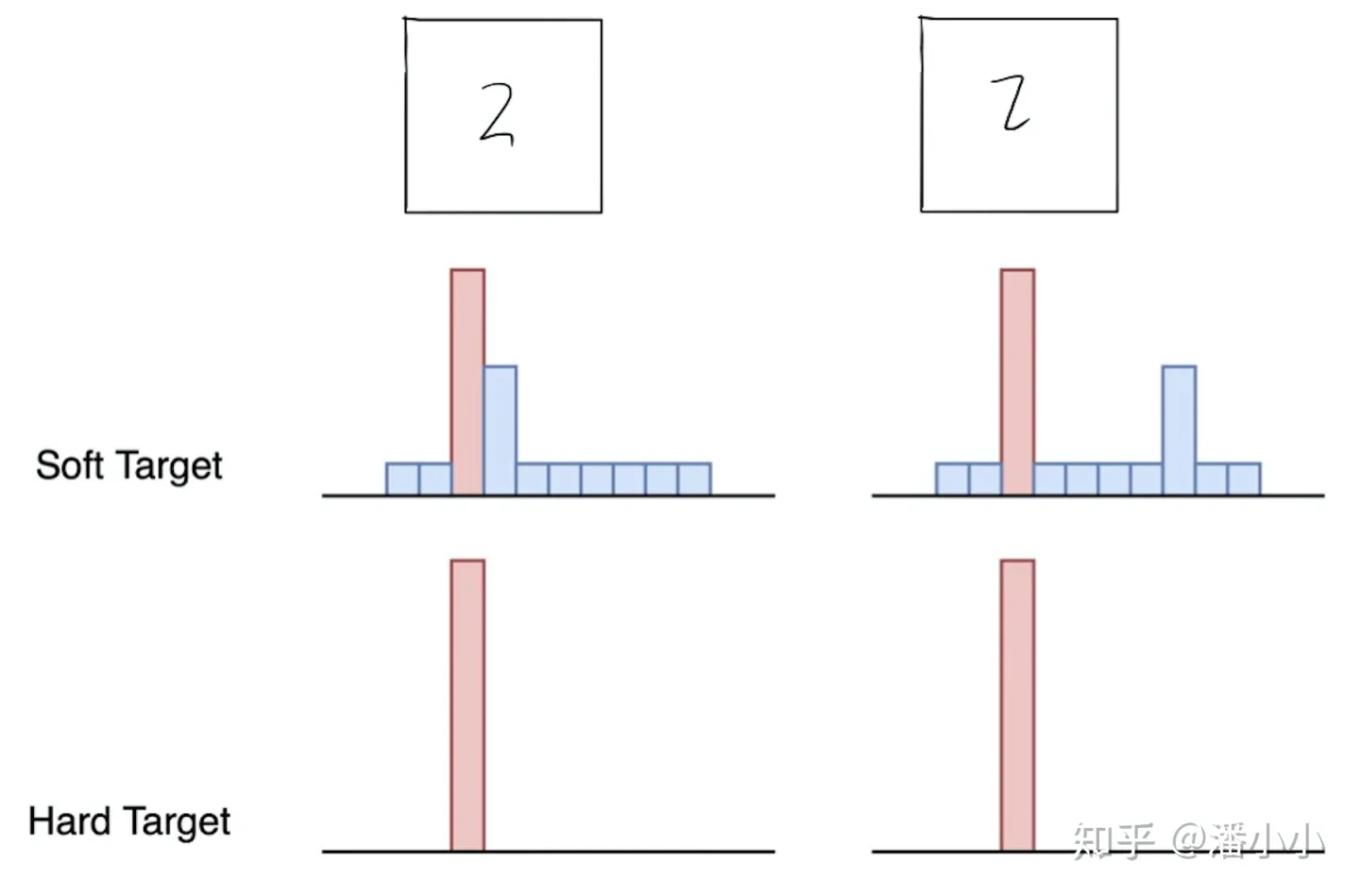
这就解释了为什么通过蒸馏的方法训练出的Net-S相比使用完全相同的模型结构和训练数据只使用hard target的训练方法得到的模型,拥有更好的泛化能力。
3.softmax函数

但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。
下面的公式时加了温度这个变量之后的softmax函数:
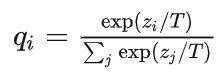
- 这里的T就是温度。
- 原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
4.知识蒸馏的具体方法
通用的知识蒸馏方法
第一步是训练Net-T;第二步是在高温T下,蒸馏Net-T的知识到Net-S
训练Net-T的过程很简单,下面详细讲讲第二步:高温蒸馏的过程。高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。示意图如上。

第二部分![]() 的必要性其实很好理解: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
的必要性其实很好理解: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
5.关于"温度"的讨论
【问题】 我们都知道“蒸馏”需要在高温下进行,那么这个“蒸馏”的温度代表了什么,又是如何选取合适的温度?
5.1温度的特点
在回答这个问题之前,先讨论一下温度T的特点

5.2温度代表了什么,如何选取合适的温度?
温度的高低改变的是Net-S训练过程中对负标签的关注程度: 温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Net-S会相对多地关注到负标签。
实际上,负标签中包含一定的信息,尤其是那些值显著高于平均值的负标签。但由于Net-T的训练过程决定了负标签部分比较noisy,并且负标签的值越低,其信息就越不可靠。因此温度的选取比较empirical,本质上就是在下面两件事之中取舍:
- 从有部分信息量的负标签中学习 --> 温度要高一些
- 防止受负标签中噪声的影响 -->温度要低一些
总的来说,T的选择和Net-S的大小有关,Net-S参数量比较小的时候,相对比较低的温度就可以了(因为参数量小的模型不能capture all knowledge,所以可以适当忽略掉一些负标签的信息)
三、代码
1.知识蒸馏动物园
知识蒸馏动物园,有助于掌握一些核心的知识蒸馏算法(一般表现为基于某种知识的损失函数)。
RepDistiller 比较清晰,这里有个相关的介绍博客知识蒸馏综述:代码整理.
2. KD: Knowledge Distillation
全称:Distilling the Knowledge in a Neural Network
链接:https://arxiv.org/pdf/1503.0253
发表:NIPS14
最经典的,也是明确提出知识蒸馏概念的工作,通过使用带温度的softmax函数来软化教师网络的逻辑层输出作为学生网络的监督信息,
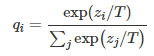
使用KL divergence来衡量学生网络与教师网络的差异,具体流程如下图所示(来自Knowledge Distillation A Survey)
kl散度:设P(X),Q(X)是随机变量X上的两个概率分布,则在离散和连续随机变量的情形下,相对熵的定义分别为
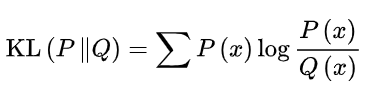
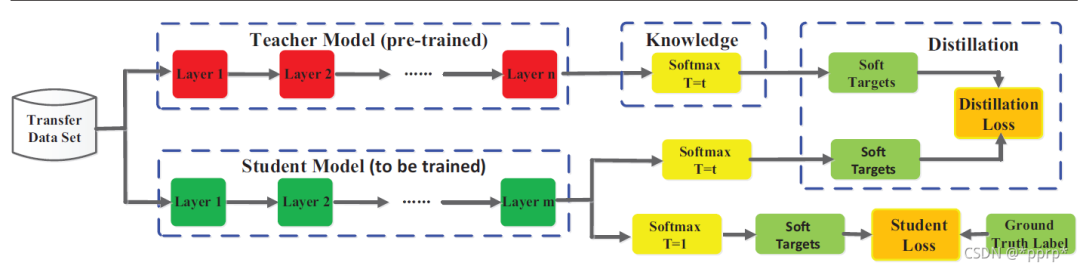
看上边这张图,其实并不难理解,就是用预训练好的模型(教师模型),去指导当前正在训练的模型(学生模型)进行训练,中间那个knowledge就是用一个softmax来放大差异嘛,最重要的部分就是那个权重T,那个就是代表“教师模型”指导“学生模型”的程度。
对学生网络来说,一部分监督信息来自hard label标签,另一部分来自教师网络提供的soft label。
代码实现:
class DistillKL(nn.Module):
"""Distilling the Knowledge in a Neural Network"""
def __init__(self, T):
super(DistillKL, self).__init__()
self.T = T#教师模型指导学生模型的程度,值越大,指导程度越高
def forward(self, y_s, y_t):
p_s = F.log_softmax(y_s/self.T, dim=1)
p_t = F.softmax(y_t/self.T, dim=1)
#下面就是对两个模型的预测值,做分布分析,如果偏差越大,则kl散度算出来的值越大。
#p_t表示教师模型的目标值
#p_s表示学生模型的预测值
loss = F.kl_div(p_s, p_t, size_average=False) * (self.T**2) / y_s.shape[0]
return loss
其实说白了,就是把预训练好的模型,当成标签,和正在训练的模型算loss。这就要求,你预训练好的模型,效果一定要好,才能去正确的指导正在训练的模型。
用别的loss function可不可以?
可以的,直接将T和loss相乘即可,因为你的T越大,loss越大,表示和教师模型差异越大,就需要向着教师模型的方向去学习
训练和测试代码解析
参考链接:https://github.com/search?q=Knowledge+Distillation
import os
import argparse
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
from models import *
from utils import progress_bar
import dataset
def __train_epoch(student_net, teacher_net, trainloader, device, criterion,
optimizer):
student_net.train()#设置学生网络为训练模式,以达到更新模型参数的目的
train_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)#将数据加载到gpu
pseudo_targets = teacher_net(inputs)#将数据输入到教师网络,得到教师的准确结果
#------------从这开始,下面是student的训练部分------------
#注意,zero_grad函数一定不要防在教师网前边!!!!
#一定按照现在代码的顺序来!!!!要不然,loss就会回传到教师网络
optimizer.zero_grad()
#输入学生网络
outputs = student_net(inputs)
#计算loss,随便用啥loss都可以,这里的target就是标签
#outputs是学生预测值,pseudo_targets是教师网络给的目标值
loss = criterion(outputs, pseudo_targets, targets)
loss.backward()
optimizer.step()
#---------------下边的不用管------------
train_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar(batch_idx,
len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)' %
(train_loss / (batch_idx + 1), 100. * correct / total,
correct, total))
def __test_epoch(student_net, testloader, device, criterion):
student_net.eval()
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
#在验证部分,就没有教师网络进行指导了,只靠学生自己去预测
inputs, targets = inputs.to(device), targets.to(device)
outputs = student_net(inputs)
loss = criterion(outputs, targets)
#下面的不用管,就只需要将loss累加,求平均后,给earlystopping就可以
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
progress_bar(batch_idx,
len(testloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)' %
(test_loss / (batch_idx + 1), 100. * correct / total,
correct, total))
# Save checkpoint.
acc = 100. * correct / total
精髓:先用大量的其他信息,其他模型,或者是其他的数据,anyway,都可以。目的就是为了使用这些信息,训练出一个好的teacher模型
然后再用teacher模型去和student模型算loss,并加上参数T控制指导的度,最后帮助学生模型提高训练效果
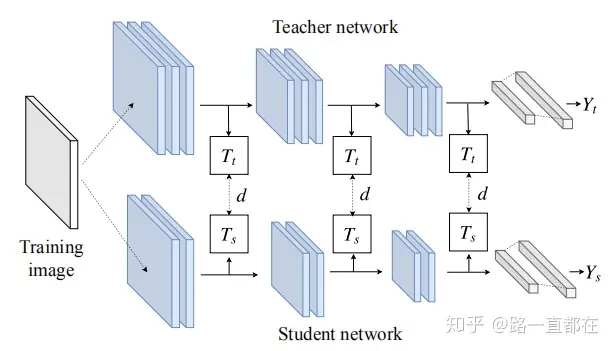
3. FitNet: Hints for thin deep nets
全称:Fitnets: hints for thin deep nets
code:https://github.com
发表:ICLR 15 Poster
本文旨在通过利用深度来解决网络压缩的问题,提出了一种新的方法来训练更窄以及更深的网络,称为FitNets。该方法受最近提出的知识蒸馏(KD)的启发,作者引入教师网络隐藏层的intermediate-level hints来引导学生网络的训练,即希望学生网络(FitNet)学习教师网络的中间层表示。
对中间层进行蒸馏的开山之作,通过将学生网络的feature map扩展到与教师网络的feature map相同尺寸以后,使用均方误差MSE Loss来衡量两者差异
1.Hint-Based Training思想
要想搞明白什么是Hint-Based Training,就需要先定义Hint和Guided。
- hint层与guided层:
- hint层:大模型的某一个选定的隐藏层
- hint:大模型hint层及其之前层的输出
- guided层:从小模型的某一个选定的隐藏层 我们在训练的第二阶段希望guided层能预测与hint层相近的输出
- 核心思想:
拓宽了知识的定义,知识不仅仅是大模型输入到输出的响应,也隐含在一些中间层的表达上
2.Fitnet训练过程及效果
1、FItnet训练过程可以分为三个阶段:
大模型训练、小模型预训练、小模型知识蒸馏
- 大模型训练: 同第一篇,用真实标签训练好大模型;随机初始化小模型
- 小模型预训练: 用教师的hint来预训练学生的guided layer及之前的层,使guided layer及其之前的层的输出与hint及其之前的层的输出相同。
- 小模型知识蒸馏: 使用经典的基于响应的知识整理对小模型继续训练
2、需要注意的问题:
- 要让小模型的guided层的输出学习大模型hint层的输出,由于卷积层大小不同,两者输出feature map大小不同(guided输出比hint大),因此需要再经过卷积保证guided层与hint层输出大小一致。
- hint来进行引导是一种正则化手段,学生guided层越深,那么正则化作用就越明显,为了避免过度正则化,需要仔细选择hint和guided层。
3、实现流程
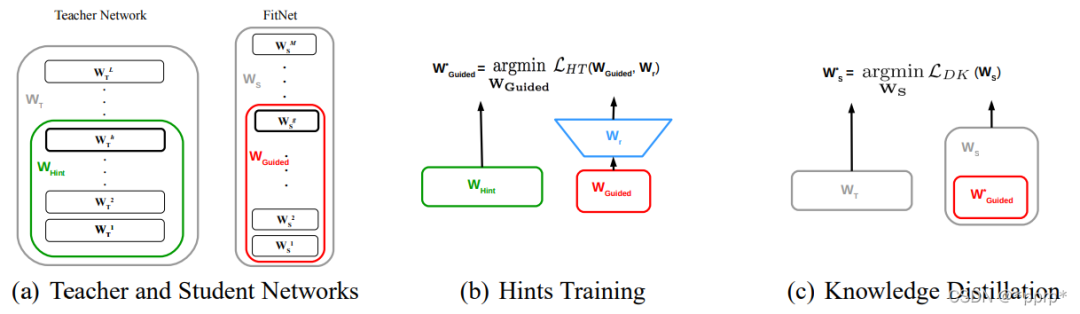
(1)大模型训练,小模型随机初始化
(2)将大模型特征提取器的第H层作为hint,从第一层到第H层的参数对应图(a)中Whint,,选择小模型特征提取器的第G层作为guided,从第一层到第G层对应图(a)中Wguided
(3)两者feature map大小可能不匹配,引入卷积层调整器(Wr)对guided层进行调整,对应图(b)
(4)优化均方损失函数![]()
(5)对预训练好的小模型进行进一步知识蒸馏,对应图(c)
4、损失函数
(1)预训练阶段:
Teacher网络的某一中间层的权值为Wt=Whint,Student网络的某一中间层的权值为Ws=Wguided。使用一个映射函数Wr来使得Wguided的维度匹配Whint,得到Ws。其中对于Wr的训练使用均方误差损失函数MSEloss:
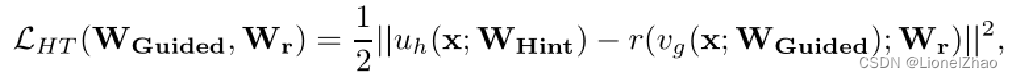
uh和vg是教师/学生的深度嵌套函数,直到他们各自的提示/引导层,带有参数WHint和WGuided,r是引导层顶部带有参数Wr的回归函数。请注意,这个和r的输出必须是可比的,即这个和r必须是相同的非线性。
(2)知识蒸馏阶段:
同上篇一样的交叉熵损失函数
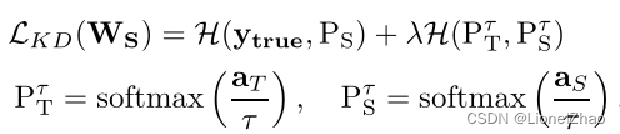
实现如下:
class HintLoss(nn.Module):
"""Fitnets: hints for thin deep nets, ICLR 2015
在这个类中,初始化函数中使用了nn.MSELoss(),即均方误差损失函数,
用于度量学生网络和教师网络之间的均方误差。"""
def __init__(self):
super(HintLoss, self).__init__()
self.crit = nn.MSELoss()
'''
在前向传播函数中,接收学生网络的中间层表示f_s和教师网络的中间层表示f_t作为输入。
然后使用均方误差损失函数计算它们之间的差异,得到"hint"损失。
'''
def forward(self, f_s, f_t):
loss = self.crit(f_s, f_t)
return loss实现核心就是MSELoss
5.Q&A
1、小模型模仿大模型中间层的输出feature map的大小还是内容?
小模型的guided及其之前的层经过Wr卷积层之后的结果去模仿大模型hint及其之前的层的feature map 两者feature map大小可能不匹配,引入卷积层调整器(Wr)对guided层进行调整,对应图(b);
Hint-Based Training所做的一切努力就是为了 使小模型guided层的feature map在经过Wr回归矩阵之后的内容与大模型hint层的feature map匹配,是大小和内容都模仿。
2、为什么小模型模仿大模型hint层及其之前的feature map可以提高训练效果?
fitnets模型提高了网络性能的影响因素之一:网络的深度
网络越深,非线性表达能力越强,可以学习更复杂的变换,从而可以拟合更复杂的特征,更深的网络可以更容易的学习复杂特征。
fitnets是深而窄的网络模型,在当时resnet、MRSA初始化、BN算法还未提出的情况下深层网络往往训练效果不好,而Hint-Based Training的提出利用了知识蒸馏有效训练了更深的神经网络,在参数比大模型更少的情况下利用了深度的优势达到的准确率甚至超过大模型。
4.AT: Attention Transfer
全称:Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
发表:ICLR16
为了提升学生模型性能提出使用注意力作为知识载体进行迁移,文中提到了两种注意力,一种是activation-based attention transfer,另一种是gradient-based attention transfer。实验发现第一种方法既简单效果又好。
1.背景
- 提出一种将注意力作为知识从一个网络转移到另一个
- 提出使用activation-based 和 gradient-based的空间注意力图
- 在多个数据集和深度网络结构(残差或非残差)验证了本文方法的性能提升
- activation-based注意力转移比full-activationtransfer更好,并且能与知识蒸馏(KD)结合
2.方法
1. Activation-based Attention Transfer
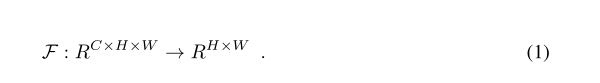
通过映射函数 F 将3D向量A∈R映射成扁平的2D向量(即空间注意力图)C为通道数。
为了定义这样一个空间注意力映射函数,我们在本节中做出的隐含假设是隐藏神经元激活的绝对值(在给定输入上评估网络时产生的结果)可以用作关于那个神经元具体输入。因此,通过考虑张量 A元素的绝对值,我们可以通过计算这些值在通道维度上的统计数据来构建空间注意力图(见图 3)。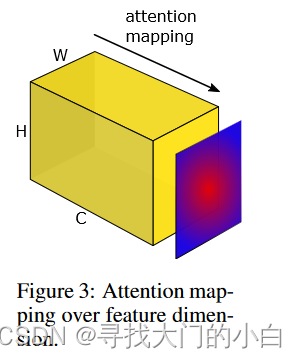
更具体地说,在这项工作中,我们将考虑以下基于激活的空间注意力图:
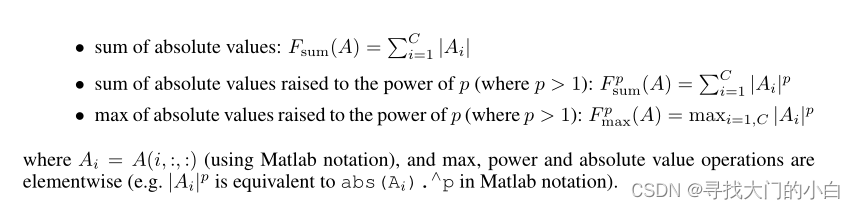
注意力图专注于网络中不同层的不同部分。在第一层中,低级梯度点的神经元激活水平较高,在中间,对于最具辨别力的区域(例如眼睛或车轮)较高,而在顶层,它反映了完整的对象。例如,为人脸识别训练的网络的中级注意力图 Parkhi et al. (2015)将在眼睛、鼻子和嘴唇周围有更高的激活,顶级激活将对应于全脸,如图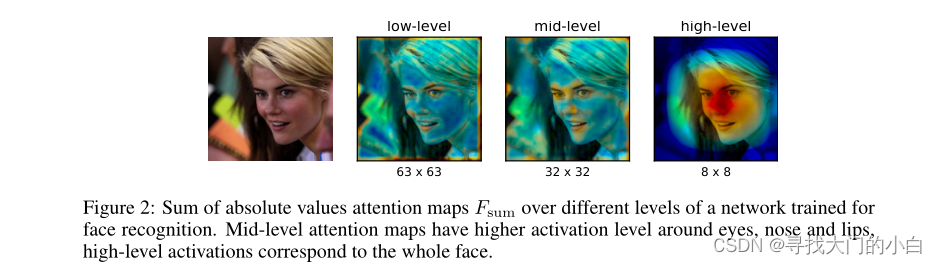
在注意力转移中,给定教师网络的空间注意力图(使用上述任何注意力映射函数计算),目标是训练一个学生网络,该网络不仅可以做出正确的预测,而且具有类似于老师的注意力图。例如,在 ResNet 架构的情况下,可以考虑以下两种情况,具体取决于教师和学生的深度:
相同深度:可能在每个残差块之后都有注意力转移层
不同深度:对每组残差块的输出激活进行注意力转移
2. Gradient-based Attention Transfer
我们将教师和学生输入的损失梯度定义为:![]()
然后,如果我们希望学生梯度注意力类似于教师注意力,我们可以最小化它们之间的距离(这里我们使用 l2 距离,但也可以使用其他距离):
![]()
由于给出了 WT 和 x,得到所需的导数 w.r.t。 WS:
![]()
我们还提出在梯度注意力图上强制水平翻转不变性。为此,我们传播水平翻转的图像以及初始图、反向传播和翻转梯度注意力图。然后我们在获得的注意力和输出上添加 l2 损失,并进行第二次反向传播:
实现如下:
![]()
其中 flip(x) 表示翻转操作。这类似于Group Equivariant CNN方法Cohen & Welling (2016) ,但这不是硬性约束。实验表明这对训练有正则化作用。
class Attention(nn.Module):
"""Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks
via Attention Transfer
code: https://github.com/szagoruyko/attention-transfer"""
def __init__(self, p=2):
super(Attention, self).__init__()
self.p = p
'''
在forward方法中,它接收学生网络(g_s)和教师网络(g_t)的特征图作为输入,
并返回每个特征图的Attention Loss。
'''
def forward(self, g_s, g_t):
return [self.at_loss(f_s, f_t) for f_s, f_t in zip(g_s, g_t)]
'''
at_loss方法用于计算单个特征图的Attention Loss。
首先,通过自适应平均池化操作将学生特征图(f_s)和教师特征图(f_t)的空间尺寸调整为相同的大小。
然后,计算两个特征图的注意力图之间的平方差,并取平均值作为Attention Loss。
'''
def at_loss(self, f_s, f_t):
s_H, t_H = f_s.shape[2], f_t.shape[2]
if s_H > t_H:
f_s = F.adaptive_avg_pool2d(f_s, (t_H, t_H))
elif s_H < t_H:
f_t = F.adaptive_avg_pool2d(f_t, (s_H, s_H))
else:
pass
return (self.at(f_s) - self.at(f_t)).pow(2).mean()
'''
at方法用于计算特征图的注意力图。它首先将特征图的每个像素值取幂(使用参数p),
然后对通道维度求平均,并归一化处理。
最终得到的注意力图是将特征图展平后的向量,形状为[batch_size, -1]。
'''
def at(self, f):
return F.normalize(f.pow(self.p).mean(1).view(f.size(0), -1))
'''
首先,将输入特征图 f 的每个元素取幂,即对特征图中的每个像素值进行指数运算,
指数的幂次为 self.p。这可以使用 f.pow(self.p) 实现。
接下来,对每个特征图的通道维度进行求平均操作,得到通道维度上的平均值。
这可以使用 mean(1) 实现,其中参数 1 表示在通道维度上进行求平均操作。
然后,将平均值得到的特征图展平为一维向量,即将其形状从 [batch_size, channel, height, width]
转换为 [batch_size, -1]。这可以使用 view(f.size(0), -1) 实现,
其中 f.size(0) 表示 batch_size,-1 表示自动推断展平后的长度。
最后,对展平后的特征向量进行归一化处理,即将其缩放到单位范数(L2范数为1)。
这可以使用 F.normalize() 函数实现,该函数会对输入向量的每个样本进行归一化处理。
'''首先使用avgpool将尺寸调整一致,然后使用MSE Loss来衡量两者差距。
5. SP: Similarity-Preserving
全称:Similarity-Preserving Knowledge Distillation
链接:https://arxiv.org/pdf/1907.0968
发表:ICCV19
1.背景
SP归属于基于关系的知识蒸馏方法。文章思想是提出相似性保留的知识,使得教师网络和学生网络会对相同的样本产生相似的激活。可以从下图看出处理流程,教师网络和学生网络对应feature map通过计算内积,得到bsxbs的相似度矩阵,然后使用均方误差来衡量两个相似度矩阵。
文中,我们提出了一种新的知识蒸馏形式,其灵感来自于观察到的语义相似的输入往往会在训练过的神经网络中引发相似的激活模式。保持相似的知识蒸馏指导学生网络的训练,这样,在受过训练的教师网络中产生相似(不相似)激活的输入对在学生网络中产生相似(不相似)激活。下入显示了整个过程。给定一个b个图像的输入小批,我们从输出激活映射计算成对的相似矩阵。b × b矩阵编码了网络激活的相似性,就像小批中的图像所诱发的那样。我们的蒸馏损失是由学生和老师产生的成对相似矩阵定义的。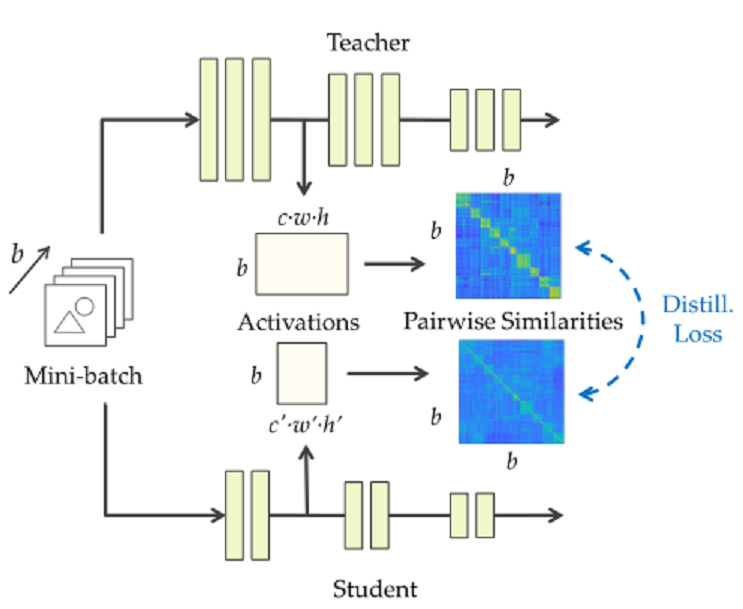
2.方法
在传统的知识蒸馏中,知识是以软化的类的分数的形式进行编码和传递的。训练学生的全部损失由以下部分构成:
![]()
其中![]() 表示为交叉熵损失函数,
表示为交叉熵损失函数,![]() 表示为softmax函数,Zs 和Zt表示模型的回归值,T为温度超参数。
表示为softmax函数,Zs 和Zt表示模型的回归值,T为温度超参数。
回顾介绍,语义相似的输入在经过训练的神经网络中往往会引发相似的激活模式。激活中的相关性是否可以编码有用的教师知识,从而传递给学生?我们的假设是,如果两个输入在教师网络中产生高度相似的激活,那么引导学生网络走向一个也会导致两个输入在学生网络中产生高度相似的激活的配置是有益的。相反,如果两个输入在老师体内产生不同的激活,我们希望这些输入在学生体内也产生不同的激活。
给定一个mini-batch的输入,我们使用![]() ,表示为老师网络T在第l层的激活输出,其中b表示为batch size,c为输出通道,h和w为空间的维度。同理,对于学生网络S来说,我们也可以使用
,表示为老师网络T在第l层的激活输出,其中b表示为batch size,c为输出通道,h和w为空间的维度。同理,对于学生网络S来说,我们也可以使用![]()
![]() 表示为第l ′ 层的激活输出。这里c不一定等于c ′,同理对于h , w也是。如果两个网络的深度相同,那么层l和l ′ 的深度也是一样的,如果深度不同,那么我们就使用同一个块的最后一层。为了引导学生像老师网络中的激活靠近,我们定义了一个蒸馏损失。首先,我们使用如下表示:
表示为第l ′ 层的激活输出。这里c不一定等于c ′,同理对于h , w也是。如果两个网络的深度相同,那么层l和l ′ 的深度也是一样的,如果深度不同,那么我们就使用同一个块的最后一层。为了引导学生像老师网络中的激活靠近,我们定义了一个蒸馏损失。首先,我们使用如下表示:![]()
其中![]() 是对
是对![]() 的维度转换,因此
的维度转换,因此![]() 是一个b × b的矩阵。可以发现,对于这个矩阵的第i行j列表示为第i张图片和第j张图片的相似度。之后使用L2正则化对每一行进行处理,同理,对于学生网络来说也是如此:
是一个b × b的矩阵。可以发现,对于这个矩阵的第i行j列表示为第i张图片和第j张图片的相似度。之后使用L2正则化对每一行进行处理,同理,对于学生网络来说也是如此:
![]()
之后我们就可以定义similarity-preserving knowledge loss:
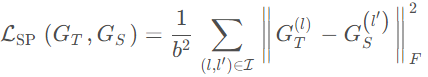
其中![]() 表示为两个网络中的每一对的层(就像上面讲的,深度一样的话就一一对应,不一样的话就按照块对应)。∣∣⋅∣∣ F 表示为Frobenius 标准化。最终,对于学生网络来说我们可以定义整个的损失:
表示为两个网络中的每一对的层(就像上面讲的,深度一样的话就一一对应,不一样的话就按照块对应)。∣∣⋅∣∣ F 表示为Frobenius 标准化。最终,对于学生网络来说我们可以定义整个的损失:
![]()
实现如下:
'''定义了一个名为"Similarity"的PyTorch模块,实现了ICCV2019论文中描述的相似性保持知识蒸馏方法。
该方法用于通过从教师模型(g_t)传递知识来训练学生模型(g_s),同时保持它们之间的中间表示的相似性。'''
class Similarity(nn.Module):
"""Similarity-Preserving Knowledge Distillation, ICCV2019, verified by original author"""
def __init__(self):
super(Similarity, self).__init__()
'''定义了一个名为"Similarity"的PyTorch模块,实现了ICCV2019论文中描述的相似性保持知识蒸馏方法。
该方法用于通过从教师模型(g_t)传递知识来训练学生模型(g_s),同时保持它们之间的中间表示的相似性。'''
def forward(self, g_s, g_t):
return [self.similarity_loss(f_s, f_t) for f_s, f_t in zip(g_s, g_t)]
'''相似性损失的计算在"similarity_loss"方法中进行。
首先,输入的特征图(f_s和f_t)被重塑为具有2D形状的张量,其中每一行表示一个样本。
然后,分别为每组特征图计算Gram矩阵(G_s和G_t),通过将矩阵与其转置相乘得到。
使用torch.nn.functional.normalize函数对Gram矩阵进行规范化。'''
def similarity_loss(self, f_s, f_t):
bsz = f_s.shape[0]
f_s = f_s.view(bsz, -1)
f_t = f_t.view(bsz, -1)
G_s = torch.mm(f_s, torch.t(f_s))
# G_s = G_s / G_s.norm(2)
G_s = torch.nn.functional.normalize(G_s)
G_t = torch.mm(f_t, torch.t(f_t))
# G_t = G_t / G_t.norm(2)
G_t = torch.nn.functional.normalize(G_t)
'''接下来,计算教师和学生Gram矩阵之间的差异(G_diff)。
最后,损失被计算为G_diff中相应元素的平方差的和,并通过批次大小(bsz)的平方进行归一化。'''
G_diff = G_t - G_s
loss = (G_diff * G_diff).view(-1, 1).sum(0) / (bsz * bsz)
return loss6.CC: Correlation Congruence
全称:Correlation Congruence for Knowledge Distillation
链接:https://arxiv.org/pdf/1904.01802.pdf
发表:ICCV19
1.背景
CC也归属于基于关系的知识蒸馏方法。不应该仅仅引导教师网络和学生网络单个样本向量之间的差异,还应该学习两个样本之间的相关性,而这个相关性使用的是Correlation Congruence 教师网络与学生网络相关性之间的欧氏距离。
- 提出相关一致性知识蒸馏(CCKD),它不仅关注实例一致性,而且关注相关一致性。(instance congruence通过mini-batch的PK或聚类实现。correlation congruence通过样本I,J直接的相关性损失函数的约束实现实现。)
- 将mini-batch中的相关性计算直接转成mini-batch的的大矩阵进行,减少计算量。
- 采用不同的mini-batch sampler strategies.
- 在CIFAR-100, ImageNet-1K, person reidentification and face recognition进行实验。
2.论文框架:

由图可知,CCKD由两个部分组成,实例一致性和相关一致性。其中,前者是指教师网络和学生网络预测结果的KL散度,后者是指教师网络和学生网络相关性的欧几里德距离。
3.方法
1.提取特征
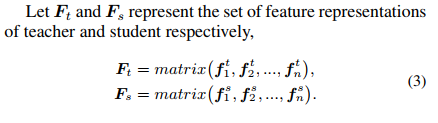
这里的f是网络的embedded feature space的一个点,即一个图像映射到embedded feature space的一个点,
2.映射embedding feature space
Cij表示的是xi和xj在embedding space的相关性

3.计算 correlation matrix
上面的fi函数可以用各种correlation关系来度量,引入下面的correlation congruence函数
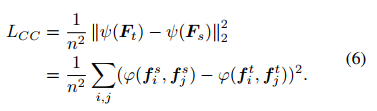
相关一致性:公式

Gaussian RBF is more flexible and powerful in capturing the complex non-linear relationship between instances.(论文最后采用高斯kernel计算相关性,但计算量真的很大。。)
整体Loss如下:
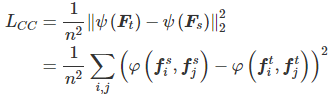
(比传统的KD多了一个相关一致性的损失函数约束)
![]()
实现如下:
class Correlation(nn.Module):
def __init__(self):
super(Correlation, self).__init__()
'''模块的前向传播方法接受两组特征图f_s和f_t作为输入,
并调用"similarity_loss"方法来计算它们之间的相似性损失。'''
def forward(self, f_s, f_t):
return self.similarity_loss(f_s, f_t)
'''相似性损失的计算在"similarity_loss"方法中进行。
首先,将输入的特征图f_s和f_t重新reshape为2D张量,其中每一行表示一个样本。
然后,分别计算f_s和f_t的Gram矩阵(G_s和G_t)通过将矩阵与其转置相乘得到。
接下来,对Gram矩阵进行L2范数归一化,即将每个元素除以L2范数。'''
def similarity_loss(self, f_s, f_t):
bsz = f_s.shape[0]
f_s = f_s.view(bsz, -1)
f_t = f_t.view(bsz, -1)
G_s = torch.mm(f_s, torch.t(f_s))
G_s = G_s / G_s.norm(2)
G_t = torch.mm(f_t, torch.t(f_t))
G_t = G_t / G_t.norm(2)
'''然后,计算教师和学生Gram矩阵之间的差异(G_diff)。
最后,损失计算为G_diff中相应元素的平方差的和,除以批次大小(bsz * bsz)。'''
G_diff = G_t - G_s
loss = (G_diff * G_diff).view(-1, 1).sum(0) / (bsz * bsz)
return loss7.VID: Variational Information Distillation
全称:Variational Information Distillation for Knowledge Transfer
链接:https://arxiv.org/pdf/1904.05835.pdf
code:https://github.com/qiu931110/RepDistiller
发表:CVPR19
1.背景
在本文中,我们提出了变分信息蒸馏(VID)作为一个朝着这个方向的尝试,在这个方向上,我们将知识转移表述为教师和学生网络之间相互信息的最大化。该框架为知识转移提出了一个可操作的目标,并允许我们量化从教师网络向学生网络转移的信息量。由于互信息难以计算,我们采用变分信息最大化[1]方案来最大化变分下界。所提出的知识转移方法的概念图如图1所示。我们进一步证明了几种现有的知识转移方法可以通过选择不同形式的变分下界作为我们框架的具体实现。
最终整个蒸馏过程如下图所示,学生网络除了学习自身任务的交叉熵损失外,同时与教师网络保持高互信息(MI),通过学习并估计教师网络中的分布,激发知识的传递,使相互信息最大化'
总的来说,本文贡献如下:
- 在变分信息最大化的基础上,提出了一种基于变分信息最大化的知识转移框架——变分信息蒸馏VID。
- 我们证明VID概括了几种现有的知识转移方法。此外,在各种知识转移实验中,包括在同一数据集或不同数据集上的(异构)dnn之间的知识转移,我们的框架的实施在经验上优于最先进的知识转移方法。
- 最后,我们证明了在cifar10上卷积神经网络(CNN)和多层感知器(MLP)之间的异构知识转移是可能的。我们的方法生成的学生MLP显著优于文献中报道最好的MLP。
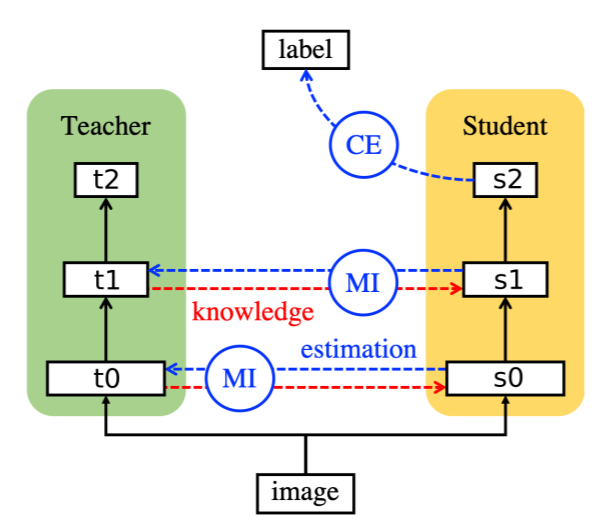
利用互信息(Mutual Information)来衡量学生网络和教师网络差异。互信息可以表示出两个变量的互相依赖程度,其值越大,表示变量之间的依赖程度越高。互信息计算如下:
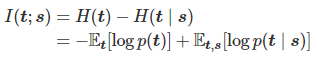
互信息是教师模型的熵减去在已知学生模型条件下教师模型的熵。目标是最大化互信息,因为互信息越大说明H(t|s)越小,即学生网络确定的情况下,教师网络的熵会变小,证明学生网络已经学习的比较充分。
整体loss如下:
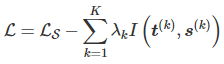
由于p(t|s)很难计算,可以使用变分分布q(t|s)去接近真实分布。上述公式中的大于等于操作用到了KL散度的非负性。由于蒸馏过程中H(t)和需要学习的学生模型参数无关,因此最大化互信息就转换为最大化可变高斯分布的问题。
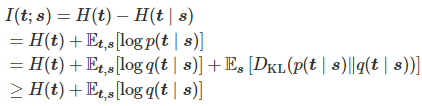
其中q(t|s)是使用方差可学习的高斯分布模拟(公式中的log_scale):
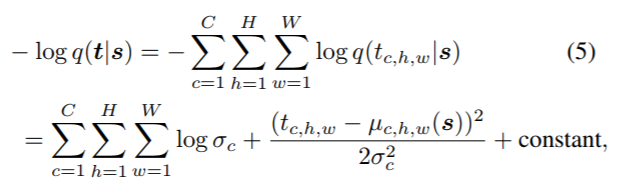
并利用如下公式构建可学习的方差,其中阿尔法c是可学习参数。
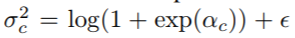
实现如下:
class VIDLoss(nn.Module):
"""Variational Information Distillation for Knowledge Transfer (CVPR 2019),
code from author: https://github.com/ssahn0215/variational-information-distillation"""
def __init__(self,
num_input_channels,
num_mid_channel,
num_target_channels,
init_pred_var=5.0,
eps=1e-5):
super(VIDLoss, self).__init__()
#在模块的初始化方法中,首先定义了一个辅助函数"conv1x1",用于创建1x1卷积层。
def conv1x1(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels, out_channels,
kernel_size=1, padding=0,
bias=False, stride=stride)
'''通过堆叠卷积层和ReLU激活函数构建了一个回归器(self.regressor),
用于从输入特征图中提取预测的中间表示。回归器的结构是1x1卷积层,
ReLU,1x1卷积层,ReLU,和1x1卷积层。'''
self.regressor = nn.Sequential(
conv1x1(num_input_channels, num_mid_channel),
nn.ReLU(),
conv1x1(num_mid_channel, num_mid_channel),
nn.ReLU(),
conv1x1(num_mid_channel, num_target_channels),
)
'''模块还定义了一个对数标度参数self.log_scale,它被用于控制预测方差的初始值。
初始的预测方差通过对初始值应用指数函数和对数函数计算得到,
并使用torch.nn.Parameter转换为可训练的模型参数。'''
self.log_scale = torch.nn.Parameter(
np.log(np.exp(init_pred_var-eps)-1.0) * torch.ones(num_target_channels)
)
self.eps = eps
'''在前向传播方法中,首先对输入和目标进行自适应平均池化,以使它们的空间尺寸匹配。
然后,通过回归器对输入进行预测,得到预测的均值(pred_mean)。
接下来,预测的方差(pred_var)通过对self.log_scale应用指数函数、加上一个小的正数eps,
以及调整维度后得到。'''
def forward(self, input, target):
# pool for dimentsion match
s_H, t_H = input.shape[2], target.shape[2]
if s_H > t_H:
input = F.adaptive_avg_pool2d(input, (t_H, t_H))
elif s_H < t_H:
target = F.adaptive_avg_pool2d(target, (s_H, s_H))
else:
pass
pred_mean = self.regressor(input)
pred_var = torch.log(1.0+torch.exp(self.log_scale))+self.eps
pred_var = pred_var.view(1, -1, 1, 1)
'''负对数概率(neg_log_prob)通过计算均方差项和对数项得到。
最后,计算平均损失(loss),并返回它作为结果。'''
neg_log_prob = 0.5*(
(pred_mean-target)**2/pred_var+torch.log(pred_var)
)
loss = torch.mean(neg_log_prob)
return loss8.RKD: Relation Knowledge Distillation
全称:Relational Knowledge Disitllation
code:https://github.com/lenscloth/RKD
链接:http://arxiv.org/pdf/1904.0506
发表:CVPR19
RKD也是基于关系的知识蒸馏方法,RKD提出了两种损失函数,二阶的距离损失和三阶的角度损失。
1.核心思想
作者提出迁移样本间的关系(结构信息)会优于迁移单个样本的特征。例如:两个样本间的距离,三个样本间的角度。传统KD和Relational KD的对比如下。

2.方法
之前蒸馏算法可为训练学生模拟由老师表示的只考虑单个数据示例的输出激活的算法。本论文提出的算法关系知识蒸馏(RKD)迁移教师模型得到的输出结果间的结构化关系给学生模型,不同于之前的只关注个体输出结果。本文的RKD算法使用两种损失函数:二阶的距离损失(distance-wise)和三阶的角度损失(angle-wise)。
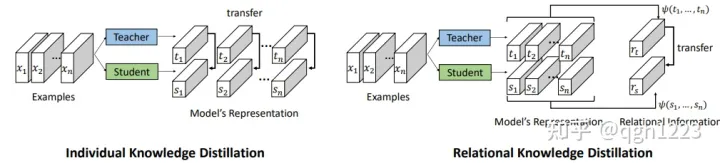
分为样本间距离损失和样本间角度损失两个部分。
![]()
2.1.样本间距离损失
![]() 用于计算样本特征图间的距离。Distance-wise损失函数用于在匹配两个样本间距离上教师模型和学生模型的差异。论文中需要对距离进行正则化处理在训练中更稳定和快速的收敛。这里损失函数选择huber损失函数。
用于计算样本特征图间的距离。Distance-wise损失函数用于在匹配两个样本间距离上教师模型和学生模型的差异。论文中需要对距离进行正则化处理在训练中更稳定和快速的收敛。这里损失函数选择huber损失函数。
样本间距离损失L为![]()
其中,fai为样本特征图间的距离![]()
损失函数采用的是Huber函数。它基本上是绝对值,在误差很小时会变为平方值。

2.2.样本间角度损失
角度损失用于计算三个样本间的距离,可以通过角度差异迁移教师模型和学生模型对应训练样本特征图。同样使用huber损失函数
样本间角度损失L为![]()
角度通过三个特征值计算,利用三个点任意构造两条线,得到两个方向向量并归一化,fai为两个单位方向向量e的夹角。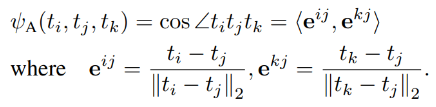
2.3. Training Process
RKD算法训练的总损失函数包括特定任务的损失函数和蒸馏的损失函数。
![]()
其中,![]() 表示与target的目标损失,
表示与target的目标损失,![]() 为蒸馏损失,
为蒸馏损失,![]() 为调节超参数
为调节超参数
实现如下:
class RKDLoss(nn.Module):
"""Relational Knowledge Disitllation, CVPR2019"""
#在模块的初始化方法中,定义了两个权重参数w_d和w_a,用于控制距离损失和角度损失的权重。
def __init__(self, w_d=25, w_a=50):
super(RKDLoss, self).__init__()
self.w_d = w_d
self.w_a = w_a
#模块的前向传播方法接受两组特征图f_s和f_t作为输入,并计算关系知识蒸馏的损失。
#首先,将学生特征图f_s和教师特征图f_t转换为2D张量,其中每一行表示一个样本。
def forward(self, f_s, f_t):
student = f_s.view(f_s.shape[0], -1)
teacher = f_t.view(f_t.shape[0], -1)
# RKD distance loss # RKD 距离损失
with torch.no_grad():
# 老师特征图各行向量之间的欧氏距离矩阵,并归一化
t_d = self.pdist(teacher, squared=False)
mean_td = t_d[t_d > 0].mean()
t_d = t_d / mean_td
# 学生特征图各行向量之间的欧氏距离矩阵,并归一化
d = self.pdist(student, squared=False)
mean_d = d[d > 0].mean()
d = d / mean_d
# 代码实现中实际才用的是smooth_l1_loss函数,与论文中有出入
loss_d = F.smooth_l1_loss(d, t_d)
# RKD Angle loss## RKD 角度损失
with torch.no_grad():
# 获取单位方向向量
'''通过对教师网络特征进行扩展(unsqueeze)操作,
得到形状为[1, num_samples, feature_dim]的教师特征张量(teacher.unsqueeze(0))
和形状为[num_samples, 1, feature_dim]的教师特征张量(teacher.unsqueeze(1))。
然后,计算两个张量之间的差异(td),即每个样本与其他样本之间的差异。'''
td = (teacher.unsqueeze(0) - teacher.unsqueeze(1))
'''接下来,使用torch.norm函数对差异张量(td)进行归一化(F.normalize(td, p=2, dim=2)),
以获得单位方向向量(norm_td)。这里使用的p=2表示使用L2范数进行归一化,
即将向量除以其L2范数,使其长度为1。'''
norm_td = F.normalize(td, p=2, dim=2)
'''然后,通过torch.bmm函数计算教师特征的角度相似度(t_angle)。
具体而言,首先将单位方向向量(norm_td)与其转置相乘,
得到形状为[num_samples, num_samples]的相似度矩阵,然后通过.view(-1)将其展平为一维张量。'''
t_angle = torch.bmm(norm_td, norm_td.transpose(1, 2)).view(-1)
# 获取单位方向向量
sd = (student.unsqueeze(0) - student.unsqueeze(1))
norm_sd = F.normalize(sd, p=2, dim=2)
s_angle = torch.bmm(norm_sd, norm_sd.transpose(1, 2)).view(-1)
loss_a = F.smooth_l1_loss(s_angle, t_angle)
#首先,将学生特征图f_s和教师特征图f_t转换为2D张量,其中每一行表示一个样本。
loss = self.w_d * loss_d + self.w_a * loss_a
return loss
@staticmethod
def pdist(e, squared=False, eps=1e-12):
'''
计算e各行向量之间的欧式距离
例如:
input: [[a11,a12],[a21,a12]]
output: [[0, d12],[d21, 0]]
if squared: d12 = d21 = (a21-a11)^2+(a22-a12)^2
else: d12 = d21 = sqrt((a21-a11)^2+(a22-a12)^2)
首先,将学生特征图f_s和教师特征图f_t转换为2D张量,其中每一行表示一个样本。
'''
e_square = e.pow(2).sum(dim=1)
prod = e @ e.t()
res = (e_square.unsqueeze(1) + e_square.unsqueeze(0) - 2 * prod).clamp(min=eps)
if not squared:
res = res.sqrt()
res = res.clone()
res[range(len(e)), range(len(e))] = 0
return res9.PKT:Probabilistic Knowledge Transfer
全称:Probabilistic Knowledge Transfer for deep representation learning
链接:https://arxiv.org/abs/1803.10837
发表:CoRR18
作者主要采用概率知识转移的思想:在学生模型中特征向量的分布应该与在老师模型特征向量的分布近似。
贡献
本文的主要贡献是提出了一种概率KT(PKT)技术,该技术通过匹配特征空间中数据的概率分布而不是其实际表示,克服了现有KT方法的一些局限性,如图1所示。据我们所知,所提出的技术是第一种能够
- a)执行跨模式知识转移,
- b)将知识从手工制作的特征提取程序转移到神经网络,
- c)转移知识而不考虑手头的任务(例如,目标检测),
- d)将领域知识纳入知识转移程序,提供对知识转移的新见解。
该方法的动机是匹配教师和学生模型的概率密度函数,在数据样本的特征表示和一组(可能未知)标签注释之间保持教师的二次互信息(QMI)
损失函数
可以采用的核函数有:
文中作者采用的是cos核函数。老师和学生模型的条件概率分布为:


总的损失为学生和老师概率的散度之和:
![]()
class PKT(nn.Module):
"""Probabilistic Knowledge Transfer for deep representation learning
Code from author: https://github.com/passalis/probabilistic_kt"""
def __init__(self):
super(PKT, self).__init__()
#模块的前向传播方法接受两组特征向量f_s和f_t作为输入,并计算它们之间的余弦相似性损失。
def forward(self, f_s, f_t):
return self.cosine_similarity_loss(f_s, f_t)
'''
静态方法cosine_similarity_loss用于计算余弦相似性损失。
首先,对每个向量进行归一化处理,将其除以其范数。使用torch.sqrt计算向量的范数,
并添加一个很小的正数eps以避免除以零。然后,将NaN值(由于归一化后的零向量)设置为0。
接下来,计算输出网络和目标网络之间的余弦相似性。使用torch.mm计算矩阵的乘积,
其中output_net和target_net分别是归一化后的输出网络和目标网络。
将余弦相似性缩放到0到1之间,将相似性加1后除以2。
然后,将相似性转换为概率。通过除以每行的和,将相似性值归一化为概率值。
最后,计算KL散度(KL-divergence)。使用torch.log计算对数,
并使用torch.mean计算均值。KL散度衡量目标概率分布与模型概率分布之间的差异。
'''
@staticmethod
def cosine_similarity_loss(output_net, target_net, eps=0.0000001):
# Normalize each vector by its norm
output_net_norm = torch.sqrt(torch.sum(output_net ** 2, dim=1, keepdim=True))
output_net = output_net / (output_net_norm + eps)
output_net[output_net != output_net] = 0
target_net_norm = torch.sqrt(torch.sum(target_net ** 2, dim=1, keepdim=True))
target_net = target_net / (target_net_norm + eps)
target_net[target_net != target_net] = 0
# Calculate the cosine similarity
model_similarity = torch.mm(output_net, output_net.transpose(0, 1))
target_similarity = torch.mm(target_net, target_net.transpose(0, 1))
# Scale cosine similarity to 0..1
model_similarity = (model_similarity + 1.0) / 2.0
target_similarity = (target_similarity + 1.0) / 2.0
# Transform them into probabilities
model_similarity = model_similarity / torch.sum(model_similarity, dim=1, keepdim=True)
target_similarity = target_similarity / torch.sum(target_similarity, dim=1, keepdim=True)
# Calculate the KL-divergence
loss = torch.mean(target_similarity * torch.log((target_similarity + eps) / (model_similarity + eps)))
return loss10.AB: Activation Boundaries(没看明白)
全称:Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
code:
链接:https://arxiv.org/pdf/1811.0323
发表:AAAI18
目标:让学生网络层的神经元的激活边界尽量和教师网络的一样。所谓的激活边界指的是分离超平面(针对的是RELU这种激活函数),其决定了神经元的激活与失活。AB提出的激活转移损失,让教师网络与学生网络之间的分离边界尽可能一致。
定义: 教师网络到最后隐藏层的函数T,相应学生为S(在激活函数之前)。为了方便,先假设教师学生最后隐藏层具有相同尺寸大小为RM。
针对图片I,相应有T(I),S(I) ∈ RM。
以前使用的损失函数中如下(1):

其中激活函数σ(x)=max(0,x)。
产生的问题: 之前的损失函数使学生仅仅近似老师的神经元反应,但结果的激活边界可能有很大的不同。尤其是不好区分弱反应和0反应。

为了准确地转移激活边界,我们的想法是放大在激活边界附近区域的可忽略的转移损失。为了放大损失,我们定义了一个元素激活指示器函数来表示:

图1的下半部分显示了使用激活转移损失的知识转移。虽然神经元反应的大小没有很好地传递,但它被训练以保持教师神经元的激活。因此,激活边界被准确地传递。考虑到激活边界在神经网络中的重要性,激活传递损失在知识传递中比均方误差更有效。
由于ρ()是一个离散函数,激活转移损失不能通过梯度下降最小化。因此,我们提出了一个可被梯度下降最小化的替代损失。
最小化激活转移损失类似于学习二值分类器。
如果教师神经元是活跃的则学生神经元的反应应大于0;如果教师神经元是不活跃的,则小于0。借鉴了hinge loss:

1).当老师和学生的最后尺寸不一致时,添加联通函数r:

2).卷积网络同样适用。

实现如下:
class ABLoss(nn.Module):
"""Knowledge Transfer via Distillation of Activation Boundaries Formed by Hidden Neurons
code: https://github.com/bhheo/AB_distillation
"""
'''
在模块的初始化方法中,接受两个参数:feat_num和margin。feat_num表示特征数量,margin表示边界的间隔。
模块根据特征数量计算了一组权重值self.w,用于加权不同特征的损失。
'''
def __init__(self, feat_num, margin=1.0):
super(ABLoss, self).__init__()
self.w = [2**(i-feat_num+1) for i in range(feat_num)]
self.margin = margin
'''
模块的前向传播方法接受学生模型和教师模型的特征图g_s和g_t作为输入,并计算激活边界蒸馏的损失。
'''
def forward(self, g_s, g_t):
#首先,获取学生特征图的批次大小bsz。然后,使用zip函数将学生特征图和教师特征图进行逐对处理。
bsz = g_s[0].shape[0]
#在forward方法中,使用criterion_alternative_l2方法计算每对特征图的损失。
#然后,将损失乘以对应的权重值self.w,以加权不同特征的损失。
losses = [self.criterion_alternative_l2(s, t) for s, t in zip(g_s, g_t)]
losses = [w * l for w, l in zip(self.w, losses)]
#接下来,将损失进行标准化处理。首先,将损失除以批次大小bsz。然后,将损失乘以系数1/1000 * 3。
# loss = sum(losses) / bsz
# loss = loss / 1000 * 3
losses = [l / bsz for l in losses]
losses = [l / 1000 * 3 for l in losses]
return losses
'''
criterion_alternative_l2方法用于计算替代的L2损失。该方法根据边界self.margin和激活值的符号差异计算损失。
当源激活值source大于边界并且目标激活值target小于等于零时,损失为(source + self.margin) **
2。当源激活值小于等于边界并且目标激活值大于零时,损失为(source - self.margin) ** 2。
最后,计算损失的绝对值之和。
'''
def criterion_alternative_l2(self, source, target):
loss = ((source + self.margin) ** 2 * ((source > -self.margin) & (target <= 0)).float() +
(source - self.margin) ** 2 * ((source <= self.margin) & (target > 0)).float())
return torch.abs(loss).sum()11.FT: Factor Transfer
全称:Paraphrasing Complex Network: Network Compression via Factor Transfer
链接:https://arxiv.org/pdf/1802.04977.pdf
发表:NIPS18
提出的是factor transfer的方法。所谓的factor,其实是对模型最后的数据结果进行一个编解码的过程,提取出的一个factor矩阵,用教师网络的factor来指导学生网络的factor。
该文提出了一种对教师网络进行知识转移的新方法,由两个神经网络模块完成的,即解释器和翻译器。解释器以无监督的方式对教师网络进行训练,位于学生网络中的翻译器则用于模仿教师网络解释器信息。这两个辅助装置实际上是谋求构造两个网络的共享特征空间
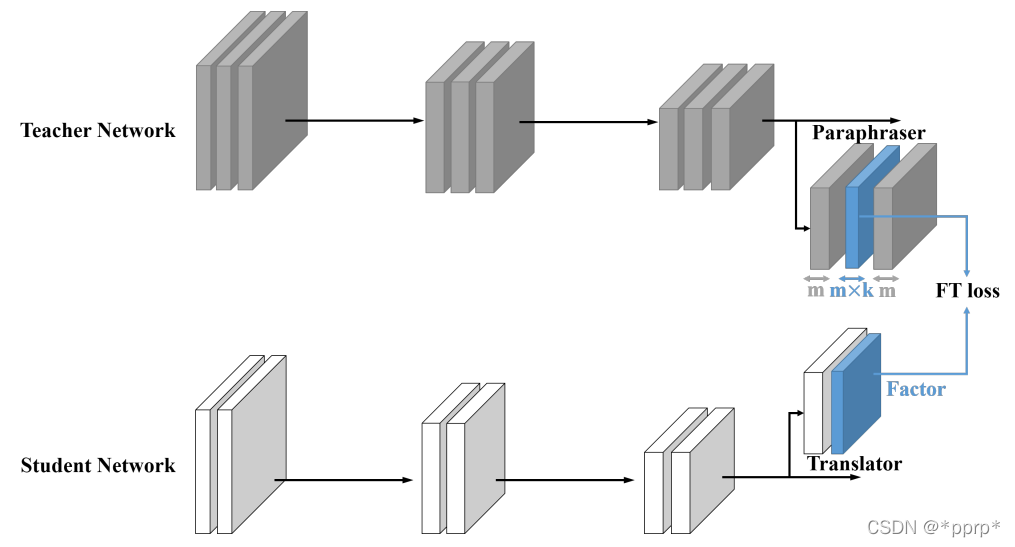
如上图,为了使教师的知识变得易于学生接受,设计了基于Autoencoder的结构命名为Paraphraser,现将m通道的特征图转变为m*k的更为紧凑的表征,然后再恢复回原始的size。训练好教师的paraphraser后再训练学生网络。
蒸馏过程的损失函数如下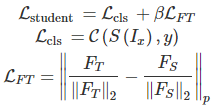
像注意力蒸馏一样,本文也对蓝色的部分(论文称为Factor)进行L2归一化,计算损失时采用L1Loss。
class FactorTransfer(nn.Module):
"""Paraphrasing Complex Network: Network Compression via Factor Transfer, NeurIPS 2018"""
#在模块的初始化方法中,接受两个参数p1和p2。p1和p2是用于计算因子的指数参数。
def __init__(self, p1=2, p2=1):
super(FactorTransfer, self).__init__()
self.p1 = p1
self.p2 = p2
#模块的前向传播方法接受学生模型和教师模型的特征图f_s和f_t作为输入,并计算因子转移的损失。
def forward(self, f_s, f_t):
return self.factor_loss(f_s, f_t)
'''
首先,获取学生特征图f_s和教师特征图f_t的高度s_H和t_H。
根据它们的高度进行自适应平均池化,使它们的高度匹配。
'''
def factor_loss(self, f_s, f_t):
s_H, t_H = f_s.shape[2], f_t.shape[2]
if s_H > t_H:
f_s = F.adaptive_avg_pool2d(f_s, (t_H, t_H))
elif s_H < t_H:
f_t = F.adaptive_avg_pool2d(f_t, (s_H, s_H))
else:
pass
'''
然后,根据p2的值计算因子转移的损失。
如果p2等于1,返回f_s的因子与f_t的因子的绝对值之差的均值。
如果p2不等于1,返回f_s的因子与f_t的因子的差的p2次方的均值。
'''
if self.p2 == 1:
return (self.factor(f_s) - self.factor(f_t)).abs().mean()
else:
return (self.factor(f_s) - self.factor(f_t)).pow(self.p2).mean()
'''
因子的计算在factor方法中进行。首先,计算f的p1次方的平均值。
然后,对每个样本,使用F.normalize函数对平均值进行归一化处理。
最后,将结果重塑为形状为(f.size(0), -1)的张量。
'''
def factor(self, f):
return F.normalize(f.pow(self.p1).mean(1).view(f.size(0), -1))12.FSP: Flow of Solution Procedure
全称:A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
链接:https://openaccess.thecvf.com/content_cvpr_2017/papers/Yim_A_Gift_From_CVPR_2017_paper.pdf
code:https://github.com/HobbitLong/RepDistiller/blob/master/distiller_zoo/FSP.py
发表:CVPR17
FSP认为教学生网络不同层输出的feature之间的关系比教学生网络结果好
1.背景
深度神经网络DNN逐层生成特征。更高层的特征更接近于任务的有用特征。如果我们把DNN的输入看作问题,把输出看作答案,我们就可以把DNN中间生成的特征看作是求解过程中的中间结果。根据这一想法,FitNets可以让学生网络简单地模拟教师网络的中间结果。然而在DNN中,有许多方法或途径来解决从输入生成输出的问题。因此,模拟教师网络生成的特征对学生网络来说是一个硬约束hard constraint。就人而言,老师解释问题的解决过程,学生学习解决问题的流程。当输入特定的问题时,学生网络不一定需要学习中间输出,但当遇到特定类型的问题时,学生网络可以学习这一类问题的通用解决方法。因此作者认为,对于知识蒸馏中的教师网络,演示问题的解决过程比演示中间结果具有更好的泛化性。
2.创新点
本文将神经网络中层与层之间的信息流动定义为需要蒸馏的知识,并通过计算两个特征层之间的内积来得到这种知识。当将这种层之间的流动作为知识传递给学生网络时,作者通过实验得到了三个结论:
- 从教师网络学习这种蒸馏知识的学生网络比原始网络的优化(收敛)速度快得多。
- 学习这种蒸馏知识的学生网络比原始网络的性能更好。
- 即使教师网络是在一个不同的任务或数据集上训练得到的,学生网络也可以从教师网络中学习到这种知识,并且比从头训练的效果更好。
下图是本文提出的知识蒸馏方法的概念图

本文的贡献如下:
- 提出了一种知识蒸馏的新方法。
- 这种知识对于快速优化非常有用。
- 利用所提出的蒸馏知识定义网络的初始权重可以提高小模型的性能。
- 即使学生网络接受了与教师网络不同的训练任务,所提出的蒸馏知识也能提高学生网络的表现。
3.方法介绍
作者设计了网络中两个相邻层之间的FSP(flow of solution procedure)矩阵来表示问题的求解过程,对于挑选的层1输出的feature map表示为![]() ,其中h,w,m分别表示特征图的高、宽、通道数。层2表示为
,其中h,w,m分别表示特征图的高、宽、通道数。层2表示为![]() ,则FSP矩阵
,则FSP矩阵![]() 可通过下式求得
可通过下式求得

其中 x表示输入图片,W表示网络权重参数。
对于残差网络,网络在一些位置的spatial size发生变化,我们选择教师网络和学生网络对应位置具有相同spatial size的特征图来生成FSP matrix,下图是一个示例

计算教师网络和学生网络对应FSP矩阵的L2损失,完整是损失函数如下

其中 λi表示每一对FSP矩阵损失的权重,文中设定所有层计算的FSP之间的损失权重相等。
N表示所有的采样点。
4.代码解析
forward函数的输入g_s和g_t分别表示学生网络和教师网络中所有用来计算FSP矩阵的层,在compute_fsp中每一层都与相邻层计算fsp矩阵,注意这里的相邻并不是说在原始网络中这两层的相邻的。这里相邻层之间计算fsp矩阵需要保证spatial size相等,如果不相等通过自适应平均池化使之相等。
from __future__ import print_function
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
class FSP(nn.Module):
"""A Gift from Knowledge Distillation:
Fast Optimization, Network Minimization and Transfer Learning"""
'''
在模块的初始化方法中,接受两个参数s_shapes和t_shapes,
它们分别表示学生模型和教师模型中各个特征图的形状。
确保学生和教师模型中特征图数量一致,并且通道数也一致,否则会引发错误。
'''
def __init__(self, s_shapes, t_shapes):
super(FSP, self).__init__()
assert len(s_shapes) == len(t_shapes), 'unequal length of feat list'
s_c = [s[1] for s in s_shapes]
t_c = [t[1] for t in t_shapes]
if np.any(np.asarray(s_c) != np.asarray(t_c)):
raise ValueError('num of channels not equal (error in FSP)')
#在模块的前向传播方法中,首先计算学生模型和教师模型特征图之间的FSP损失。
#FSP损失是通过计算特征图之间的点积和均方差来衡量特征的一致性。
def forward(self, g_s, g_t):
# [(64,32,32,32),(64,64,32,32),(64,128,16,16),(64,256,8,8)]
# [(64,32,32,32),(64,64,32,32),(64,128,16,16),(64,256,8,8)]
s_fsp = self.compute_fsp(g_s)
t_fsp = self.compute_fsp(g_t)
loss_group = [self.compute_loss(s, t) for s, t in zip(s_fsp, t_fsp)]
return loss_group
@staticmethod
#compute_loss方法用于计算FSP损失。它计算FSP特征的均方差损失。
def compute_loss(s, t):
return (s - t).pow(2).mean()
'''
compute_fsp方法用于计算FSP特征。它迭代处理每一对特征图(bot, top)。
首先,通过自适应平均池化将bot和top的高度调整为相同的值
然后,将bot和top扩展为4D张量,并根据维度重新调整它们的形状。
接下来,计算两个特征图的点积,并在最后一个维度上取平均值,得到FSP特征。
将每个层的FSP特征添加到fsp_list列表中
'''
@staticmethod
def compute_fsp(g):
fsp_list = []
for i in range(len(g) - 1):
bot, top = g[i], g[i + 1] # (64,32,32,32),(64,64,32,32)
b_H, t_H = bot.shape[2], top.shape[2]
if b_H > t_H:
bot = F.adaptive_avg_pool2d(bot, (t_H, t_H))
elif b_H < t_H:
top = F.adaptive_avg_pool2d(top, (b_H, b_H))
else:
pass
bot = bot.unsqueeze(1) # (64,1,32,32,32)
top = top.unsqueeze(2) # (64,64,1,32,32)
bot = bot.view(bot.shape[0], bot.shape[1], bot.shape[2], -1) # (64,1,32,1024)
top = top.view(top.shape[0], top.shape[1], top.shape[2], -1) # (64,64,1,1024)
fsp = (bot * top).mean(-1) # (64,64,32,1024)->(64,64,32)
fsp_list.append(fsp)
return fsp_list
13.NST: Neuron Selectivity Transfer
全称:Like what you like: knowledge distill via neuron selectivity transfer
code:mdistiller/mdistiller/distillers/NST.py at master · megvii-research/mdistiller · GitHub
链接:https://arxiv.org/pdf/1707.01219.pdf
发表:CoRR17
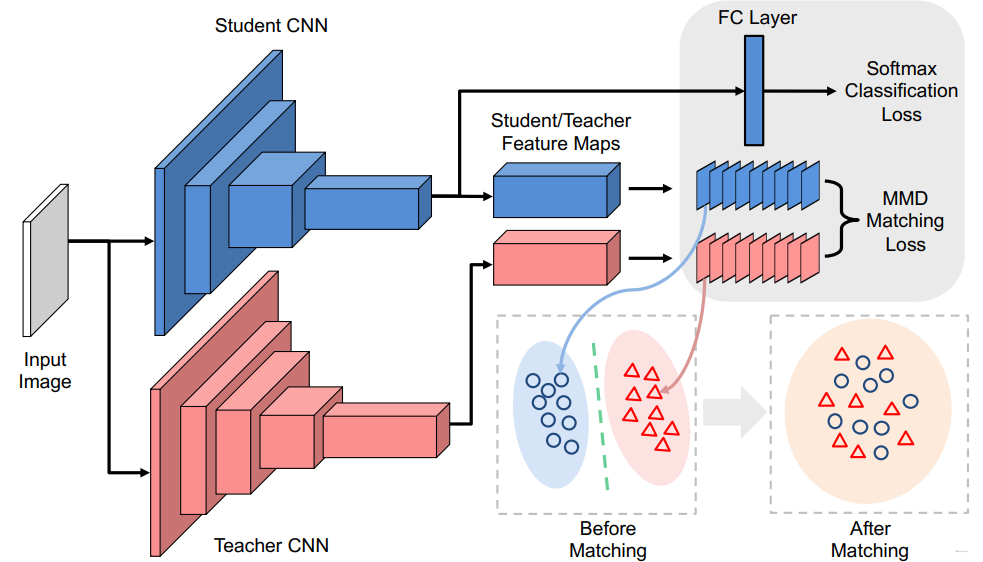
使用新的损失函数最小化教师网络与学生网络之间的Maximum Mean Discrepancy(MMD), 文中选择的是对其教师网络与学生网络之间神经元选择样式的分布。
1.创新点
本文探索了一种新型的知识 - 神经元的选择性知识,并将其传递给学生模型。这个模型背后的直觉相当简单:每个神经元本质上从原始输入提取与特定任务相关的某种模式,因此,如果一个神经元在某些区域或样本中被激活,这意味着这些区域或样本共享一些与该任务相关的特性。这种聚类知识对学生模型非常有价值,因为它为教室模型的最终预测结果提供了一种解释。因此,作者提出对齐教师模型和学生模型神经元选择模式的分布。
2.背景
假定教师模型和学生模型都是卷积神经网络,并将教师模型表示为T ,学生模型表示为S 。CNN中某一层的输出特征图表示为 ![]() , C表示通道,H*W表示空间尺寸。F的每一行(每个通道的特征图)表示为
, C表示通道,H*W表示空间尺寸。F的每一行(每个通道的特征图)表示为![]() , F的每一列(一个位置中的所有激活)表示为
, F的每一列(一个位置中的所有激活)表示为![]() 。 FT和FS分别表示教师模型和学生模型中某一层的特征图,不失一般性,我们假设FT和FS的大小相等,如果不相等则可以通过插值使它们相等。
。 FT和FS分别表示教师模型和学生模型中某一层的特征图,不失一般性,我们假设FT和FS的大小相等,如果不相等则可以通过插值使它们相等。
Maximum Mean Discrepancy
最大平均差异(Maximum Mean Discrepancy,MMD)可以看作是一种概率分布间的距离度量,基于从它们采样的样本。假设我们有两组分别从分布p 和 q中采样的样本 ![]() 和
和 ![]() ,那么p 和 q之间的MMD距离的平方如下
,那么p 和 q之间的MMD距离的平方如下
其中![]() 是一个显式映射函数,通过进一步扩展并应用核技巧(kernel trick),式(1)可以表示为
是一个显式映射函数,通过进一步扩展并应用核技巧(kernel trick),式(1)可以表示为

其中k(,)是一个核函数,它将样本向量投射到一个更高维或是无限维的特征空间中。
最小化MMD等价于最小化p 和 q之间的距离。
3.方法介绍
Motivation
下面是两张叠加了热力图(heat map)的图片,其中热力图是根据VGG16 Conv5_3中的某个神经元得到的。从图中很容易看出这两个神经元具有很强的选择性:左图的神经元对猴子的脸部非常敏感,右侧的神经元对字符非常敏感。这种激活实际上意味着神经元的选择性,即什么样的输入可以触发这些神经元。换句话说,一个神经元高激活的区域可能共享一些与任务相关的相似特性,尽管这些特性可能对于人类没有非常直观的解释。

为了捕获这些相似特性,在学生模型中也应该有神经元模仿这些激活模式。因此本文提出了一种新的知识类型:神经元选择性(neuron selectivities)或者叫做共激活(co-activations),并将其传递给学生模型。
Formulation
每个通道的特征图 ![]() 示特定神经元的选择性知识,我们定义神经元选择性迁移损失(NST损失)如下
示特定神经元的选择性知识,我们定义神经元选择性迁移损失(NST损失)如下
其中 H是交叉熵损失, Ytrue是ground truth标签, 是PS学生模型的输出概率
MMD损失可以扩展如下

其中用![]() 替代了
替代了![]() ,确保每个样本具有相同的比例。最小化MMD损失就等价于将神经元的选择性知识传递给学生模型。
,确保每个样本具有相同的比例。最小化MMD损失就等价于将神经元的选择性知识传递给学生模型。
Choice of Kernels
本文选用以下三种核函数

对于多项式核,我们设置d=2,c=0.对于高斯核,将![]() 设置为对应得平方距离的均值。
设置为对应得平方距离的均值。
实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from ._base import Distiller
'''
在代码中,定义了nst_loss函数用于计算NST损失。
它接受学生模型和教师模型的特征图作为输入,
通过归一化和多项式核函数计算特征图之间的相似度损失
'''
def nst_loss(g_s, g_t):
return sum([single_stage_nst_loss(f_s, f_t) for f_s, f_t in zip(g_s, g_t)])
'''
single_stage_nst_loss函数用于计算单个阶段的NST损失。
它首先将特征图的高度进行自适应平均池化,使得学生和教师特征图的尺寸相同。
然后,将特征图重塑为2D张量,并进行归一化。
接下来,计算特征图之间的多项式核函数相似度,并返回损失值。
'''
def single_stage_nst_loss(f_s, f_t):
s_H, t_H = f_s.shape[2], f_t.shape[2]
if s_H > t_H:
f_s = F.adaptive_avg_pool2d(f_s, (t_H, t_H))
elif s_H < t_H:
f_t = F.adaptive_avg_pool2d(f_t, (s_H, s_H))
f_s = f_s.view(f_s.shape[0], f_s.shape[1], -1) # (64,64,32,32)->(64,64,1024)
f_s = F.normalize(f_s, dim=2)
f_t = f_t.view(f_t.shape[0], f_t.shape[1], -1)
f_t = F.normalize(f_t, dim=2)
return (
poly_kernel(f_t, f_t).mean().detach()
+ poly_kernel(f_s, f_s).mean()
- 2 * poly_kernel(f_s, f_t).mean()
)
'''
poly_kernel函数用于计算多项式核函数。
它将特征图扩展为4D张量,并计算点积后进行平方操作。
'''
def poly_kernel(a, b):
a = a.unsqueeze(1) # (64,64,1024)->(64,1,64,1024)
b = b.unsqueeze(2) # (64,64,1024)->(64,64,1,1024)
res = (a * b).sum(-1).pow(2) # (64,64,64,1024)->(64,64,64)
return res
'''
NST类继承自Distiller类,用于实现模型的训练过程。
在训练过程中,通过学生模型和教师模型对输入图像进行前向传播,
得到学生模型的输出和特征图。
同时,通过教师模型对输入图像进行前向传播,得到教师模型的特征图。
'''
class NST(Distiller):
"""
Like What You Like: Knowledge Distill via Neuron Selectivity Transfer
"""
def __init__(self, student, teacher, cfg):
super(NST, self).__init__(student, teacher)
self.ce_loss_weight = cfg.NST.LOSS.CE_WEIGHT
self.feat_loss_weight = cfg.NST.LOSS.FEAT_WEIGHT
def forward_train(self, image, target, **kwargs):
logits_student, feature_student = self.student(image) # (64,3,32,32)
with torch.no_grad():
_, feature_teacher = self.teacher(image)
'''
然后,计算交叉熵损失和特征损失。
交叉熵损失用于测量学生模型输出与目标标签之间的差异。
特征损失通过调用nst_loss函数计算学生特征图与教师特征图之间的相似度损失。
'''
# losses
loss_ce = self.ce_loss_weight * F.cross_entropy(logits_student, target)
loss_feat = self.feat_loss_weight * nst_loss(
feature_student["feats"][1:], feature_teacher["feats"][1:]
# [torch.Size([64, 64, 32, 32]), torch.Size([64, 128, 16, 16]), torch.Size([64, 256, 8, 8])]
# [torch.Size([64, 64, 32, 32]), torch.Size([64, 128, 16, 16]), torch.Size([64, 256, 8, 8])]
)
#最后,返回学生模型的输出和损失字典。
losses_dict = {
"loss_ce": loss_ce,
"loss_kd": loss_feat,
}
return logits_student, losses_dict
14.CRD: Contrastive Representation Distillation
全称:Contrastive Representation Distillation
code:https://github.com/HobbitLong/RepDistiller
链接:https://arxiv.org/abs/1910.1069
发表:ICLR20
将对比学习引入知识蒸馏中,其目标修正为:学习一个表征,让正样本对的教师网络与学生网络尽可能接近,负样本对教师网络与学生网络尽可能远离。
Contrastive Representation Distillation(对比表示蒸馏)是一种知识蒸馏方法,旨在通过学习教师模型和学生模型之间的对比表示来提高学生模型的表示能力和泛化能力。
该方法的核心思想源于对比学习(Contrastive Learning)的概念,其中模型被训练来将相同样本的表示聚集在一起,并将不同样本的表示分开。Contrastive Representation Distillation 基于此思想,将对比学习的原理应用于知识蒸馏。
Contrastive Representation Distillation 的步骤如下:
-
教师模型的特征提取:首先,利用教师模型将输入样本映射到特征空间中,获得教师模型的特征表示。
-
对比表示构建:使用一对一的对比方式,从教师模型的特征表示中随机选择两个不同的样本,同时选择一个正样本和一个负样本。正样本来自于同一类别,而负样本来自于不同类别。构建正样本和负样本对比的表示。
-
学生模型训练:学生模型以对比表示作为目标,通过最小化教师模型的对比表示与学生模型的对比表示之间的差异来训练。学生模型通过逐渐逼近教师模型的对比表示,从而学习到教师模型的知识和表示能力。
通过对比表示的训练目标,Contrastive Representation Distillation 帮助学生模型学习到更具区分性和鲁棒性的特征表示。它可以通过对不同类别和同一类别样本之间的关系进行建模,从而提高学生模型在分类、检测等任务中的性能。
构建的对比学习问题表示如下:
整体的蒸馏Loss表示如下:
![]()
实现如下:
class ContrastLoss(nn.Module):
"""
contrastive loss, corresponding to Eq (18)
构造函数中接收参数 n_data,表示训练集中的样本数量。
forward 方法接收输入 x,代表对比表示。它计算对比损失,具体步骤如下:
获取输入 x 的维度信息,包括批大小 bsz 和对比维度 m。
计算噪声分布 Pn,即每个负样本的概率。
计算正样本对应的损失,使用 P_pos 和公式 log(D1) = log(P_pos / (P_pos + m * Pn))。
计算负样本对应的损失,使用 P_neg 和公式 log(D0) = log((m * Pn) / (P_neg + m * Pn))。
将正负样本损失相加并除以 bsz,得到最终的损失。
"""
def __init__(self, n_data):
super(ContrastLoss, self).__init__()
self.n_data = n_data
def forward(self, x):
bsz = x.shape[0]
m = x.size(1) - 1
# noise distribution
Pn = 1 / float(self.n_data)
# loss for positive pair
P_pos = x.select(1, 0)
log_D1 = torch.div(P_pos, P_pos.add(m * Pn + eps)).log_()
# loss for K negative pair
P_neg = x.narrow(1, 1, m)
log_D0 = torch.div(P_neg.clone().fill_(m * Pn), P_neg.add(m * Pn + eps)).log_()
loss = - (log_D1.sum(0) + log_D0.view(-1, 1).sum(0)) / bsz
return loss
class CRDLoss(nn.Module):
"""CRD Loss function
includes two symmetric parts:
(a) using teacher as anchor, choose positive and negatives over the student side
(b) using student as anchor, choose positive and negatives over the teacher side
Args:
opt.s_dim: the dimension of student's feature
opt.t_dim: the dimension of teacher's feature
opt.feat_dim: the dimension of the projection space
opt.nce_k: number of negatives paired with each positive
opt.nce_t: the temperature
opt.nce_m: the momentum for updating the memory buffer
opt.n_data: the number of samples in the training set, therefor the memory buffer is: opt.n_data x opt.feat_dim
构造函数中接收参数 opt,包含了学生模型和教师模型的维度信息,以及对比表示的相关参数。
初始化了 Embed 类的实例 embed_s 和 embed_t,用于将学生和教师特征映射到投影空间中。
初始化了 ContrastMemory 类的实例 contrast,用于保存对比表示的记忆库。
初始化了 ContrastLoss 类的实例 criterion_s 和 criterion_t,用于计算学生和教师对比损失。
forward 方法接收学生特征 f_s、教师特征 f_t、样本索引 idx 和对比索引 contrast_idx(可选)。
通过 embed_s 和 embed_t 将特征映射到投影空间。
使用 contrast 对象计算学生和教师的对比表示。
使用 criterion_s 和 criterion_t 计算学生和教师的对比损失。
将学生和教师对比损失相加,得到最终的损失。
"""
def __init__(self, opt):
super(CRDLoss, self).__init__()
self.embed_s = Embed(opt.s_dim, opt.feat_dim)
self.embed_t = Embed(opt.t_dim, opt.feat_dim)
self.contrast = ContrastMemory(opt.feat_dim, opt.n_data, opt.nce_k, opt.nce_t, opt.nce_m)
self.criterion_t = ContrastLoss(opt.n_data)
self.criterion_s = ContrastLoss(opt.n_data)
def forward(self, f_s, f_t, idx, contrast_idx=None):
"""
Args:
f_s: the feature of student network, size [batch_size, s_dim]
f_t: the feature of teacher network, size [batch_size, t_dim]
idx: the indices of these positive samples in the dataset, size [batch_size]
contrast_idx: the indices of negative samples, size [batch_size, nce_k]
Returns:
The contrastive loss
"""
f_s = self.embed_s(f_s)
f_t = self.embed_t(f_t)
out_s, out_t = self.contrast(f_s, f_t, idx, contrast_idx)
s_loss = self.criterion_s(out_s)
t_loss = self.criterion_t(out_t)
loss = s_loss + t_loss
return loss
15. Overhaul
全称:A Comprehensive Overhaul of Feature Distillation
链接:http://openaccess.thecvf.com/content_ICCV_2019/papers/
code:跳转中...
发表:CVPR19
1.背景
本文研究了知识蒸馏的各个方面,并提出了一种新的特征蒸馏方法,使蒸馏损失在教师特征变换、学生特征变换、特征蒸馏位置、距离函数各方面之间协同作用。具体来说,本文提出的蒸馏损失包括一个新设计的margin relu特征变换方法、一个新的蒸馏位置、以及一个partial L2距离函数。在ImageNet中,本文提出的方法使得ResNet-50取得了21.65%的top-1 error,优于教师网络ResNet-152的精度。
常规特征蒸馏的过程:
如下图, ![]() 表示教师网络的特征,
表示教师网络的特征, ![]() 表示学生网络的特征,
表示学生网络的特征, ![]() 和
和 ![]() 分别代表教师网络和学生网络的特征转移形式, d 表示转化后特征的距离,被用来作为蒸馏的损失函数,用公式可以表示为:
分别代表教师网络和学生网络的特征转移形式, d 表示转化后特征的距离,被用来作为蒸馏的损失函数,用公式可以表示为:
![]()
通过最小化上述蒸馏损失来训练学生网络。
蒸馏损失函数的设计十分关键,必须不能遗漏教师网络的所有重要特征信息,为了进一步提升蒸馏表现,本文设计了全新的特征蒸馏损失,确保教师网络的所有重要特征都尽可能的进行迁移。主要从四个方面进行考虑:
- 教师网络转换(Teacher transform)
教师网络的转换![]() 将隐藏特征转换成容易迁移的特征形式。这是特征蒸馏中非常重要的部分也是蒸馏过程中特征信息损失的主要原因。此前提出的一些方法,将教师网络的高维特征信息进行降维处理,造成了严重的信息损失,还有的方法引入了压缩率或者以二值化的形式表征原始特征,造成特征信息的变形,与原始信息有很大的差异。由于教师网络特征既包括不利的信息,也包括有益的信息,因此区分它们并避免遗漏有益的信息是很重要的。
将隐藏特征转换成容易迁移的特征形式。这是特征蒸馏中非常重要的部分也是蒸馏过程中特征信息损失的主要原因。此前提出的一些方法,将教师网络的高维特征信息进行降维处理,造成了严重的信息损失,还有的方法引入了压缩率或者以二值化的形式表征原始特征,造成特征信息的变形,与原始信息有很大的差异。由于教师网络特征既包括不利的信息,也包括有益的信息,因此区分它们并避免遗漏有益的信息是很重要的。
本文利用了一个新的ReLU激活函数,margin ReLU,通过这个激活函数,有益的特征信息不经过任何变换直接保留,而无用的特征信息被抑制,通过这样的设置,能够最大限度的保留有益的特征信息。
- 学生网络转换(Student transform)
通常来说,学生网络的转换 ![]() 利用与
利用与![]() 相同的形式,因此会造成与
相同的形式,因此会造成与 ![]() 类似的不足即有益特征信息的丢失。由于教师网络的特征维度通常较高,因此学生网络通常需要通过1x1卷积进行升维来进行维度匹配,在这种情况下,学生网络的特征维度不仅不会降低还会增加,这种教师网络和学生网络间非对称式的转换方式更有利于有益信息保存。
类似的不足即有益特征信息的丢失。由于教师网络的特征维度通常较高,因此学生网络通常需要通过1x1卷积进行升维来进行维度匹配,在这种情况下,学生网络的特征维度不仅不会降低还会增加,这种教师网络和学生网络间非对称式的转换方式更有利于有益信息保存。
- 特征蒸馏位置(Distillation feature position)
除了转换方式之外,在网络结构中的哪些位置进行蒸馏同样需要细心设计。在FitNets上用任意中间层的末端作为蒸馏点,提升有限。这里需要跟margin ReLU一起考虑,在margin ReLU中,有益特征信息被保留而无用特征信息被抑制,因此,蒸馏必须在激活函数之前进行,在本文中,作者设计了在ReLU之前的蒸馏损失函数,称为pre-ReLU。所有的特征值和位置信息都会被保存在pre-ReLU中,不会发生改变。
- 距离度量函数(Distance function)
大多数的蒸馏方法采用L1或者L2函数进行距离度量。但是在本文提出的方法中,需要根据新提出的教师网络转换方式,蒸馏位置等设计引入一个适合的距离度量。所有特征值的转移都可能对学生网络产生不利影响。为了解决这个问题,提出了一个新的距离函数,称为局部L2距离,它被设计用来跳过在无用区域上提取到的特征信息。
2.方法
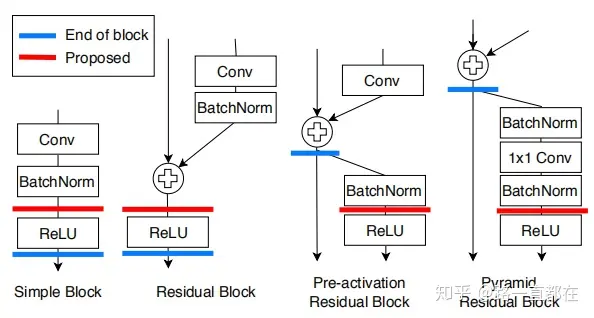
- 蒸馏位置
在神经网络中,激活函数能够其非线性表达能力,是神经网络成功的关键一环。在各式各样的激活函数类型中,ReLU及其各种变种在神经网络中有广泛应用。ReLU对于正值是一个线性映射的关系,对于负值采取清零的方式。这种对正负值的区分处理,有助于防止无用信息的进一步传播。ReLU在知识蒸馏中也有用武之地,作者定义了网络的最小单元,比如ResNet中的残差块,VGG中的Conv-ReLU结构,称为一个block,常规的蒸馏位置通常是在每一个block的后面。在本文中,蒸馏的位置位于第一个ReLU和每一个block之间,这样能让学生网络达到保存教师网络特征信息的目的。如下图所示,对于普通神经网络的block和残差网络的block,本文提出的方法与其他方法的不同之处在于,蒸馏发生在ReLU之前还是之后,而与那些使用了预激活的网络进行对比,两者之间的差异更大,因为预激活的网络在每一个block后没有ReLU,因此本文的方法需要在下一个block中寻找ReLU。虽然蒸馏位置根据体系结构的不同可能会比较复杂,但是实验证明它对性能有很大的影响。能显著提高学生网络的表现。
- 损失函数
上文已经解释了关于教师网络转换 ![]() ,学生网络转换
,学生网络转换 ![]() 和距离度量 d。由于教师网络的特征值
和距离度量 d。由于教师网络的特征值 ![]() 是ReLU之前的值,正的值是教师网络利用的信息,而负的值则不是。如果教师网络的特征值是正的,学生网络必须产生与教师网络相同的特征值。反之,如果教师网络的特征值为负,则学生网络产生的特征值应小于零,使神经元处于相同的激活状态。作者提出了margin-ReLU,具体形式为:
是ReLU之前的值,正的值是教师网络利用的信息,而负的值则不是。如果教师网络的特征值是正的,学生网络必须产生与教师网络相同的特征值。反之,如果教师网络的特征值为负,则学生网络产生的特征值应小于零,使神经元处于相同的激活状态。作者提出了margin-ReLU,具体形式为:
![]()
其中,m是小于0的边缘值(margin value),通过引入margin-ReLU,教师网络的转换可以保留有益的正的特征值。下图是margin-ReLU与常规ReLU的对比
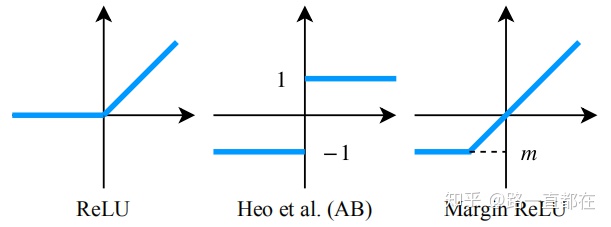
可以看到,边际值m被定义为负响应的逐通道期望值,边际ReLU使用与输入的每个通道对应的值,公式表示为:
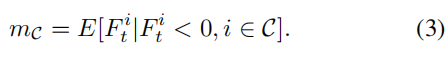
期望值可以在训练过程中直接计算,如https://github.com/clovaai/overhaul-distillation/issues/7所示。也可以使用前BN层的参数进行计算:
对于一个通道C和教师特征![]() 的第i个元素,该通道的margin值mc为训练图片的期望值即式(3).通常我们不知道
的第i个元素,该通道的margin值mc为训练图片的期望值即式(3).通常我们不知道![]() 的分布,所以只能通过训练过程中的平均值来得到期望。但是ReLU前的BN层决定了一个batch中的特征
的分布,所以只能通过训练过程中的平均值来得到期望。但是ReLU前的BN层决定了一个batch中的特征![]() 的分布,BN层将每个通道的特征归一化为均值 μ方差 σ 的高斯分布,即
的分布,BN层将每个通道的特征归一化为均值 μ方差 σ 的高斯分布,即
![]()
每个通道的均值方差 (μ,σ)对应BN层的参数 (β,γ),因此利用![]() 的分布可以直接计算边际值
的分布可以直接计算边际值

利用高斯分布的概率密度函数pdf进行积分就可以得到期望,其中范围小于0。积分的结果可以通过正太分布的cdf累积分布函数 Φ(⋅)进行简单的表示。

在官方实现中,也是通过这种方式即式(10)来计算margin值的。
margin-ReLU被用作教师网络转换 ![]() ,通过该操作产生学生网络的目标特征值。而学生网络的转换
,通过该操作产生学生网络的目标特征值。而学生网络的转换 ![]() 则包括1x1卷积层和BN层。
则包括1x1卷积层和BN层。
现在再来看距离度量d。在教师网络的特征中,正响应实际上是用于网络训练的,这意味着教师网络的正响应应该以其确切的值来传递。然而,负响应却不是。假定教师网络此时输出一个负响应,如果此时学生网络输出的响应值高于目标值,那么必须要减小,但是如果此时学生网络的输出值低于目标值,就没有必要再增加,因为响应值在经过激活函数后会被抑制。因此,定义一个局部的L2函数,公式如下:
其中,T是教师网络的特征位置,S是学生网络的特征位置。
综上,设 ![]() 表示margin-ReLU作为教师网络的转移操作,
表示margin-ReLU作为教师网络的转移操作, ![]() 表示1x1卷积和BN层作为学生网络的转移操作,
表示1x1卷积和BN层作为学生网络的转移操作, ![]() 表示局部的L2正则化作为距离度量,总的蒸馏损失函数可以表示为:
表示局部的L2正则化作为距离度量,总的蒸馏损失函数可以表示为:
![]()
有了蒸馏损失,总损失需要加上任务自身的损失,因此,总损失函数为:
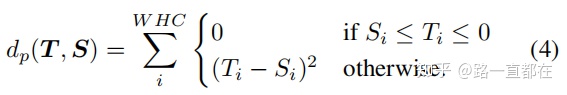
![]()
其中 σmc 是教师转换函数margin ReLU,r是是学生转换函数1x1 conv + BN,dp 是距离函数patial L2 distance
- BN层
最后看一下BN层在知识蒸馏中的作用。BN层在神经网络中有广泛应用,能够让训练更稳定。在蒸馏网络中,通常,学生网络的特征是逐批进行归一化的。因此,教师网络的特征也必须以同样的方式归一化。也就是说,教师网络应该在训练时进行批处理归一化。为此,作者在1x1的卷积层之后附加一个BN层,在学生网络的设置上也是如此。
3.代码
#实现代码主要在distiller.py中,本文的第一个创新点在蒸馏的位置,即ReLU前,实现如下
'''
这两行代码分别提取了教师网络和学生网络在ReLU激活函数之前的特征表示。
extract_feature 函数用于提取网络的特征表示,preReLU=True 表示在ReLU激活函数之前提取特征。
'''
t_feats, t_out = self.t_net.extract_feature(x, preReLU=True)
s_feats, s_out = self.s_net.extract_feature(x, preReLU=True)
#学生特征的转换为1x1卷积+BN,即实现中的self.Connectors,具体实现如下
'''
build_feature_connector(t_channel, s_channel):
该函数用于构建将学生特征转换为教师特征的连接器。
连接器由一个1x1卷积层和BatchNormalization组成,用于调整通道数和特征表示的对齐。
'''
def build_feature_connector(t_channel, s_channel):
C = [nn.Conv2d(s_channel, t_channel, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(t_channel)]
for m in C:
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
return nn.Sequential(*C)
#教师特征的转换为本文提出的margin ReLU,边际margin值的计算如下,即上述的式(10)
'''
get_margin_from_BN(bn):该函数用于从BatchNormalization层中计算边际(margin)值。
根据提供的BatchNormalization层的权重和偏置,通过计算标准差和均值,结
合正态分布的累积分布函数(CDF),计算每个通道的边际值。
'''
def get_margin_from_BN(bn):
margin = []
std = bn.weight.data
mean = bn.bias.data
for (s, m) in zip(std, mean):
s = abs(s.item())
m = m.item()
if norm.cdf(-m / s) > 0.001:
margin.append(- s * math.exp(- (m / s) ** 2 / 2) / math.sqrt(2 * math.pi) / norm.cdf(-m / s) + m)
else:
margin.append(-3 * s)
return torch.FloatTensor(margin).to(std.device)
#蒸馏损失函数实现如下,其中第一行就是教师特征的转换函数,即式(2)
'''
distillation_loss(source, target, margin):这个函数用于计算蒸馏损失。
首先,对教师特征应用边际值进行转换,
然后使用均方误差损失函数(MSE)计算源特征和转换后的目标特征之间的损失。
其中,损失值仅在源特征大于目标特征或目标特征大于0的位置处有效。
'''
def distillation_loss(source, target, margin):
target = torch.max(target, margin)
loss = torch.nn.functional.mse_loss(source, target, reduction="none")
loss = loss * ((source > target) | (target > 0)).float()
return loss.sum()
四.超分与蒸馏
众所周知,图像/视频超分 (SR) 是工业界非常具有应用场景的应用,但能够生产具有良好视觉效果的重建图像的SR模型的参数量和运算量都非常巨大,比如业界公认的优秀baseline模型EDSR,EDVR等的算力需求高达几百,几千GFLOPs。而业界真正需求的轻量化模型,尤其是可以部署于移动端设备的实时模型,其算力限制可能严苛到小于10GFlops。
在high-level CV tasks上得到广泛应用和验证的模型剪枝、c馏方法应用到超分任务上,即将一个训练好的大模型进行裁剪,或者用性能较强的教师大模型蒸馏原本较弱的学生小模型,使裁剪/蒸馏后的小模型能够取得相比普通训练方式更好,甚至接近原先大模型的性能。这里的challenge在于,直接的迁移应用这些算法,在超分任务上无法得到有效的性能提升,甚至可能导致非常严重的performance degradation.
1.SRKD
它将最基本的知识蒸A Comprehensive Overhaul of Feature Distillation馏直接应用到图像超分中,整体思想分类网络中的蒸馏方式基本一致,整体来看属于应用形式。
全称:Image Super-Resolution Using Knowledge Distillation
链接:
code:
发表:ACCV 2018
团队:Fuzhou University
1.贡献
- 首先,本文首次利用师生网络策略,将教师SR网络中的知识转移到学生SR网络中,从而在不改变学生网络结构的情况下,大大提高了学生网络的SR重建性能。
- 其次,为了确定从教师网络到学生网络的有效知识传播,我们评估和比较了多种不同的统计地图提取方法。最后,选择一种最优的方式将教师网络的知识传播到学生网络中。
- 第三,MobileNet用于学生SR模型。与教师SR网络相比,学生SR模型需要较少的计算资源,并且可以高效地在低功耗的手机和嵌入式设备上运行,从而为在计算有限的设备上及时部署SR模型提供了一种很有前途的方法。
2.方法
1.教师结构
我们的TNSR结构如图1所示。它在TNSR结构中由三部分组成。TNSR的第一部分是特征提取和表示,包括卷积层和非线性激活层。第一部分操作F1(X)表示为:
F1(X) = max(0, W1 ∗ X + B1)
其中W1和B1分别表示第一卷积层的权重和偏置。W1由m个空间大小为f × f的滤波器组成。'∗'表示卷积运算。X是输入的LR图像。
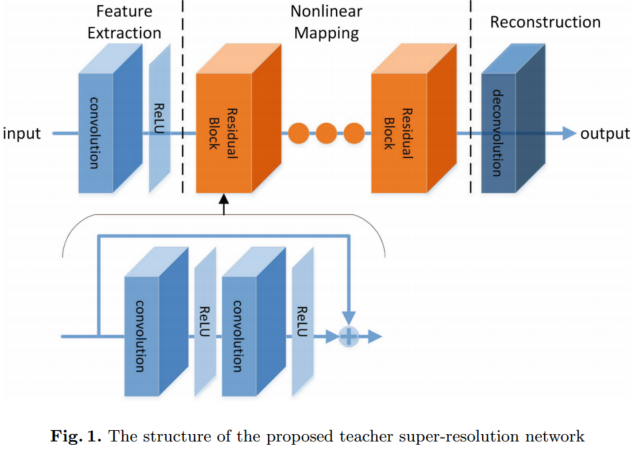
TNSR的第二部分是非线性映射步骤,由10个残差块组成。每个残差块有两个卷积层,如图1所示。每个卷积层之后是一个非线性激活层。使用跳跃连接对每个残差块的输入和输出特征映射进行求和。这样,只学习每个残差块输入和输出之间的残差信息。通过在TNSR中使用跳跃连接,可以解决训练非常深度网络时的梯度消失问题。每个残差块可表示为:
![]()
式中n为残差块数。F2n+1(X)表示每个残差块的输出。W2n+1和B2n+1分别是残差块中第二层的权重和偏置。F2n(X)表示残差块中第一卷积层和非线性激活层的输出。F2n−1(X)为残差块的输入特征映射。
TNSR的最后一部分使用反卷积层来重建高分辨率输出。使用反褶积层进行升级有两个优点。首先,它可以加速sr的重建过程。由于上尺度操作是在网络的末端进行的,所以所有的卷积操作都是在LR空间中进行的。如果升级因子是r,它将大约减少r2的计算成本。此外,由于在SR网络的末端添加反卷积层,覆盖了很大的接收场,因此可以使用来自LR图像的大量上下文信息来推断高频细节。
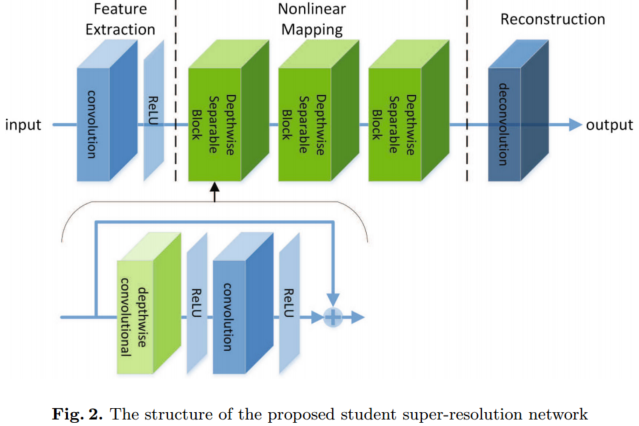
2.学生结构
SNSR包括三部分:第一部分是特征提取层,最后一部分是用于重建的反卷积层,这与TNSR相同。第二部分使用了三个深度可分离的卷积块。每个块由一个深度卷积层和一个称为点卷积的1 × 1卷积层组成。深度卷积层对每个输入通道应用单个滤波器,而点向卷积应用1 × 1卷积来组合深度卷积的输出。我们从MobileNet中删除了批处理规范化层,因为这在以前的研究中被证明对SR没有帮助。深度卷积和点向卷积之后都有一个非线性激活层。
如果使用3 × 3滤波器,深度可分离卷积块使用的计算量比标准卷积少8到9倍。这可以显著节省大量的计算资源,而在图像分类和目标检测上的准确率却只有很小的降低。
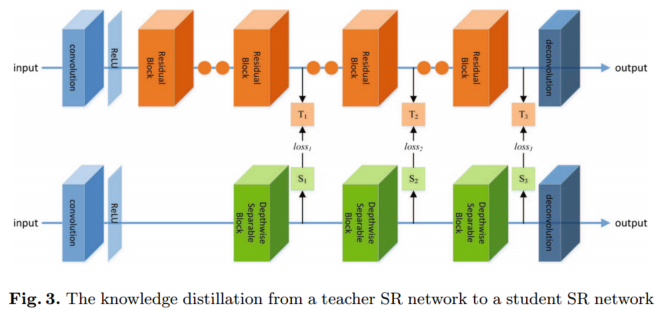
3.Knowledge Distillation and Propagation
为了将有用的知识从教师网络传播到学生网络,分别从TNSR和SNSR中提取统计图。如图3所示,利用TNSR的第4、第7和第10残差块的输出计算统计图,分别记为t1、t2和t3,分别描述低级、中级和高级视觉信息。这些图表示TNSR中从低级特征到高级特征的特征。
在SNSR中,我们使用第一、第二和第三个深度可分离卷积块的输出提取相应级别的统计映射,分别表示为s1、s2和s3。之后,我们在训练SNSR时使用t1、t2、t3中的信息来引导信息s1、s2、s3。统计特征是从网络的中间输出中计算出来的,而不是直接使用中间输出。这在图像分类中比直接传播中间输出更有效。网络的中间输出可以表示为一个张量 ![]() ,它由C个特征通道组成,空间维度为H× w,然后从张量T计算出一个统计映射:
,它由C个特征通道组成,空间维度为H× w,然后从张量T计算出一个统计映射:
![]()
其中G是将张量输出T映射到统计映射S∈R(H×W)的函数。在这项工作中,使用了四种类型的映射函数来计算统计映射。
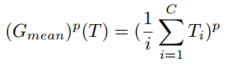 计算T的平均映射并取p1的幂。
计算T的平均映射并取p1的幂。- .
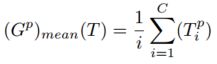 计算p1 (≥1)对T的幂。计算平均值作为知识传播的统计图。
计算p1 (≥1)对T的幂。计算平均值作为知识传播的统计图。 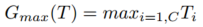 T中特征映射跨C个通道的最大值作为另一种统计映射计算:
T中特征映射跨C个通道的最大值作为另一种统计映射计算: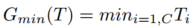 T中跨特征映射的最小值也作为统计映射计算
T中跨特征映射的最小值也作为统计映射计算
在训练学生网络时,从SNSR中提取的统计图s1、s2、s3被强制与从TNSR中提取的统计图t1、t2、t3相似。此外,SR重构图像被强制与原始HR图像相似。因此,训练SNSR的总损失可表示为:
![]()
其中λi是损失的权重。loss0计算重建图像Y与原始HR图像Y之间的损失。loss1、loss2和loss3表示SNSR和TNSR统计图之间的损失。我们不使用均方误差作为损失函数,而是采用一种称为Charbonnier惩罚函数的鲁棒损失来处理离群值,其定义为:
![]()
其中μ根据经验设置为0.001。采用Charbonnier损失函数训练SNSR的总损失。
4.结论
- 第一和第二特征映射的信息传播显著提高了SR重建性能,而第三特征映射对结果有负面影响。这表明高级特征(第三部分)在低级计算机视觉任务中可能没有用(在我们的例子中是超分辨率)。
- 结果表明,(Gmean)p和(Gp)均值比Gmax和Gmin更适合在SR中进行知识蒸馏。因此,我们最后选择(Gmean)2来计算统计图。
可适用于我们的模型,初代KDSR,利用三层中间feature,效果一般,残差块+深度可分离,无代码
2.FAKD
它在常规知识蒸馏的基础上引入了特征关联机制,进一步提升被蒸馏所得学生网络的性能,相比直接应用有了一定程度的提升;
全称:FAKD: FEATURE-AFFINITY BASED KNOWLEDGE DISTILLATION FOR EFFICIENT
IMAGE SUPER-RESOLUTION
链接:
发表:ICIP 2020
团队:Tsinghua Shenzhen International Graduate School
1.背景
卷积神经网络(cnn)在图像超分辨率(SR)中得到了广泛的应用。现有的大多数基于cnn的方法侧重于通过设计更深/更广的网络来获得更好的性能,但存在沉重的计算成本问题,从而阻碍了此类模型在资源有限的移动设备上的部署。为了解决这一问题,我们提出了一种新的、高效的基于特征亲和力的知识蒸馏(FAKD)模型,该模型通过将重教师模型的结构知识转移到轻学生模型中。为了有效地传递结构知识,FAKD旨在从特征图中提取二阶统计信息,并训练具有低计算和内存成本的轻量级学生网络。实验结果证明了该方法的有效性,并且在定量和可视化度量方面优于其他基于知识蒸馏的方法。
具体来说,FAKD将知识从教师模型的特征关联图转移到轻量级学生模型,这迫使轻量级学生模型模仿特征关联。实验表明,我们提出的框架有效地压缩了基于cnn的SR模型,同时通过转移来自强教师模型的结构知识来提高学生网络的性能。
2.方法
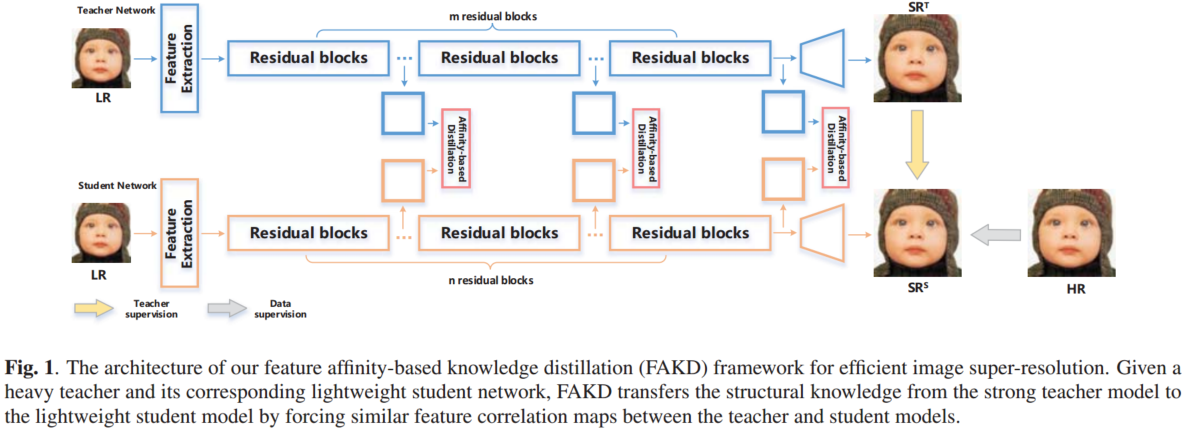
本文提出的基于特征亲和力的知识蒸馏框架的流水线如图1所示。退化的LR图像通过教师T和学生S网络传播。教师模型是一个功能强大的笨重网络,而学生模型是一个轻量级网络。在我们的框架中,它们共享相同的架构,但有不同的超参数(例如,网络深度)。如图1所示,它们分别由m和n个残差块组成(m>n)。为了有效地将知识从教师模型转移到学生模型,学生网络的中间特征映射被迫模仿教师模型的特征亲和矩阵。此外,教师输出图像和地面真实图像也分别通过教师监督(TS)和数据监督(DS)来监督学生网络。
1.基于特征亲和力的蒸馏(FAKD)
给定一批特征映射![]() ,我们首先将它们重塑成一个三维张量
,我们首先将它们重塑成一个三维张量![]() ,分别为batch size、通道和空间维度。为了利用特征映射内部的一致性,我们提出了计算亲和矩阵a的方法。它们是由低级、中级和高级的特征映射生成的,以表示不同程度的相关性。鼓励学生网络产生与教师网络相似的亲和矩阵,基于特征亲和的蒸馏损失可以表示为
,分别为batch size、通道和空间维度。为了利用特征映射内部的一致性,我们提出了计算亲和矩阵a的方法。它们是由低级、中级和高级的特征映射生成的,以表示不同程度的相关性。鼓励学生网络产生与教师网络相似的亲和矩阵,基于特征亲和的蒸馏损失可以表示为
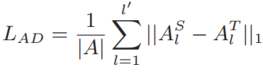
式中,![]() 和
和![]() 为从第l层特征图中提取的师生网络亲和矩阵;L‘是我们选择提取的层数。|A|表示关联矩阵中元素的个数。
为从第l层特征图中提取的师生网络亲和矩阵;L‘是我们选择提取的层数。|A|表示关联矩阵中元素的个数。
为了保持像素之间的空间连续性,我们从空间角度考虑亲和矩阵,旨在探索像素之间的关系。pipeline如图2所示,其中每个像素都被视为c维向量(蓝色列),并且在每个列上进行规范化,如公式2所示。归一化后,每一列都是单位长度的,因此两个像素之间的余弦相似度可以简单地通过内积得到,经验上效果很好。空间亲和矩阵表示为:

其中F ~为归一化特征映射。生成的空间亲和矩阵大小为b × HW × HW。空间亲和矩阵中的每个元素表示两个像素之间的空间相关性。
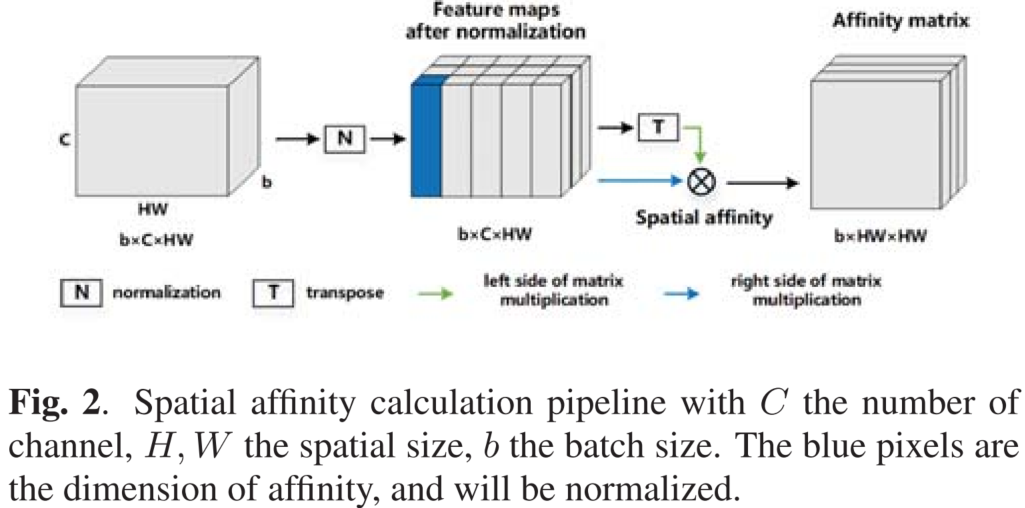
2.损失函数
除了基于特征亲和力的蒸馏,我们还通过实证发现,教师监督(TS)和数据监督(DS)也有助于提高蒸馏性能,如图1所示。TS和DS分别将学生的输出与教师的和groundtrue图像进行比较,如式4和式5所示。因此,学生网络可以同时接收到来自教师分布和真实数据分布的监控信号。整体损失函数如式6所示。

其中![]() 分别为学生输出、教师输出和真地集的图像。α、β和γ是平衡不同方面损失的惩罚系数。利用这个整体损失函数,可以优化学生网络,从老师那里获取所有这些知识。
分别为学生输出、教师输出和真地集的图像。α、β和γ是平衡不同方面损失的惩罚系数。利用这个整体损失函数,可以优化学生网络,从老师那里获取所有这些知识。
利用中间层feature每个点的关系矩阵,可使用,残差块,有代码
3.PISR
利用了广义蒸馏的思想进行超分网络的蒸馏,通过充分利用训练过程中HR信息的可获取性进一步提升学生网络的性能。
全称:Learning with Privileged Information for Efficient Image Super-Resolution
链接:
code:https://cvlab.yonsei.ac.kr/projects/PISR
发表:ECCV 2020
团队:Yonsei University
1.背景
本文中提出了一个简单而有效的框架,用于高效的SISR方法。基本思想是,真实的HR图像可以被认为是特权信息(图1),这在SISR和特权学习中都没有被探索。诚然,HR图像包含LR图像的互补信息(例如,高频成分),但目前的SISR方法只是使用它来惩罚cnn结束时的错误重建。相反,我们使用HR图像作为特权信息的方法允许提取互补特征并显式地将它们用于SISR任务。
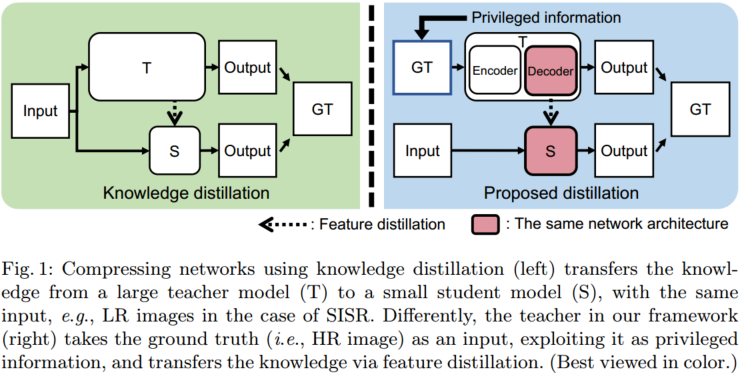
为了实现这一想法,我们引入了一种新的蒸馏框架,其中教师和学生网络尝试重构HR图像,但使用不同的输入(即分别为教师和学生的ground-truth HR和相应的LR图像),这与传统的知识蒸馏框架(图1)明显不同。具体而言,教师网络具有由编码器和解码器组成的沙漏架构。编码器从HR图像中提取紧凑的特征,同时鼓励它们使用模仿损失来模仿LR对应的图像。解码器与学生具有相同的网络结构,利用压缩特征再次重构HR图像。然后通过特征蒸馏将解码器中的中间特征传递给学生,这样学生就可以学习使用特权数据(即HR图像)训练的教师的知识(例如,HR输入的高频或精细细节)。请注意,我们的框架是有用的,因为学生可以用解码器的网络参数初始化,这允许将教师的重建能力转移给学生。我们主要利用FSRCNN[11]作为学生网络,因为它具有硬件友好的架构(即卷积层堆栈),并且与其他基于cnn的SR方法相比,参数数量非常少。在标准SR基准测试上的实验结果证明了该方法的有效性,该方法在不添加任何额外模块的情况下提高了FSRCNN的性能。据我们所知,我们的框架是第一次尝试为SISR利用特权信息。我们工作的主要贡献可以概括如下:
- 我们提出了一种新的SISR蒸馏框架,该框架利用基础真相(即HR图像)作为特权信息,将HR图像的重要知识转移到学生网络。
- 我们建议使用模仿损失来训练教师网络,使提取学生能够学习的知识成为可能。
- 我们证明,我们的方法显著提高了当前的SISR方法的性能,包括FSRCNN[11]、VDSR[29]、IDN[27]和CARN[1]。我们对消融研究进行了广泛的实验分析。
2.方法
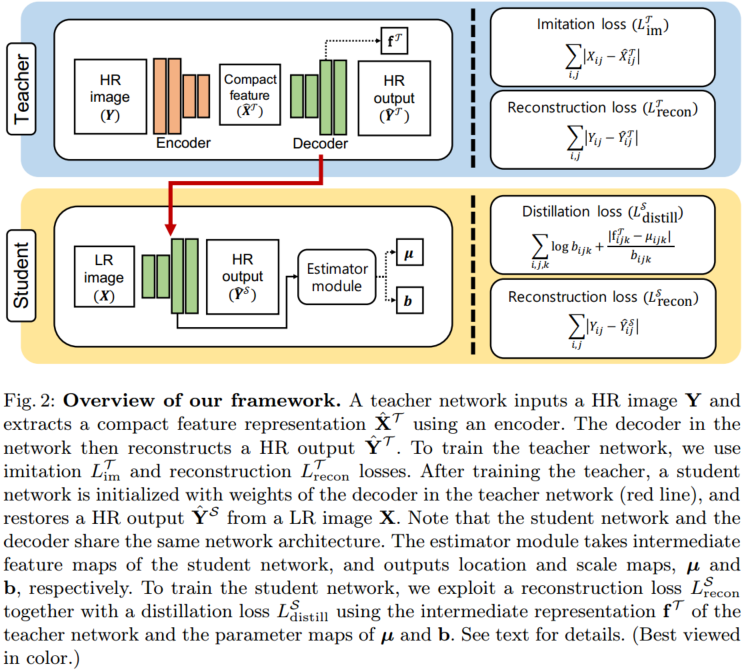
1.老师
我们为教师网络开发了一个沙漏架构。它将HR图像投影到低维特征空间中,生成紧凑的特征,并从中重建原始HR图像,从而使教师学会为图像重建任务提取更好的特征表示。具体来说,教师网络由编码器![]() 和解码器
和解码器![]() 组成。给定一对LR和HR图像,编码器
组成。给定一对LR和HR图像,编码器![]() 将输入的HR图像Y转换为低维空间中的特征表示
将输入的HR图像Y转换为低维空间中的特征表示![]() :
:
![]()
其中![]() 的特征表示与LR图像具有相同的大小。解码器
的特征表示与LR图像具有相同的大小。解码器![]() 使用压缩特征
使用压缩特征![]() 重建HR图像
重建HR图像 ![]() :
:
![]()
对于解码器,我们使用与学生网络相同的架构。它允许教师具有与学生相似的表征能力。
为了训练教师网络,我们使用重建损失和模仿损失,分别用![]() 和
和![]() 表示。重建项计算HR图像Y与其重建图像Y^ T之间的平均绝对误差(MAE),定义为:
表示。重建项计算HR图像Y与其重建图像Y^ T之间的平均绝对误差(MAE),定义为:
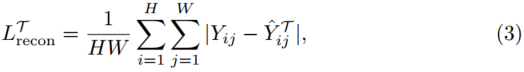
H和W分别为HR图像的高度和宽度,用Yij表示Y在(i,j)位置的强度值.它鼓励编码器输出(即紧凑特征![]() )包含对图像重建有用的信息,并迫使解码器再次使用紧凑特征重建HR图像。
)包含对图像重建有用的信息,并迫使解码器再次使用紧凑特征重建HR图像。
模仿项限制了编码器的表示能力,使编码器的输出接近LR图像。具体来说,我们将此项定义为LR图像X与编码器输出![]() 之间的MAE:
之间的MAE:
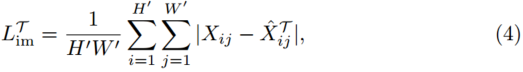
H’和W‘分别为LR图像的高度和宽度。这有助于初始化以LR图像X作为输入的学生网络。请注意,我们的框架避免了简单的解决方案,即紧凑特征成为LR图像,因为编码器中的网络参数由模仿和重建项更新。总体目标是重建和模仿项的总和,由参数![]() 平衡:
平衡:
![]()
2.学生
学生网络与教师网络中的解码器![]() 具有相同的架构,但使用不同的输入。它以LR图像X作为输入,生成HR图像
具有相同的架构,但使用不同的输入。它以LR图像X作为输入,生成HR图像![]() :
:
![]()
我们将学生网络的权重初始化为教师网络中解码器的权重。这将教师的重构能力转移给了学生,为优化提供了一个很好的起点。我们采用硬件友好的SR架构FSRCNN作为学生网络![]() 。
。
虽然最初将学生![]() 和教师中
和教师中![]() 的网络参数设置为相同,但由于输入不同,从中提取的特征也不同。此外,这些参数没有对输入LR图像进行优化。我们进一步用重建损失
的网络参数设置为相同,但由于输入不同,从中提取的特征也不同。此外,这些参数没有对输入LR图像进行优化。我们进一步用重建损失![]() 和蒸馏损失
和蒸馏损失![]() 训练学生网络
训练学生网络![]() 。重构项类似地定义为Eq.(3),使用ground-truth HR图像及其来自学生网络的重构,专门用于SISR任务:
。重构项类似地定义为Eq.(3),使用ground-truth HR图像及其来自学生网络的重构,专门用于SISR任务:
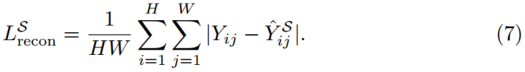
![]()
其中![]() 是蒸馏参数。下面,我们详细地描述蒸馏损失。
是蒸馏参数。下面,我们详细地描述蒸馏损失。
我们采用VID方法中提出的蒸馏损失,使师生之间的相互信息最大化。我们分别用![]() 和
和![]() 表示教师和学生网络的中间特征映射,它们的大小为
表示教师和学生网络的中间特征映射,它们的大小为![]() ,其中C为通道数。我们定义互信息
,其中C为通道数。我们定义互信息![]() 如下:
如下:
![]()
我们分别用H(f T)和H(f T|f S)表示边际熵和条件熵。为了最大化互信息,我们应该最小化条件熵H(f T|f S)。然而,对学生的权重进行精确的优化是难以处理的,因为它涉及到对条件概率p(f T|f S)的积分。变分信息最大化技术使用参数模型q(f T |f S)近似条件分布p(f T |f S),如高斯分布或拉普拉斯分布,从而有可能找到互信息I(f T;f S)的下界。利用这种技术,我们最大化了特征蒸馏的互信息I(f T;f S)的下界。作为参数模型q(f T |f S),我们使用一个多变量拉普拉斯分布,其参数分别为位置和尺度,![]() 和
和![]() .我们将蒸馏损失
.我们将蒸馏损失![]() 蒸馏定义为:
蒸馏定义为:
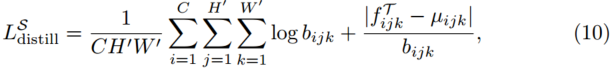
我们用![]() 表示µ的元素在位置(i;j;k).这最小化了教师的特征
表示µ的元素在位置(i;j;k).这最小化了教师的特征![]() 与位置图µ之间的距离。比例尺b控制蒸馏的程度。例如,当学生没有从蒸馏中受益时,为了减少蒸馏的程度,尺度参数
与位置图µ之间的距离。比例尺b控制蒸馏的程度。例如,当学生没有从蒸馏中受益时,为了减少蒸馏的程度,尺度参数![]() 增加。这对我们的框架很有用,因为教师和学生网络采用不同的输入,因为它自适应地决定了学生可以负担得起从老师那里学习的特征。
增加。这对我们的框架很有用,因为教师和学生网络采用不同的输入,因为它自适应地决定了学生可以负担得起从老师那里学习的特征。![]() 防止了一个平凡的解当尺度参数趋于无穷大时。我们从学生
防止了一个平凡的解当尺度参数趋于无穷大时。我们从学生![]() 的特征中估计这些µ和b的映射。注意,为特征蒸馏设计的其他损失也可以在我们的框架中使用(参见补充材料)。
的特征中估计这些µ和b的映射。注意,为特征蒸馏设计的其他损失也可以在我们的框架中使用(参见补充材料)。
估计模块
我们使用一个小型网络来估计Eq.(10)中的位置µ和尺度b的参数。它由位置和比例尺分支组成,其中每个分支都取学生![]() 的特征,并分别估计位置和比例尺地图。两个分支共享相同的网络架构,即两个1 × 1卷积层和它们之间的PReLU。对于尺度分支,我们在最后一层添加了softplus函数
的特征,并分别估计位置和比例尺地图。两个分支共享相同的网络架构,即两个1 × 1卷积层和它们之间的PReLU。对于尺度分支,我们在最后一层添加了softplus函数![]() ,迫使尺度参数为正。注意,估计模块仅在训练时使用。
,迫使尺度参数为正。注意,估计模块仅在训练时使用。
利用教师网络的编码器初始化学生网络,后利用最大互信息作为蒸馏损失,FSRCNN有代码
4.Towards Compact Single Image Super-Resolution via Contrastive Self-distillation
链接:
发表:IJCAI21
团队:Yonsei University
1.背景
卷积神经网络在超分任务上取得了很好的成果,但是依然存在着参数繁重、显存占用大、计算量大的问题,为了解决这些问题,作者提出利用对比自蒸馏实现超分模型的压缩和加速。
我们的目标是同时压缩和加速SR模型。我们提出了一个简单的自蒸馏框架,其中学生网络通过在每层使用教师的部分通道从教师(目标)网络中分离出来。我们将这种学生网络称为信道分割超分辨率网络(CSSRNet)。教师网络和学生网络共同训练,形成两个计算方式不同的SR模型。根据设备中计算资源的不同,我们可以动态分配这两种模型,即在资源有限的设备中,如果超过所需的计算开销,则选择CSSR-Net,否则选择教师模型.
主要贡献
- 作者提出的对比自蒸馏(CSD)框架可以作为一种通用的方法来同时压缩和加速超分网络,在落地应用中的运行时间也十分友好。
- 自蒸馏被引用进超分领域来实现模型的加速和压缩,同时作者提出利用对比学习进行有效的知识迁移,从而 进一步的提高学生网络的模型性能。
- 在Urban100数据集上,加速后的EDSR+可以实现4倍的压缩比例和1.77倍的速度提高,带来的性能损失仅为0.13 dB PSNR。
2.方法
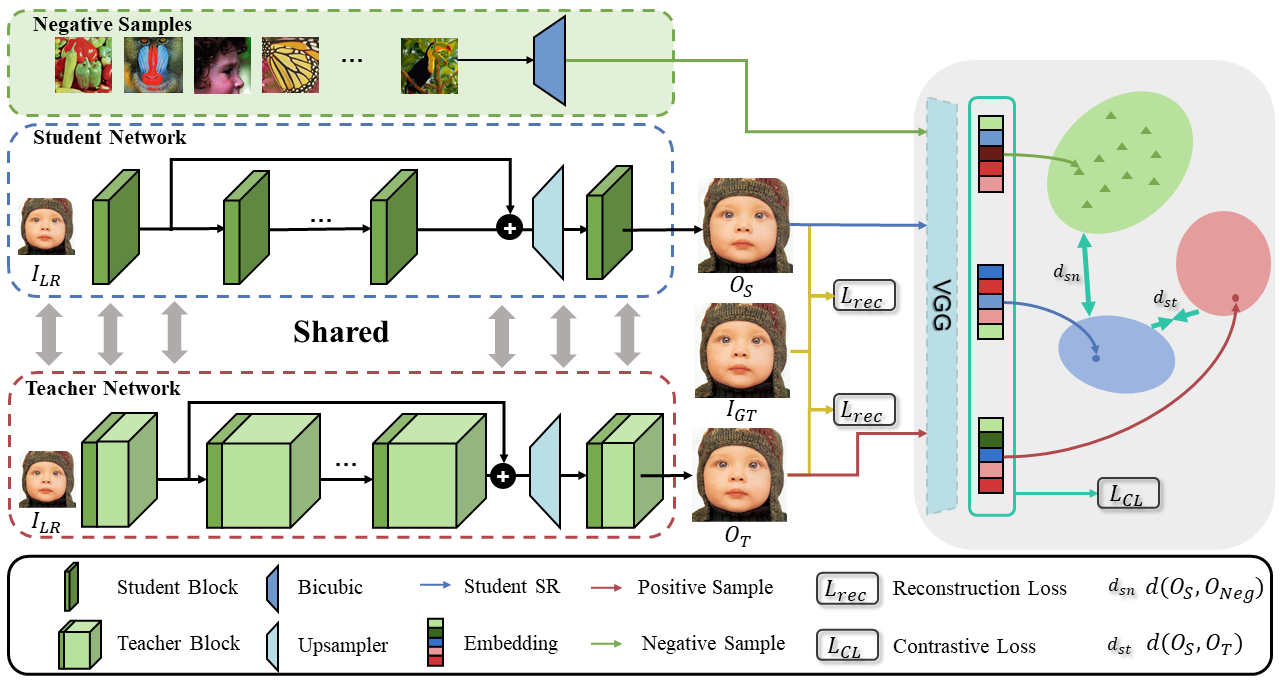
我们的CSD包括两个部分:CSSR-Net和对比损失(CL)。首先,我们描述了CSSR-Net。然后,我们给出了构造CSSR-Net的上界和下界的正则表达式。
最后,给出了CSD方案的总体损失函数,并用一种新的优化策略对其进行了求解。
1.信道分裂超分辨率网络
信道分裂超分辨率网络(CSSR-Net)是将任意一个基于cnn的超分辨率网络在信道维度上进行分裂而构建的网络。CSSR-Net可以看作是一个学生网络,而它的原始网络是一个教师网络。这对关系可以用来构建一个自蒸馏框架,并隐含地将知识从教师传递给学生。CSSR-Net与教师网络纠缠在一起,因为它共享了教师的一部分权重,如图2左面板所示。
CSSR-Net的宽度由手动设置的比例因子![]() 乘以所有层的教师宽度来控制。例如,
乘以所有层的教师宽度来控制。例如,![]() = 0:5,对应于CSSRNet在所有层中保留的通道宽度或数量为教师的一半。
= 0:5,对应于CSSRNet在所有层中保留的通道宽度或数量为教师的一半。
我们可以共同将CSSR-Net和教师的重构损失最小化:
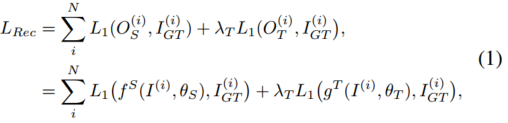
其中![]() 和
和![]() 分别为CSSR-Net
分别为CSSR-Net![]() 和教师网络
和教师网络![]() 在LR输入
在LR输入![]() 上的输出,参数分别为θS和θT。θS与θT共享,满足
上的输出,参数分别为θS和θT。θS与θT共享,满足![]() 。
。![]() 为真实HR图像,N为训练图像个数。
为真实HR图像,N为训练图像个数。
我们引入对比学习来明确构建学生和教师之间的关系,并提供封闭的上界和下界,以提高CSSR-Net和教师的绩效。上界是为了将CSSR-Net的输出拉向教师的输出,下界是为了约束CSSR-Net的输出远离负样本(如双三次上采样图像)。
2.对比损失
我们提出了一种新的对比损失(CL)来明确表示培训教师网络和CSSR-Net的知识。对于对比学习,我们需要考虑两个方面:一是构建“正”和“负”样本,二是寻找潜在特征空间来比较样本。
对于前者,我们将CSSR-Net的输出![]() 和其教师的输出
和其教师的输出![]() 分别构建为锚点和正样本。更多的负样本可能更好地覆盖不希望的分布。因此,我们从相同的小批量中抽取K个图像(锚点除外)作为负样本到
分别构建为锚点和正样本。更多的负样本可能更好地覆盖不希望的分布。因此,我们从相同的小批量中抽取K个图像(锚点除外)作为负样本到![]() 。然后通过双三次插值将它们上采样到与
。然后通过双三次插值将它们上采样到与![]() 相同的分辨率。用
相同的分辨率。用![]() 表示;K = 1;2···;K。
表示;K = 1;2···;K。
对于潜在特征空间,我们使用预训练模型φ的中间特征。给定正、负样本,我们可以将对比损失构造为:
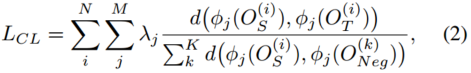
式中![]() ;j = 1;2;···M 为预训练模型第j层的中间特征。M是隐藏层的总数。d (x;y)为x和y之间的l1距离损失,λj为每层的平衡权值。我们在训练时不更新预训练模型φ的参数。
;j = 1;2;···M 为预训练模型第j层的中间特征。M是隐藏层的总数。d (x;y)为x和y之间的l1距离损失,λj为每层的平衡权值。我们在训练时不更新预训练模型φ的参数。
对比损耗如图2右图所示;损失引入了相反的力,将CSSRNet的输出![]() 拉向它的老师
拉向它的老师![]() 的输出,并将
的输出,并将![]() 推向负样本
推向负样本![]() 。请注意,我们的对比损失与InfoNCE 不同,InfoNCE使用基于点积的相似性。与这种相似性相反,我们的l1距离损失实现了更好的性能(参见实验了解更多细节)。此外,与我们的CL相关的是感知损失,它最大限度地减少了学生与预训练的VGG的多层特征之间的距离损失。这是约束学生网络的上限。然而,与感知损失不同的是,我们还采用了多个负样本作为下界,以减少解空间,进一步提高CSSR-Net及其教师的性能。 3.The Overall Loss and Its Solver
。请注意,我们的对比损失与InfoNCE 不同,InfoNCE使用基于点积的相似性。与这种相似性相反,我们的l1距离损失实现了更好的性能(参见实验了解更多细节)。此外,与我们的CL相关的是感知损失,它最大限度地减少了学生与预训练的VGG的多层特征之间的距离损失。这是约束学生网络的上限。然而,与感知损失不同的是,我们还采用了多个负样本作为下界,以减少解空间,进一步提高CSSR-Net及其教师的性能。 3.The Overall Loss and Its Solver
Overall Loss
![]()
Solver
由于我们的CSSR-Net和它的老师是纠缠在一起的,我们需要从它们中更新两个梯度。一种朴素的解决方案是通过基于SGD直接最小化Eq. 3来更新所有参数(即θS和θT)。然而,教师只是变得更弱,而不是保持良好的表现。
作为一种解决方案,我们将教师梯度从对比损失中分离出来,只从重建损失中更新梯度。对于学生,我们对Eq. 3进行正态梯度更新。
算法1总结了CSD方案的伪码。
Algorithm 1 Pseudocode of CSD in a PyTorch-like style
# f_t: Pre-trained teacher network
# width_mult: the width of network f_s
# lt, lc: lambda_t, lambda_c in Eq. 1, Eq. 3
initialize()
for lr, hr in loader: # load a minibatch
neg = bic(generate()) # negative samples
o_s = f_s.forward(lr) # anchor
o_t = f_t.forward(lr) # positive samples
# reconstruction loss, Eq. 1
loss = L1(o_s, hr) + lt * L1(o_t, hr)
# No gradient to o_t from contrastive loss
o_t.detach()
# contrastive loss, Eq. 2
vgg_s, vgg_t, vgg_n = VGG19(o_s, o_t, neg)
loss += lc * CL(vgg_s, vgg_t, vgg_n)
loss.backward() # update信道分裂超分辨率网络 将学生和教师共同与gt的loss forward,再加一个对比损失,有代码
5.DAFL-SR
全称:Data-Free Knowledge Distillation For Image Super-Resolution
链接:知乎 - 安全中心https://openaccess.thecvf.com/content/CVPR2021/papers/Zhang_Data-Free_Knowledge_Distillation_for_Image_Super-Resolution_CVPR_2021_paper.pdf
code:https://github.com/huawei-noah/Efficient-Computing
发表:CVPR 2021
团队:华为诺亚方舟实验室联合北京大学和悉尼大学
 https://zhuanlan.zhihu.com/p/395992657
https://zhuanlan.zhihu.com/p/395992657不好实现
6.Space-Time Distillation for Video Super-Resolution
作者单位:中科大
编者言:将知识蒸馏结合时空特征应用到VSR任务上,加强了学生网络的时空建模能力,验证了知识蒸馏方案在VSR任务上的可行性。
7.Generative Adversarial Super-Resolution at the Edge with Knowledge Distillation
标题:边缘生成性对抗性超分辨与知识蒸馏
链接:https://arxiv.org/abs/2209.03355
作者:Simone Angarano,Francesco Salvetti,Mauro Martini,Marcello Chiaberge
机构:Department of Electronics and Telecommunications, Politecnico di Torino, Turin, Italy, PIC,SeR PoliTo Interdepartmental Center for Service Robotics
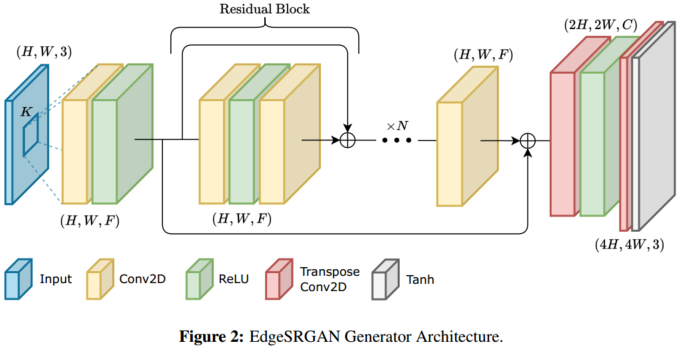
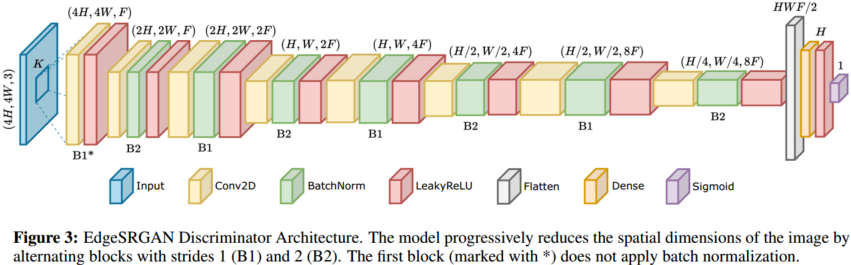
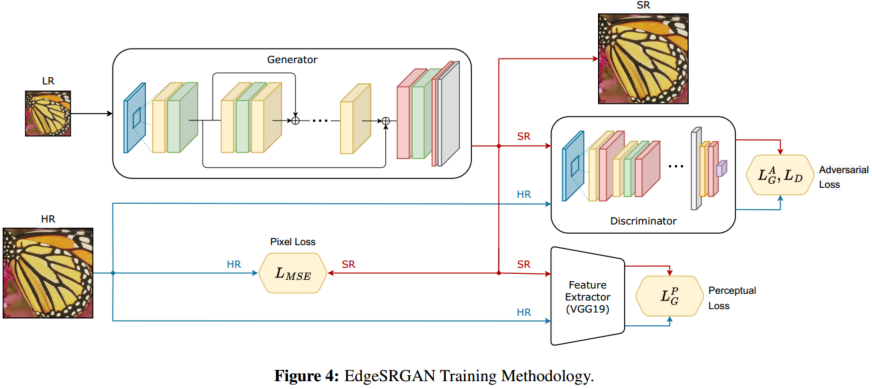
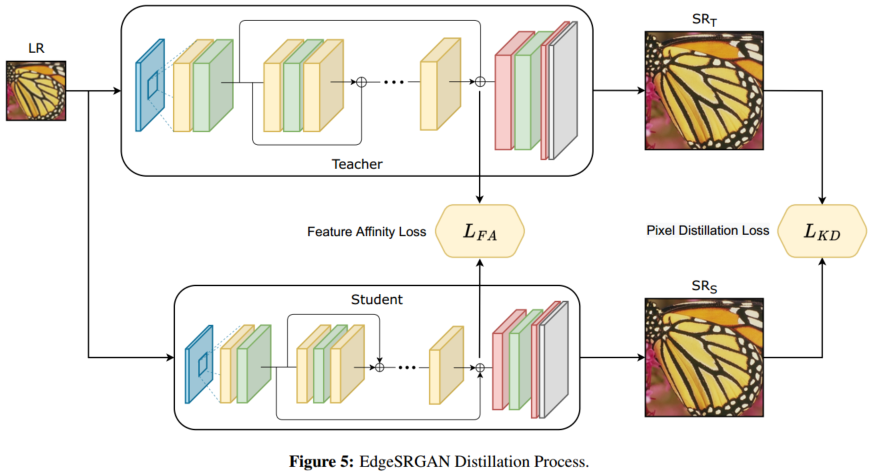
EdgeSRGAN 有代码
文章使用了四种蒸馏方法
-
分块关联知识蒸馏(BRKD):
- 在 BRKD 中,首先创建一个简化的学生模型头部(self.head),用于蒸馏知识。该头部是生成器模型的一部分,但仅用于特定任务。
- 在每个训练步骤中,生成器会生成超分辨率图像(sr)和特征图(feats_s)。这些特征图用于计算特征损失(feat_kd_loss)和输出损失(out_kd_loss)。
- 如果启用了蒸馏(DISTILLATION 不等于 'None'),则从教师模型(teacher)获取特征图(feats_t)。
- 特征图 feats_t 和 feats_s 通过教师模型和学生模型获取,根据配置文件中的 DIST_LAYERS 参数选择对应的层。
- 通过配置文件中的蒸馏方式(DISTILLATION),计算不同的蒸馏损失:
- 对于 FAKD,只计算特征损失(feat_kd_loss)。
- 对于 COKD 和 ABKD,需要构建连接器模型(self.connectors)来对齐特征空间,然后计算连接器损失。
- 对于 BRKD,需要计算特征损失、输出损失和任务特定损失,并根据不同的权重(W、L 和 T)加权蒸馏损失。
- 使用生成器的损失函数计算生成器的梯度,并使用优化器(self.gen_optim)应用梯度来更新生成器的参数。
-
因式化激活知识蒸馏(FAKD):
- FAKD 只涉及特征损失,用于衡量教师模型和学生模型特征之间的差异。
- 在每个训练步骤中,学生模型生成超分辨率图像(sr)和特征图(feats_s),教师模型也生成特征图(feats_t)。
- 特征图 feats_t 和 feats_s 通过教师模型和学生模型获取,根据配置文件中的 DIST_LAYERS 参数选择对应的层。
- 计算特征损失(feat_kd_loss),衡量教师模型和学生模型特征之间的差异。
- 使用生成器的损失函数计算生成器的梯度,并使用优化器(self.gen_optim)应用梯度来更新生成器的参数。
-
基于连接器的知识蒸馏(COKD):
- COKD 使用连接器模型来对齐教师模型和学生模型之间的特征空间。
- 在每个训练步骤中,学生模型生成超分辨率图像(sr)和特征图(feats_s),教师模型也生成特征图(feats_t)。
- 特征图 feats_t 和 feats_s 通过教师模型和学生模型获取,根据配置文件中的 DIST_LAYERS 参数选择对应的层。
- 构建连接器模型(self.connectors),对齐学生模型和教师模型的特征空间。
- 计算连接器损失(perc_loss),衡量连接器模型的输出和教师模型特征之间的差异。
- 使用生成器的损失函数计算生成器的梯度,并使用优化器(self.gen_optim)应用梯度来更新生成器的参数。
-
激活边界知识蒸馏(ABKD):
- ABKD 引入基于边界的损失,用于对齐学生模型和教师模型的激活边界。
- 在每个训练步骤中,学生模型生成超分辨率图像(sr)和特征图(feats_s),教师模型也生成特征图(feats_t)。
- 特征图 feats_t 和 feats_s 通过教师模型和学生模型获取,根据配置文件中的 DIST_LAYERS 参数选择对应的层。
- 根据教师模型的统计信息确定边界值(margin)。
- 计算基于边界的损失(perc_loss),衡量学生模型和教师模型激活边界之间的差异。
- 使用生成器的损失函数计算生成器的梯度,并使用优化器(self.gen_optim)应用梯度来更新生成器的参数。
coheab都是通过connector进行1*1卷积得到大小匹配,进行后续loss计算
五.Paper with code
1.CIFER top1
全称:Knowledge Distillation with the Reused Teacher Classifier
链接:https://arxiv.org/abs/2203.14001
发表:CVPR 2022
团队:浙江大学
1.背景
在本文中,我们提出了一种简单的知识蒸馏技术,并证明它可以显著弥合教师和学生模型之间的性能差距,而不需要详细的知识表示。我们提出的“SimKD”技术如图1所示。
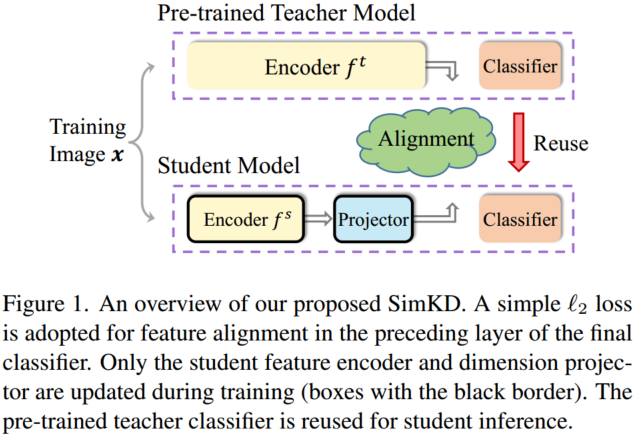
本文认为教师模型强大的班级预测能力不仅归功于那些表达特征,而且同样重要的是,它是一个判别分类器。基于这一论点,我们通过在分类器的前一层的特征对齐来训练学生模型,并直接复制教师分类器进行学生推理。这样,如果我们能够将学生的特征与教师模型的特征完美地结合起来,他们的表现差距就会消失。也就是说,仅特征对齐误差就可以解释学生推理的准确性,这使得我们的知识迁移更容易理解。根据我们的实验结果,一个单一的l2损失对于特征对齐的效果已经非常好了。这种简单的损失使我们不必像以前的工作那样,为了平衡多重损失的影响而仔细调整超参数。
由于从教师和学生模型中提取的特征尺寸通常不同,因此在学生特征编码器之后添加一个投影仪来弥补这种尺寸不匹配。这种投影仪通常在师生压缩中产生不到3%的剪枝比成本,但它使我们的技术适用于任意模型架构。在少数情况下,添加的投影仪加上重用的教师分类器的参数数小于原始学生分类器的参数数,甚至可以扩大剪枝比(见图7)。
我们在标准基准数据集上进行了广泛的实验,并观察到我们的SimKD始终优于各种师生架构组合的所有比较先进的方法。我们还表明,我们的简单技术在多教师知识蒸馏和无数据知识蒸馏等不同场景下都有很好的泛化效果。
2.方法
1.Vanilla Knowledge Distillation
一般来说,当前时代流行的用于图像分类任务的深度神经网络可以看作是一个具有多个非线性层的特征编码器和一个通常包含单个具有softmax激活函数的全连接层的分类器的堆栈。这两个组件都将使用反向传播算法进行端到端训练。符号描述如下。
给定一个来自k类分类数据集的带有一个 one-hot标签y的训练样本x,我们将学生模型倒数第二层的编码特征表示为![]() 。随后将该特征传递到权重为
。随后将该特征传递到权重为![]() 的分类器中,得到logits
的分类器中,得到logits ![]() ,以及带有softmax激活函数σ(·)和温度T的类预测
,以及带有softmax激活函数σ(·)和温度T的类预测![]()
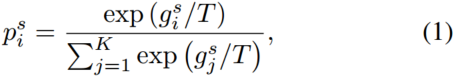
式中![]() 为对应向量的第i个元素,T为软化效果的超参数
为对应向量的第i个元素,T为软化效果的超参数
Vanilla Knowledge Distillation包括两种损失:一种是传统的交叉熵损失,另一种是具有Kullback-Leibler散度的![]() 与软目标
与软目标![]() 之间的预测对的对齐损失。
之间的预测对的对齐损失。
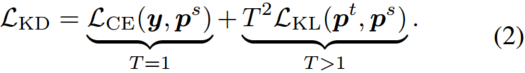
与交叉熵损失相比,引入的预测对齐损失提供了错误类的额外信息,以方便学生训练。由于经过softmax变换后,分配给这些错误类的概率往往很小,因此需要提高该项的温度T,以产生更软的分布,以传递更多的信息。
2.Simple Knowledge Distillation
近年知识蒸馏利用中间层特征或者关系,计算复杂。本文提出了一种简单的知识蒸馏技术,称为SimKD。如图2c所示,SimKD的一个关键要素是“分类器重用”操作,即我们直接借用预先训练好的教师分类器进行学生推理,而不是训练一个新的分类器。这样就不需要标签信息来计算交叉熵损失,使特征对齐损失成为生成梯度的唯一来源。
我们认为教师分类器中包含的判别信息很重要,但在KD的文献中被很大程度上忽视了。考虑一个模型被要求处理具有不同数据分布的多个任务的情况,一个基本的做法是冻结或共享一些浅层作为跨不同任务的特征提取器,同时对最后一层进行微调以学习特定于任务的信息。在这种单模型多任务设置中,现有的工作认为任务不变信息可以共享,而任务特定信息需要独立识别,通常由最终分类器识别。对于KD,在同一数据集上训练具有不同能力的教师和学生模型,类似地,我们可以合理地认为,在不同模型中容易获得的数据中存在一些能力不变的信息,而强大的教师模型可能包含更简单的学生模型难以获得的额外基本能力特定信息。此外,我们假设大多数特定于能力的信息都包含在深层中,并期望重用这些层,即使只有最终分类器也会对学生训练有帮助。
基于这一假设,我们为学生模型提供了教师分类器进行推理,并强制其提取的特征与下面的l2损失函数相匹配。
![]()
其中投影仪P(·)的设计以相对较小的成本匹配特征尺寸,同时足够有效地确保精确对准。我们实际上是在试图揭示重用教师分类器的潜在价值,而不是开发一个复杂的损失函数来进行特征对齐。如图3所示,从预训练的教师模型中提取的特征(深色)和SimKD中提取的学生模型(浅色)被紧密地聚在同一个类中,并在不同的类中明显地分开,这确保了学生特征在重用的教师分类器中被正确地分类。
3.Projector Analysis
投影器P(·)的目的是完美匹配特征向量![]() 和
和![]() ,实现是使用一个具有批处理归一化和ReLU激活的卷积层,它具有
,实现是使用一个具有批处理归一化和ReLU激活的卷积层,它具有![]() 参数。然而,由于教师和学生模型之间的巨大能力差距,这种单层转换可能不足以实现准确的对齐。因此,我们采用最后的特征映射和具有降维因子r的three-layer bottleneck transformation作为替代方案,希望这些将有助于更好地对齐特征。总参数 是:
参数。然而,由于教师和学生模型之间的巨大能力差距,这种单层转换可能不足以实现准确的对齐。因此,我们采用最后的特征映射和具有降维因子r的three-layer bottleneck transformation作为替代方案,希望这些将有助于更好地对齐特征。总参数 是:![]()
这个公式意味着,如果r增加一倍,增加的参数将减少到1 / 4到1 / 2之间,这使我们能够通过改变r将参数复杂性控制在可接受的水平。
这篇重点是分类器重用,那我们是否可以实现反卷积重用
2.IMAGEnet top1
全称:Knowledge Distillation with the Reused Teacher Classifier
链接:
发表:2023
团队:浙江大学
1.背景
贡献:
- 采用了一种新的视角来提高KD,方法是使学生产生(1)具有大规范的特征(2)与基于教师现成特征构建的class-means 一致。
- 广泛研究基线方法来实现这种正则化。研究表明,采用它们可以改进现有的方法,以获得更好的KD性能,例如更高的分类精度和更高的学生检测精度。
- 提出了一种新的简单的损失,同时正则化特征范数和方向,称为ND损失。实验表明,现有的额外使用ND损失的KD方法比使用基线正则化器获得更好的学生表现。
2.知识蒸馏中的正则化特征范数与方向
1.Notations
在不失去一般性的前提下,我们将分类神经网络视为两个模块:特征提取器![]() ,分类器
,分类器![]() ,分别由Θ和W参数化。对于教师,给定输入数据x,我们表示其嵌入特征为
,分别由Θ和W参数化。对于教师,给定输入数据x,我们表示其嵌入特征为![]() logits为
logits为![]() ,类似地,学生输出x的嵌入特征为
,类似地,学生输出x的嵌入特征为![]() ,logits为
,logits为![]() ,
,![]() = softmax(
= softmax(![]() ;
;![]() ),其中
),其中![]() 为温度(从头开始训练模型时默认为1)。
为温度(从头开始训练模型时默认为1)。
给定N个属于C类的训练集,xi和它的标签yi(其中i = 1,…, N),我们通过最小化所有训练数据上的交叉熵(CE)损失![]() 来训练分类模型(例如,教师)。
来训练分类模型(例如,教师)。

2. Baseline Methods of Feature Norm and Direction Regularizatio
在这项工作中,我们关注的是在倒数第二层的嵌入特征![]() ,它直接用于分类。我们计算第k个类的类均值为
,它直接用于分类。我们计算第k个类的类均值为![]() ,其中
,其中![]() 是属于类
是属于类![]() 的训练样例的指标集。我们现在介绍一些简单的技术,利用
的训练样例的指标集。我们现在介绍一些简单的技术,利用![]() 在特征范数和方向上正则化学生特征。
在特征范数和方向上正则化学生特征。
(1). Feature Norm Regularization
![]() 如图2b所示,学生等小容量模型产生小范数特征。为了训练学生产生更大范数的特征,方法是最小化学生和教师特征之间的L2距离:
如图2b所示,学生等小容量模型产生小范数特征。为了训练学生产生更大范数的特征,方法是最小化学生和教师特征之间的L2距离:
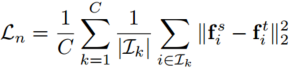
虽然最小化Eq. 2是特征蒸馏中的一种常见做法,但它隐式地训练学生生成具有接近相应的大规范教师特征的规范的特征。
![]() 我们现在描述一个损失来明确地增加学生特征的范数。通过最小化来逐渐增加特征范数:
我们现在描述一个损失来明确地增加学生特征的范数。通过最小化来逐渐增加特征范数:
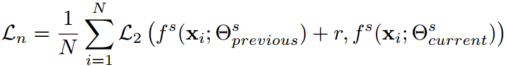
其中![]() 和
和![]() 分别为早期检查点和当前优化模型的参数;r是在训练过程中增加学生特征范数的步长。
分别为早期检查点和当前优化模型的参数;r是在训练过程中增加学生特征范数的步长。
(2).Feature Direction Regularization
![]() 使用一个简单的基于余弦相似度的损失项,根据其对应的类均值
使用一个简单的基于余弦相似度的损失项,根据其对应的类均值![]() 正则化
正则化![]() 的特征方向:
的特征方向:
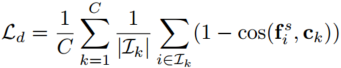
![]() 还考虑了类间示例和类方法:
还考虑了类间示例和类方法:
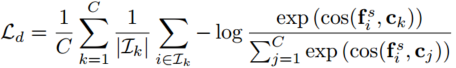
3.The Proposed ND Loss
设![]() 和
和![]() 分别为由学生和老师计算的输入示例x的嵌入特征。基于x的基真标签y,我们有它对应的类均值c。我们计算
分别为由学生和老师计算的输入示例x的嵌入特征。基于x的基真标签y,我们有它对应的类均值c。我们计算![]() 沿c方向的投影:
沿c方向的投影:![]() 。我们表示单位向量
。我们表示单位向量![]() ,
,![]() 。物理意义见图3。
。物理意义见图3。
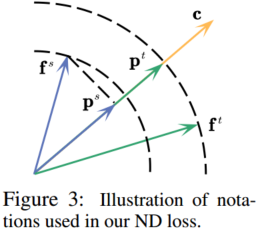
当![]() 的范数较小,或者其投影
的范数较小,或者其投影![]() 的范数较小,即
的范数较小,即![]() 时,我们鼓励学生输出更大的范数特征,并通过最小化
时,我们鼓励学生输出更大的范数特征,并通过最小化![]() 来将它们与教师的类均值对齐。由于不同样例的特征规范可能会有一个数量级的差异(见图2a),因此用上述方法进行学习可能会从特定的训练数据中产生人为的较大梯度,并对训练产生负面影响。因此,我们将上面的式子除以
来将它们与教师的类均值对齐。由于不同样例的特征规范可能会有一个数量级的差异(见图2a),因此用上述方法进行学习可能会从特定的训练数据中产生人为的较大梯度,并对训练产生负面影响。因此,我们将上面的式子除以![]() ,就等于
,就等于![]() :
:
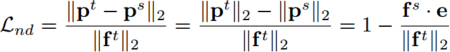
最小化![]() 相当于同时(1)增加
相当于同时(1)增加![]() 的范数和(2)减小
的范数和(2)减小![]() 与类均值c之间的角距离。
与类均值c之间的角距离。
当![]() 的范数,即
的范数,即![]() 时,我们不需要来
时,我们不需要来![]() 帮助学生增加特征范数。相反,我们使用下面的公式来提取特征范数的影响:
帮助学生增加特征范数。相反,我们使用下面的公式来提取特征范数的影响: 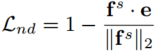
我们合并两个公式,并对所有训练样本取平均值作为ND损失(去掉常数1):
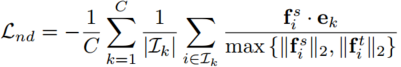
与现有的KD方法兼容,我们的ND损耗lld可以与CE损耗![]() 和KD损耗
和KD损耗![]() 一起使用,培养学生:
一起使用,培养学生:
![]()
α和β分别为![]() 和
和![]() 的权值。
的权值。![]() 取决于蒸馏方法。
取决于蒸馏方法。
另外,我们用精馏法KD研究![]() ,因此
,因此![]() 。
。
ND loss鼓励学生在训练过程中输出更大的范数特征。重要的是,学生的特征规范可以大于教师的特征规范。此外,ND loss直接最小化了学生特征与教师定义的class均值之间的角距离。这是训练学生获得更好的分类精度所需要的属性。
新用损失函数,用处不大
3.IMAGEnet top2
全称:在知识蒸馏中发挥更大教师模型和更强训练策略的作用 Knowledge Distillation from A Stronger Teacher
链接:https://arxiv.org/pdf/2205.10536.pdf
code:https://github.com/hunto/DIST_KD
发表:NeurIPS 2022
团队:商汤
1.背景
题目中 "更强的教师模型",有两个含义:尺寸更大,数据增强策略更先进。
获得更好的知识蒸馏性能的方式之一是尝试不同类型的教师模型 (比如说使用更大的教师模型或者更强的训练策略),作者在本文中认为:应该借助 "更强的教师模型" 进行知识蒸馏。而针对什么是 "更强的教师模型",作者推广实验给出了一些建议:
-
除了扩大模型规模,还可以通过先进的训练策略,如标签平滑和数据增强 (label smoothing and data augmentation),以获得更强的教师模型。但是仅仅有这些是不够的。配备了更强的教师模型之后,学生模型在正常 KD 下的表现可能会下降,甚至性能还不如不用 KD。
-
当将教师和学生的训练策略转换为更强的训练策略时,教师和学生之间的差异往往会变得相当大。在这种情况下,通过 KL 散度来精确恢复预测可能具有挑战性,并导致 KD 的失败。
-
保留教师和学生模型之间的预测关系非常重要。在将知识从 teacher 传给 student 时,我们其实真正关心的是教师模型的偏好 (预测的相对 Rank),而不是去恢复其预测结果的绝对值。教师预测与学生预测之间的相关性有利于放松 KL 散度的精确匹配,提取内在关系 (intrinsic relations)。
2.DIST 中的类间匹配
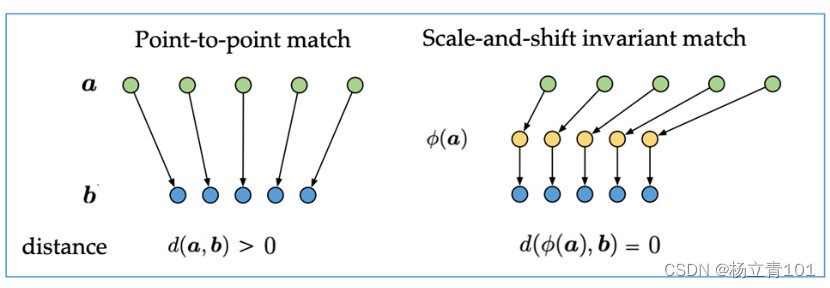
预测分数代表了一个模型对于所有类别的置信度,那么如果希望教师模型和学生模型的输出以一种更加轻松的方式匹配,作者认为只需要把各个类别输出置信度的关系匹配好就可以了,也就是去匹配教师模型预测结果的相对顺序。具体如下:
假设现在有一个距离度量方式![]()
精准匹配的意思是: 当a=b时有![]() 。
。
松弛匹配的意思是![]() 其中
其中![]() 是额外的映射
是额外的映射
也就是说, 在松弛匹配的要求下,![]() 并不意味着a和b是完全相等的,但是要注意映射
并不意味着a和b是完全相等的,但是要注意映射![]() 应是等值的,并不影响预测向量的语义信息和推理结果。
应是等值的,并不影响预测向量的语义信息和推理结果。
因此,一个简单而有效的映射方式是正线性变换,它就满足松弛匹配的要求:![]()
式中,m1,m2,n1,n2是常数,且有m1*m2>0.d(,)可以选择 皮尔逊相关系数
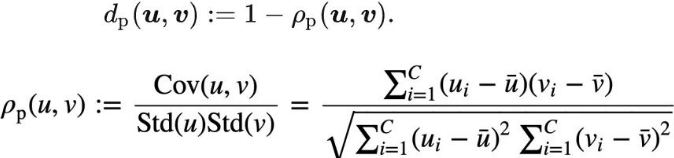
式中,Cov(u,v)是向量u,v的协方差,Std(u)是向量u的标准差。
相当于把correlation视为relation,它舍弃了传统的 KL 散度的精确匹配的模式,而是采用一种较为松弛的模式,希望保持住每个实例教师和学生模型输出向量的线性相关关系。作者称这样的匹配为类间匹配 (inter-class relation),写成公式就是:
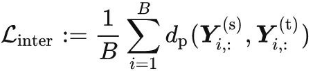
3.DIST 中的类内匹配
除了类间的关系,作者还考虑到了单个样本中类内的关系。作者认为每个类的,多个实例的,预测分数也是有用的。
举个例子, 我有三张图片, 里面的内容分别是 "猫", "狗", 和 "飞机", 它们对于 "猫" 这个类别的预测结果分别是e,f,g.那么, 猫图的对应 "猫" 类别的预测结果应该是最大的, 飞机那个图对应 "猫" 类别的预测结果应该是最小的。所以,e>f>g 的关系也应当由教师模型传给学生。
受到以上思想的启发,作者也觉得应该进行类内匹配:
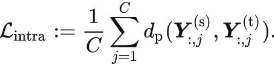
因此,如下图3所示,本文最终的蒸馏策略是:
![]()
式中, ![]() 是超参数。作者通过类间匹配和类内匹配的方式,赋予了学生或多或少的自适应匹配教师网络输出的自由,从而在很大程度上提高了蒸馏性能。
是超参数。作者通过类间匹配和类内匹配的方式,赋予了学生或多或少的自适应匹配教师网络输出的自由,从而在很大程度上提高了蒸馏性能。
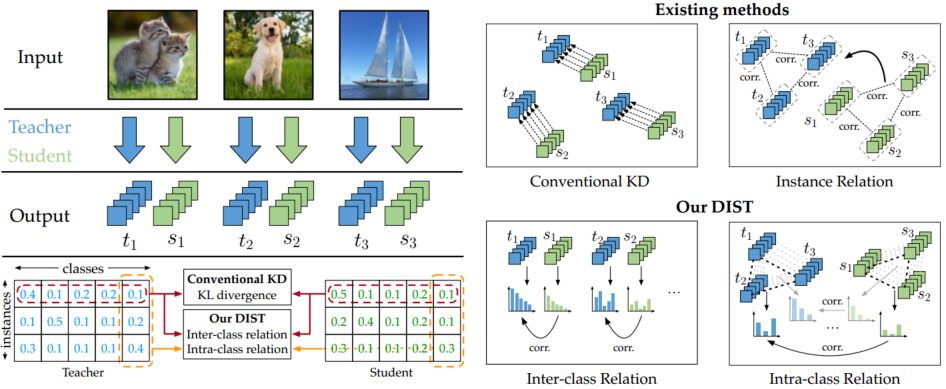
PyTorch 伪代码:
import torch.nn as nn
def cosine_similarity(a, b, eps=1e-8):
return (a * b).sum(1) / (a.norm(dim=1) * b.norm(dim=1) + eps)
def pearson_correlation(a, b, eps=1e-8):
return cosine_similarity(a - a.mean(1).unsqueeze(1), b - b.mean(1).unsqueeze(1), eps)
def inter_class_relation(y_s, y_t):
return 1 - pearson_correlation(y_s, y_t).mean()
def intra_class_relation(y_s, y_t):
return inter_class_relation(y_s.transpose(0, 1), y_t.transpose(0, 1))
class DIST(nn.Module):
def __init__(self, beta, gamma):
super(DIST, self).__init__()
self.beta = beta
self.gamma = gamma
def forward(self, z_s, z_t):
y_s = z_s.softmax(dim=1)
y_t = z_t.softmax(dim=1)
inter_loss = inter_class_relation(y_s, y_t)
intra_loss = intra_class_relation(y_s, y_t)
kd_loss = self.beta * inter_loss + self.gamma * intra_loss
return kd_loss对分类做的,用处大不
4.IMAGEnet top3
全称:在知识蒸馏中发挥更大教师模型和更强训练策略的作用 Knowledge Distillation from A Stronger Teacher
链接:Ensemble Knowledge Distillation for Learning Improved and Efficient Networks - 百度学术
code:GitHub - Adlik/model_optimizer
发表:CVPR 2019
作者提出了一种蒸馏方法,让教师和网络都由多个子网络构成,将所有子网络的输出结果求和后通过softmax得到分类判决结果,在进行蒸馏时,对学生和教师的每一个子网络分别进行蒸馏,其网络结构如下:
其损失函数为:
![]()
其中的三个表达式分别代表教师网络的损失,学生网络的损失和蒸馏损失,![]()
 为调节三者重要性的超参数,取值均为0,0.5,1三者之一。而蒸馏损失即为所有子网络蒸馏损失之和,由KL散度和MSE损失两部分组成:
为调节三者重要性的超参数,取值均为0,0.5,1三者之一。而蒸馏损失即为所有子网络蒸馏损失之和,由KL散度和MSE损失两部分组成:
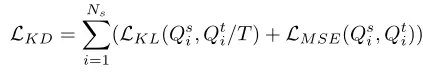

















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









