







MySQL存储数据是以行为单位的,查询某条数据的某一列,就会把整行拿到,如果列比较多,就比较慢,不想要的列也会查出来!宽表垂直拆分,高表水平拆分(如日志文件按日期拆分)。增加列也可使用JSON方式动态增加。但MySQL的问题是存储大小受限(例如InnoDB最大64T)。MySQL是面向行的,适合查询,但不利于统计分析,比如要求某列的平均值,会把不需要的列都查出来,效率变低了。而HBase是面向列的存储,适合统计分析。
HBase 数据模型
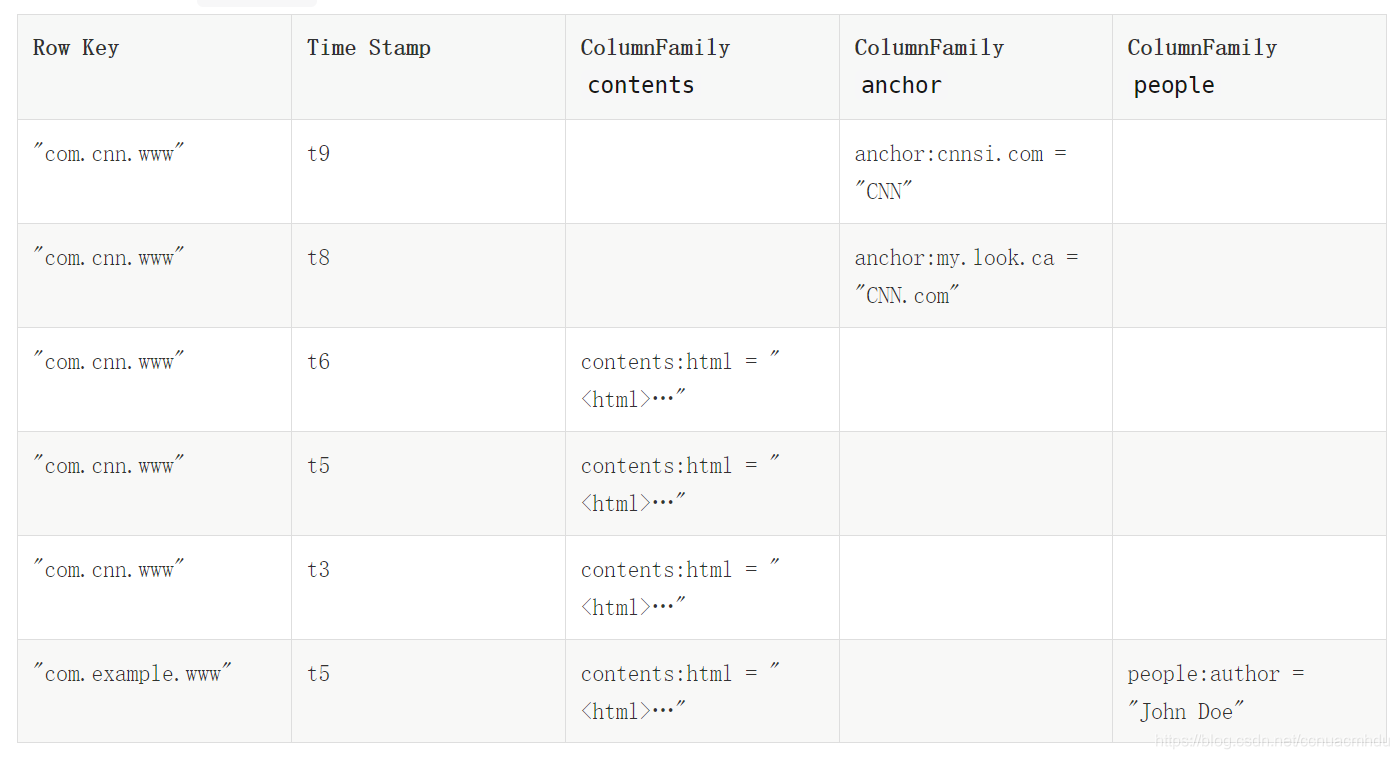
The following represents the same information as a multi-dimensional map. This is only a mock-up for illustrative purposes and may not be strictly accurate.
{
"com.cnn.www": {
contents: {
t6: contents:html: "<html>..."
t5: contents:html: "<html>..."
t3: contents:html: "<html>..."
}
anchor: {
t9: anchor:cnnsi.com = "CNN"
t8: anchor:my.look.ca = "CNN.com"
}
people: {}
}
"com.example.www": {
contents: {
t5: contents:html: "<html>..."
}
anchor: {}
people: {
t5: people:author: "John Doe"
}
}
}
Row Key,行的唯一标识,类似于主键;按照字典序进行排列存储(字节数组方式存储,利于压缩。HBase存储是有序的,像MySQL等数据库是无序的);最大长度是64KB,但是建议长度是10-100byte。
命名空间演示,默认右两个,自己可以创建一个,其实就是类似于MySQL中的数据库
安装
-
安装并配置HBase
1. 官网下载并解压 tar -zxvf hbase-1.4.13-bin.tar.gz -C 解压目录 2. 配置hbase-env.sh // 把JAVA_HOME改成自己电脑上的JDK路径,去掉# # The java implementation to use. Java 1.7+ required. # export JAVA_HOME=/usr/java/jdk1.6.0/ // true改成false # Tell HBase whether it should manage it's own instance of Zookeeper or not. # export HBASE_MANAGES_ZK=true // 根据下面提示,注释掉下面两个配置 # Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+ export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m" export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m" 3. 配置hbase-site.xml <configuration> <property> <name>hbase.rootdir</name> <value>hdfs://localhost:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>localhost:2181,localhost:2182,localhost:2183</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/mi2/env/zookeeper/zkData</value> <description>Property from ZooKeeper's config zoo.cfg. The directory where the snapshot is stored. </description> </property> </configuration> 4. regionservers 这里regionservers使用本机,就用默认的localhost。若是分布式,就每行写一个机器 5. 建立Hadoop配置文件的软连接到Hbase ln -s /home/mi2/env/hadoop/etc/hadoop/core-site.xml /home/mi2/env/hbase/conf/core-site.xml ln -s /home/mi2/env/hadoop/etc/hadoop/hdfs-site.xml /home/mi2/env/hbase/conf/hdfs-site.xml -
启动HBase
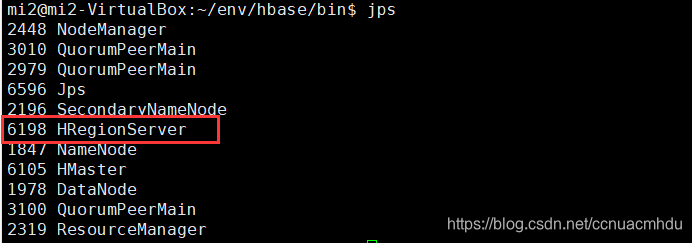
/hbase/bin/start-hbase.sh
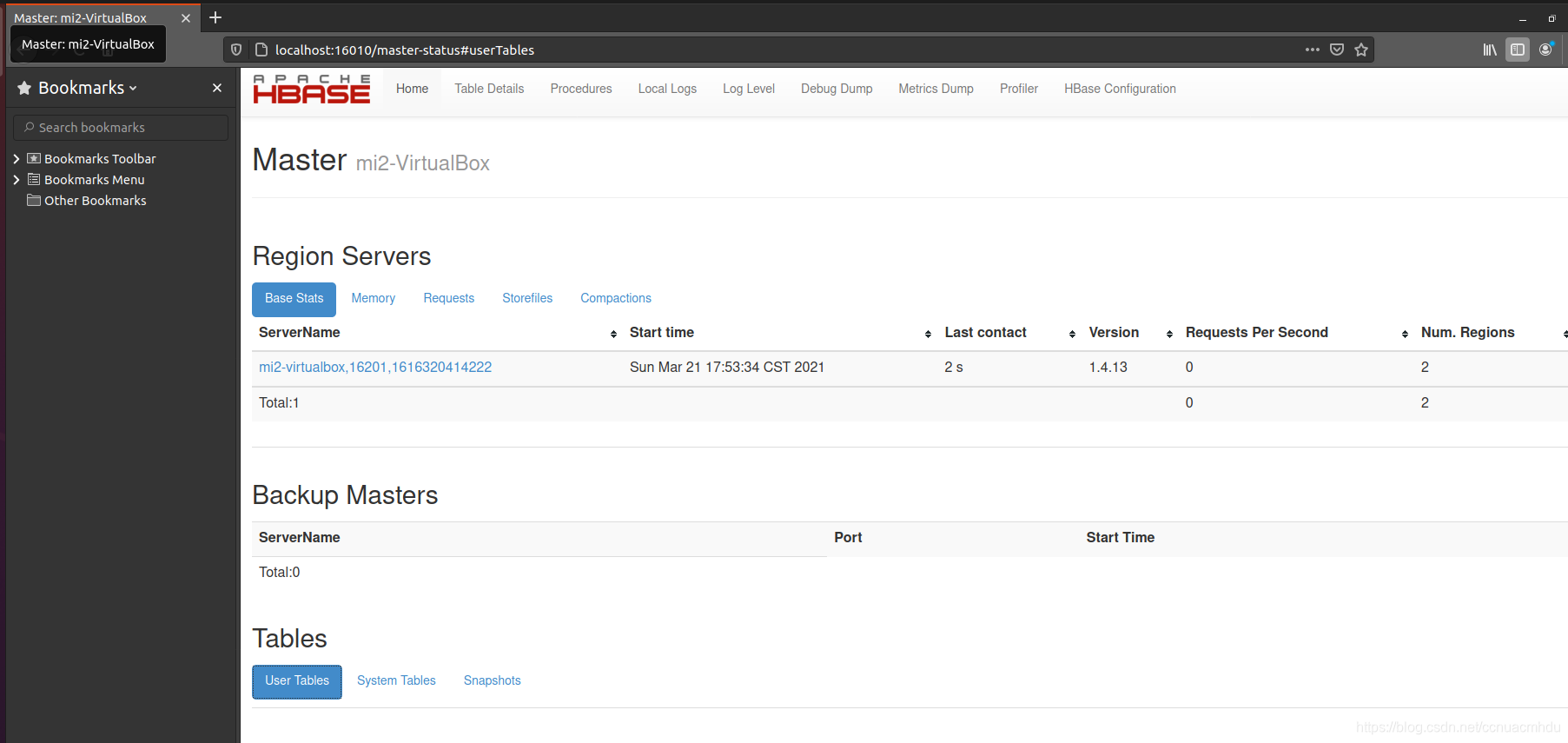
访问页面http://localhost:16010,没问题的话,HBase就启动成功了!
HBase Shell
/hbase/bin/hbase
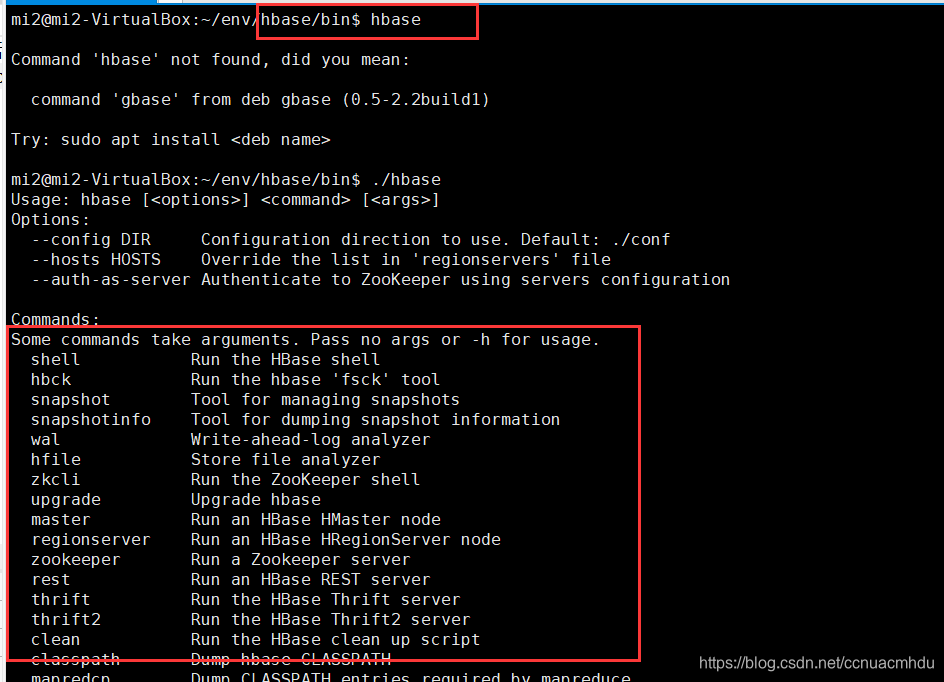
/hbase/bin/hbase shell

注意:进入hbase命令行,输入的字符退格键还删不掉,要用Ctrl+Backspace
help
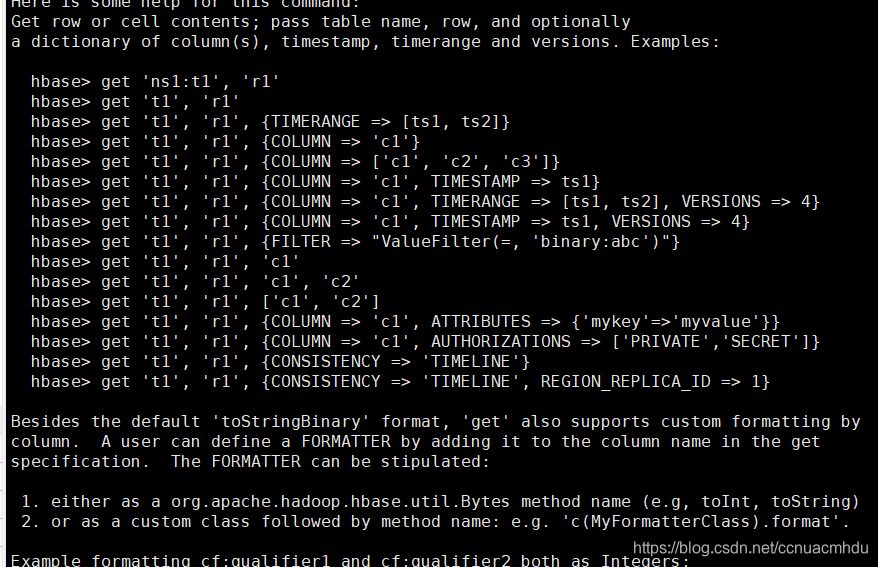
get help
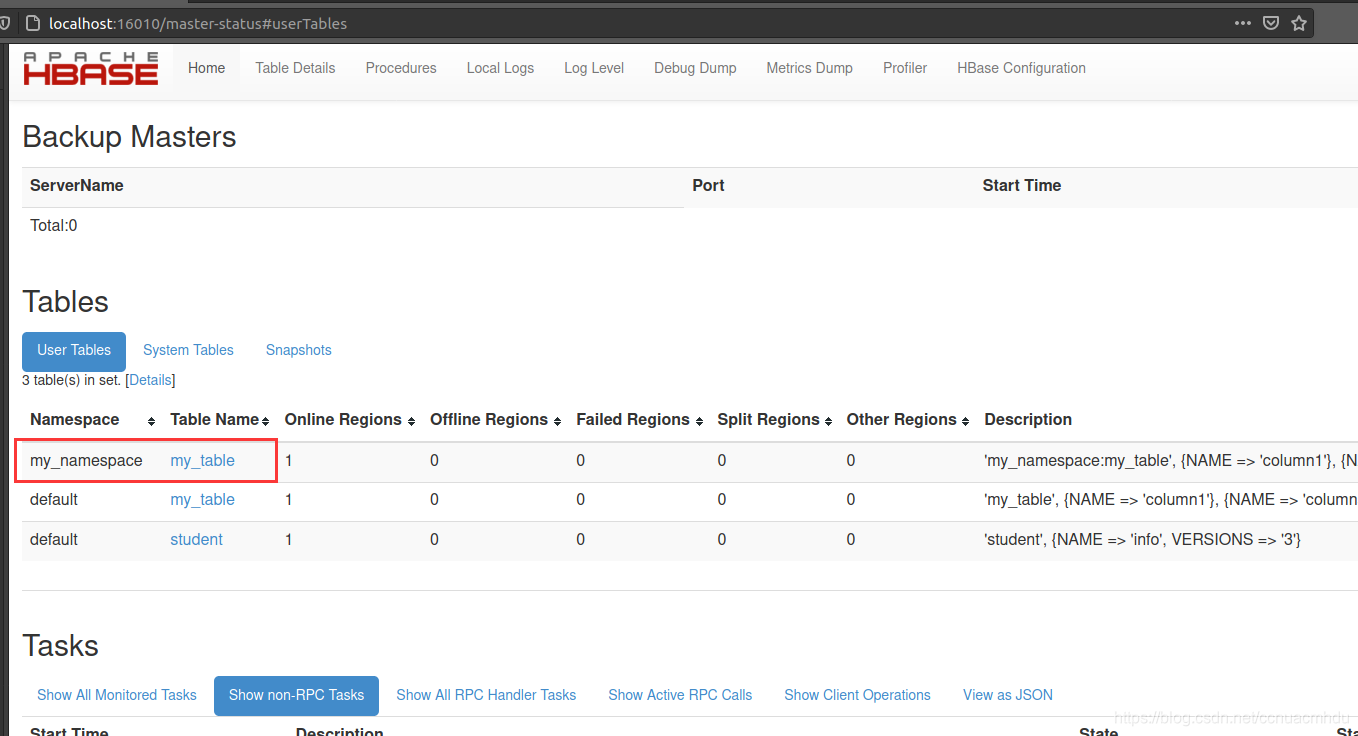
// 查看当前命名空间(类似于MySQL的数据库)下的所有表
list
// 创建一个表student,列族是info。查看hbase网页 http://localhost:16010,可看到该表
create 'student', 'info'
// 查看表结构信息
describe 'student'
// 插入数据
put 'student', '1001', 'info:sex', 'male'
put 'student', '1002', 'info:sex', 'male'
put 'student', '1001', 'info:name', 'zhangsan'
// 查看表所有数据
scan 'student'
// 查看表数据,row key起始标明,左闭右开
scan 'student', {STARTROW => '1001', STOPROW => '1001'} // 会打印1001这条数据
scan 'student', {STARTROW => '1001'}
// row key已存在,新值会覆盖(不准确,其实是时间戳不同的新版本)
put 'student', '1001', 'info:name', 'Nick'
// 查询数据
get 'student', '1001'
get 'student', '1001', 'info:name'
// 统计表student共多少行
count 'student'
// 删除rowkey=1001的全部数据
deleteall 'student', '1001'
// 删除rowkey=1001,列为info:sex的数据
delete 'student', '1001', 'info:sex'
// hbase没有事务,但有原子性,如果某表有人使用,别人用完之后就先标记禁用(禁止别人再用),再清空表
truncate 'student'
// 删除表,得先禁用,才能删除掉
disable 'student'
drop 'student'
// 该表表结构,列族info,保留3个版本
alter 'student', {NAME=>'info', VERSIONS=>3}
put 'student', '1002', 'info:name', 'zhangsan'
put 'student', '1002', 'info:name', 'lisi'
put 'student', '1002', 'info:name', 'wangwu'
put 'student', '1002', 'info:name', 'zhaoliu'
// 会显示最近三个版本
get 'student', '1002', {COLUMN=>'info:name', VERSIONS=>3}
// 也会显示最近三个版本,因为表结构是只保留三个版本
get 'student', '1002', {COLUMN=>'info:name', VERSIONS=>4}
// 删除数据
delete 'student', '1002', 'info:name'
// 惊奇发现,之前所有历史版本都还在!!其实put都是增加行,delete只会标记,等待合适的时候删除,类似于JAVA的GC
scan 'student', {RAW => true, VERSIONS => 10}
// 查看有哪些命名空间
list_namespace
// 创建命名空间
create_namespace 'my_namespace'
// 不指定命名空间,创建的表在默认的命名空间default下
create 'my_table', 'columns', 'column1'
// 指定命名空间创建表
create 'my_namespace:my_table', 'columns', 'column1'
// 查看某命名空间下的所有表
list_namespace_tables 'my_namespace'
HBase 架构
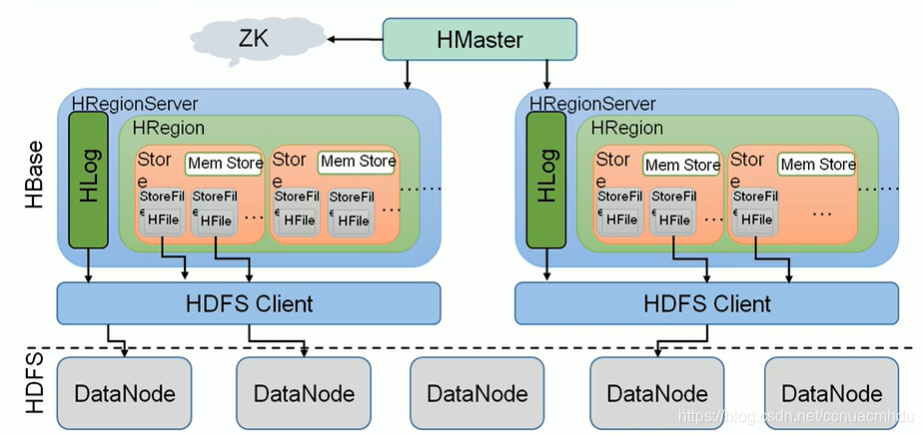
HMaster负责把HRegion(类似分区)分配给HRegionServer,每一个HRegionServer可以包含多个HRegion,多个HRegion共享HLog,HLog(write ahead log,预写日志,持久化存储)用来做灾难恢复。每一个HRegion由一个或多个Store组成,一个Store对应表的一个列族,每个Store中包含与其对应的MemStore以及一个或多个StoreFile(是实际数据存储文件HFile的轻量级封装),MemStore是在内存中的,保存了修改的数据,MemStore中的数据写到文件中就是StoreFile。
HMaster负责为RegionServer分配Region,维护整个集群的负载均衡;维护集群的元数据信息;发现失效的Region,并将其分配到正常的RegionServer。
HBase其实是一个管理HDFS的软件,数据是存在HDFS中的。
数据读取流程
hbase:meta表记录了某个表table存放在某台机器server1上,而meta表存放位置等信息记录在了Zookeeper。于是乎,查询数据的时候先通过Zookeeper找到meta表所在的机器server2,访问server2拿到table所在的机器server1,访问server1找到对应的分区(HRegion),然后先查写缓存(MemStore),写缓存没有就查读缓存(blockCache),读缓存也没有就查HFile并放入blockCache一份。

HBase查询流程较复杂,效率较低,不适合实时查询(MySQL适合),而是做统计分析用的。
数据写入流程
写HBase的时候(先通过Zookeeper找到meta,再通过meta找到查询表所在的机器,再通过RegionServer查到所在Region),同时写HLog(万一MemStore没了,可以用来恢复数据同步到HDFS)和MemStore(写缓存,之后查这份数据比较快,何时同步到HDFS由HBase决定),如果MemStore写不下了(缓冲区有限,默认128M),会把缓冲区数据写入HDFS并删除对应的HLog中的数据(flush),再写MemStore。写了很多小文件的话,会把小文件合并,当合并生成的文件比较大的时候有可能会拆成不同的Region(HMaster负责将其分配到哪个RegionServer)。
API
亲测Windows本地IDEA程序连接不了虚拟机中的HBase!笔者采用本地打包上传到虚拟机的方式测试下API。
package com.example.bigdata.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import java.io.IOException;
public class TestHbaseApi01 {
public static void main(String[] args) throws IOException {
// 查看源码,可知从类路径下加载hbase-default.xml和hbase-site.xml,
// Maven把java目录下的类编译后并将其和resources下的文件放在了target下(类路径),
// java目录和resources路径都可认为是类路径
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
System.out.println(connection);
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf("student");
boolean flag = admin.tableExists(tableName);
System.out.println(flag);
}
}
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost:2181,localhost:2182,localhost:2183</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/mi2/env/zookeeper/zkData</value>
<description>Property from ZooKeeper's config zoo.cfg. The directory where the snapshot is stored. </description>
</property>
</configuration>
添加打包插件:
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
执行程序结果:

参考资料
[1] 尚硅谷HBase教程
[2] hbase官方文档

















 1294
1294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









