







今天登龙跟大家分享下我对多维特征的读取、缩放和多变量梯度下降算法的理解,文章不长,有理论也有实际的代码,下面开始,Go!
一、如何表示多维特征?
1.1 特征缩放
实际项目中在读取多维特征之前需要先对数据进行缩放,为什么呢?
因为在有了多维特征向量和多变量梯度下降法后,为了帮助算法更快地收敛,还需要对选用的特征进行尺度缩放,其实就是缩小特征值,将多个特征的值都缩小到同样大小的区间,通常是缩小到 [-1, 1] 周围。
以下图为例:
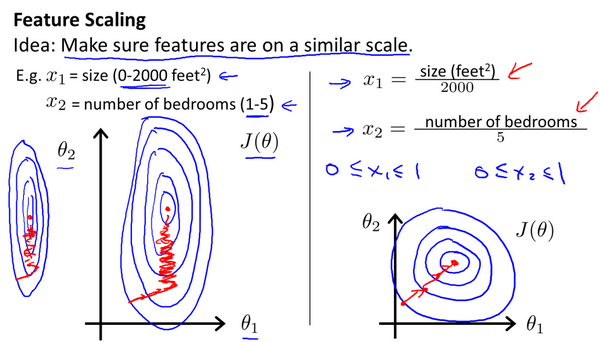
在没有进行特征缩放之前,两参数梯度下降的等高线图呈竖的椭圆形,这是因为横轴和纵轴参数范围不同,进而导致算法在寻找最小值时会迭代很多次。
而当进行缩放使得横纵轴范围大致相同后,等高线图基本呈圆形,算法在迭代的时候往一个方向很快就能找到最小值,大大减少迭代次数。
缩放的最终结果不一定非要准确到 [-1, 1],比如 [-3, 3],[-2, 1] 这些范围不是太大都是可以的,一个又常用有简单的特征缩放计算方法是:
x n = x n − μ n s n x_n=\frac{x_n - \mu_n}{s_n} xn=snxn−μn
其中 μ n {\mu_{n}} μn 是平均值, s n {s_{n}} sn 是(max - min),比如用这个公式将所有的房屋面积和卧室数量进行缩放:
- x 1 = ( s i z e − 1000 ) / 2000 x_1 = (size - 1000) / 2000 x1=(size−1000)/2000,其中 1000 是面积平均值,2000 是最大面积减最小面积。
- x 2 = ( b e d r o o m s − 2 ) / 5 x_2 = (bedrooms - 2) / 5 x2=(bedrooms−2)/5,其中 2 是卧室数量平均值,5 个最大卧室数量减去最小卧室数量。
理论学会后,再来学习下实际的特征缩放代码:
# 特征缩放
def normalize_feature(df):
# 对原始数据每一列应用一个 lambda 函数,mean() 求每列平均值,std() 求标准差
return df.apply(lambda column: (column - column.mean()) / column.std())
我们用这个函数来实际缩放一下含有 2 个特征的原始房价数据:
# 读取原始数据
raw_data = pd.read_csv('ex1data2.txt', names = ['square', 'bedrooms', 'price'])
# 显示前 5 行
raw_data.head()
# 对原始数据进行特征缩放
data = normalize_feature(raw_data)
# 显示缩放后的前 5 行数据
data.head()
可以看到缩放后的数据范围基本都在 [ − 1 , 1 ] [-1, 1] [−1,1] 区间左右,说明我们的特征缩放成功了 _!下面来学习如何读取多维特征!
1.2 读取多维特征
还记得上篇文章我们介绍的第一个机器学习算法吗?
即通过房屋面积来预测价格,这个问题中只使用一个输入特征房屋面积,可现实生活中要解决的问题通常都含有多个特征,因为用多个特征训练出的模型准确度更高。
那么如何机器学习算法如何处理多个特征的输入呢?
我们还用预测房价的例子,不过这次要增加另外 3 个特征,卧室数量,房屋楼层,房屋年龄:
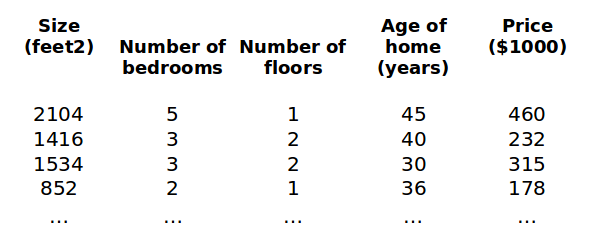
这样一来,我们就有了 4 个输入特征了,特征多了,表示的方法也要升升级了:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4996
4996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









