







目录
一. 梯度
梯度(gradient)是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。由于函数在该点处沿着梯度的方向变化最快,变化率最大,我们常常会利用这个特性来优化模型。而Pytorch有一个特性,即会自动帮你求变量或参数的梯度,具体例子如下:
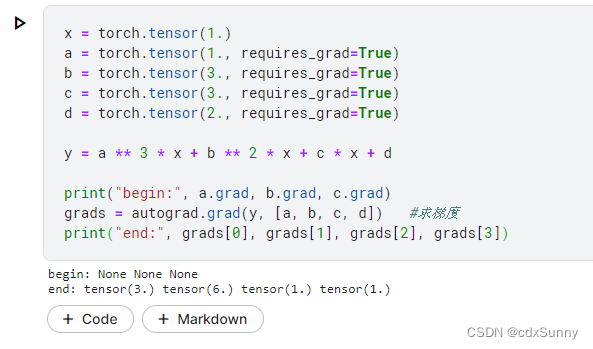
上图求的是 中系数a,b,c,d的偏导:
在机器学习和深度学习中常见的利用梯度来优化模型的方法有梯度下降法(Gradient Descent),对损失函数的值Loss求梯度,以最快的方式来找到Loss最小的点,来减小模型的误差。
二. 损失Loss
损失函数是在学习机器学习和深度学习过程中非常重要的一个函数和评价指标。它代表的是我们模型的预测值与真实值之间的误差大小。损失函数有平方损失函数MSE(主要用于回归问题)、交叉熵损失函数(主要用于分类问题)等。以下我们只介绍这两种常用的。
(1)平方损失函数
求你预测的值和真实值的差的平方。
数学公式表达为: ,其中y表示真实值,f(x)表示预测值。
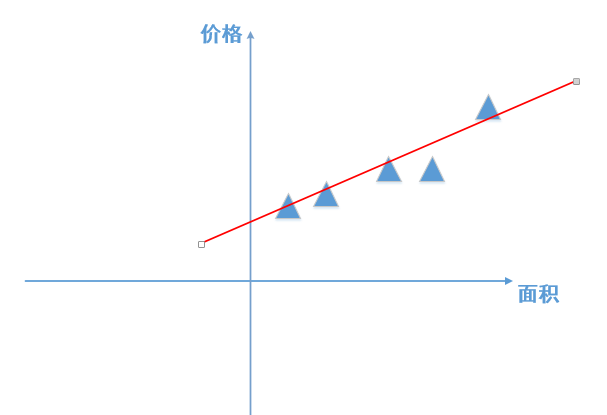
公式的物理意义:如图,图中的三角形代表真实的点,红色的直线代表我们模型预测得到的直线,损失Loss代表所有真实的点在竖直方向上到红色直线距离的和。
(2)交叉熵损失函数
交叉熵损失函数常用于二分类和多分类问题。交叉熵是信息论里面的概念,刻画的是两个概率分布之间的距离。给定两个概率分布p和q,通过q来表示p的交叉熵为:
其中,p代表真实值, q代表的是预测值。
交叉熵损失函数:
其中,代表真实值,
代表预测的值。交叉熵损失函数的输入值常常是Softmax函数的输出值。
在二分类问题中交叉熵损失函数也可表达为:
其中,n样本数量,y表示实际的标签值,表示预测的值。
交叉熵损失函数的例子如下:
假设有一个三分类问题,某个样例的正确答案是(1, 0, 0)
A模型经过softmax回归之后的预测答案是(0.5, 0.2, 0.3)
B模型经过softmax回归之后的预测答案是(0.7, 0.1, 0.2)
利用公式
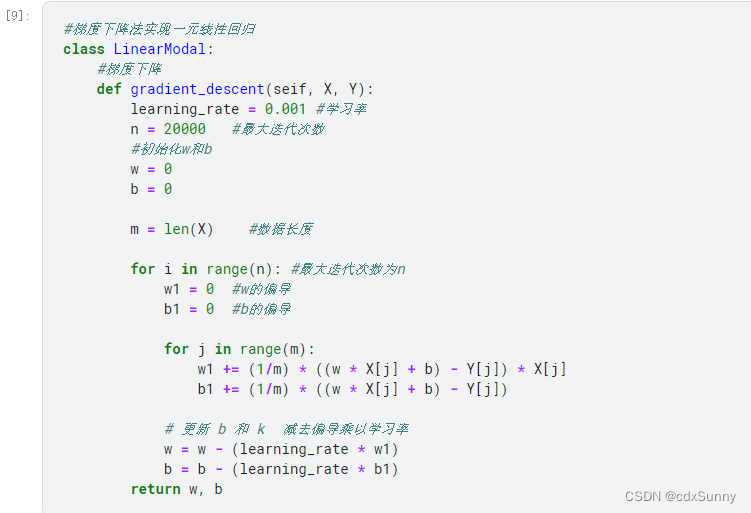
三. 实现梯度下降算法
准备100个训练样本来训练模型。
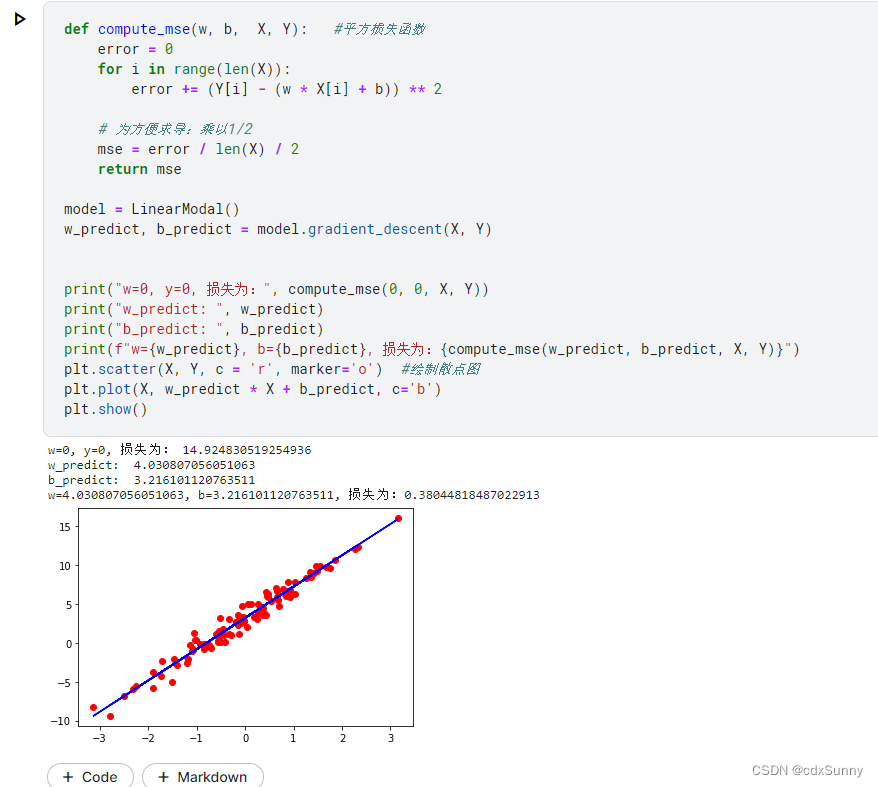
将所有样本绘制在图上:
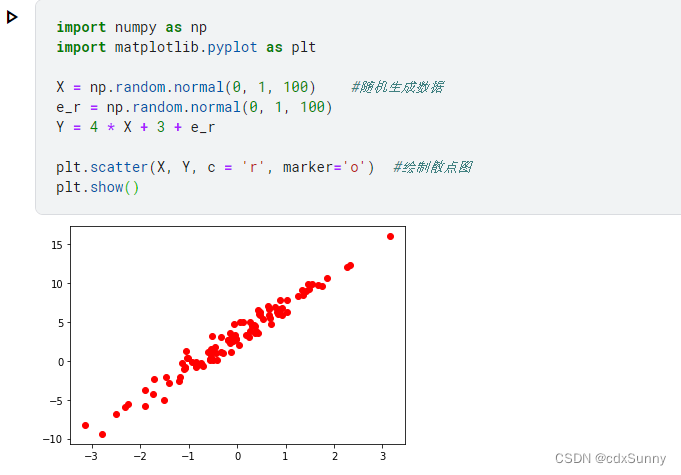
实现梯度下降算法,其中w1,b1是指w和b对y的偏导,最后用w = w - 学习率 * 偏导 来更新参数w的值来时Loss减小:















 1034
1034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









