







目录
1. 下载以及可视化数据集(Download and Visualize the Data)
2. 定义网络(Define the Network Architecture)
3. 定义损失函数和优化器(Specify Loss Function and Optimizer)
5. 测试网络(Test the Trained Network)
一、背景
说到机器学习,不得不说深度学习,说到深度学习就不得不说神经网络。神经网络是目前深度学习最重要的技术。其中,用来构建神经网络的深度学习框架主流的有pytorch和tensorflow等。
目前我们可以接触到的神经网络有:前馈神经网络(全连接神经网络)、卷积神经网络以及循环神经网络(Recurrent Neural Network, RNN)。其中,卷积神经网络主要用于计算机视觉领域,而循环神经网络主要用于自然语言处理领域。
- 卷积神经网络:卷积神经网络中右延伸出了许多的网络,比如说googleNet、ResNet(残差神经网络),AlexNet等。其中,本人认为最重要的还是ResNet残差神经网络。ResNet认为神经网络的层数不是越深越好,神经网络的层数和模型训练和预测的准确度不成正相关。这并不是过拟合问题,模型可能因为网络层数的增加而可能出现梯度消失或梯度爆炸的问题,导致模型难以训练,由此何恺明提出了ResNet网络。ResNet里面有18、34、50、101、152层的网络结构。
- 循环神经网络中也有分许多网络,一种是Eleman RNN、另外还有门控循环网络GRU(Gated Recurrent Unit networks)、长短期记忆网络LSTM(Long Short-Term Memory networks)。其中LSTM为了解决循环神经网络的长期依赖问题(long-term dependencies problem),即在对长序列进行学习时,循环神经网络会出现梯度消失(gradient vanishing)和梯度爆炸(gradient explosion)现象,无法掌握长时间跨度的非线性关系。由于我们自然语言处理中理解一句话我们需要考虑这句话中每个单词的意思,我们就需要考虑这个单词的上下文语境来判断它的意思,由于循环神经网络具有记忆,所以我们需要用循环神经网络来处理自然语言处理领域的问题。
接下来我们会使用pytorch来构建一个简单的全连接神经网络框架,并用它来实现手写数字的识别。
二、构建神经网络
以下就是构建的一个简单的全连接神经网络。
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# 定义三个线性层
self.fc1=nn.Linear(in_features=28*28,out_features=256)
self.fc2=nn.Linear(in_features=256,out_features=256)
self.fc3=nn.Linear(in_features=256,out_features=10)
# 定义激活函数
self.relu=nn.ReLU()
def forward(self, x):
x = x.view(-1, 28 * 28) # 将多维的输入给它压扁
out=self.fc1(x)
out=self.relu(out)
out=self.fc2(out)
out=self.relu(out)
out=self.fc3(out)
return out上面的链接是pytorch的官方文档,其中有对许多种方法进行介绍,其中就包括nn.Linear。
nn.Linear表示一个线性层,主要实现以下图1的功能,即计算输入值x通过l-1层的过程,也可以表示l-1的输出值通过l层的过程:

图1
而nn.ReLU()则表示激活函数,在每一个nn.Linear()函数后都会加一个nn.ReLU()函数来充当激活函数,除了nn.ReLU函数之外还有nn.Sigmoid()、nn.Tanh、nn.LeakyReLU()、nn.Softmax()等激活函数,不过ReLU函数是最常用的激活函数。
self.fc1=nn.Linear(in_features=28*28,out_features=256)
self.fc2=nn.Linear(in_features=256,out_features=256)
self.fc3=nn.Linear(in_features=256,out_features=10)在def __init__() 函数中我们用了3个Linear函数,in_features代表输入值的大小,out_features代表这一层输出值的大小。此时我们要注意上一个Linear的out_features和下一个Linear的in_features要一样,即表示上一层的输出是下一层的输入。例如,self.fc1的out_features为256,下一层self.fc2的in_features为256。
三、用前馈神经网络实现MINIST手写数字集的识别
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
1. 下载以及可视化数据集(Download and Visualize the Data)
下载数据集:
import torch
import numpy as np
from torchvision import datasets
import torchvision.transforms as transforms
num_workers = 0 # 用于数据加载的子进程数
batch_size = 20 # 每批加载多少个样本
transform = transforms.ToTensor() # 将数据转换为torch.FloatTensor
# choose the training and test datasets
train_data = datasets.MNIST(root='data', train=True,
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,
download=True, transform=transform)
# prepare data loaders
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,
num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=batch_size,
num_workers=num_workers)
可视化一个batch_size的数据:
import matplotlib.pyplot as plt
%matplotlib inline
# 获取一批次的训练图像
dataiter = iter(train_loader)
images, labels = dataiter.next()
images = images.numpy()
# 绘制1批次中的图像以及相应的标签
fig = plt.figure(figsize=(25, 4))
for idx in np.arange(20):
ax = fig.add_subplot(2, 10, idx+1, xticks=[], yticks=[])
ax.imshow(np.squeeze(images[idx]), cmap='gray')
# 打印出每张图片的正确标签
# .item() gets the value contained in a Tensor
ax.set_title(str(labels[idx].item()))
print(images[idx].shape)
(1,28,28)是每张图片的维度,1代表一个通道数(代表灰度图像),两个28代表图片的像素为28*28。
2. 定义网络(Define the Network Architecture)
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import transforms
import torch as t
from torch.utils.data import DataLoader,Dataset
from torchvision.datasets import mnist
## Define the NN architecture
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
# 定义三个线性层
self.fc1=nn.Linear(in_features=28*28,out_features=256)
self.fc2=nn.Linear(in_features=256,out_features=256)
self.fc3=nn.Linear(in_features=256,out_features=10)
# 定义激活函数
self.relu=nn.ReLU()
def forward(self, x):
x = x.view(-1, 28 * 28) # 将多维的输入给它压扁
out=self.fc1(x)
out=self.relu(out)
out=self.fc2(out)
out=self.relu(out)
out=self.fc3(out)
return out
# initialize the NN
model = Net()
print(model)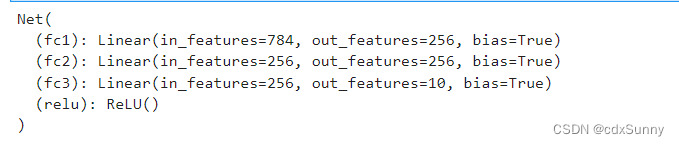
3. 定义损失函数和优化器(Specify Loss Function and Optimizer)
# specify loss function
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
# specify optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降损失函数用交叉熵损失函数CrossEntropyLoss,优化方法用随机梯度下降SGD。
4. 训练网络(Train the NetWork)
训练网络的步骤如下:
- 定义训练轮数n_epochs,代表总共需要训练多少轮
- 将模型设置为训练模式,model.train()
- 迭代训练轮数n_epochs次来训练模型
- 在每个轮数里迭代train_data
- 再每次迭代train_data中,先将梯度清空置为0
- 将data输入进模型得到出输值
- 将输出值和真实值计算损失loss
- 将损失loss反向传播,计算模型中各参数的梯度
- 根据上一步算出的梯度更新模型参数
- 回到步骤三,直到迭代够n_epochs次
# 模型训练轮数:建议在20-50间,也可根据情况自行设置
n_epochs = 30
model.train() # 训练模式
for epoch in range(n_epochs):
train_loss = 0.0
for data,target in train_loader:
optimizer.zero_grad() # 优化器将梯度值清零
#前向传播
output=model(data)
#计算交叉熵损失loss
loss=criterion(output,target)
#反向传播backpropogation
loss.backward()
#更新参数
optimizer.step()
train_loss+=loss.item()*data.size(0)
#输出本轮训练的训练误差
train_loss =train_loss/len(train_loader.dataset)
print("epoch:{} Training loss:{:.6f}".format(epoch+1,train_loss))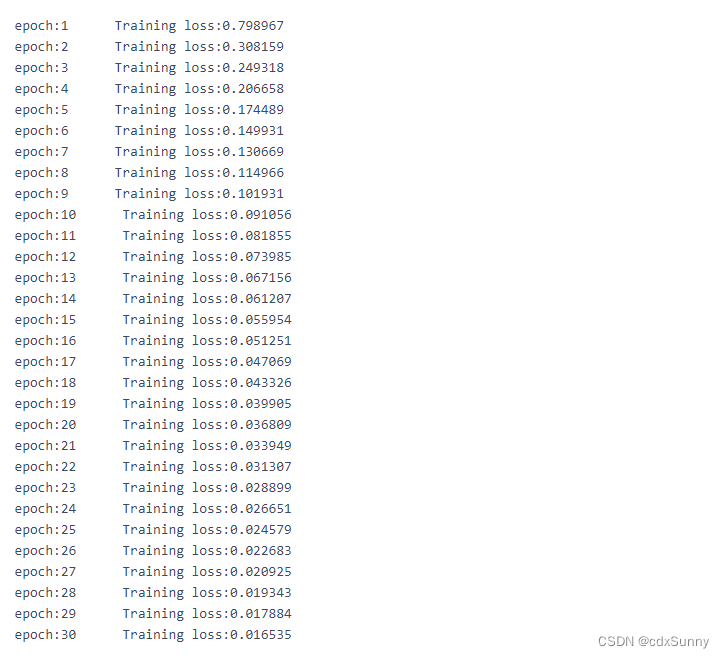
由上图可知,随着训练轮数的增加,训练误差逐渐减小。
5. 测试网络(Test the Trained Network)
# 测试模型
# 打印测试数据和准确率
# 初始化test_loss
test_loss = 0.0
class_True = list(0. for i in range(10)) # 分类正确数
class_Sum = list(0. for i in range(10)) # 总分类个数
model.eval() #测试模式
with torch.no_grad():
for data, target in test_loader:
#前向传播
output = model(data)
# 计算损失函数
loss = criterion(output, target)
# 迭代更新损失函数
test_loss += loss.item()*data.size(0)
# 将输出概率转换为预测类别
_, pred = torch.max(output, 1)
# 将预测类别与真实标签进行比较
correct = np.squeeze(pred.eq(target.data.view_as(pred)))
# 计算每个对象类别的测试准确度
for i in range(batch_size):
label = target.data[i] # 真实分类
class_True[label] += correct[i].item() # 预测分类的正确个数
class_Sum[label] += 1 # 总共分类个数
# 计算并打印平均测试损失
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}\n'.format(test_loss))
for i in range(10):
if class_Sum[i] > 0:
print('The test accuracy of %2s is : %2d%% (%2d/%2d)' % (
str(i), 100 * class_True[i] / class_Sum[i],
np.sum(class_True[i]), np.sum(class_Sum[i])))
else:
print("the test accuracy is None")
print('\nTest Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_True) / np.sum(class_Sum),
np.sum(class_True), np.sum(class_Sum)))
如上图可知,10000张图片中,我们的网络成功分类出9790张,准确率高达97%,模型效果很好。















 897
897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









