






神经网络的训练分为两步:前向传播和反向传播进行梯度更新。对于任何深度学习框架来说,自动求导是它们的核心组件。Pytorch 中的 autograd 负责进行自动求导。
进行网络训练的时候,Pytorch 会自动:
- 构建计算图
- 将输入进行前向传播
- 为每个可训练参数计算梯度
虽然我们不需要显式地调用 autograd,但更深入地了解它能够帮助我们规避一些报错,遇到报错时也有解决的思路。
计算图
我们会好奇,autograd 是如何计算梯度的。实际上,它会把所有的数据(张量)以及它们之间进行的运算,保存在一张有向无环图(directed acyclic graph, DAG)里。这张图就叫做计算图。
在计算图中,输入的张量叫做叶子节点;输出的张量叫做根节点。关于叶子节点 (leaf node) 的具体定义,我们后面仔细研究。
前向传播过程中,autograd 会同时做两件事情:
- 根据计算图进行运算,保留结果张量;
- 为计算图中用到的运算保留梯度函数
grad_fn
例子:
x = torch.ones(2, 2, requires_grad=True)
y = torch.sigmoid(x)
print(y)
>>> tensor([[0.7311, 0.7311],
[0.7311, 0.7311]], grad_fn=<SigmoidBackward0>)
当计算图的根节点(输出张量)调用 .backward() 方法时,反向传播开始,autograd 会:
- 为每一个
.grad_fn计算梯度; - 将梯度累加到相应张量的
.grad属性中; - 利用链式法则,将梯度一直反向传播至叶子节点。
下面是一个简单的计算图,蓝色代表叶子节点;绿色代表根节点;灰色代表要进行的运算。箭头指示前向传播的方向。
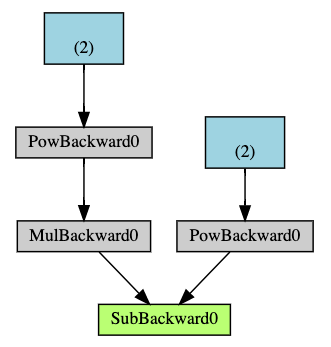
autograd
叶子节点
要真正理解 autograd,第一步就是要区分清楚叶子节点 (leaf node) 与非叶子节点。
All Tensors that have
requires_gradwhich isFalsewill be leaf Tensors by convention.
For Tensors that haverequires_gradwhich isTrue, they will be leaf Tensors if they were created by the user. This means that they are not the result of an operation and sograd_fnis None. What is the purpose ofis_leaf?
两种情况下,张量会成为叶子节点:
- 它的属性
.requires_grad=False - 它的属性
.requires_grad=True,同时该张量是由用户定义得到,而非由运算得到。
乍一看到这个定义会有些懵,还是看些例子缓缓神吧。
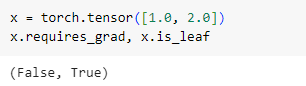
- 新定义的张量在默认情况下,
.requires_grad=False,所以它们是叶子节点:
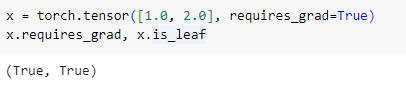
- 当我们在定义张量时设置
requires_grad=True,此时由于该张量是由用户自定义,而不是经过运算得到,它仍然是叶子节点。
- 一个张量是由其他张量运算得到,并且
requires_grad=True时,它就不是叶子节点。

注:一个运算中,如果任意一个参与运算的张量的属性
requires_grad=True,那么结果张量的requires_grad=True
到这里,叶子节点的定义清晰了许多。还要注意的一点就是,我们上面提到的“运算”,不仅仅包括加减乘除,还包括 .double(), .cuda() 等操作。例如:

另外,可以查看 .is_leaf 属性,了解某个张量是否为叶子节点
y.is_leaf
>>> False
对于计算得到的(非用户定义的)张量,无法直接更改它们的 requires_grad 属性:
y.requires_grad = False
产生错误:
RuntimeError: you can only change
requires_gradflags of leaf variables. If you want to use a computed variable in a subgraph that doesn’t require differentiation use var_no_grad = var.detach().
计算梯度
理解好叶子节点,是为反向传播时的梯度计算铺路。
我们知道,对某一张量调用 .backward() 方法会从该节点反向传播,并计算梯度。在这个过程中,只有叶子节点的 .grad 属性才会被填充,其余非叶子节点的梯度不会保留。
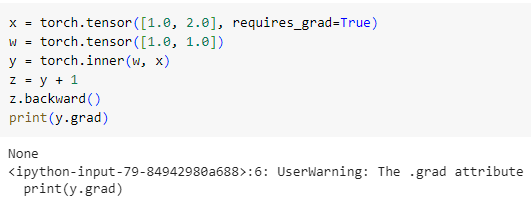
上面的例子中,y 不是叶子节点。在反向传播后,当我们想查看 y.grad 时,会发现是 None,并且还有一个 warning:
UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won’t be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations.
warning 的大意是说,你正在访问一个非叶子节点的 .grad 属性。它的 .grad 属性在反向传播时不会被填充。如果你真的要计算非叶子节点的梯度,需要先调用 .retain_grad() 方法。

在反向传播前调用 .retain_grad() 方法,Pytorch 就保留了关于 y 的梯度信息。
还有一点需要注意,对于 .requires_grad=False 的叶子节点,反向传播后,它们的 .grad 也是 None。所以如果求某个节点的梯度,必须设置属性 requires_grad=True
对于此类张量,可以通过 .detach() 方法,返回一个新的、从计算图中被分离出来的张量。
也可以使用 .detach_() 方法,实现 in-place 操作,不会返回一个新的张量——将张量从创建它的图中分离出来,使其成为一个叶子节点。
设置 retain_graph=True
进行一次反向传播后,计算图就被销毁了。此时如果我们再次调用 .backward(),就会报错
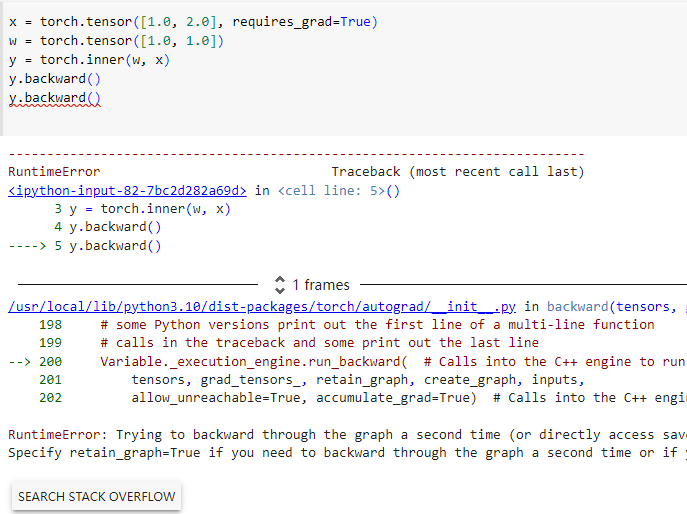
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
错误信息提示我们要设置 retain_graph=True。
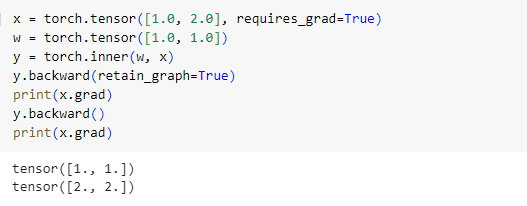
上面这段代码中,有两点需要注意:
- 设置
retain_graph=True后,第一次反向传播后计算图保留,可以进行第二次反传; - x 的梯度是累加的(一模一样的计算图,反传两次后 x 的梯度是反传一次的两倍)
retain_graph和create_graph参数 这篇文章介绍了 retain_graph 参数的另一个应用:如果想要在损失函数中加入一项“输出对于输入的导数”,那么需要设置 retain_graph=True ;如果要加入“输出对于输入的二阶导数”,还要配合 create_graph=True,对于一阶导数创建计算图,以便再次反传求二阶导。
detach() 函数
顾名思义,detach() 函数把某个张量从计算图中分离出来,使得梯度计算时不再沿着这个张量所在的路径反传。
Dive into Deep learning 中有个简单的例子:
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x * x
z = y * x
此时的计算图为:
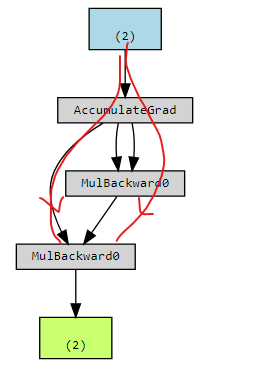
x 有两条路径对 z 造成影响。一个是直接,另一条是通过 y 间接影响。
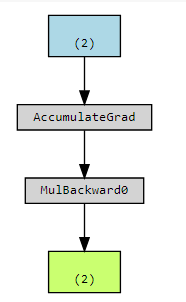
如果我们想研究 x 对 z 的直接影响有多大,应该把 x 通过 y 影响 z 的这条路径堵死,就是在计算图中分离出来:
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x * x
z = y.detach() * x
此时的计算图:
有一点要注意,分离得到的张量与原张量共享内存。如果更改分离后的张量,原张量所在的计算图将无法计算梯度。
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x * x
u = y.detach()
z = y * x
u[0] = 5.0
print(y)
>>> tensor([5., 4.], grad_fn=<MulBackward0>)
可以看到 y 的值随着 u 而改变了。如果此时调用反传,就会报错:
z.sum().backward()
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation
另外,Pytorch: Can’t call numpy() on Variable that requires grad. Use var.detach().numpy() instead 这个问题提到, 一个经常应用 detach() 方法的场景,就是把 torch.tensor 转化成 numpy ndarray 时:x.detach().numpy()
实际应用
设置 requires_grad = False
torch.autograd tracks operations on all tensors which have their requires_grad flag set to True. For tensors that don’t require gradients, setting this attribute to False excludes it from the gradient computation DAG.
autograd 会跟踪所有 requires_grad = True 的张量上的运算。对于那些不需要梯度的张量,设置 requires_grad = False 能够节省计算资源。
对模型进行微调的时候,我们不希望更新已经预训练好的网络参数,此时需要为它们设置 requires_grad = False:
for param in model.parameters():
param.requires_grad = False
with torch.no_grad() vs model.eval()
with torch.no_grad() 是一个上下文管理器 (context manager),它会创建一个环境,在此之内的张量运算均不会计算梯度。
model.eval() 会改变模型中某些层的前向传播行为,如 BatchNorm layer, Dropout layer.
可能有人会把它们混淆,但它们实际上在做完全不一样的事情。在做模型推理时,一定要设置 model.eval();最好也用 with torch.no_grad,节省计算资源。
model.eval()
with torch.no_grad():
output = model(input)
...
训练过程详解
optimizer.zero_grad()
output = model(input)
loss = criterion(output, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
上面这段代码模式,我们经常见到。我们来看看每一步都在干什么。
前面提到,反向传播时,autograd 将梯度累加到相应张量的 .grad 属性中。因此第一步要通过 optimizer.zero_grad(),将该优化器中所有的参数梯度归零。
计算得到损失函数 loss。我们知道,当计算图的根节点(输出张量)调用 .backward() 方法时,反向传播开始。这里 loss 就是根节点。loss.backward() 开启反向传播,计算梯度。
下面一步——梯度裁剪——是可选的。clip_grad_norm_(model.parameters(), 0.5) 将参数的梯度绝对值控制在 0.5 之内。梯度裁剪被认为可以增强模型的鲁棒性。
optimizer.step() 进行参数更新。如果使用最简单的梯度下降,直接计算
w
=
w
−
l
r
∗
w
.
g
r
a
d
w = w - lr*w.grad
w=w−lr∗w.grad;如果是更复杂的优化器,比如最常用的 Adam,还要考虑历史梯度。
动态计算图 vs 静态计算图
参考:stanford cs231n 2018 lecture08
Pytorch 采用动态的方式构建计算图——计算图的构建与计算同时进行;每次前向传播都会定义一个新的计算图。这样带来了很多的方便:允许我们在不同的迭代步采用不同的网络结构;也可以根据输入的不同,生成不同的计算图。
举个例子:RNN网络中,计算图是取决于输入序列的长度的,此时动态计算图就很有用。另一个例子是模块化网络——根据输入的不同,不同的网络模块会被调用,计算图自然也不同。
Pytorch 动态生成计算图:

而大多数深度学习框架,如 TensorFlow, Theano, Caffe, and CNTK,都采用静态的方式构建计算图——先构建计算图,然后进行计算;一次性为网络构建计算图,使用多次。静态计算图的优势也很明显:节省了多次构建的时间;并且能够在运算之前对计算图进行优化(比如将卷积层和 ReLU 激活函数合并)。
其实静态与动态之间的分界线正在变得模糊:
- TensorFlow 1.7 引入了
eager execution,允许动态地构建计算图; - Pytorch 也引入了 TorchScript,允许用户将 PyTorch 模型转换成 TorchScript 的中间表示,之后再进行序列化,即可把模型部署到各种平台。Torch 还提供了 C++ API,序列化后的模型可以不依赖 python,在 C++ 环境中进行推理。
预告:下一篇就来详细讲讲 Pytorch 中的即时编译(JIT)以及 TorchScript















 4339
4339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









