






Train()
每次搭神经网络都要写这个train() 函数,这次Lab作业的train()函数的框架很全面,记录一下,供之后借鉴。
from tqdm import tqdm
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = my_model(...).to(device)
model = model.double()
lr = 0.001 # learning rate
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
def train(x_train=my_docs_array_train,
y_train=my_labels_array_train,
x_test=my_docs_array_test,
y_test=my_labels_array_test,
word_dict=index_to_word,
batch_size=batch_size,
nb_epochs=nb_epochs):
model.train() # switch to `train` mode
train_data = get_loader(x_train, y_train, batch_size)
test_data = get_loader(my_docs_array_test, my_labels_array_test, batch_size)
best_validation_acc = 0.0
p = 0 # patience for early-stopping
for epoch in range(1, nb_epochs + 1):
# store the loss and accuracy in each batch
losses = []
accuracies = []
# use tqdm to better visualize the training process
with tqdm(train_data, unit="batch") as tepoch: # evaluate every batch
for idx, data in enumerate(tepoch):
tepoch.set_description(f"Epoch {epoch}") # custome the printed message in tqdm
optimizer.zero_grad()
input = data['document'].to(device)
label = data['label'].to(device)
label = label.double()
output = model.forward(input)[0]
output = output[:, -1]
loss = criterion(output, label)
loss.backward() # backward propagation
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5) # prevent exploding gradient
optimizer.step() # update parameters
# Attention: this is loss on whole batch of data, not averaged.
losses.append(loss.item())
accuracy = torch.sum(torch.round(output) == label).item() / len(label)
accuracies.append(accuracy)
# custome what is printed in tqdm message
tepoch.set_postfix(loss=sum(losses)/len(losses), accuracy=100. * sum(accuracies)/len(accuracies))
test_acc = evaluate_accuracy(test_data)
# Attention: loss is are averaged on batches.
print("===> Epoch {} Complete: Avg. Loss: {:.4f}, Validation Accuracy: {:3.2f}%"
.format(epoch, sum(losses)/len(losses), 100.*test_acc))
# save the model or not
if test_acc >= best_validation_acc:
best_validation_acc = test_acc
print("Validation accuracy improved, saving model...")
torch.save(model.state_dict(), './best_model.pt')
p = 0
print()
else:
p += 1
# early-stopping
if p==my_patience:
print("Validation accuracy did not improve for {} epochs, stopping training...".format(my_patience))
print("Loading best checkpoint...")
model.load_state_dict(torch.load('./best_model.pt'))
model.eval()
print('done.')
def evaluate(data_loader):
model.eval()
correct = 0
total = 0
for data in data_loader:
input = data['document'].to(device)
label = data['label'].to(device)
label = label.double()
output = model.forward(input)[0]
output = output[:, -1]
loss = criterion(output, label)
losses.append(loss.item())
correct += torch.sum(output == label).item()
total += len(label)
return correct/total
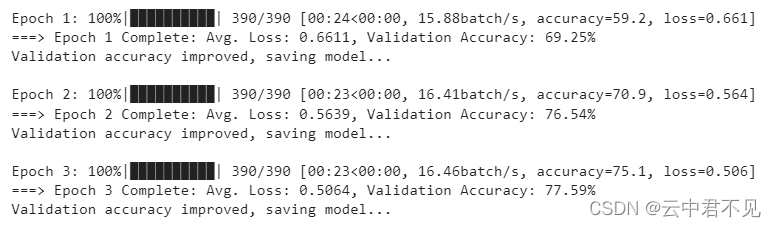
注意:losses 的每一项对应着一个 Batch 数据的平均 loss。训练过程中打印的 loss,是截止目前为止,该 epoch 中已经训练过数据上的平均 loss。最终打印的 Avg. Loss 就是该 epoch 中全部训练数据的平均 loss。对于 accuracy 同理。这就是为什么我们总是看到在一个 epoch 结束后,下一个 epoch 前几个 batch 的 loss 会骤降一些,accuracy 则会骤升几个点——因为前一个 epoch 的后几个 batch 的 loss 和 accuracy 被平均值拖了后腿。
另一个需要注意的点是,计算 accuracy 时,最好不要除以 batch size,而是除以 len(label)。因为在 DataLoader 中,如果参数 drop_last=False,那么每个 epoch 的最后一个 batch 往往是不足数的。
继承Dataset类
自定义的数据集要继承Dataset这个抽象类,并实现__len__、__getitem__方法。举个栗子:
from torch.utils.data import DataLoader, Dataset
class Dataset_(Dataset):
def __init__(self, x, y):
self.documents = x
self.labels = y
def __len__(self):
return len(self.documents)
def __getitem__(self, index):
document = self.documents[index]
label = self.labels[index]
sample = {
"document": torch.tensor(document),
"label": torch.tensor(label),
}
return sample
定义好了数据集,可以定义Dataloader了:
def get_loader(x, y, batch_size=32):
dataset = Dataset_(x, y)
data_loader = DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
drop_last=True,
)
return data_loader
保存与加载模型
保存模型参数与优化器:
torch.save({
'state_dict': myModel.state_dict(),
'optimizer' : optimizer.state_dict(),
}, 'model_lstm.pth.tar')
加载模型:
myModel = model(...).to(device)
checkpoint = torch.load('model_lstm.pth.tar')
myModel.load_state_dict(checkpoint['state_dict'])
myModel.eval()
Pytorch细节
其实,用Pytorch这个架构有很多细节和Tensorflow, Keras不一样。比如Pytorch要求必须指明线性层的输入、输出神经元的个数,但Tensorflow和 Keras可以从上一层的输出神经元个数推断出下一层线性层的输入神经元个数。搭个简单的模型:
import tensorflow as tf
inputs = tf.keras.Input(shape=(10,))
x = tf.keras.layers.Dense(4)(inputs)
outputs = tf.keras.layers.Dense(2)(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
Dense层只需要定义输出神经元个数(这里是4)即可。看一下模型的summary:
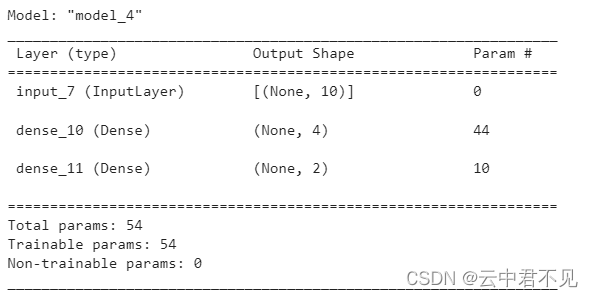
ps: 我最近才搞明白,output shape中的None是给batch size留空位的。
以后有时间再来更新~














 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









