







来源:夕小瑶科技说 原创
作者:谢年年
最近开源模型Llama3.1上线,其405B模型竟超越闭源GPT-4o,一夜之间成最强大模型!
然而榜首的位置还没坐热,仅隔一天,Mistral AI团队发布Mistral Large 2 ,最强开源再易主!
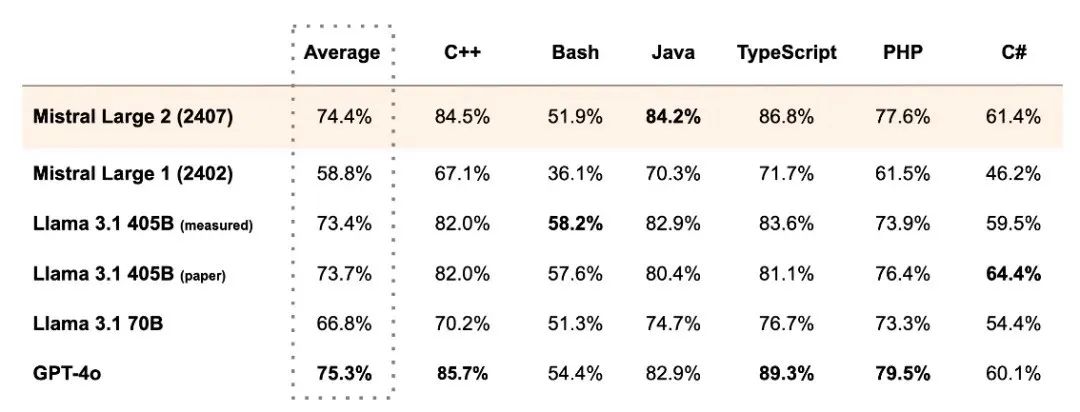
大模型之间的竞争异常激烈,榜单的分数也是越刷越高,你解决不了的问题,对我来说so easy!比如问倒一众模型的问题:3.9和3.11哪个大?Mistral Large 2模型居然答对了!

LLMs之间的规模和能力或许各不相同,但在chatgpt之后的LLMs,无论在架构、训练方式、数据方面都高度统一:比如都使用仅解码器的 transformer的结构,以及都有位置嵌入设计,预训练语料库由书籍、互联网文本和代码组成,使用基于随机梯度下降(SGD)进行优化 ,以及在预训练后进行指令调优和对齐的类似程序等等。
Salesforce AI团队最近就发现:不同的大模型家族之间,无论是闭源代表GPT和Claude,还是开源代表Mistral和Llama 3在面对虚构的问题时展现出惊人的相似性!
团队首先提示一个问题模型(QM)生成一个虚构的选择题并指出正确答案,然后邀请另一个回答模型进行回答,对比两者的答案。
结果发现,回答模型在直接生成的虚构问题上平均达到54%的正确率,当两个模型相同或属于同一家族时,正确率更高。
对于包含上下文的虚构问题时,正确率提高到86%,某些模型对的正确率高达96%。

作者称这种现象为——“共享想象力”,LLMs竟然能正确回答其他模型虚构的问答,准确率还这么高,脑回路在此刻统一了。
论文标题:
Shared Imagination: LLMs Hallucinate Alike
论文链接:
https://arxiv.org/pdf/2407.16604
构建虚构的问答数据
虚构的问答数据一共包含两种问题生成模式:直接问题生成,要求问题模型(QM)生成独立问题,称为直接问题(DQ),如下表所示:

第二种是基于上下文的问题生成),先生成虚构概念段落再生成问题,称为上下文问题(CQ):

从答案模型(AM)获取答案时,打乱选项,使用下表中的提示:

构建17种学科虚构问题,四大模型家族PK
作者选用以下模型进行实验,QMs的temperature设置为1平衡输出质量和随机性,而AMs temperature=0来贪婪地选择答案:
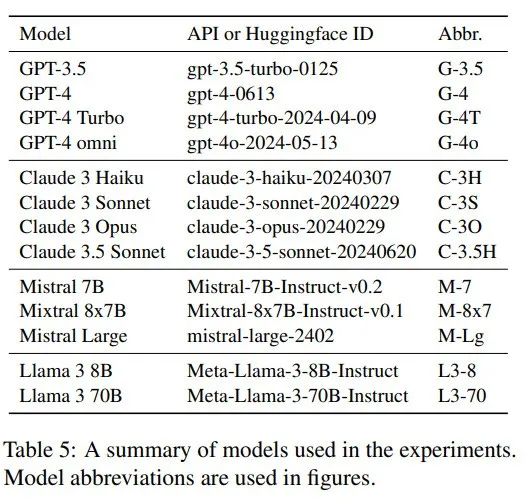
作者选择了17个常见大学学科主题构建虚构的问题,包括数学、计算机科学、物理、化学、生物、地理、社会学、心理学、经济学、会计学、市场营销、法律、政治、历史、文学、哲学和宗教。上表中的每个QM为每个主题生成20个直接问题和20个上下文问题,总计生成8840个问题。
比如Mistral Large生成的关于化学的问题:
以下哪一种元素最有可能经历一个被称为“量子隧穿”的过程,以便与稀有气体形成稳定的化合物?
答: a. 氮
b .碳
c .氧气
d .氢
Llama 3 70B生成的关于数学的问题:
下列哪个陈述是几何结构具有高流动性的直接结果?
A.结构的曲率在不同的外部影响下保持恒定。
B.结构对外力的适应性使其保持稳定的形状。
C.结构的几何形状更能抵抗周围环境的变化。
D.随着时间的推移,结构的轨迹更有可能表现出混乱的行为。
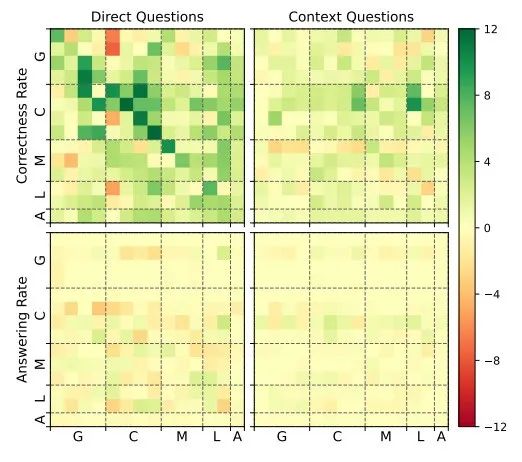
下表显示了各模型的正确率和回答率,以及相应的平均值:
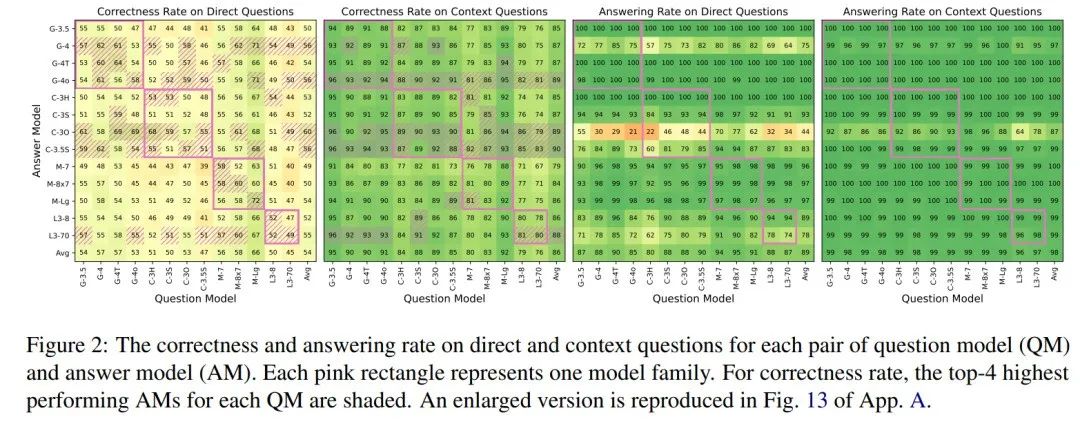
所有的正确率都高于25%的随机猜测概率。
对于直接问题(DQ),大多数表现优异的AM(即阴影单元格)与QM相同(对角线)或来自相同模型家族(块对角线)。不是一家人不进一家门,看来相同家族的模型之间共享的想象力相对来说更突出。
在上下文问题(CQ)中,正确率显著提高,平均从54%上升到86%。尽管各AM间性能差异缩小,但GPT-4 omni、Claude 3 Opus、Claude 3.5 Sonnet及Llama 3 70B在多数QM上展现出了微小优势(水平阴影标记)。
直接问题的回答率受AM特性显著影响,如GPT-4及Llama 3 70B回答率稍低,特别是Claude 3 Opus拒绝回答比较明显。而在上下文问题中,这种回避行为近乎消失,Claude 3 Opus虽仍稍显保守,但其回答率也显著提升(从44%至87%)。
LLMs为什么会出现“共享想象力”现象?
LLMs虽然来自不同的家族,但是在架构、训练方式、数据方面都高度统一:比如都使用仅解码器的 transformer的结构,以及都有位置嵌入设计,预训练语料库由书籍、互联网文本和代码组成,使用基于随机梯度下降(SGD)进行优化 ,以及在预训练后进行指令调优和对齐的类似程序。
因此LLMs在对幻觉的回答呈现出相似性似乎是理所当然的,那具体是怎么回事,我们再一起看看作者的分析。
1. 数据特征
通过研究构建的虚假问答数据,作者发现它们存在许多共同词汇,如“个体”、“原则”、“现象”和“时间”。

作者还可视化了跨主题和模型生成的问题:
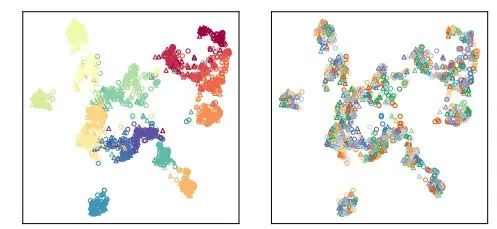
可以看到,虽然来自不同主题的问题得到了很好的聚类(图左上角),但来自不同问题模型(QM)的问题并未呈现出清晰的模式。此外,描述性问题(用三角形标记)和上下文问题(用圆形标记)之间也没有明显的区别。
另外还展示了不同模型生成的问题之间的平均余弦相似度: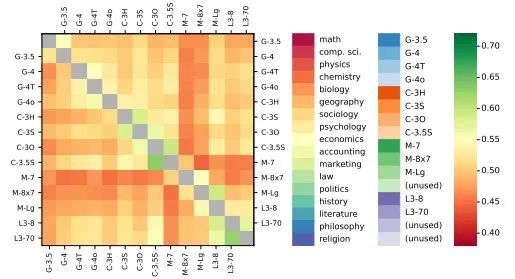
每个模型对的相似度值普遍较为接近,范围在0.44到0.63之间,其中Mistral模型与其他模型的差异最大,不同问题模型生成的问题高度相似且同质化。
2. 答案分析
人工答案猜测
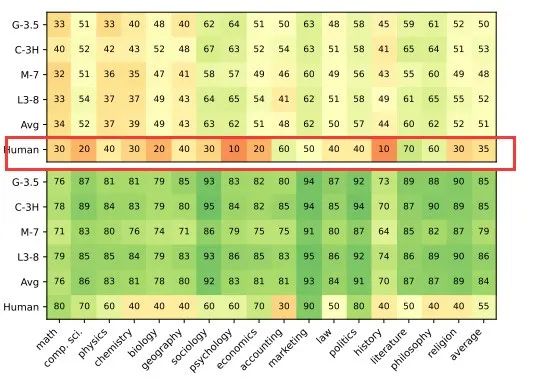
为评估生成问题的质量,作者手动回答了来自各主题的340个问题。尽管部分线索有助于猜测答案,但大多数问题仍难以回答。
如下图显示,人类在直接和上下文问题上的表现远低于模型,尤其是上下文问题。
正确答案长度分析:
对于每个问题模型中,四个选项中正确答案长度的分析,如下图显示: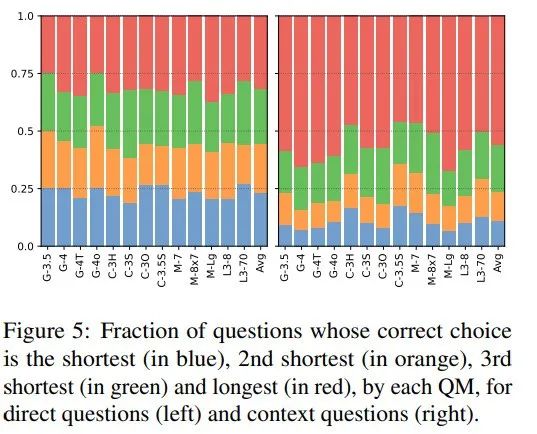
对于直接生成的问题,正确答案长度分布均匀;而对于上下文问题,正确答案更可能是最长的,这一趋势在不同模型中保持一致。
那么为何答案模型在上下文问题上表现更佳(86%正确率),或许是掌握了选择题答题的技巧——“三短一长选最长”?
答案困惑度
作者直接将问题输入模型中,要求模型生成答案,然后与各选项答案对比,研究了各选项作为自由文本响应的模型困惑度,发现正确答案并不总是困惑度最低的。

下图展示了开源模型在生成问题上的困惑度:
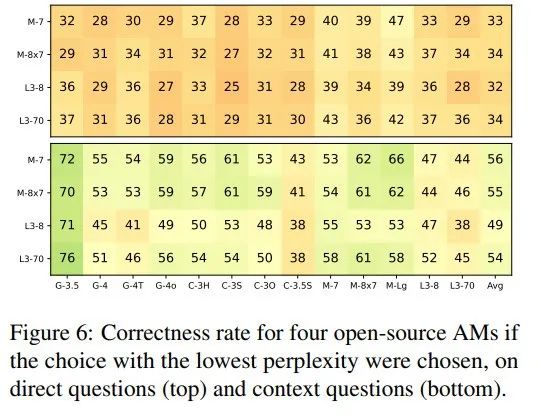
结果显示,直接选择困惑度最低的答案效果并不佳,表明模型预测涉及更复杂的特征。
答案选项顺序实验
当以问题模型生成的原始顺序呈现答案选项,发现这通常能提高正确率,尤其在直接生成问题上效果显著。
这表明模型间存在共享的正确选择规则,且模型能识别问题的虚构性。
总结:尽管发现了一些提高正确率的因素,但尚未能充分解释高正确率背后的全部机制,答案顺序的影响揭示了模型间复杂的相互作用。
3. 模型是否知道这些内容是假的?
大多数回答模型表现出较高的回答率,这引发了一个问题:模型是否真的认为这些内容具有虚构性。因此作者通过两个指标来评估模型对虚构性的识别能力。
首先在每个问题中增加了一个第五选项,即“E. 此问题无法回答,因为该概念不存在。”其次,直接使用提示“以下段落是否描述了(主题)中的真实概念?”来查询模型对上下文的虚构性识别。
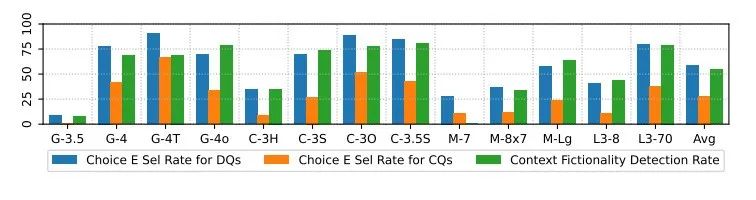
直接问题的“E”选项选择率(左图)高于上下文问题(右图)。然而,上下文问题的“E”选项选择率(中图)平均远低于上下文虚构性检测率(右图),这表明当直接查询时,模型能够识别某些内容的虚构性,但往往无法将这种知识应用于包含上下文的问答任务。
4. 模型预热的影响
上下文问题(CQ)正确率更高可能是,问题模型(QM)有更多的tokens来进行“Warm-Up(预热)”,并且模型以高度相似的方式进行预热。为了验证这个猜想,作者假设生成任何前置内容都有助于模型收敛到这个共享的想象空间。
利用先前问题预热
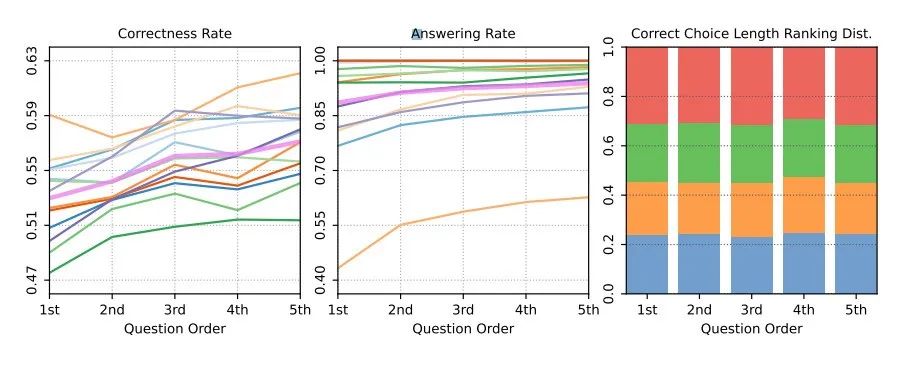
作者让模型按顺序生成五个问题,并观察从第一个到第五个问题的正确率变化。每个问题模型在每个主题上运行10次。
如果假设成立,那么预计从第一个问题到第五个问题,正确率将逐渐增加。
实验结果如下图显示,从第一个到第五个生成问题,正确率和回答率均显著增加,但正确选项的长度分布在各组中保持一致,这可能限制了增幅。
利用当前问题预热
若模型在生成先前问题时能“收敛”,生成当前问题时是否也如此?
作者假设更长的问题更易回答。为此将原始问题集按长度分成10个子集,并计算各子集下各自动模型的正确率和回答率。结果如下图,实线为直接问题,虚线为上下文问题。
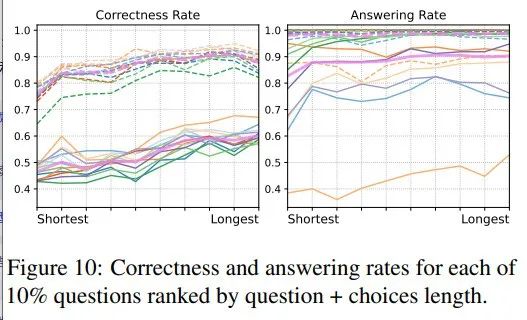
趋势非常明显:更长的问题被更准确地回答。
总结:尽管问题顺序和长度受多因素影响,但两种趋势的一致性表明,随着生成进行,内容对模型而言变得愈发熟悉和可预测。
5. 共享想象行为可能源自预训练语料库
鉴于研究模型均为ChatGPT后的指令微调版LLMs,作者还评估了下表中其他模型能否达到相同高的正确率。
设置如下提示,对于BERT使用[MASK]替换方框,并提取预测概率;其他模型则提取方框前内容的下一个标记预测概率。
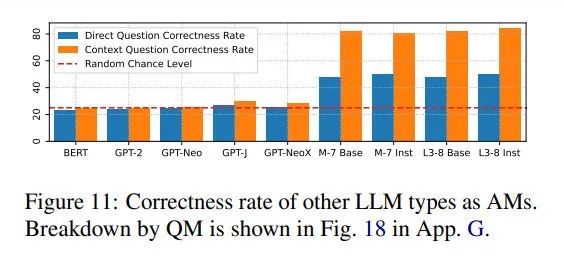
结果显示,多数ChatGPT之前的模型表现平平,而M-7和L3-8的基础与微调版(无聊天模板)表现优异,表明高正确率无需指令微调或聊天模板。
因此作者推测,共享想象行为源自预训练语料库,具体待未来工作进一步调查。
6. 写作中是否也存在类似共享想象力的行为?
作者还探究了在其他内容类型比如创意写作中是否也存在类似共享想象力的行为。
对于直接问题,让模型基于一个虚构的“关于(主题)的复杂故事情节”来生成问题,这里选择了十个抽象或具体的主题,如“友谊”或“古老帝国”;对于上下文问题,则先让模型编写短故事再提问。
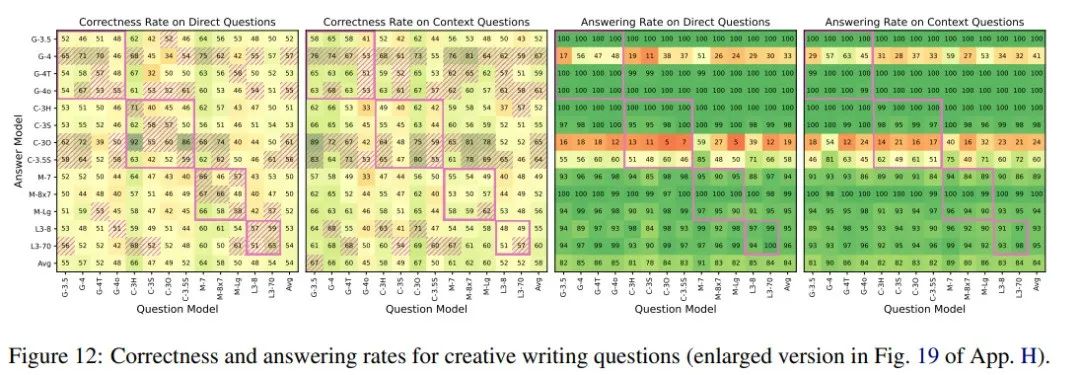
结果显示,虽然问题显得更“虚幻”,但模型在直接问题上的正确率高于随机,特别是在同一家族之间。上下文问题的正确率也有提升,但幅度较小。同时,两种设置下的回答率均高达84%,显示出模型在应对这类问题时的能力。
结论
本文提出了一个虚构问答(IQA)任务,揭示了模型能够以惊人的高正确率回答彼此纯粹虚构的问题这一有趣行为。这些结果揭示了模型之间在预训练过程中可能获得的一些相似性。
这不禁让笔者想起,现在的LLMs在扩大训练数据规模时用了大量的合成数据,很可能会进一步加剧模型之间的相似性,对于模型的长远发展来说可能并不是一件好事。
人造数据固然可贵但按照现有模型的发展速度总有耗尽的那一天,期待未来有更先进的方法解决这一难题!
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









