







来源:AI前线
作者:Dina Genkina
译者:明知山
策划:褚杏娟
虽然英伟达的 GPU 在 AI 训练领域的主导地位仍然难以撼动,但似乎有迹象表明,在 AI 推理方面,竞争对手正在迎头赶上这家科技巨头,尤其是在能效方面。然而,英伟达新推出的 Blackwell 芯片的卓越性能可能很难被超越。
最近,ML Commons 发布了最新的 AI 推理竞赛 ML Perf Inference v4.1 的成绩单。这一轮竞赛包括使用 AMD Instinct 加速器的团队、最新的谷歌 Trillium 加速器、来自多伦多初创公司 UntetherAI 的芯片以及英伟达最新发布的 Blackwell 芯片的首次试水。另外两家公司,Cerebras 和 FuriosaAI,也发布了最新的推理芯片,虽然没有提交给 MLPerf 进行评测。
就像奥林匹克运动会一样,MLPerf 也有许多类别和子类别。提交数量最多的是“封闭数据中心”类别。封闭类别(相对于开放类别)要求提交者在不进行重大软件修改的情况下按照原样运行推理任务。数据中心类别评估的是批量处理查询的能力,而边缘类别则侧重于降低延迟。
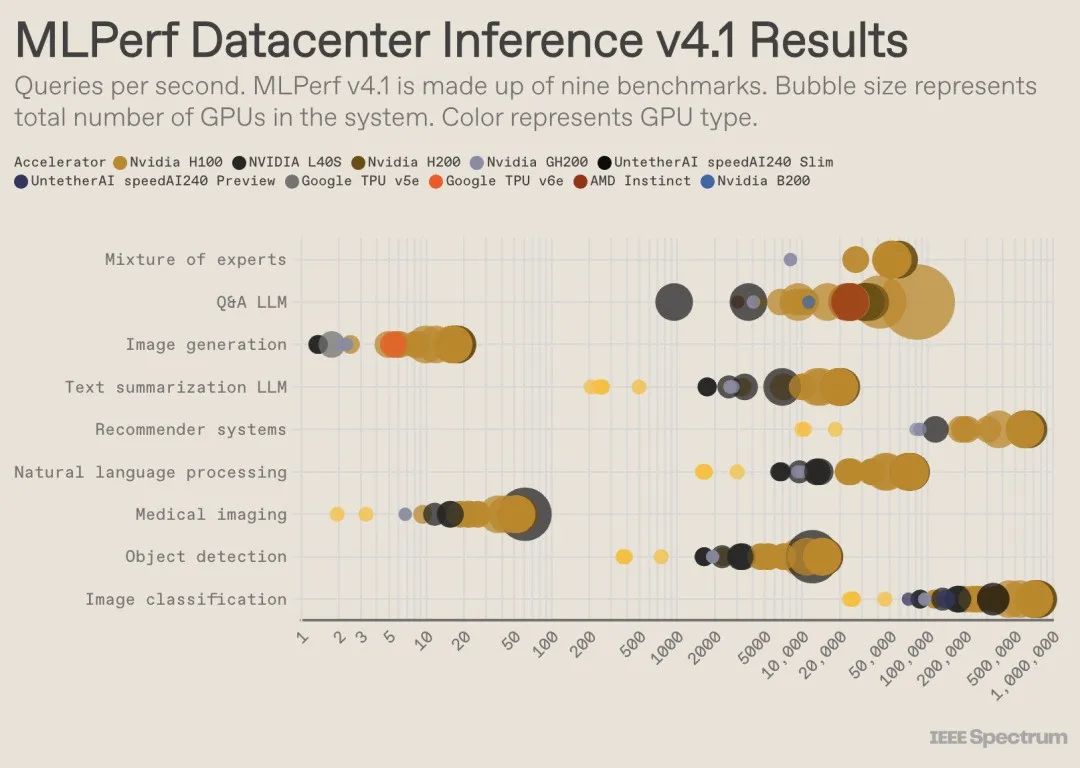
每个类别有 9 个不同的基准测试,针对不同类型的 AI 任务,包括一些流行的应用场景,如图像生成(例如 Midjourney)和 LLM 问答(例如 ChatGPT),以及同样关键但可能不那么引人注目的任务,比如图像分类、目标识别和推荐引擎。
本轮竞赛新增了一个叫作 Mixture of Experts 的基准测试。这是 LLM 部署方面的一个日益流行的趋势:一个语言模型被分解为几个较小的、独立的模型,每个子模型都针对特定任务进行微调,如常规对话、解决数学问题和协助编码。模型能够将每个查询定向到适当的子模型(或者叫“专家”模型)。这种方法使得每个查询使用更少的资源,从而降低成本并提升吞吐量。
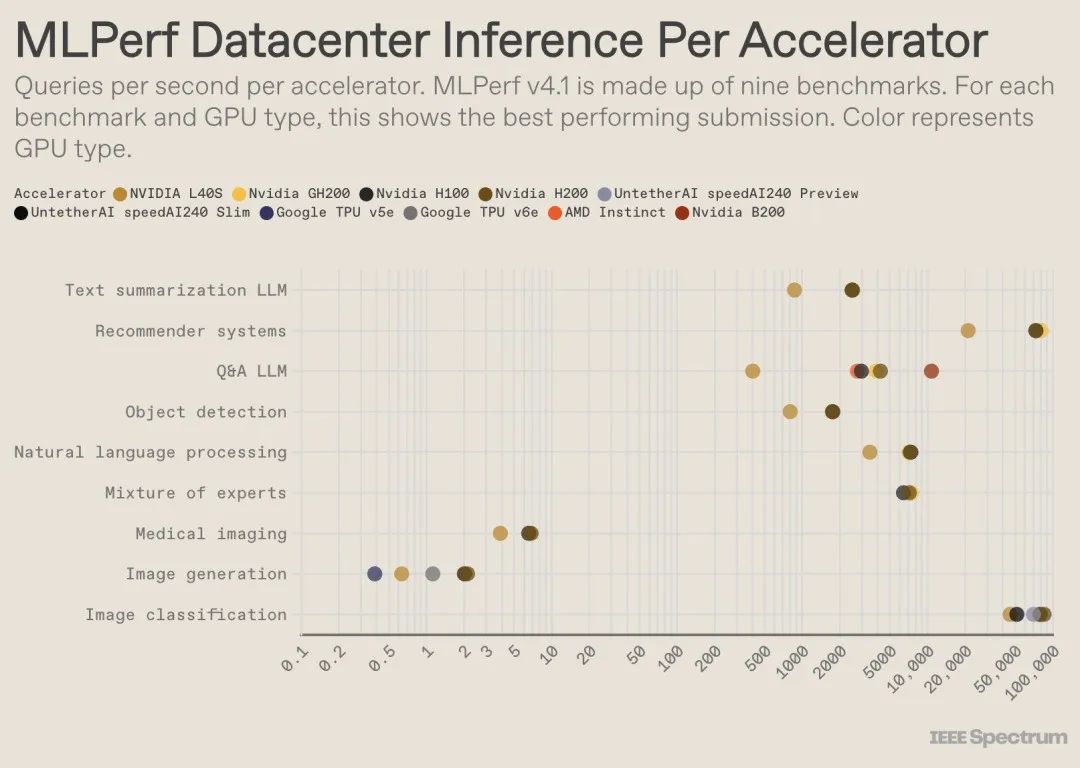
在备受瞩目的封闭数据中心基准测试中,获胜者仍然是基于英伟达 H200 GPU 和 GH200 超级芯片(封装了 GPU 和 CPU)的参赛者。然而,如果深入分析性能数据,我们会发现情况远比表面看起来的复杂。一些参赛者部署了大量加速器芯片,而另一些则只使用了一片。如果我们将每个参赛者每秒处理的查询数量按使用的加速器数量进行标准化,并仅考虑每种加速器类型的最佳性能,一些有趣的细节便会浮出水面。(需要注意的是,这种分析方法并未考虑 CPU 和互连对性能的影响。)
以单个加速器为前提,英伟达的 Blackwell 芯片在其参与的唯一基准测试——LLM 问答任务中,性能比所有之前的芯片高出 2.5 倍。Untether AI 的 speedAI240 预览芯片在它参与的唯一任务——图像识别中,性能几乎与 H200 持平。谷歌的 Trillium 在图像生成任务上的性能大约是 H100 和 H200 的一半,而 AMD 的 Instinct 在 LLM 问答任务上的性能与 H100 大致相当。
强大的 Blackwell
英伟达 Blackwell 芯片取得成功的一个关键因素是它能够使用 4 位浮点精度运行 LLM。英伟达及其竞争对手一直在努力减少用于表示数据的位数,以此来提升计算速度。英伟达在 H100 中引入了 8 位数,而此次参赛在基准测试中首次展示了其 4 位数的运算能力。
英伟达产品营销总监 Dave Salvator 指出,使用低精度数字位的最大挑战在于保持模型的准确性。为了满足 MLPerf 评测所需的高精度标准,英伟达团队不得不在软件层面进行重大创新,他补充道。
Blackwell 芯片成功的另一个关键因素是其内存带宽的显著提升,达到了每秒 8 兆字节,几乎是 H200 芯片每秒 4.8 兆字节带宽的两倍。

英伟达 GB2800 Grace Blackwell 超级芯片
Blackwell 芯片虽然在竞赛中仅使用了单个芯片,但 Salvator 指出,该芯片是为了实现联网和伸缩性而设计的,在与英伟达的 NVLink 互连技术配合使用时将发挥最大效能。Blackwell GPU 支持多达 18 个 NVLink 连接,每个连接的速率为每秒 100 千兆字节,总带宽达到每秒 1.8 兆字节,大约是 H100 互连带宽的两倍。
Salvator 认为,随着大型语言模型的不断扩展,推理任务也将需要多 GPU 平台来满足日益增长的需求,而 Blackwell 芯片正是为了应对这一趋势而设计。Salvator 强调,“Blackwell 不仅仅是一个芯片,它还是一个平台”。
英伟达基于 Blackwell 芯片的基础系统参与了 MLPerf 的预览子类别,这表明该芯片尚未对外销售,但预计将在未来六个月内,即下一次 MLPerf 评测发布之前上市。
Untether AI 在功耗和
边缘计算方面表现出色
对于 MLPerf 的每一项基准测试,都有相应的能源效率测试,以系统性地评估各系统在执行任务时的功耗。封闭数据中心能源类别只有 Nvidia 和 Untether AI 两家提交了测试结果。Nvidia 参与了所有基准测试,但 Untether AI 只参与图像识别环节。
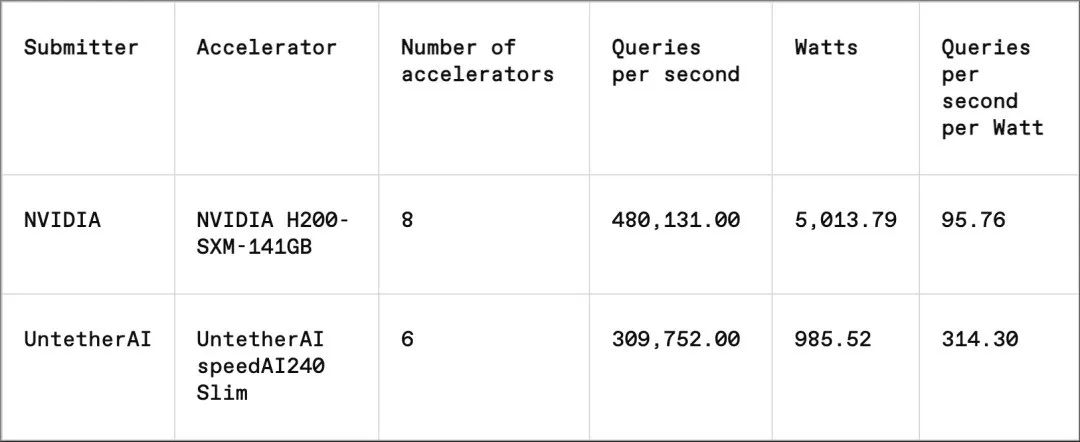
Untether AI 通过所谓的“内存内计算”实现了卓越的能效。Untether AI 的芯片设计为由内存元素构成的网格,每个小处理器紧邻其旁。处理器采用并行处理方式,与邻近内存单元格中的数据同步工作,显著减少了模型数据在内存与计算核心间传输所需的时间和资源。
Untether AI 产品副总裁 Robert Beachler 表示:“我们发现,在 AI 工作负载中,大约 90% 的能耗仅用于将数据从 DRAM 传输到缓存,再传输到处理单元。因此,我们采取了相反的策略……不是将数据移至计算单元,而是将计算单元移到数据所在的地方。”
这种创新方法在 MLPerf 的“封闭边缘”子类别中取得了显著成效。这个类别专注于更贴近实际的应用场景,如工厂内的机器检查、引导视觉机器人和自动驾驶汽车等——Beachler 指出,在这些应用中,低能耗和快速处理至关重要。
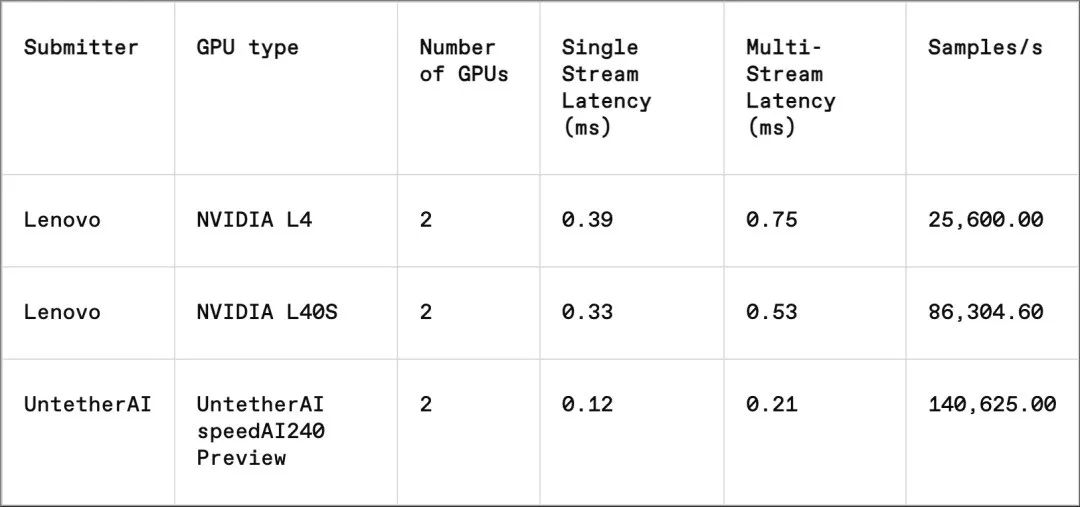
在图像识别任务中,Untether AI 仍然是唯一提供评测结果的公司,它的 speedAI240 预览芯片在延迟性能方面是 NVIDIA L40S 的 2.8 倍,吞吐量(每秒处理的样本数)提升了 1.6 倍。这家初创公司还提交了功耗数据,但因为 Nvidia 没有提供相应的数据,因此很难进行直接比较。不过,Untether AI 的 speedAI240 预览芯片每个芯片的标称功耗为 150 瓦,而 Nvidia 的 L40s 为 350 瓦,这意味着在延迟性能提升的同时,功耗名义上降低了 2.3 倍。
Cerebras、Furiosa 没有参与
MLPerf 竞赛,但发布了新的芯片
Furiosa 的新芯片采用了一种独特且高效的手段来实现 AI 推理中的基本数学运算——矩阵乘法。
在近期斯坦福大学举办的 IEEE Hot Chips 大会上,Cerebras 公司推出了自己的推理服务。这家位于加州 Sunnyvale 的公司专注于制造大型芯片,利用尽可能大的硅片来避免芯片间的互连问题,并显著提升设备的内存带宽。这些设备主要用于训练大型神经网络。现在,Cerebras 已经升级了其软件栈,用于其最新的计算机 CS3 执行推理任务。

Furiosa 的新芯片以一种不同的、更有效的方式实现了 AI 推理最基本的矩阵乘法。
尽管 Cerebras 尚未参与 MLPerf 的评测,但该公司宣称其平台在每秒生成的 Token 数量比 Nvidia 的 H100 高出 7 倍,比竞争对手 AI 初创公司 Groq 的芯片高出 2 倍。Cerebras 首席执行官兼联合创始人 Andrew Feldman 表示:“我们正处在通用人工智能的拨号上网时代。这是因为受到内存带宽的限制。无论是 Nvidia 的 H100、MI 300 还是 TPU,它们都使用相同的外部内存,从而受到相同的限制。我们已经突破了这一限制,这得益于我们的晶圆级技术。”
在 Hot Chips 大会上,来自首尔的 Furiosa 公司也发布了第二代芯片——RNGD。Furiosa 芯片的独特之处在于它所采用的张量收缩处理器(TCP)架构。在 AI 工作负载中,矩阵乘法是一项基础操作,通常在硬件中以原语的形式实现。然而,矩阵的规模和形状(即张量)可以有极大的变化。RNGD 实现了这种更为通用的乘法版本作为原语。Furiosa 创始人兼首席执行官 June Paik 在 Hot Chips 大会上解释说:“在推理过程中,批次大小差异显著,因此充分利用张量形状的固有并行性和数据重用至关重要。”
虽然 Furiosa 没有向 MLPerf 提交 RNGD 芯片的评测数据,但该公司已在内部将 RNGD 芯片在 MLPerf 的 LLM 摘要基准测试中的性能与 Nvidia 的边缘计算芯片 L40S 进行了比较。结果显示,在功耗仅为 185 瓦的情况下,RNGD 芯片的性能与功耗为 320 瓦的 L40S 相当。June Paik 表示,随着软件优化的进一步深入,芯片的性能有望得到进一步提升。
IBM 还发布了他们为满足企业生成式 AI 工作负载需求而设计的新款 Spyre 芯片,并计划于 2025 年第一季度推向市场。
至少,在可预见的未来,AI 推理芯片市场的买家们将不会感到乏味。
原文链接:
https://spectrum.ieee.org/new-inference-chips
"未来资料库"是欧米伽未来研究所为了跟踪世界范围前沿科技、能源,经济,军事、人类安全等领域未来发展趋报,建立的最新研究资料学习平台,每周将更新不少于100篇报告、论文、文章。目前“”未来资料库“”拥有重要资料超过8300份,“纵览世界,洞悉未来“,欢迎加入未来资料库。(欧米伽未来研究所是关注人类与科技的未来的研究机构,研究人类向欧米伽点演化过程中面临的重大机遇与挑战。)

部分最新精华资料如下:
1.麦肯锡2024技术趋势展望报告 100页
2.数字合作组织:2024数字经济趋势报告 132页
3.联合国:2024数字经济报告 288页
4.世界经济论坛:2024年度十大新兴技术报告 46页
5.世界银行:2024年全球经济展望报告6月刊 200页
6.斯坦福大学:2024年人工智能指数报告 502页
7.国际科学理事会:2024全球地球健康和人类福祉展望报告 1085页
8.联合国白皮书:2024气候变化、不确定性和全球灾难性风险
9.世界经济论坛:全球灾难性风险应对报告(2023-2024)
10.国防军工报告:可控核聚变,“人造太阳”未来发展研究报告
11.中国指挥与控制学会:城市大脑系列建设标准(8项)汇编
12.量子计算的未来研究报告
13.2024人形机器人研究报告
14.2024全球AI芯片行业报告
15.2024中国游戏产业AIGC发展前景
16.国际能源署:2024年世界能源展望特别报告 210页
17.彭博:2024年全球ESG展望报告 39页
18.碳中和背景下全球气候风险治理和投资趋势
19.全国信标委:智慧城市一网统管运营研究报告2024 64页
20.《未来自主系统集成的人机协作研究路线图》2024 115页
21.美国海军部:《信息优势愿景 2.0》
22.Newzoo:2024年全球游戏市场报告 44页
23.美国国家科学委员会:2023学术研究与试验发展(R&D)
24.高通:2024高通AI白皮书-让AI触手可及 76页
25.腾讯:2024大模型十大趋势,走进机器外脑时代报告 51页
26.光子盒:2024全球量子产业发展现状及展望报告 105页
27.伽马数据:2023全球移动游戏市场企业竞争力报告 57页
28.中科院:2023-2024游戏科技与人工智能创新发展报告
29.科学院大学:飞行模型-智能与意识基本原理的新探索
30.AI+汽车智能化系列之五:大模型技术综述,54页
31.《计算力与人工智能治理》2024最新 104页报告
32.《未来战争与人工智能:可见之路》 52页报告
33.《利用人工智能应对全球挑战》 63页报告
34.西电焦李成团队:6G 前沿深度学习模型的综述、机遇与挑战
35.《无人机蜂群的应用、挑战和研究课题》
36.人工智能与美国空军的未来
37.人工智能对国防的战略意义:重新定义全球安全的未来
38.2024人形机器人行业研究报告
39.2024低空智联网行业技术体系白皮书
40.2024中国低空经济行业研究报告















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









